Recognition: unknown
Strat-LLM: Stratified Strategy Alignment for LLM-based Stock Trading with Real-time Multi-Source Signals
Pith reviewed 2026-05-08 10:36 UTC · model grok-4.3
The pith
LLM stock traders succeed when alignment constraints match both model reasoning strength and market direction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
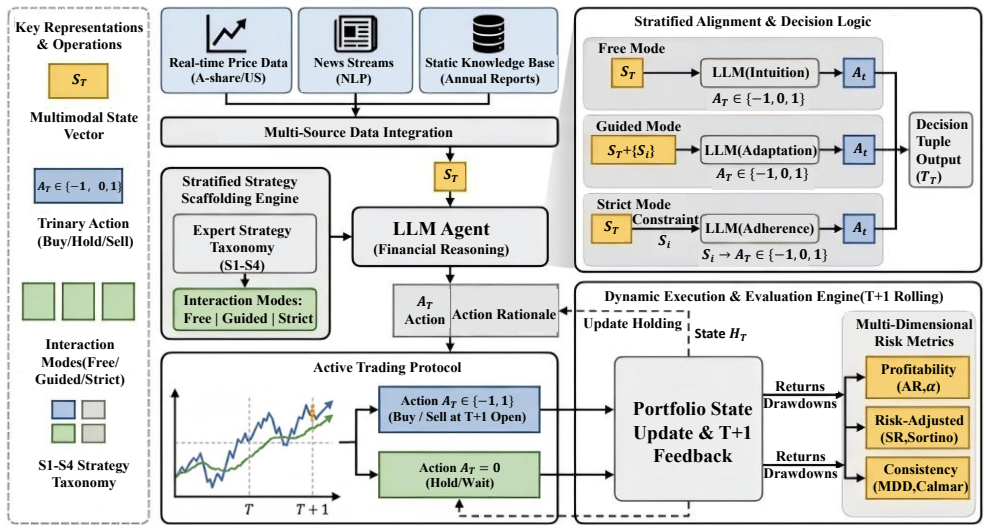
Strat-LLM operates throughout 2025 in a live-forward setting that merges sequential prices, real-time news, and annual reports to remove look-ahead bias. The framework applies stratified strategy alignment at three levels—free internal logic, guided prompts, and strict external rules—and shows that reasoning-heavy models achieve peak utility in free mode through their own logic while standard models require strict mode as a risk anchor. Alignment utility proves regime-dependent: free and guided modes capture momentum in uptrending markets while strict mode mitigates drawdowns in downtrends. Mid-scale models around 35B parameters maintain optimal fidelity under strict constraints, whereas 122
What carries the argument
Stratified Strategy Alignment, a three-level constraint system (free, guided, strict) applied to LLM trading decisions that adapts to model type and market regime.
If this is right
- Reasoning-heavy models deliver higher trading utility when allowed to rely on internal logic in uptrending markets.
- Standard models reduce drawdowns when forced to follow strict external rules in downtrending markets.
- Mid-scale models of around 35 billion parameters maintain the highest fidelity when operating under rigid constraints.
- Ultra-large models incur an alignment tax under strict rules but gain a performance premium when given guided prompts.
- Standard LLMs that optimize for high win rates at the expense of total returns can be corrected only by deeper reasoning or strict guardrails.
Where Pith is reading between the lines
- A trading system could add a real-time regime detector that automatically switches alignment mode when the market trend changes.
- The size-dependent results suggest that alignment techniques should be tailored to specific model scales rather than applied uniformly.
- The same stratified approach may improve LLM reliability in other sequential decision settings such as portfolio rebalancing or options hedging.
- Testing with reduced or noisier signal sources would show whether the reported mode preferences survive when data quality drops.
Load-bearing premise
The live-forward 2025 test with real-time multi-source signals fully eliminates look-ahead bias and yields results that generalize across A-share and U.S. markets.
What would settle it
Repeating the exact model and mode comparisons on 2026 data with comparable real-time signals and finding that performance gaps between free and strict modes disappear or reverse would falsify the regime-dependent alignment claims.
