Scene-Adaptive Continual Learning for CSI-based Human Activity Recognition with Mixture of Experts
Pith reviewed 2026-05-08 12:37 UTC · model grok-4.3
The pith
A scene-adaptive mixture of experts with selective routing enables efficient continual learning for CSI-based human activity recognition across domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
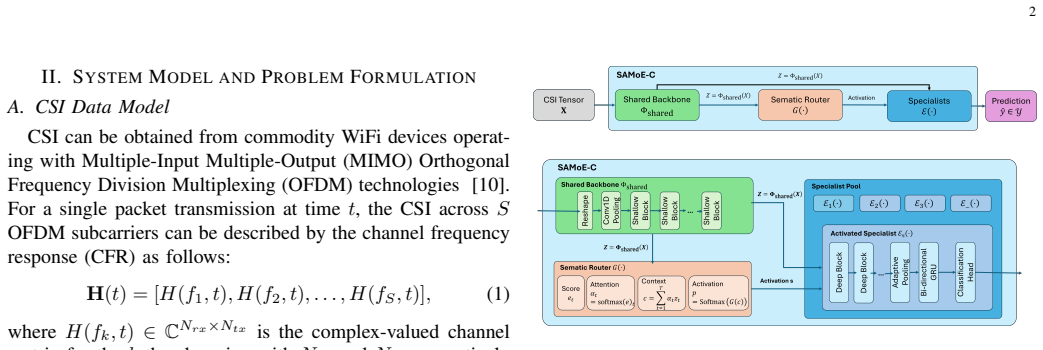
SAMoE-C formulates cross-domain CSI-based HAR as a mixture-of-experts system that enables scene-specific adaptation via an attention-based semantic router activating only selected experts for each input, trained with a novel protocol requiring only a tiny replay buffer, which on a four-scene CSI dataset approaches state-of-the-art accuracy while maintaining significantly lower inference cost.
What carries the argument
The Scene-Adaptive Mixture of Experts with Clustered Specialists (SAMoE-C), where an attention-based semantic router selectively activates modular experts for scene-specific adaptation.
Load-bearing premise
The attention-based semantic router can reliably discriminate scenes and activate the correct experts using only a tiny replay buffer, without the router itself suffering catastrophic forgetting or requiring scene labels at inference time.
What would settle it
Running the model on the four-scene CSI dataset or additional scenes where the router misclassifies scenes leading to accuracy significantly below state-of-the-art, or where inference cost does not remain lower.
Figures
read the original abstract
Channel state information (CSI)-based human activity recognition (HAR) is vulnerable to performance degradation under domain shifts across varying physical environments. Continual learning (CL) offers a principled way to learn new domains sequentially while preserving past knowledge, but existing CL solutions for CSI-based HAR scale poorly with accumulating domains, rely on a large replay buffer, or incur linearly growing inference cost. In this letter, we propose Scene-Adaptive Mixture of Experts with Clustered Specialists (SAMoE-C), which formulates cross-domain CSI-based HAR as a mixture-of-experts system that enables scene-specific adaptation, via an attention-based semantic router that activates only selected experts for each input. Moreover, we develop a novel training protocol, which requires only a tiny replay buffer for stabilizing domain discrimination of the router. Experimental results on a four-scene CSI dataset demonstrate that SAMoE-C approaches the state-of-the-art accuracy, while maintaining a significantly lower inference cost. By jointly combining modular experts, selective activation with router and a lightweight training protocol, SAMoE-C enables scalable cross-domain CSI-based HAR deployment with low training overhead and high computational efficiency in real-world settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAMoE-C, a mixture-of-experts architecture with clustered specialists and an attention-based semantic router for continual learning in CSI-based human activity recognition. It introduces a training protocol using only a tiny replay buffer to stabilize router domain discrimination, enabling scene-specific expert activation without scene labels at inference. Experiments on a four-scene CSI dataset are reported to approach state-of-the-art accuracy while achieving significantly lower inference cost than prior CL methods.
