Recognition: no theorem link
When Symbol Names Should Not Matter: A Logistic Theory of Fresh-Symbol Classification
Pith reviewed 2026-05-11 01:25 UTC · model grok-4.3
The pith
In template classification, logistic predictors decompose into ideal symbol-invariant rules plus perturbations from token overlaps modeled by a colored collision graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The learned predictor decomposes into an ideal template-level classifier and a finite-sample perturbation caused by accidental token overlaps in the training data. Overlaps are encoded by a colored collision graph, and high-probability margin-transfer guarantees are proved for fresh-symbol classification. Vocabulary size controls the average rate of collisions, but collision geometry controls whether the ideal classification margin is preserved.
What carries the argument
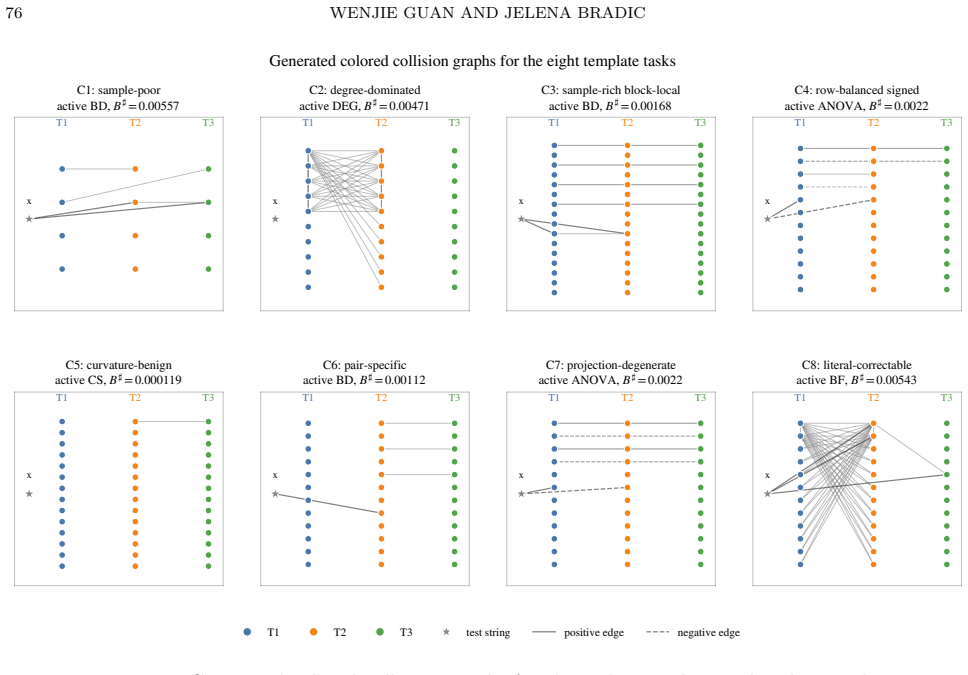
Colored collision graph encoding token overlaps whose geometry determines margin preservation under symbol renaming.
If this is right
- The same perturbation analysis applies to abstraction-augmented inputs and yields a margin-versus-collision test for prompting strategies.
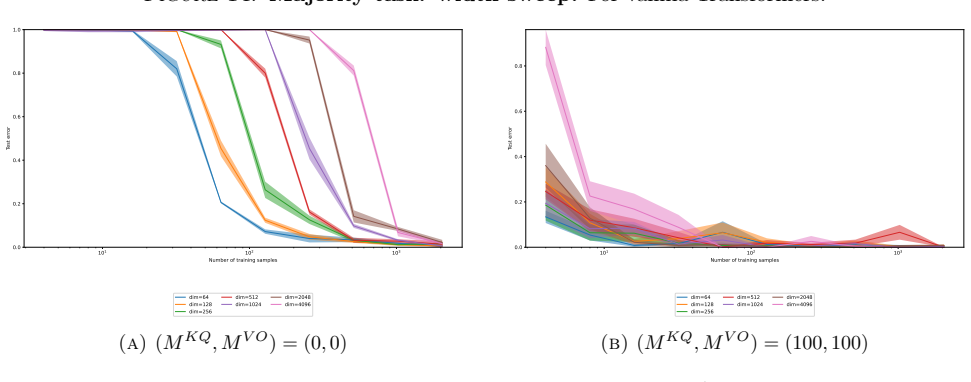
- Synthetic experiments confirm that regularization strength, sample size, and kernel structure affect fresh-symbol performance exactly as predicted by the graph geometry.
- Scalar diversity conditions are replaced by a joint rate-and-geometry criterion for when symbol names cease to matter.
- The framework supplies explicit high-probability bounds that quantify how much training overlap can be tolerated before the ideal rule is lost.
