Recognition: unknown
Hedging Memory Horizons for Non-Stationary Prediction via Online Aggregation
Pith reviewed 2026-05-08 12:24 UTC · model grok-4.3
The pith
Hedging across a grid of forgetting factors lets online predictors track unknown distribution shifts without external indicators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MELO competes with the best raw predictor and the best bounded time-varying affine combinations of the base predictions up to a path-length-dependent tracking cost and a sublinear aggregation overhead.
What carries the argument
MELO procedure that hedges a fixed grid of forgetting factors by running parallel EWLS adaptation experts on the base-predictor pool and then applies MLpol aggregation to the resulting raw and adapted forecasts.
If this is right
- Stable quiet-period performance is preserved while automatic adaptation occurs when regimes change.
- The method works with any existing non-anticipating base predictors without retraining or external regime indicators.
- Only lightweight recursive updates are needed at each time step.
- The same hedging idea can be applied to other online aggregation rules beyond MLpol.
Where Pith is reading between the lines
- The approach may extend naturally to other drifting environments such as financial returns or sensor streams where the right memory length is unknown in advance.
- If the true shift dynamics are much faster or slower than the chosen grid, performance may degrade and a data-driven grid selection step could become necessary.
- Pairing MELO with stronger modern base predictors could compound the observed error reductions.
Load-bearing premise
Predictions and outcomes stay bounded, base predictors are non-anticipating, and a fixed discrete grid of forgetting factors is sufficient to track arbitrary unknown regime shifts.
What would settle it
On a bounded synthetic stream with abrupt, sustained shifts whose optimal memory length lies outside the chosen forgetting grid, MELO should show no RMSE improvement over the single best fixed forgetting factor.
Figures




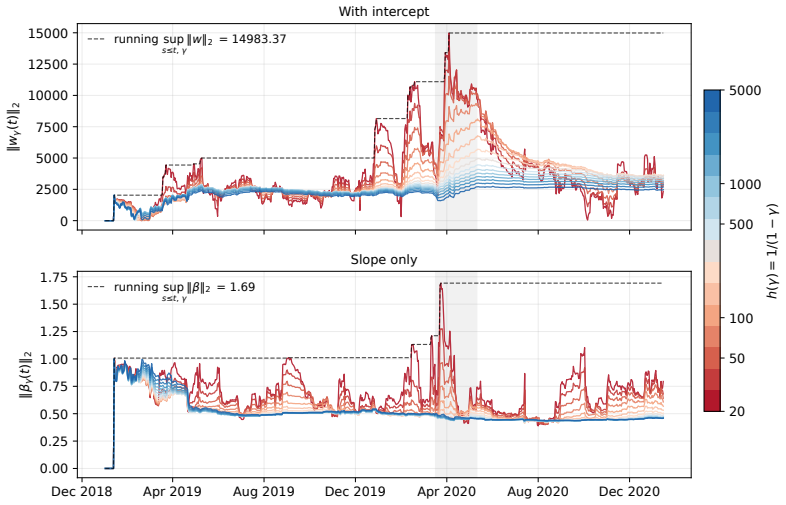









read the original abstract
We study online prediction under distribution shift, where inputs arrive chronologically and outcomes are revealed only after prediction. In this setting, predictors must remain stable in quiet regimes yet adapt when regimes shift, and the right adaptation memory is unknown in advance. We propose MELO (Memory-hedged Exponentially Weighted Least-Squares Online aggregation), a model-agnostic method that hedges across adaptation scales: it wraps any non-anticipating base-predictor pool with exponentially weighted least-squares (EWLS) adaptation experts at multiple forgetting factors, and aggregates raw and EWLS-adapted forecasts with MLpol, a parameter-free online aggregation rule. Under boundedness conditions, we establish deterministic oracle inequalities showing that it competes with both the best raw predictor and the best bounded, time-varying affine combinations of the base predictions, up to a path-length-dependent tracking cost and a sublinear aggregation overhead. We evaluate MELO on French national electricity-load forecasting through the COVID-19 lockdown using no regime indicators, lockdown dates, or policy covariates. MELO reduces overall RMSE by 34.7\% relative to base-only MLpol and achieves lower overall RMSE than a TabICL reference supplied with an external COVID policy-response covariate. Moreover, MELO requires only lightweight per-step recursive updates without model retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MELO, a model-agnostic online aggregation method that wraps non-anticipating base predictors with exponentially weighted least-squares (EWLS) experts at a grid of forgetting factors and aggregates the raw and adapted forecasts via MLpol. Under boundedness assumptions it establishes deterministic oracle inequalities showing competition with both the best raw predictor and the best bounded time-varying affine combination of the bases, up to a path-length-dependent tracking cost plus sublinear aggregation overhead. On French national electricity-load data during the COVID-19 period, MELO achieves a 34.7% RMSE reduction relative to base-only MLpol and outperforms a TabICL reference that receives an external policy covariate.