Significance. If the router's scene discrimination holds across sequential domains, the approach would provide a scalable, low-overhead solution for cross-domain CSI-HAR, addressing the poor scaling and high replay/inference costs of existing continual learning methods in wireless sensing. The combination of modular experts and selective activation is a practical strength for real-world deployment where computational efficiency matters.
major comments (1)
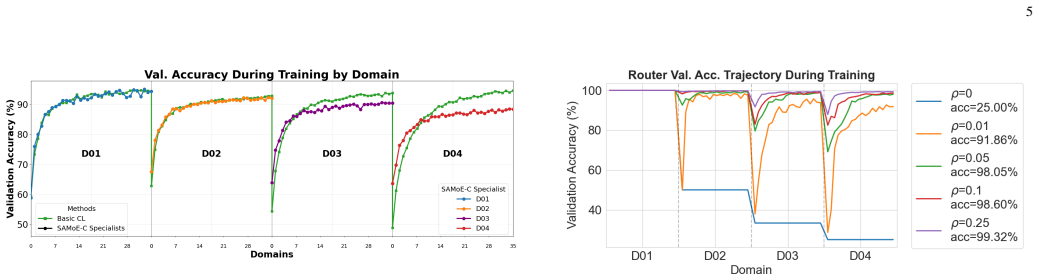
- [Abstract] Abstract: The headline claim of near-SOTA accuracy with lower inference cost is load-bearing on the attention-based semantic router reliably mapping inputs to the correct scene experts without scene labels at test time and without catastrophic forgetting as new scenes arrive. No router accuracy, mis-routing rate, or ablation on replay-buffer size is reported, leaving the central continual-learning benefit unverified even on the modest four-scene setup.
minor comments (2)
- The abstract refers to a 'four-scene CSI dataset' without naming the dataset, providing acquisition details, or citing prior work that introduced it; this information is needed for reproducibility.
- The terms 'Clustered Specialists' and 'attention-based semantic router' are introduced without a brief definition or reference to the relevant equations/figures in the abstract, which reduces immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to explicitly verify the router's scene discrimination and the continual learning benefits. We address the major comment below and outline revisions to strengthen the presentation of these aspects.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of near-SOTA accuracy with lower inference cost is load-bearing on the attention-based semantic router reliably mapping inputs to the correct scene experts without scene labels at test time and without catastrophic forgetting as new scenes arrive. No router accuracy, mis-routing rate, or ablation on replay-buffer size is reported, leaving the central continual-learning benefit unverified even on the modest four-scene setup.
Authors: We acknowledge that the manuscript does not report explicit router accuracy, mis-routing rates, or a dedicated ablation on replay-buffer size, which would provide more direct verification of the router's role in the continual learning process. The current evaluation demonstrates the overall approach through end-to-end accuracy approaching state-of-the-art on the four-scene dataset while achieving substantially lower inference cost than prior methods; this outcome would be inconsistent with frequent mis-routing, as incorrect expert activation would degrade performance and increase effective cost. The training protocol with the tiny replay buffer is introduced specifically to stabilize router domain discrimination across sequential scenes without requiring scene labels at inference, and the modular expert design with frozen past specialists inherently limits catastrophic forgetting. To make these elements explicit and address the concern, we will revise the manuscript to include router accuracy metrics and a scene confusion matrix on the test set, a mis-routing analysis, and an ablation study on replay-buffer size showing its effect on router stability, overall accuracy, and forgetting. These additions will be placed in the experimental section and will not change the core claims or results. revision: yes
Circularity Check
No circularity: empirical results from proposed architecture and protocol
full rationale
The paper presents SAMoE-C as a new mixture-of-experts model with an attention-based semantic router and a lightweight training protocol using a tiny replay buffer. All performance claims (near-SOTA accuracy, reduced inference cost) are stated as outcomes of experiments on a four-scene CSI dataset. No derivation step reduces a result to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on a self-citation chain. The router's scene discrimination is presented as an empirical capability verified by the reported results rather than defined into existence.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of experts
- replay buffer size
axioms (2)
- domain assumption Attention mechanism can learn to route inputs to correct scene-specific experts without explicit scene labels at test time.
