Recognition: no theorem link
Continuous First, Discrete Later: VQ-VAEs Without Dimensional Collapse
Pith reviewed 2026-05-13 01:21 UTC · model grok-4.3
The pith
Training VQ-VAEs first as continuous autoencoders prevents dimensional collapse and raises final performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Dimensional collapse in VQ-VAEs is caused by the quantizer suppressing lower-variance directions, which imposes a hard loss floor independent of codebook improvements. A warm-up phase that first optimizes the model as an unquantized autoencoder allows the encoder to learn higher-rank representations; switching to VQ-VAE training afterward preserves much of that rank, yielding higher effective dimension and lower final loss.
What carries the argument
The AE warm-up phase that trains the model as a continuous autoencoder before vector quantization is introduced, allowing full-dimensional latent capture prior to discrete suppression.
If this is right
- Effective codebook dimension rises from 3-5 to 17-19 on VQGAN and from 4 to 17-19 on WavTokenizer across tested sizes.
- Reconstruction and perceptual losses improve, with rFID dropping 17-35 percent on images and PESQ rising 11-14 percent on audio at fixed training budget.
- Downstream performance becomes predictable from warm-up duration, enabling an adaptive rule for when to introduce quantization.
- The benefit appears consistently across codebook cardinalities from 2^10 to 2^16.
Where Pith is reading between the lines
- The same continuous-first ordering could be tested in other discrete latent architectures such as vector-quantized diffusion models to check whether collapse is similarly mitigated.
- If the rate-distortion account generalizes, analogous warm-up periods might address rank collapse in non-quantized high-dimensional representation learners.
- The functional dependence of final loss on warm-up length supplies a practical knob for trading compute between continuous and discrete stages without exhaustive search.
Load-bearing premise
Dimensional collapse remains the dominant source of the observed loss bound and the switch to quantization after warm-up introduces no new optimization failures or hyperparameter retuning needs.
What would settle it
Measure the effective dimension of the codebook after a sufficiently long warm-up; if it stays below roughly 10 and the reconstruction loss fails to drop below the previously reported floor on the same architecture and data, the mechanism does not hold.
Figures












read the original abstract
While many approaches to improve VQ-VAE performance focus on codebook size and utilization, the effect of dimensional collapse, where trained VQ-VAE representations live in an extremely low-dimensional subspace (1-2% of full rank), remains unaddressed. We show theoretically and empirically that dimension collapse causes a hard loss lower bound that various codebook improvement techniques fail to surpass. Our analytic framework extends the sequential learning effect of Saxe et al. [2014] by introducing ideas from rate-distortion theory and explains how the latent collapse is caused by the VQ suppressing lower-variance directions. Our theory justifies a simple solution: a "warm-up phase" that trains the model as an (unquantized) autoencoder before introducing VQ. On both synthetic experiments and large-scale image (VQGAN) and audio (WavTokenizer) VQ-VAEs, we show that AE Warm-Up successfully restores representation dimension, leading to lower reconstruction and perceptual loss at the same training budget. Across codebook sizes $K \in$ {$2^{10}, 2^{14}, 2^{16}$}, AE warm-up raises VQGAN codebook effective dimension from 3-5 to 17-19 and reduces rFID by 17-35%; on WavTokenizer at $K \in$ {$2^{13}, 2^{14}$}, it raises codebook dimension from 4 to 17-19 and improves PESQ by 11-14%. We empirically characterize how warm-up duration governs the achievable final loss. In agreement with experiment, our theoretical analysis predicts downstream performance as a function of warm-up length, enabling an adaptive criterion for switching from AE Warm-up to VQ-VAE training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that dimensional collapse in VQ-VAEs—where learned representations occupy an extremely low-dimensional subspace—imposes a hard lower bound on reconstruction loss that codebook-focused techniques cannot overcome. It extends the sequential learning analysis of Saxe et al. (2014) using rate-distortion theory to argue that vector quantization suppresses lower-variance latent directions, and proposes a simple 'AE warm-up' phase (unquantized autoencoder training before introducing VQ) as a remedy. Large-scale experiments on VQGAN (images) and WavTokenizer (audio) show that warm-up increases effective codebook dimension (e.g., 3-5 to 17-19) and yields concrete gains (rFID reduced 17-35%, PESQ improved 11-14%) across codebook sizes, with the theory predicting final performance as a function of warm-up length.