Significance. If the oracle inequalities hold as stated, the work supplies a practical, parameter-light way to hedge unknown adaptation memory in non-stationary online prediction without external change indicators. The deterministic (non-probabilistic) nature of the bounds, the explicit path-length term, and the real-data evaluation on a regime-shift episode without post-hoc selection are clear strengths. The approach sits at the intersection of online aggregation and adaptive filtering and could be useful wherever memory horizons are unknown a priori.
major comments (2)
- [Abstract and §3] Abstract and §3 (MELO construction): the stated oracle inequality competes with the best bounded time-varying affine combination of the base predictors up to a path-length term. However, MELO realizes the competition by hedging only over a fixed finite grid of EWLS forgetting factors. No discretization-error analysis or grid-density guarantee is supplied; an optimal forgetting factor lying between or outside the grid points incurs an extra approximation error that is not absorbed into the path-length cost and can therefore make the realized regret exceed the claimed bound.
- [§4] §4 (empirical study): the reported 34.7% RMSE reduction is measured against base-only MLpol on a single COVID-era electricity series. No ablation or sensitivity table is given for grid range, spacing, or number of forgetting factors, leaving open the possibility that performance is sensitive to the particular discretization chosen for that dataset.
minor comments (2)
- [Theorem statement] The notation for the path-length functional (variation of the combination weights) should be given an explicit equation number in the statement of the main theorem so that readers can verify how it interacts with the discretization.
- [§4] A short paragraph clarifying that the boundedness assumptions are verified (or approximately satisfied) on the electricity-load series would help readers assess applicability.
Simulated Author's Rebuttal
We thank the referee for the constructive report and positive overall assessment. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (MELO construction): the stated oracle inequality competes with the best bounded time-varying affine combination of the base predictors up to a path-length term. However, MELO realizes the competition by hedging only over a fixed finite grid of EWLS forgetting factors. No discretization-error analysis or grid-density guarantee is supplied; an optimal forgetting factor lying between or outside the grid points incurs an extra approximation error that is not absorbed into the path-length cost and can therefore make the realized regret exceed the claimed bound.
Authors: We agree that the current statement of the oracle inequality requires clarification. The bound holds with respect to the best time-varying affine combination whose forgetting factor lies within the finite grid employed by MELO; the path-length term controls variation of the combination weights but does not explicitly bound the additional approximation error incurred when the optimal forgetting factor falls between or outside grid points. In the revised manuscript we will (i) restate the theorem to make the grid restriction explicit and (ii) add a short paragraph discussing practical grid selection (e.g., a geometrically spaced grid over [0,1] with spacing chosen so that the induced approximation error is absorbed into the existing sub-linear term for typical path lengths). This change does not alter the deterministic nature of the bounds or the practical algorithm. revision: yes
-
Referee: [§4] §4 (empirical study): the reported 34.7% RMSE reduction is measured against base-only MLpol on a single COVID-era electricity series. No ablation or sensitivity table is given for grid range, spacing, or number of forgetting factors, leaving open the possibility that performance is sensitive to the particular discretization chosen for that dataset.
Authors: We acknowledge that the empirical evaluation would be strengthened by sensitivity analysis. In the revised version we will add a table (or set of plots) that reports RMSE for the same French electricity series under different grid configurations: varying the number of forgetting factors (e.g., 5, 10, 20), the range (e.g., [0.01,0.99] vs. [0.001,0.999]), and the spacing (linear vs. geometric). The table will also include the performance of the single best grid point chosen ex post, thereby quantifying the benefit of hedging versus using a fixed forgetting factor. These results will be obtained with the same experimental protocol already described. revision: yes
Circularity Check
No circularity: oracle inequalities are external and derivation is self-contained
full rationale
The paper establishes deterministic oracle inequalities bounding MELO's regret against the best raw base predictor and the best bounded time-varying affine combination of the base predictions, with explicit additive terms for path-length tracking cost and sublinear MLpol aggregation overhead. These bounds are derived from standard online learning techniques under stated boundedness assumptions and do not reduce to any fitted parameter, self-defined quantity, or prior self-citation by construction. The fixed grid of EWLS forgetting factors is an explicit algorithmic choice whose discretization effect is absorbed into the path-length term rather than presupposed; the empirical RMSE reduction on real electricity data is an independent validation, not a tautological fit. No load-bearing step collapses to renaming or self-referential input.