- domain assumption Tiny replay buffer suffices to prevent router forgetting across sequential scene arrivals.
invented entities (2)
-
Clustered Specialists
no independent evidence
-
Attention-based semantic router
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. Xiao, H. Li, M. Wu, H. Jin, M. J. Deen, and J. Cao, “A survey on wireless device-free human sensing: Application scenarios, current solutions, and open issues,”ACM Comput. Surv., vol. 55, no. 5, Dec. 2022
work page 2022
-
[2]
Cross-domain human activity recognition via domain adaptation and fused attention,
T. Zhu, Y . Dong, Y . Zhou, C. Zhu, and L. Cao, “Cross-domain human activity recognition via domain adaptation and fused attention,”IEEE JBHI, vol. 29, no. 8, pp. 5394–5404, 2025
work page 2025
-
[3]
Transfer Learning in Human Activity Recognition: A Survey,
S. G. Dhekane and T. Ploetz, “Transfer Learning in Human Activity Recognition: A Survey,”arXiv preprint arXiv:2401.10185, 2024
-
[4]
Transfer learning for activity recognition: a survey,
D. Cook, K. D. Feuz, and N. C. Krishnan, “Transfer learning for activity recognition: a survey,”Knowl. Inf. Syst., vol. 36, pp. 537–556, 2013
work page 2013
-
[5]
Domain-adversarial training of neural networks,
Y . Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Lavio- lette, M. Marchand, and V . Lempitsky, “Domain-adversarial training of neural networks,”J. Mach. Learn. Res., vol. 17, no. 59, pp. 1–35, 2016
work page 2016
-
[6]
A statistical theory of regularization-based continual learning,
X. Zhao, H. Wang, W. Huang, and W. Lin, “A statistical theory of regularization-based continual learning,” inProc. Int. Conf. Mach. Learn. (ICML), 2024
work page 2024
-
[7]
iCaRL: Incremental classifier and representation learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “iCaRL: Incremental classifier and representation learning,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Honolulu, HI, USA, 2017
work page 2017
-
[8]
A model or 603 exemplars: Towards memory-efficient class-incremental learning,
D.-W. Zhou, Q.-W. Wang, H.-J. Ye, and D.-C. Zhan, “A model or 603 exemplars: Towards memory-efficient class-incremental learning,” inProc. Int. Conf. Learn. Represent. (ICLR), 2023
work page 2023
-
[9]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” inProc. Int. Conf. Learn. Represent. (ICLR), 2017
work page 2017
-
[10]
MIMO-OFDM wireless systems: basics, perspectives, and challenges,
H. B ¨olcskei, D. Gesbert, and A. J. Paulraj, “MIMO-OFDM wireless systems: basics, perspectives, and challenges,”IEEE Wireless Commun., vol. 13, no. 4, pp. 31–37, 2006
work page 2006
-
[11]
Optimal preprocessing of wifi csi for sensing applications,
V . V . Ratnam, H. Chen, H.-H. Chang, A. Sehgal, and J. Zhang, “Optimal preprocessing of wifi csi for sensing applications,”IEEE Transactions on Wireless Communications, vol. 23, no. 9, pp. 10 820–10 833, 2024
work page 2024
-
[12]
Learning strict identity mappings in deep residual networks,
X. Yu, Z. Yu, and S. Ramalingam, “Learning strict identity mappings in deep residual networks,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 4432–4440
work page 2018
-
[13]
Mm-Fi: A Multi-Modal Human-Computer Interaction Platform With Wi-Fi,
H. Wen, J. Zhang, D. Zhang, and X.-D. Yang, “Mm-Fi: A Multi-Modal Human-Computer Interaction Platform With Wi-Fi,”IEEE Internet Things J., vol. 10, no. 15, pp. 13 329–13 342, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.