Visual Fingerprints for LLM Generation Comparison
Pith reviewed 2026-05-08 10:32 UTC · model grok-4.3
The pith
Visual fingerprints of linguistic choice distributions reveal consistent LLM behaviors across different generation conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
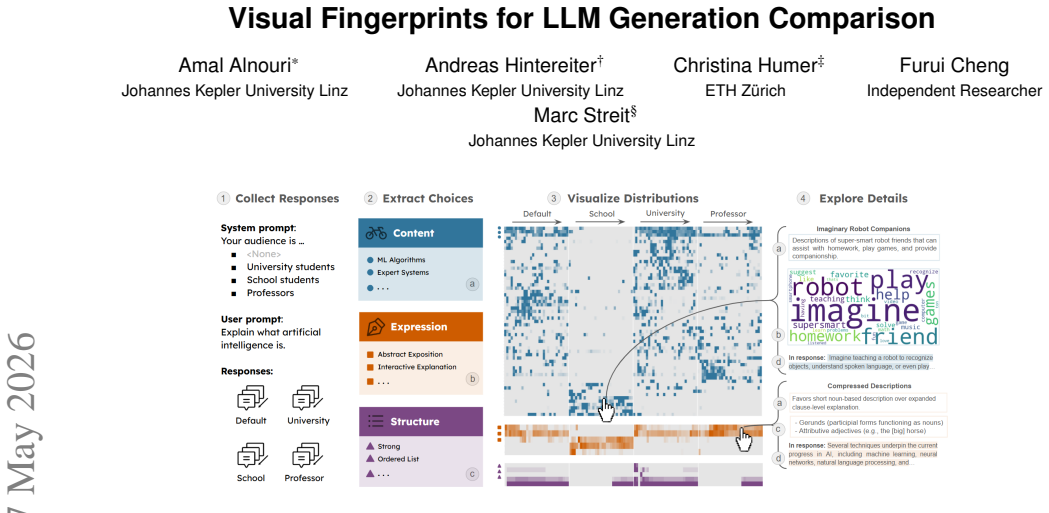
The authors claim that modeling LLM responses under specific generation conditions as distributions of linguistic choices in content, expression, and structure, then visualizing these distributions as fingerprints, enables direct comparison of condition-specific tendencies and uncovers consistent behavioral patterns that are difficult to observe through individual responses or aggregate metrics, as demonstrated in four usage scenarios.
What carries the argument
The visual fingerprint, a representation of frequency distributions of categorized linguistic choices (content, expression, structure) extracted from repeated samples under a fixed generation condition.
If this is right
- Distinct generation conditions produce distinguishable fingerprints that expose specific biases in what content is chosen, how it is phrased, and how it is organized.
- Consistent patterns in LLM behavior become visible at the distribution level even when any single response looks ordinary.
- Changes to prompts or system instructions can be evaluated by observing shifts in the choice distributions shown in the fingerprints.
- Model evaluation gains a visual, distribution-based view that supplements or replaces reliance on single examples and summary scores.
Where Pith is reading between the lines
- The same fingerprint method could be used to compare outputs from entirely different models under identical conditions to highlight architectural differences.
- Tracking fingerprints over successive model versions or fine-tuning steps might reveal how training changes gradually alter generation tendencies.
- Automated monitoring systems could flag when fingerprints drift toward repetitive or undesired choice distributions in deployed applications.
Load-bearing premise
Natural language processing pipelines can reliably extract and categorize linguistic choices in content, expression, and structure so that the resulting distributions faithfully reflect biases induced by different generation conditions.
What would settle it
If fingerprints produced under two generation conditions known to differ produce visually identical distributions, or if manual inspection of the underlying texts shows that the automated categories do not match the actual choices made.
Figures



read the original abstract
Large language model (LLM) outputs arise from complex interactions among prompts, system instructions, model parameters, and architecture. We refer to specific configurations of these factors as generation conditions, each of which can bias outputs in various ways. Understanding how different generation conditions shape model behaviors is essential for tasks such as prompt design and model evaluation, yet it remains challenging due to the stochastic and open-ended nature of text generation. We present an approach to visually compare LLM outputs across generation conditions by modeling responses as collections of linguistic choices, including content, expression, and structure. We extract these choices using natural language processing pipelines and represent their distributions across repeated samples. We then visualize these distributions as visual fingerprints, enabling direct, distribution-level comparison of condition-specific tendencies. Through four usage scenarios, we demonstrate how visual fingerprints reveal consistent patterns in LLM behavior that are difficult to observe through individual responses or aggregate metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes modeling LLM outputs under varying generation conditions (prompts, instructions, parameters) as distributions of linguistic choices across content, expression, and structure. These distributions are extracted via standard NLP pipelines and rendered as visual fingerprints to enable direct comparison of condition-specific biases. The central claim is that four usage scenarios demonstrate how the fingerprints surface consistent behavioral patterns that are difficult to detect from individual responses or aggregate metrics alone.