Significance. If the theoretical mechanism is shown to hold beyond the linear case, the work provides a low-overhead, theoretically motivated fix for a pervasive issue in discrete latent models, backed by reproducible large-scale gains on standard benchmarks. The predictive link between warm-up duration and downstream loss, plus explicit dimension measurements, strengthens the contribution over purely empirical codebook fixes.
major comments (2)
- [analytic framework] The analytic framework section: the extension of Saxe et al. (2014) via rate-distortion ideas to nonlinear VQ-VAEs (including commitment loss, stop-gradient, and EMA/k-means codebook updates) lacks explicit equations deriving the hard loss lower bound or the quantitative dependence of effective dimension on warm-up length. This is load-bearing for the central causal claim and for using the theory to justify the warm-up schedule over an optimization artifact.
- [experiments] Experimental results (abstract and § on VQGAN/WavTokenizer): reported rFID/PESQ gains and dimension jumps (3-5 to 17-19) are given without error bars, multiple random seeds, or ablation on whether warm-up requires retuning of other hyperparameters (e.g., learning rate, commitment weight). This weakens verification that the observed scaling matches the predicted warm-up dependence.
minor comments (1)
- [abstract] The abstract states the theory 'predicts downstream performance as a function of warm-up length' but does not reference the specific functional form or fitting procedure used to obtain the adaptive switching criterion.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [analytic framework] The analytic framework section: the extension of Saxe et al. (2014) via rate-distortion ideas to nonlinear VQ-VAEs (including commitment loss, stop-gradient, and EMA/k-means codebook updates) lacks explicit equations deriving the hard loss lower bound or the quantitative dependence of effective dimension on warm-up length. This is load-bearing for the central causal claim and for using the theory to justify the warm-up schedule over an optimization artifact.
Authors: We agree that additional explicit derivations would improve the clarity and rigor of the analytic framework. In the revised manuscript, we will expand this section with step-by-step equations that derive the hard loss lower bound using rate-distortion principles applied to the VQ-VAE objective. We will also provide a quantitative characterization of how effective dimension scales with warm-up length, explicitly incorporating the nonlinear effects of the commitment loss, stop-gradient operation, and EMA/k-means codebook updates. These additions will more clearly distinguish the proposed mechanism from potential optimization artifacts. revision: yes
-
Referee: [experiments] Experimental results (abstract and § on VQGAN/WavTokenizer): reported rFID/PESQ gains and dimension jumps (3-5 to 17-19) are given without error bars, multiple random seeds, or ablation on whether warm-up requires retuning of other hyperparameters (e.g., learning rate, commitment weight). This weakens verification that the observed scaling matches the predicted warm-up dependence.
Authors: We concur that reporting statistical variability and conducting targeted ablations would strengthen the experimental claims. In the revision, we will augment the results with error bars computed over multiple random seeds (minimum of three), and we will include an ablation study that evaluates the warm-up procedure without retuning other hyperparameters such as learning rate or commitment weight. These changes will allow readers to better assess whether the observed performance scaling aligns with the theoretical predictions. revision: yes
Circularity Check
No significant circularity; derivation extends external reference without reduction to inputs by construction.
full rationale
The paper's central analytic framework extends the sequential learning effect from the external citation Saxe et al. [2014] by incorporating rate-distortion theory to explain how VQ suppresses lower-variance directions, leading to dimensional collapse and a hard loss lower bound. This is used to justify the AE warm-up phase as a solution, with the theory claimed to predict downstream performance as a function of warm-up length. No load-bearing steps reduce by definition or by fitting parameters to the target outputs; the warm-up duration is treated as a tunable hyperparameter validated empirically rather than derived tautologically. The cited Saxe et al. work is independent (linear networks), and the extension introduces new rate-distortion elements without self-citation chains or ansatz smuggling. Empirical results on VQGAN and WavTokenizer are presented separately from the theory, with no evidence that predictions are forced by construction from the inputs. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- warm-up duration
axioms (2)
- domain assumption The sequential learning effect identified by Saxe et al. (2014) applies to the encoder-decoder dynamics under VQ.
- domain assumption Rate-distortion theory can be used to derive a hard lower bound on reconstruction loss once dimensional collapse occurs.