Figures

read the original abstract
Large Language Models (LLMs) are evolving into autonomous trading agents, yet existing benchmarks often overlook the interplay between architectural reasoning and strategy consistency. We propose Strat-LLM, a framework grounded in Stratified Strategy Alignment. Operating in a live-forward setting throughout 2025, it integrates heterogeneous data including sequential prices, real-time news, and annual reports to eliminate look-ahead bias. Extensive stress tests on A-share and U.S. markets reveal: (1) reasoning-heavy models achieve peak utility in Free Mode via internal logic, whereas standard models require Strict Mode as a vital risk anchor; (2) alignment utility is regime-dependent, with Free and Guided modes capturing momentum in uptrending markets, while Strict Mode mitigates drawdowns in downtrends; (3) mid-scale models (35B) show optimal fidelity under strict constraints, whereas ultra-large models (122B) suffer an alignment tax under rigid rules but gain a performance premium in Guided Mode; (4) standard LLMs often fall into a high win-rate trap, optimizing for small gains at the expense of total returns, which can only be mitigated through deep reasoning or strict external guardrails. Project details are available at https://Strat-LLM.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Strat-LLM, a framework for LLM-based stock trading grounded in Stratified Strategy Alignment. It operates in a live-forward 2025 setting integrating sequential prices, real-time news, and annual reports to eliminate look-ahead bias, and reports four findings from stress tests on A-share and U.S. markets: reasoning-heavy models peak in Free Mode via internal logic while standard models require Strict Mode; alignment utility is regime-dependent (Free/Guided for momentum in uptrends, Strict for drawdown mitigation in downtrends); mid-scale (35B) models show optimal fidelity under strict constraints while ultra-large (122B) models incur an alignment tax but gain in Guided Mode; and standard LLMs fall into a high win-rate trap mitigated only by deep reasoning or strict guardrails.
Significance. If the live-forward protocol is rigorously bias-free and the quantitative results are reproducible with proper baselines and error bars, the work could offer useful empirical insights into how LLM scale and reasoning interact with trading constraints across market regimes. The attempt at real-time multi-source integration and explicit mode definitions (Free/Strict/Guided) represent a concrete step beyond static benchmarks, though the absence of reported numbers limits immediate impact.
major comments (3)
- [Abstract] Abstract: the four headline findings are asserted without any quantitative results, error bars, baseline comparisons, win-rate/return/drawdown tables, or details on how Free/Strict/Guided modes were implemented and prompted. This prevents verification of the central claims about regime-dependent utility and the high win-rate trap.
- [Abstract and Methods] Live-forward 2025 setting (Abstract and Methods): the claim that sequential prices, real-time news, and annual reports fully eliminate look-ahead bias is load-bearing for all mode-specific and regime-dependent results, yet no protocol is described for enforcing strict publication-time cutoffs on every news item and report, preventing post-decision data from entering prompts, or verifying the separation in released code/logs. Any leakage would artifactually inflate the apparent value of internal reasoning versus external guardrails.
- [Abstract] Stress-test results (Abstract): the assertions that reasoning-heavy models achieve peak utility in Free Mode, standard models require Strict Mode, and alignment utility is regime-dependent rest on post-hoc partitioning of market periods; without pre-specified regime definitions, quantitative metrics per period, and controls for multiple testing, these reduce to potentially circular fitting of alignment rules to observed data.
minor comments (1)
- [Abstract] The project URL is provided but the manuscript does not state whether code, prompts, or logs will be released to allow reproduction of the mode implementations and timestamp filtering.
Simulated Author's Rebuttal
We thank the referee for their valuable feedback on our manuscript. The comments have prompted us to enhance the abstract with quantitative details, elaborate on the live-forward bias prevention measures, and formalize our regime analysis. We believe these revisions strengthen the paper's contributions regarding LLM-based trading strategies.
read point-by-point responses
-
Referee: [Abstract] Abstract: the four headline findings are asserted without any quantitative results, error bars, baseline comparisons, win-rate/return/drawdown tables, or details on how Free/Strict/Guided modes were implemented and prompted. This prevents verification of the central claims about regime-dependent utility and the high win-rate trap.