Significance. If the extraction step can be shown to faithfully preserve generation-induced biases rather than pipeline artifacts, the visual-fingerprint approach would supply a compact, intuitive complement to existing quantitative evaluation tools for prompt design and model auditing. The method reuses off-the-shelf NLP components without introducing new parameters or circular fitting, which is a modest but positive design choice.
major comments (2)
- [Abstract] Abstract: the claim that fingerprints 'reveal consistent patterns ... difficult to observe through individual responses or aggregate metrics' is presented without any quantitative validation, baseline comparisons, error rates, or human-judgment agreement scores for the four scenarios. This directly undermines the demonstration that the method adds observable value beyond existing approaches.
- [Abstract] Abstract (method description): the NLP pipelines used to categorize linguistic choices (content, expression, structure) are described only at the level of 'natural language processing pipelines' with no specification of the concrete tools, category definitions, inter-annotator reliability, or ablation showing that the chosen categories capture condition-induced biases rather than generic text statistics. This extraction step is load-bearing for the entire pipeline.
minor comments (1)
- [Abstract] The abstract introduces the term 'visual fingerprints' without a concise one-sentence definition that could be used as a caption or takeaway.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where the abstract and method presentation can be strengthened. We will revise the manuscript to incorporate quantitative validation and detailed methodological specifications while preserving the core contribution of visual fingerprints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that fingerprints 'reveal consistent patterns ... difficult to observe through individual responses or aggregate metrics' is presented without any quantitative validation, baseline comparisons, error rates, or human-judgment agreement scores for the four scenarios. This directly undermines the demonstration that the method adds observable value beyond existing approaches.
Authors: We agree that the claim in the abstract would be more robust with supporting quantitative evidence. The four usage scenarios currently serve as qualitative demonstrations through side-by-side visual comparisons of distributions. In the revision, we will add quantitative validation: statistical measures of consistency (e.g., reduced variance in feature distributions across repeated samples under the same condition), baseline comparisons against a null model of shuffled or random linguistic choices, and extraction error rates computed over multiple runs. We will also report stability metrics. A limited human interpretability study is feasible as supplementary material but is not central to the automated pipeline; we will prioritize the statistical analyses to directly address the added value. revision: yes
-
Referee: [Abstract] Abstract (method description): the NLP pipelines used to categorize linguistic choices (content, expression, structure) are described only at the level of 'natural language processing pipelines' with no specification of the concrete tools, category definitions, inter-annotator reliability, or ablation showing that the chosen categories capture condition-induced biases rather than generic text statistics. This extraction step is load-bearing for the entire pipeline.
Authors: We acknowledge that the abstract (and high-level method overview) leaves the extraction step underspecified. We will revise the abstract to briefly note the use of standard off-the-shelf NLP components and expand the Methods section with concrete details: category definitions (content: entity and topic extraction; expression: lexical and sentiment features; structure: syntactic metrics), the specific libraries employed, and an ablation study. The ablation will compare the full category set against generic text statistics (e.g., length and frequency alone) to demonstrate that the chosen categories better isolate generation-condition biases. As the pipelines are deterministic and rule-based, inter-annotator reliability does not apply; we will instead report run-to-run stability. These additions will confirm the extraction preserves condition-induced signals. revision: yes
Circularity Check
No circularity in methodological proposal for visual fingerprints
full rationale
The paper proposes a direct visualization method that models LLM outputs as distributions of linguistic choices extracted via standard NLP pipelines and rendered as fingerprints for comparison across generation conditions. No equations, derivations, fitted parameters, or predictions appear in the abstract or described approach. The four usage scenarios function as empirical demonstrations rather than self-referential fits or outputs forced by construction. No self-citations are invoked to justify core premises, uniqueness theorems, or ansatzes, and the method applies existing NLP components without redefining inputs in terms of outputs or smuggling assumptions through prior author work. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Responses can be modeled as collections of linguistic choices (content, expression, structure) extractable by NLP pipelines.