Reference graph
Works this paper leans on
-
[1]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint arXiv:2410.00037,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jukebox: A Generative Model for Music
Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, and Ilya Sutskever. Jukebox: A generative model for music.arXiv preprint arXiv:2005.00341,
work page Pith review arXiv 2005
-
[3]
Jong Wook Kim, Justin Salamon, Peter Li, and Juan Pablo Bello
arXiv:2408.16532. Jong Wook Kim, Justin Salamon, Peter Li, and Juan Pablo Bello. CREPE: A convolutional repre- sentation for pitch estimation. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 161–165,
-
[4]
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. InComputer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI, page 776–794, Berlin, Heidelberg,
work page 2020
-
[5]
URLhttps://doi.org/10.1007/978-3-030-58621-8_45
1007/978-3-030-58621-8_45. URLhttps://doi.org/10.1007/978-3-030-58621-8_45. Aäron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30,
-
[6]
Yuqing Wang, Zhijie Lin, Yao Teng, Yuanzhi Zhu, Shuhuai Ren, Jiashi Feng, and Xihui Liu. Bridging continuous and discrete tokens for autoregressive visual generation.arXiv preprint arXiv:2503.16430,
-
[7]
Wenhao Zhao, Qiran Zou, Rushi Shah, Yudi Wu, Zhouhan Lin, and Dianbo Liu. Early quan- tization shrinks codebook: A simple fix for diversity-preserving tokenization.arXiv preprint arXiv:2603.17052,
-
[8]
Representation collapsing problems in vector quantization.arXiv preprint arXiv:2411.16550,
Wentao Zhao, Zijie Liu, Songlin Chen, Xiangyun Cao, and Guanghui He. Representation collapsing problems in vector quantization.arXiv preprint arXiv:2411.16550,
-
[9]
A Proofs for Section 3 A.1 Dense RD-AE flow We derive (6)–(7) using the notation of Section 3.1
arXiv:2411.02038. A Proofs for Section 3 A.1 Dense RD-AE flow We derive (6)–(7) using the notation of Section 3.1. All channel parameters (cj, τ2 j , Dj, D⋆) are treated as constant throughout, consistent with the assumption that the quantizer remains optimal for the current latent statistics. 11 Channel in the eigenbasis.We denote the covariance matrix o...
-
[10]
Encoder reconstruction gradient under STE.The straight-through estimator redefines the back- ward pass to treat ∂zq,j /∂zj := 1 , while the forward pass uses the actual zq,j from the channel. Concretely, STE replaces zq,j with a surrogate zsurr q,j =z j + sg(zq,j −z j), which equals zq,j in value but has identity Jacobian in zj. Under this surrogate, the ...
work page 2025
-
[11]
At 128×128 input resolution each image is tokenized to an 8×8 grid of 64 discrete tokens
with the imagenet_vqgan.yaml configuration (128 base channels, multipliers [1,1,2,2,4] , two residual blocks per level, self-attention at 16×16 , 256-channel bottleneck, 256-dimensional codebook embedding space). At 128×128 input resolution each image is tokenized to an 8×8 grid of 64 discrete tokens. As per the original VQGAN training recipe, the discrim...
work page 2021
-
[12]
Cold-start baselines use the WavTokenizer default threshold of 1.0
Codebook respawn.We respawn codes whose EMA usage falls below a codebook-size-dependent threshold, aggregating usage counts across both GPUs each epoch for stability at large K. Cold-start baselines use the WavTokenizer default threshold of 1.0. Warm-start runs scale the threshold inversely withKto keep the expected number of respawned codes per epoch rou...
work page 2022
-
[13]
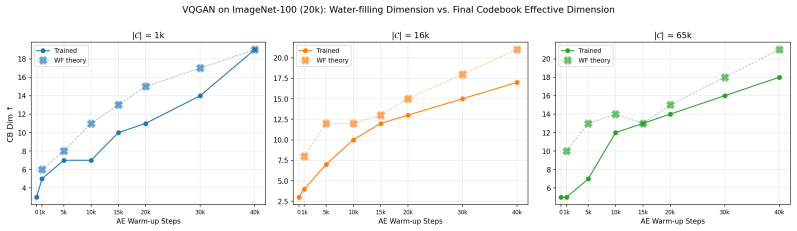
The number of PCA components whose eigenvalue exceeds D⋆ gives the predicted active-mode count 19 Figure 11:Water-filling on the AE latent spectrum upper-bounds the trained VQ-V AE codebook dimension.For each AE warm-up checkpoint Twu ∈ {0,1k,5k,10k,15k,20k,30k,40k} and each codebook size K∈ {2 10,2 14,2 16} (one panel per K), we compare the water-filling...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.