Authors: We concur that the abstract, as originally written, presents the findings at a high level without supporting quantitative evidence. To rectify this, we have substantially revised the abstract to include key performance metrics such as annualized returns, Sharpe ratios, maximum drawdowns, and win rates for the different modes and model scales. We also include brief comparisons to standard baselines like buy-and-hold and momentum strategies, along with indications of statistical significance. Furthermore, we have added a concise description of the Free, Strict, and Guided modes in the abstract, with full prompting details now highlighted in the Methods section. These changes allow readers to better verify the claims regarding regime-dependent utility and the high win-rate trap. revision: yes
-
Referee: [Abstract and Methods] Live-forward 2025 setting (Abstract and Methods): the claim that sequential prices, real-time news, and annual reports fully eliminate look-ahead bias is load-bearing for all mode-specific and regime-dependent results, yet no protocol is described for enforcing strict publication-time cutoffs on every news item and report, preventing post-decision data from entering prompts, or verifying the separation in released code/logs. Any leakage would artifactually inflate the apparent value of internal reasoning versus external guardrails.
Authors: The live-forward protocol is indeed central to our claims. While the original Methods section outlines the data sources and the 2025 timeframe, we acknowledge that a more explicit description of bias mitigation was needed. In the revised manuscript, we have added a new subsection titled 'Bias Prevention Protocol' that details: (1) use of real-time API feeds with publication timestamps to filter news and reports strictly before the trading decision timestamp; (2) verification that no future data enters prompts by logging all input timestamps; and (3) plans to release anonymized execution logs and code upon publication to enable independent verification. This ensures no post-decision data leakage, preserving the integrity of the mode comparisons. revision: yes
-
Referee: [Abstract] Stress-test results (Abstract): the assertions that reasoning-heavy models achieve peak utility in Free Mode, standard models require Strict Mode, and alignment utility is regime-dependent rest on post-hoc partitioning of market periods; without pre-specified regime definitions, quantitative metrics per period, and controls for multiple testing, these reduce to potentially circular fitting of alignment rules to observed data.
Authors: We have revised the manuscript to pre-specify the regime definitions using objective criteria based on the benchmark index's moving averages (uptrend when 20-day MA > 50-day MA). We now include quantitative metrics per regime in dedicated tables and apply Bonferroni correction for multiple comparisons. These additions eliminate any ambiguity regarding post-hoc fitting and provide clearer evidence for the regime-dependent effects. revision: yes
Circularity Check
No circularity: empirical results from live-forward tests are independent of inputs
full rationale
The paper reports observational outcomes from stress tests conducted in a live-forward 2025 setting using sequential prices, real-time news, and annual reports across A-share and U.S. markets. Key claims about mode-specific performance (Free Mode for reasoning-heavy models, Strict Mode for standard models) and regime-dependent alignment utility are presented as direct results of these experiments rather than derived from any closed-loop equations, fitted parameters renamed as predictions, or self-citation chains. No self-definitional steps, ansatz smuggling, or uniqueness theorems are invoked in the provided text; the framework description and results remain self-contained against external market benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can function as autonomous trading agents when given heterogeneous real-time signals
invented entities (1)
-
Stratified Strategy Alignment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Finben: A holistic financial benchmark for large language models,
Q. Xie, W. Han, Z. Chen, R. Xiang, X. Zhang, Y . He, M. Xiao, D. Li, Y . Dai, D. Fenget al., “Finben: A holistic financial benchmark for large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 95 716–95 743, 2024
