On the Divergence of Differential Temporal Difference Learning without Local Clocks
Pith reviewed 2026-05-11 00:56 UTC · model grok-4.3
The pith
Differential temporal difference learning converges with local clocks but can diverge with global clocks in average-reward reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We construct a counterexample showing that although differential temporal difference learning is convergent with a local clock, it can diverge with a global clock. This counterexample closes the open problem in Wan et al. [2021], Blaser et al. [2026].
What carries the argument
A finite-state average-reward MDP in which the global-clock differential TD update produces unbounded value estimates while the local-clock version, driven by per-state visit counts, converges.
If this is right
- Convergence guarantees for differential TD in average-reward RL require local clocks that track state visits rather than global time-based rates.
- The correspondence between local-clock and global-clock convergence that holds in discounted RL does not extend to average-reward RL.
- Practical implementations must maintain per-state visit counters to avoid divergence when using differential TD for undiscounted problems.
- Learning-rate schedules in average-reward settings cannot safely rely on a single global time index.
Where Pith is reading between the lines
- Similar clock-type sensitivities may appear in other average-reward algorithms such as differential Q-learning, suggesting targeted checks.
- In large or continuous state spaces the computational cost of exact local clocks may motivate approximate visit-count mechanisms.
- The counterexample MDP could be used as a test case when designing new average-reward methods or proving their convergence.
Load-bearing premise
The load-bearing premise is that there exists a particular finite-state MDP in which global-clock differential TD updates produce unbounded value estimates.
What would settle it
Simulate the global-clock differential TD algorithm on the paper's specific counterexample MDP and observe whether the value estimates remain bounded for all time or grow without limit.
Figures



read the original abstract
Learning rate is a critical component of reinforcement learning (RL). This work uses global and local clocks to distinguish two types of learning rates. The former is of the standard form $\alpha_t$ that depends only on the time step $t$ (i.e., a global clock). The latter is of the form $\alpha_{\nu(S_t, t)}$, where $\nu(s, t)$ counts the number of visits to state $s$ until time $t$ (i.e., a local clock). In discounted RL, an RL algorithm that is convergent with a local clock is always also convergent with a global clock, and vice versa. We are not aware of any counterexample. The key contribution of this work is to show that this nice correspondence breaks down in average-reward RL. Specifically, we construct a counterexample showing that although differential temporal difference learning is convergent with a local clock, it can diverge with a global clock. This counterexample closes the open problem in Wan et al. [2021], Blaser et al. [2026].
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs a finite-state MDP counterexample in the average-reward setting showing that differential temporal difference learning converges when learning rates are scheduled by local clocks (visit counts ν(s,t)) but diverges under global clocks (standard time-step schedules α_t). This separation does not occur in discounted RL and is claimed to resolve an open question from Wan et al. (2021) and Blaser et al. (2026).
Significance. If the counterexample is valid and the MDP satisfies the standard regularity conditions (communicating or unichain structure) under which local-clock convergence is known to hold, the result would be significant: it would establish a fundamental distinction between average-reward and discounted settings regarding the necessity of local clocks for convergence of differential TD, with direct implications for algorithm design and analysis in average-reward RL.
major comments (2)
- [counterexample construction (likely §3 or Theorem 1)] The central claim rests on the existence of a specific MDP where local-clock differential TD converges while the global-clock version produces unbounded estimates. The manuscript must explicitly verify that this MDP satisfies the unichain or communicating conditions required for the local-clock convergence theorem to apply (see the statement of the open problem being closed). Without this verification, the separation may be invalid because the differential value function could be ill-defined or the local-clock result may not hold.
- [proof of divergence (global clock) and convergence (local clock)] The proof of divergence under global clocks and convergence under local clocks should be checked for dependence on any additional assumptions (e.g., bounded rewards, finite states, or specific transition structure). If the construction relies on a non-ergodic MDP, the local-clock convergence claim would need separate justification beyond citing prior work.
minor comments (2)
- [preliminaries] Clarify the precise definition of the differential value function and the update rule for differential TD in the average-reward case, including how the average reward estimate is handled.