Axiom & Free-Parameter Ledger
free parameters (1)
- forgetting factors grid
axioms (1)
- domain assumption Boundedness conditions on the loss and predictions
Reference graph
Works this paper leans on
-
[1]
1983 , publisher=
Theory and practice of recursive identification , author=. 1983 , publisher=
1983
-
[2]
2006 , publisher=
Prediction, learning, and games , author=. 2006 , publisher=
2006
-
[3]
Journal of Basic Engineering , year=
A New Approach to Linear Filtering and Prediction Problems , author=. Journal of Basic Engineering , year=
-
[4]
COLT , year=
A second-order bound with excess losses , author=. COLT , year=
-
[5]
Introduction to Online Convex Optimization , author=
-
[6]
The Thirteenth International Conference on Learning Representations , year=
TabM: Advancing tabular deep learning with parameter-efficient ensembling , author=. The Thirteenth International Conference on Learning Representations , year=
-
[7]
Proceedings of the 38th International Conference on Machine Learning , pages =
Leveraging Good Representations in Linear Contextual Bandits , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[8]
A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting , journal =. 1997 , issn =. doi:https://doi.org/10.1006/jcss.1997.1504 , url =
-
[9]
1996 , publisher=
Statistical digital signal processing and modeling , author=. 1996 , publisher=
1996
-
[10]
1990 , publisher=
Forecasting, structural time series models and the Kalman filter , author=. 1990 , publisher=
1990
-
[11]
Proceedings of the AAAI conference on artificial intelligence , volume=
Informer: Beyond efficient transformer for long sequence time-series forecasting , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[12]
Advances in neural information processing systems , volume=
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting , author=. Advances in neural information processing systems , volume=
-
[13]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
A time series is worth 64 words: Long-term forecasting with transformers , author=. arXiv preprint arXiv:2211.14730 , year=
work page internal anchor Pith review arXiv
-
[14]
A NSTransformer-Based Carbon Emission Prediction Model for Transmission Line Project Construction , year=
Liu, Rui and Liu, Chao and Li, Shuzheng and Ma, Na , booktitle=. A NSTransformer-Based Carbon Emission Prediction Model for Transmission Line Project Construction , year=
-
[15]
International Conference on Learning Representations , year=
Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift , author=. International Conference on Learning Representations , year=
-
[16]
International Journal of Computer Vision , volume=
A comprehensive survey on test-time adaptation under distribution shifts , author=. International Journal of Computer Vision , volume=. 2025 , publisher=
2025
-
[17]
Shalev-Shwartz, Shai , title =. Foundations and Trends in Machine Learning , volume =. 2012 , month =. doi:10.1561/2200000018 , url =
-
[18]
The Journal of Machine Learning Research , volume=
Follow the leader if you can, hedge if you must , author=. The Journal of Machine Learning Research , volume=. 2014 , publisher=
2014
-
[19]
Machine Learning , volume=
Optimal learning with Bernstein online aggregation , author=. Machine Learning , volume=. 2017 , publisher=
2017
-
[20]
Machine learning , volume=
Tracking the best expert , author=. Machine learning , volume=. 1998 , publisher=
1998
-
[21]
Machine learning , volume=
Selective sampling using the query by committee algorithm , author=. Machine learning , volume=. 1997 , publisher=
1997
-
[22]
2003 , publisher=
Fundamentals of adaptive filtering , author=. 2003 , publisher=
2003
-
[23]
IEEE Open Access Journal of Power and Energy , volume=
State-space models for online post-covid electricity load forecasting competition , author=. IEEE Open Access Journal of Power and Energy , volume=. 2022 , publisher=
2022
-
[24]
1979 , publisher =
Optimal Filtering , author =. 1979 , publisher =
1979
-
[25]
2008 , doi =
A robust variable forgetting factor recursive least-squares algorithm for system identification , author =. 2008 , doi =
2008
-
[26]
IEEE Transactions on Automatic Control , volume =
Approaches to adaptive filtering , author =. IEEE Transactions on Automatic Control , volume =. 1972 , publisher =
1972
-
[27]
Learning an Outlier-Robust
Ting, Jo-Anne and Theodorou, Evangelos and Schaal, Stefan , booktitle =. Learning an Outlier-Robust. 2007 , publisher =
2007
-
[28]
Gradient-based variable forgetting factor
Leung, Shun-Hung and So, Ching-Fong , journal =. Gradient-based variable forgetting factor. 2005 , doi =
2005