invented entities (1)
-
visual fingerprints
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems
I. Arawjo, C. Swoopes, P. Vaithilingam, M. Wattenberg, and E. L. Glassman. Chainforge: A visual toolkit for prompt engineering and llm hypothesis testing. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, 2024. doi: 10.1145/3613904. 3642016 2
-
[2]
N. Begu ˇs. Experimental narratives: A comparison of human crowd- sourced storytelling and ai storytelling.Humanities and Social Sci- ences Communications, 11(1):1–22, 2024. 4
2024
-
[3]
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM Conference on Fairness, Account- ability, and Transparency, p. 610–623, 2021. doi: 10.1145/3442188. 3445922 1
-
[4]
Biber.Variation across speech and writing
D. Biber.Variation across speech and writing. Cambridge university press, 1991. 2
1991
-
[5]
Holistic evaluation of language models
R. Bommasani, P. Liang, and T. Lee. Holistic evaluation of language models.Annals of the New York Academy of Sciences, 1525(1):140– 146, 2023. doi: 10.1111/nyas.15007 1
-
[6]
Brath, A
R. Brath, A. Bradley, and D. Jonker. Visualizing llm text style transfer: visually dissecting how to talk like a pirate. InProceedings of the NLVIZ Workshop at IEEE VIS 2023, 10 2023. 2
2023
-
[7]
Brath, A
R. Brath, A. Bradley, and D. Jonker. Visualizing textual distributions of repeated llm responses to characterize llm knowledge. InProceed- ings of the NLVIZ Workshop at IEEE VIS 2023, 10 2023. 2
2023
-
[8]
Q. Castell `a and C. Sutton. Word storms: multiples of word clouds for visual comparison of documents. InProceedings of the 23rd Interna- tional Conference on World Wide Web, p. 665–676. New York, NY , USA, 2014. doi: 10.1145/2566486.2567977 2
-
[9]
T. A. Chang and B. K. Bergen. Language model behavior: A com- prehensive survey.Computational Linguistics, 50(1):293–350, Mar
-
[10]
doi: 10.1162/coli a 00492 1
-
[11]
F. Cheng, V . Zouhar, S. Arora, M. Sachan, H. Strobelt, and M. El- Assady. Relic: Investigating large language model responses using self-consistency. InProceedings of the 2024 CHI Conference on Hu- man Factors in Computing Systems. New York, NY , USA, 2024. doi: 10.1145/3613904.3641904 2
-
[12]
K. I. Gero, C. Swoopes, Z. Gu, J. K. Kummerfeld, and E. L. Glassman. Supporting sensemaking of large language model outputs at scale. In Proceedings of the 2024 CHI Conference on Human Factors in Com- puting Systems, 2024. doi: 10.1145/3613904.3642139 2
-
[13]
From scale to speed: Adaptive test-time scaling for image editing.CoRR, abs/2603.00141, 2026
M. Grootendorst. BERTopic: Neural topic modeling with a class- based tf-idf procedure.arXiv preprint, 2022. doi: 10.48550/arXiv. 2203.05794 2
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[14]
Gupta, V
S. Gupta, V . Shrivastava, A. Deshpande, A. Kalyan, P. Clark, A. Sab- harwal, and T. Khot. Bias runs deep: Implicit reasoning biases in persona-assigned LLMs. InThe Twelfth International Conference on Learning Representations, 2024. 3
2024
-
[15]
M. A. K. Halliday and C. M. Matthiessen.Halliday’s introduction to functional grammar. Routledge, 2013. 2
2013
-
[16]
P. Jiang, J. Rayan, S. P. Dow, and H. Xia. Graphologue: Exploring large language model responses with interactive diagrams. InPro- ceedings of the 36th Annual ACM Symposium on User Interface Soft- ware and Technology, 2023. doi: 10.1145/3586183.3606737 2
-
[17]
J ¨anicke, A
S. J ¨anicke, A. Geßner, M. B ¨uchler, and G. Scheuermann. Visualiza- tions for text re-use. In2014 International Conference on Information Visualization Theory and Applications (IVAPP), pp. 59–70, 2014. 2
2014
-
[18]
M. Kahng, I. Tenney, M. Pushkarna, M. X. Liu, J. Wexler, E. Reif, K. Kallarackal, M. Chang, M. Terry, and L. Dixon. Llm comparator: Visual analytics for side-by-side evaluation of large language models. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems, 2024. doi: 10.1145/3613905.3650755 2
-
[19]
D. A. Keim and D. Oelke. Literature fingerprinting: A new method for visual literary analysis. In2007 IEEE Symposium on Visual Analyt- ics Science and Technology, pp. 115–122, 2007. doi: 10.1109/V AST. 2007.4389004 2
work page doi:10.1109/v 2007
-
[20]
J. Kessler. Scattertext: a browser-based tool for visualizing how cor- pora differ. InProceedings of ACL 2017, System Demonstrations, pp. 85–90. Vancouver, Canada, July 2017. 2
2017
-
[21]