- [counterexample] Add a table or diagram summarizing the MDP transition probabilities, rewards, and the behavior of both clock variants to aid readability of the counterexample.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below and commit to revisions that strengthen the presentation of the counterexample and its assumptions.
read point-by-point responses
-
Referee: The central claim rests on the existence of a specific MDP where local-clock differential TD converges while the global-clock version produces unbounded estimates. The manuscript must explicitly verify that this MDP satisfies the unichain or communicating conditions required for the local-clock convergence theorem to apply (see the statement of the open problem being closed). Without this verification, the separation may be invalid because the differential value function could be ill-defined or the local-clock result may not hold.
Authors: We agree that explicit verification strengthens the result. Our MDP is communicating: from any state s there exists a policy under which every other state s' is reachable with positive probability in finite time. This ensures the differential value function is well-defined up to an additive constant and that the local-clock convergence theorems cited from Wan et al. (2021) and Blaser et al. (2026) apply directly. In the revision we will add a short subsection (or paragraph in §3) that explicitly checks the communicating property via the transition graph and reachability arguments. revision: yes
-
Referee: The proof of divergence under global clocks and convergence under local clocks should be checked for dependence on any additional assumptions (e.g., bounded rewards, finite states, or specific transition structure). If the construction relies on a non-ergodic MDP, the local-clock convergence claim would need separate justification beyond citing prior work.
Authors: The construction uses a finite-state MDP with bounded rewards (in {0,1}) and a transition structure that is irreducible and aperiodic under the behavior policy, hence ergodic. The global-clock divergence argument relies only on these standard finite-state bounded-reward conditions and does not invoke non-ergodicity. Because the MDP is communicating, the local-clock convergence follows immediately from the cited prior theorems without extra assumptions. We will add a clarifying remark in the proof sections confirming that no additional assumptions beyond those stated in the open problem are used. revision: yes
Circularity Check
No circularity: explicit counterexample construction is self-contained
full rationale
The paper's central contribution is the explicit construction of a finite-state MDP demonstrating that differential TD learning converges under local clocks (ν(s,t)) but diverges under global clocks (α_t). This directly addresses and closes the open problem stated in the cited prior works (Wan et al. [2021], Blaser et al. [2026]) without any derivation that reduces by construction to fitted parameters, self-definitions, or load-bearing self-citations. The abstract and described structure contain no equations or steps where a claimed result is equivalent to its inputs; the result is an existence proof via counterexample rather than a predictive or uniqueness-based derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard average-reward MDP assumptions including existence of a constant average reward and differential value function.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
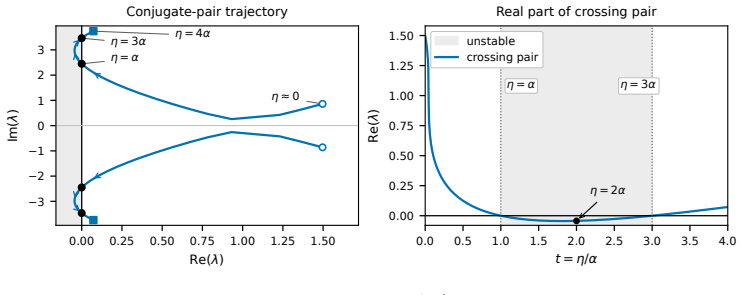
We construct a counterexample showing that although differential temporal difference learning is convergent with a local clock, it can diverge with a global clock. ... Aη is positive stable if and only if η∈(0,α)∪(3α,∞)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The ODE@∞ associated with differential TD with a global clock is dx(t)/dt = −Dμ(I−Pπ + ηee⊤)x(t). ... Aη can be viewed as a rank-one perturbation of a singular M-matrix