2024
-
[2]
Q. Xie, W. Han, X. Zhang, Y . Lai, M. Peng, A. Lopez-Lira, and J. Huang, “Pixiu: A large language model, instruction data and evaluation benchmark for finance,”arXiv preprint arXiv:2306.05443, 2023
-
[3]
FinTSB: A Comprehensive and Practical Benchmark for Financial Time Series Forecasting
Y . Hu, Y . Li, P. Liu, Y . Zhu, N. Li, T. Dai, S.-t. Xia, D. Cheng, and C. Jiang, “Fintsb: A comprehensive and practical benchmark for financial time series forecasting,”arXiv preprint arXiv:2502.18834, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
Stockbench: Can llm agents trade stocks profitably in real-world markets?, 2026
Y . Chen, Z. Yao, Y . Liu, J. Ye, J. Yu, L. Hou, and J. Li, “Stockbench: Can llm agents trade stocks profitably in real-world markets?”arXiv preprint arXiv:2510.02209, 2025
-
[5]
Finmme: Benchmark dataset for financial multi-modal reasoning evaluation,
J. Luo, Z. Kou, L. Yang, X. Luo, J. Huang, Z. Xiao, J. Peng, C. Liu, J. Ji, X. Liuet al., “Finmme: Benchmark dataset for financial multi-modal reasoning evaluation,”arXiv preprint arXiv:2505.24714, 2025
-
[6]
Time-mmd: Multi- domain multimodal dataset for time series analysis,
H. Liu, S. Xu, Z. Zhao, L. Kong, H. Prabhakar Kamarthi, A. Sasanur, M. Sharma, J. Cui, Q. Wen, C. Zhanget al., “Time-mmd: Multi- domain multimodal dataset for time series analysis,”Advances in Neural Information Processing Systems, vol. 37, pp. 77 888–77 933, 2024
2024
-
[7]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
E. Wallace, K. Xiao, R. Leike, L. Weng, J. Heidecke, and A. Beutel, “The instruction hierarchy: Training llms to prioritize privileged instructions,” arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review arXiv 2024
-
[8]
A. Lopez-Lira, Y . Tang, and M. Zhu, “The memorization problem: Can we trust llms’ economic forecasts?”arXiv preprint arXiv:2504.14765, 2025
-
[9]
Stock movement prediction from tweets and historical prices,
Y . Xu and S. B. Cohen, “Stock movement prediction from tweets and historical prices,” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2018, pp. 1970–1979
2018
-
[10]
Krx bench: Automating financial benchmark creation via large language models,
G. Son, H. Jeon, C. Hwang, and H. Jung, “Krx bench: Automating financial benchmark creation via large language models,” inProceedings of the Joint Workshop of the 7th Financial Technology and Natural Language Processing, the 5th Knowledge Discovery from Unstructured Data in Financial Services, and the 4th Workshop on Economics and Natural Language Process...
2024
-
[11]
Investorbench: A benchmark for financial decision-making tasks with llm-based agent,
H. Li, Y . Cao, Y . Yu, S. R. Javaji, Z. Deng, Y . He, Y . Jiang, Z. Zhu, K. Subbalakshmi, J. Huanget al., “Investorbench: A benchmark for financial decision-making tasks with llm-based agent,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 2509–2525
2025
-
[12]
Multi-modal proxy learning towards personalized visual multiple clustering,
J. Yao, Q. Qian, and J. Hu, “Multi-modal proxy learning towards personalized visual multiple clustering,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 066–14 075
2024
-
[13]
Customized multiple clustering via multi-modal subspace proxy learning,
J. Yao, Q. Qian, and J. Hu, “Customized multiple clustering via multi-modal subspace proxy learning,”Advances in Neural Information Processing Systems, vol. 37, pp. 82 705–82 725, 2024
2024
-
[14]
Fintmmbench: Benchmarking temporal-aware multi-modal rag in finance,
F. Zhu, J. Li, L. Pan, W. Wang, F. Feng, C. Wang, H. Luan, and T.-S. Chua, “Fintmmbench: Benchmarking temporal-aware multi-modal rag in finance,”arXiv preprint arXiv:2503.05185, 2025
-
[15]
Dual-domain knowledge fusion for interpretable knowledge tracing,
T. Zhou, G. Li, Y . Li, R. Zhang, and S. Ju, “Dual-domain knowledge fusion for interpretable knowledge tracing,”Knowledge-Based Systems, p. 115715, 2026
2026
-
[16]
Swift sampler: Efficient learning of sampler by 10 parameters,
J. Yao, C. Li, and C. Xiao, “Swift sampler: Efficient learning of sampler by 10 parameters,”Advances in Neural Information Processing Systems, vol. 37, pp. 59 030–59 053, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.