T. S. Kim, H. Lee, Y . Lee, J. Seering, and J. Kim. Evalet: Evaluating large language models through functional fragmentation. InProceed- ings of the 2026 CHI Conference on Human Factors in Computing Systems, CHI ’26, 2026. doi: 10.1145/3772318.3790285 2
-
[22]
T. S. Kim, Y . Lee, J. Shin, Y .-H. Kim, and J. Kim. Evallm: Interac- tive evaluation of large language model prompts on user-defined cri- teria. InProceedings of the 2024 CHI Conference on Human Fac- tors in Computing Systems. New York, NY , USA, 2024. doi: 10.1145/ 3613904.3642216 2
-
[23]
J. Lee, T. Le, J. Chen, and D. Lee. Do language models plagiarize? In Proceedings of the ACM Web Conference 2023, p. 3637–3647. New York, NY , USA, 2023. doi: 10.1145/3543507.3583199 1
-
[24]
A. Maimon, A. D. Cohen, G. Vishne, S. Ravfogel, and R. Tsarfaty. IQ test for LLMs: An evaluation framework for uncovering core skills in LLMs.arXiv preprint, 2025. doi: 10.48550/arXiv.2507.20208 2
-
[25]
D. Murray, C. Ni, W. Gu, and T. Hubbard. Using language models to label clusters of scientific documents.Scientometrics, pp. 1–30, 2025. doi: 10.1007/s11192-025-05445-5 2
-
[26]
O’Sullivan
J. O’Sullivan. Stylometric comparisons of human versus ai-generated creative writing.Humanities and Social Sciences Communications, 12(1):1–6, 2025. 4
2025
-
[27]
R. Y . Pang, K. J. K. Feng, S. Feng, C. Li, W. Shi, Y . Tsvetkov, J. Heer, and K. Reinecke. Interactive reasoning: Visualizing and controlling chain-of-thought reasoning in large language models. InProceedings of the 31st International Conference on Intelligent User Interfaces, p. 852–867, 2026. doi: 10.1145/3742413.3789091 2
-
[28]
E. Reif, C. Qian, J. Wexler, and M. Kahng. Automatic histograms: Leveraging language models for text dataset exploration. InExtended Abstracts of the CHI Conference on Human Factors in Computing Sys- tems, CHI EA ’24. New York, NY , USA, 2024. doi: 10.1145/3613905 .3650798 2
-
[29]
R. L. Ribler and M. Abrams. Using visualization to detect plagiarism in computer science classes. InProceedings of the IEEE Symposium on Information Vizualization 2000, p. 173. USA, 2000. 2
2000
-
[30]
D. Shi, F. Cheng, T. Weinkauf, A. Oulasvirta, and M. El-Assady. DxHF: Providing high-quality human feedback for llm alignment with interactive decomposition. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology, 2025. doi: 10 .1145/3746059.3747600 2
-
[31]
D. A. Szafir, D. Stuffer, Y . Sohail, and M. Gleicher. Textdna: Visu- alizing word usage with configurable colorfields.Computer Graphics Forum, 35(3):421–430, 2016. doi: 10.1111/cgf.12918 2
-
[32]
A. S. Thakur, K. Choudhary, V . S. Ramayapally, S. Vaidyanathan, and D. Hupkes. Judging the judges: Evaluating alignment and vulnera- bilities in llms-as-judges. InProceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM2), pp. 404–430, 2025. 2
2025
-
[33]
doi: 10.18653/v1/ 2023.blackboxnlp-1.2
D. Wadi and M. Fredette. A Monte-Carlo sampling framework for reliable evaluation of large language models using behavioral analysis. InFindings of the Association for Computational Linguistics: EMNLP 2025, pp. 9414–9432. Suzhou, China, Nov. 2025. doi: 10.18653/v1/ 2025.findings-emnlp.500 1
-
[34]
Y . Wang, X. Ma, G. Zhang, Y . Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. InAdvances in Neu- ral Information Processing Systems, vol. 37, pp. 95266–95290, 2024. doi: 10.52202/079017-3018 1
-
[35]
W. Weber. Text visualization - what colors tell about a text. In2007 11th International Conference Information Visualization (IV ’07), pp. 354–362, 2007. doi: 10.1109/IV.2007.108 2
-
[36]
Z. Yin, H. Wang, K. Horio, D. Kawahara, and S. Sekine. Should we respect LLMs? a cross-lingual study on the influence of prompt polite- ness on LLM performance. InProceedings of the Second Workshop on Social Influence in Conversations (SICon 2024), pp. 9–35, Nov
2024
-
[37]
doi: 10.18653/v1/2024.sicon-1.2 3
-
[38]
Yousef and S
T. Yousef and S. Janicke. A survey of text alignment visualiza- tion.IEEE transactions on visualization and computer graphics, 27(2):1149–1159, 2020. 2
2020
-
[39]
Zhang, H
W. Zhang, H. Cai, and W. Chen. Beyond the singular: Revealing the value of multiple generations in benchmark evaluation. InNeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Bench- marks, Emergent Abilities, and Scaling, 2025. 1
2025
-
[40]
Y . Zhou and B. Shbita. Evaluating ill-defined tasks in large language models. 03 2026. doi: 10.48550/arXiv.2603.17067 1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.