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning algorithms for markov decision processes with average cost
Jinane Abounadi, Dimitri Bertsekas, and Vivek S Borkar. Learning algorithms for markov decision processes with average cost. SIAM Journal on Control and Optimization , 2001
work page 2001
-
[2]
A note on a conjecture concerning rank one perturbations of singular m-matrices
B Anehila and ACM Ran. A note on a conjecture concerning rank one perturbations of singular m-matrices. Quaestiones Mathematicae, 2022
work page 2022
-
[3]
Richard Bellman. A markovian decision process. Journal of Mathematics and Mechanics, 1957
work page 1957
-
[4]
Dimitri P Bertsekas and John N Tsitsiklis. Neuro-Dynamic Programming. Athena Scientific Belmont, MA, 1996
work page 1996
-
[5]
Joris Bierkens and Andr \'e Ran. A singular M -matrix perturbed by a nonnegative rank one matrix has positive principal minors; is it D -stable? Linear Algebra and Its Applications, 2014
work page 2014
-
[6]
Asymptotic and finite sample analysis of nonexpansive stochastic approximations with markovian noise
Ethan Blaser and Shangtong Zhang. Asymptotic and finite sample analysis of nonexpansive stochastic approximations with markovian noise. In Proceedings of the AAAI Conference on Artificial Intelligence , 2026
work page 2026
-
[7]
Ethan Blaser, Jiuqi Wang, and Shangtong Zhang. Almost sure convergence of differential temporal difference learning for average reward markov decision processes. In Proceedings of the International Conference on Artificial Intelligence and Statistics, 2026
work page 2026
-
[8]
The ODE method for asymptotic statistics in stochastic approximation and reinforcement learning
Vivek Borkar, Shuhang Chen, Adithya Devraj, Ioannis Kontoyiannis, and Sean Meyn. The ODE method for asymptotic statistics in stochastic approximation and reinforcement learning. The Annals of Applied Probability, 2025
work page 2025
-
[9]
Stochastic approximation: a dynamical systems viewpoint
Vivek S Borkar. Stochastic approximation: a dynamical systems viewpoint. Springer, 2009
work page 2009
-
[10]
Non-asymptotic guarantees for average-reward Q -learning with adaptive stepsizes
Zaiwei Chen. Non-asymptotic guarantees for average-reward Q -learning with adaptive stepsizes. In Advances in Neural Information Processing Systems, 2025
work page 2025
-
[11]
A lyapunov theory for finite-sample guarantees of markovian stochastic approximation
Zaiwei Chen, Siva T Maguluri, Sanjay Shakkottai, and Karthikeyan Shanmugam. A lyapunov theory for finite-sample guarantees of markovian stochastic approximation. Operations Research, 2024
work page 2024
-
[12]
Eigenvalues of rank-one updated matrices with some applications
Jiu Ding and Aihui Zhou. Eigenvalues of rank-one updated matrices with some applications. Applied Mathematics Letters, 2007
work page 2007
-
[13]
On matrices with non-positive off-diagonal elements and positive principal minors
Miroslav Fiedler and Vlastimil Pták. On matrices with non-positive off-diagonal elements and positive principal minors. Czechoslovak Mathematical Journal, 1962
work page 1962
-
[14]
Rank one perturbations of h-positive real matrices
JH Fourie, GJ Groenewald, DB Janse van Rensburg, and ACM Ran. Rank one perturbations of h-positive real matrices. Linear Algebra and its Applications, 2013
work page 2013
- [15]
-
[16]
Convergence of stochastic iterative dynamic programming algorithms
Tommi Jaakkola, Michael Jordan, and Satinder Singh. Convergence of stochastic iterative dynamic programming algorithms. In Advances in Neural Information Processing Systems, 1993
work page 1993
-
[17]
A unified switching system perspective and convergence analysis of Q-Learning algorithms
Donghwan Lee and Niao He. A unified switching system perspective and convergence analysis of Q-Learning algorithms. In Advances in Neural Information Processing Systems, 2020