-
[29]
International Conference on Learning Representations (
Efficiently Modeling Long Sequences with Structured State Spaces , author =. International Conference on Learning Representations (. 2022 , url =
2022
-
[30]
and van der Hoeven, Dirk , title =
van Erven, Tim and Koolen, Wouter M. and van der Hoeven, Dirk , title =. Journal of Machine Learning Research , volume =
-
[31]
Proceedings of the 20th International Conference on Machine Learning (ICML) , pages =
Zinkevich, Martin , title =. Proceedings of the 20th International Conference on Machine Learning (ICML) , pages =
-
[32]
Advances in Neural Information Processing Systems 31 (NeurIPS) , pages =
Zhang, Lijun and Lu, Shiyin and Zhou, Zhi-Hua , title =. Advances in Neural Information Processing Systems 31 (NeurIPS) , pages =
-
[33]
and Granger, Clive W
Bates, John M. and Granger, Clive W. J. , title =. Journal of the Operational Research Society , volume =. 1969 , doi =
1969
-
[34]
Handbook of Economic Forecasting, Volume 1 , editor =
Timmermann, Allan , title =. Handbook of Economic Forecasting, Volume 1 , editor =
-
[35]
Hashem and Pettenuzzo, Davide and Timmermann, Allan , title =
Pesaran, M. Hashem and Pettenuzzo, Davide and Timmermann, Allan , title =. The Review of Economic Studies , volume =. 2006 , doi =
2006
-
[36]
Hashem and Pick, Andreas and Pranovich, Mikhail , title =
Pesaran, M. Hashem and Pick, Andreas and Pranovich, Mikhail , title =. Journal of Econometrics , volume =. 2013 , doi =
2013
-
[37]
Raftery, Adrian E. and K. Online prediction under model uncertainty via dynamic model averaging: Application to a cold rolling mill , journal =. 2010 , doi =
2010
-
[38]
International Economic Review , volume =
Koop, Gary and Korobilis, Dimitris , title =. International Economic Review , volume =. 2012 , doi =
2012
-
[39]
Journal of Econometrics , volume =
Giraitis, Liudas and Kapetanios, George and Price, Simon , title =. Journal of Econometrics , volume =. 2013 , doi =
2013
-
[40]
Machine Learning , volume =
Devaine, Marie and Gaillard, Pierre and Goude, Yannig and Stoltz, Gilles , title =. Machine Learning , volume =. 2013 , doi =
2013
-
[41]
Modeling and Stochastic Learning for Forecasting in High Dimensions , editor =
Gaillard, Pierre and Goude, Yannig , title =. Modeling and Stochastic Learning for Forecasting in High Dimensions , editor =. 2015 , doi =
2015
-
[42]
IEEE Transactions on Power Systems , volume =
Obst, David and de Vilmarest, Joseph and Goude, Yannig , title =. IEEE Transactions on Power Systems , volume =. 2021 , doi =
2021
-
[43]
Nature human behaviour , volume=
A global panel database of pandemic policies (Oxford COVID-19 Government Response Tracker) , author=. Nature human behaviour , volume=. 2021 , publisher=
2021
-
[44]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[45]
The Annals of Statistics , volume=
The jackknife and the bootstrap for general stationary observations , author=. The Annals of Statistics , volume=
-
[46]
Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
Optuna: A next-generation hyperparameter optimization framework , author=. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
-
[47]
Econometrica , volume=
A simple adaptive procedure leading to correlated equilibrium , author=. Econometrica , volume=. 2000 , publisher=
2000
-
[48]
Statistical Inference for Stochastic Processes , volume =
de Vilmarest, Joseph and Wintenberger, Olivier , title =. Statistical Inference for Stochastic Processes , volume =. 2024 , doi =
2024
-
[49]
IEEE Transactions on Automatic Control , volume =
Huang, Yulong and Zhang, Yonggang and Wu, Zhemin and Li, Ning and Chambers, Jonathon , title =. IEEE Transactions on Automatic Control , volume =. 2018 , doi =
2018
-
[50]
Blom, Henk A. P. and Bar-Shalom, Yaakov , title =. IEEE Transactions on Automatic Control , volume =. 1988 , doi =
1988
-
[51]
Advances in Neural Information Processing Systems , editor =
Moulines, Eric and Bach, Francis , title =. Advances in Neural Information Processing Systems , editor =. 2011 , publisher =
2011
-
[52]
Concentration Inequalities: A Nonasymptotic Theory of Independence , publisher =
Boucheron, St. Concentration Inequalities: A Nonasymptotic Theory of Independence , publisher =. 2013 , isbn =
2013
-
[53]
Advances in Neural Information Processing Systems , volume=
Revisiting Deep Learning Models for Tabular Data , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Advances in Neural Information Processing Systems , volume =
OneNet: Enhancing Time Series Forecasting Models under Concept Drift by Online Ensembling , author =. Advances in Neural Information Processing Systems , volume =. 2023 , pages =