work page 2020
-
[18]
The ODE method for stochastic approximation and reinforcement learning with markovian noise
Shuze Liu, Shuhang Chen, and Shangtong Zhang. The ODE method for stochastic approximation and reinforcement learning with markovian noise. Journal of Machine Learning Research, 2025 a
work page 2025
-
[19]
Extensions of robbins-siegmund theorem with applications in reinforcement learning
Xinyu Liu, Zixuan Xie, and Shangtong Zhang. Extensions of robbins-siegmund theorem with applications in reinforcement learning. ArXiv Preprint, 2025 b
work page 2025
-
[20]
Linear Q -learning does not diverge in L ^2 : Convergence rates to a bounded set
Xinyu Liu, Zixuan Xie, and Shangtong Zhang. Linear Q -learning does not diverge in L ^2 : Convergence rates to a bounded set. In Proceedings of the International Conference on Machine Learning, 2025 c
work page 2025
-
[21]
Christian Mehl, Volker Mehrmann, Andr \'e CM Ran, and Leiba Rodman. Eigenvalue perturbation theory of classes of structured matrices under generic structured rank one perturbations. Linear Algebra and Its Applications, 2011
work page 2011
-
[22]
Christian Mehl, Volker Mehrmann, Andr \'e CM Ran, and Leiba Rodman. Eigenvalue perturbation theory of symplectic, orthogonal, and unitary matrices under generic structured rank one perturbations. BIT Numerical Mathematics, 2014
work page 2014
-
[23]
The projected bellman equation in reinforcement learning
Sean Meyn. The projected bellman equation in reinforcement learning. IEEE Transactions on Automatic Control, 2024
work page 2024
-
[24]
Low rank perturbation of jordan structure
Julio Moro and Froil \'a n M Dopico. Low rank perturbation of jordan structure. SIAM Journal on Matrix Analysis and Applications, 2003
work page 2003
- [25]
-
[26]
Eigenvalues of rank one perturbations of unstructured matrices
Andr \'e CM Ran and Micha Wojtylak. Eigenvalues of rank one perturbations of unstructured matrices. Linear Algebra and its Applications, 2012
work page 2012
-
[27]
Andr \'e CM Ran and Micha Wojtylak. Global properties of eigenvalues of parametric rank one perturbations for unstructured and structured matrices. Complex Analysis and Operator Theory, 2021
work page 2021
-
[28]
On the change in the spectral properties of a matrix under perturbations of sufficiently low rank
Sergey Valerievich Savchenko. On the change in the spectral properties of a matrix under perturbations of sufficiently low rank. Functional Analysis and Its Applications, 2004
work page 2004
-
[29]
Reinforcement Learning: An Introduction (2nd Edition)
Richard S Sutton and Andrew G Barto. Reinforcement Learning: An Introduction (2nd Edition). MIT press, 2018
work page 2018
-
[30]
Asynchronous stochastic approximation and Q-learning
John N Tsitsiklis. Asynchronous stochastic approximation and Q-learning . Machine Learning, 1994
work page 1994
-
[31]
Yi Wan, Abhishek Naik, and Richard S. Sutton. Learning and planning in average-reward markov decision processes. In Proceedings of the International Conference on Machine Learning, 2021
work page 2021
-
[32]
Almost sure convergence of linear temporal difference learning with arbitrary features
Jiuqi Wang and Shangtong Zhang. Almost sure convergence of linear temporal difference learning with arbitrary features. Journal of Machine Learning Research, 2026
work page 2026
-
[33]
Christopher JCH Watkins and Peter Dayan. Q -learning. Machine Learning, 1992
work page 1992
-
[34]
Christopher John Cornish Hellaby Watkins. Learning from delayed rewards. PhD thesis, King's College, Cambridge, 1989
work page 1989
-
[35]
Finite sample analysis of linear temporal difference learning with arbitrary features
Zixuan Xie, Xinyu Liu, Rohan Chandra, and Shangtong Zhang. Finite sample analysis of linear temporal difference learning with arbitrary features. In Advances in Neural Information Processing Systems, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.