2023
-
[55]
Advances in Neural Information Processing Systems , volume =
Online Time Series Forecasting with Theoretical Guarantees , author =. Advances in Neural Information Processing Systems , volume =. 2025 , url =
2025
-
[56]
International Conference on Learning Representations , year =
Fast and Slow Streams for Online Time Series Forecasting Without Information Leakage , author =. International Conference on Learning Representations , year =
-
[57]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining , series =
Proactive Model Adaptation Against Concept Drift for Online Time Series Forecasting , author =. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining , series =. 2025 , pages =. doi:10.1145/3690624.3709210 , url =
-
[58]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Battling the Non-stationarity in Time Series Forecasting via Test-time Adaptation , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2025 , pages =
2025
-
[59]
Advances in Neural Information Processing Systems , volume =
Improving Time Series Forecasting via Instance-aware Post-hoc Revision , author =. Advances in Neural Information Processing Systems , volume =
-
[60]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Lightweight Online Adaption for Time Series Foundation Model Forecasts , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[61]
International Conference on Learning Representations , year=
TabReD: Analyzing Pitfalls and Filling the Gaps in Tabular Deep Learning Benchmarks , author=. International Conference on Learning Representations , year=
-
[62]
Advances in Neural Information Processing Systems , year=
On Embeddings for Numerical Features in Tabular Deep Learning , author=. Advances in Neural Information Processing Systems , year=
-
[63]
KDD , year=
XGBoost: A Scalable Tree Boosting System , author=. KDD , year=
-
[64]
NeurIPS , year=
LightGBM: A Highly Efficient Gradient Boosting Decision Tree , author=. NeurIPS , year=
-
[65]
ICLR , year=
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second , author=. ICLR , year=
-
[66]
Jingang Qu and David Holzm. Tab. Forty-second International Conference on Machine Learning , year=
-
[67]
ACM Computing Surveys , volume =
A Survey on Concept Drift Adaptation , author =. ACM Computing Surveys , volume =. 2014 , publisher =
2014
-
[68]
Proceedings of the 2007 SIAM International Conference on Data Mining , pages =
Learning from Time-Changing Data with Adaptive Windowing , author =. Proceedings of the 2007 SIAM International Conference on Data Mining , pages =. 2007 , publisher =
2007
-
[69]
Machine Learning and Knowledge Discovery in Databases , pages =
Adaptive Random Forests for Evolving Data Stream Classification , author =. Machine Learning and Knowledge Discovery in Databases , pages =. 2017 , publisher =
2017
-
[70]
Additive Models and Robust Aggregation for
Gaillard, Pierre and Goude, Yannig and Nedellec, Rapha\". Additive Models and Robust Aggregation for. International Journal of Forecasting , year =
-
[71]
Local Short and Middle Term Electricity Load Forecasting with Semi-Parametric Additive Models , journal =
Goude, Yannig and Nedellec, Rapha\". Local Short and Middle Term Electricity Load Forecasting with Semi-Parametric Additive Models , journal =. 2014 , volume =
2014
-
[72]
and Kennard, Robert W
Hoerl, Arthur E. and Kennard, Robert W. , title =. Technometrics , year =
-
[73]
, title =
Wood, Simon N. , title =
-
[74]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , title =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[75]
Statistical Science , year =
Hastie, Trevor and Tibshirani, Robert , title =. Statistical Science , year =
-
[76]
Adaptive Methods for Short-Term Electricity Load Forecasting During COVID-19 Lockdown in France , year=
Obst, David and de Vilmarest, Joseph and Goude, Yannig , journal=. Adaptive Methods for Short-Term Electricity Load Forecasting During COVID-19 Lockdown in France , year=
-
[77]
and Watson, Mark W
Stock, James H. and Watson, Mark W. , title =. Journal of Forecasting , year =
-
[78]
Journal of Machine Learning Research , volume =
Tracking the Best Linear Predictor , author =. Journal of Machine Learning Research , volume =
-
[79]
Warmuth , title =
Olivier Bousquet and Manfred K. Warmuth , title =. Journal of Machine Learning Research , volume =
-
[80]
Advances in Neural Information Processing Systems 25 (NeurIPS) , year =
Nicol\`o Cesa-Bianchi and Pierre Gaillard and G\'abor Lugosi and Gilles Stoltz , title =. Advances in Neural Information Processing Systems 25 (NeurIPS) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.