Where Pith is reading between the lines
- Training sets could be actively chosen to avoid collision geometries that destroy margins, improving generalization without larger vocabularies.
- If real transformers depart from the kernel regime, the guarantees may fail in ways that suggest new inductive biases are needed.
- The collision-graph view might extend to non-kernel models by measuring effective overlaps in their internal representations.
- Prompt engineering could be scored by computing the implied collision graph on augmented inputs and checking margin preservation.
Load-bearing premise
The transformer must behave like the kernel model and the overlaps must follow the graph structure that keeps the ideal margin intact.
What would settle it
A trained transformer whose decision boundary deviates substantially from the ideal template classifier even when the collision graph is favorable would falsify the margin-transfer guarantees.
Figures













read the original abstract
Template tasks have emerged as a clean testbed for asking whether transformers reason with abstract symbols rather than concrete token names. We study the fixed-label classification version of this problem, where train and test examples share latent templates but may use disjoint vocabularies. Unlike next-token prediction, the model need not emit unseen symbols; it must learn a decision rule invariant to symbol renaming. We analyze regularized kernel logistic classification in the transformer-kernel regime. Our main result decomposes the learned predictor into an ideal template-level classifier and a finite-sample perturbation caused by accidental token overlaps in the training data. We encode these overlaps by a colored collision graph and prove high-probability margin-transfer guarantees for fresh-symbol classification. This perspective extends template-based analyses to logistic classification and refines scalar diversity conditions: vocabulary size controls the average rate of collisions, but collision geometry controls whether the ideal classification margin is preserved. More broadly, the same perturbation framework applies to abstraction-augmented inputs, yielding a general margin-versus-collision criterion for identifying when prompting strategies improve fresh-symbol generalization. Synthetic template experiments illustrate the predicted roles of regularization, sample size, and transformer-kernel structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes regularized kernel logistic classification in the transformer-kernel regime for fixed-label template classification tasks, where train and test share latent templates but may use disjoint vocabularies. The central result decomposes the learned predictor into an ideal template-level classifier plus a finite-sample perturbation from accidental token overlaps, encoded via a colored collision graph. High-probability margin-transfer guarantees are proved for fresh-symbol classification. The work refines scalar diversity conditions by separating vocabulary size (average collision rate) from collision geometry (margin preservation), extends the framework to abstraction-augmented inputs, and illustrates predictions via synthetic experiments on regularization, sample size, and kernel structure.
Significance. If the decomposition and guarantees hold under the stated assumptions, the paper supplies a principled perturbation analysis that clarifies when symbol renaming invariance emerges in logistic settings. It gives concrete credit to the distinction between average collision rate and geometry, and the margin-versus-collision criterion for prompting strategies is a useful generalization. The synthetic experiments directly test the predicted roles of regularization and sample size, providing reproducible support for the theory. This framework could inform both theoretical work on transformer abstraction and practical choices in prompt design.
major comments (2)
- [§3] §3 (Transformer-kernel regime): The high-probability margin-transfer guarantees are derived under the assumption that the transformer behaves as a kernel method, yet no quantitative bounds are supplied on the approximation error to actual finite-width attention or optimization dynamics; this is load-bearing for the claim that the decomposition applies to transformers rather than only to the idealized kernel model.
- [Definition 2.3 and Theorem 3.1] Colored collision graph construction (Definition 2.3 and Theorem 3.1): The graph encodes overlaps to control the perturbation term, but the manuscript does not demonstrate that the graph construction is independent of label information or that its geometry is preserved under the data distribution; without this, the separation between vocabulary size and margin preservation rests on an unverified modeling choice.
minor comments (2)
- [§5] The synthetic experiments in §5 are well-aligned with the theory but would benefit from an explicit statement of the kernel hyperparameters used and a brief comparison to a non-kernel baseline to isolate the regime effect.
- [Eq. (8)] Notation for the perturbation term (Eq. (8)) could be cross-referenced more clearly when it reappears in the margin bound statements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the positive assessment of the significance of our work. We address the two major comments below, providing clarifications and indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Transformer-kernel regime): The high-probability margin-transfer guarantees are derived under the assumption that the transformer behaves as a kernel method, yet no quantitative bounds are supplied on the approximation error to actual finite-width attention or optimization dynamics; this is load-bearing for the claim that the decomposition applies to transformers rather than only to the idealized kernel model.
Authors: We agree that our results are derived under the transformer-kernel regime assumption. The manuscript does not provide quantitative bounds on the approximation error between the kernel model and finite-width attention mechanisms or specific optimization paths, as the focus is on the idealized setting. This is a modeling choice to enable the decomposition analysis. We will revise the discussion in §3 to more explicitly delineate the scope of the claims, noting that extensions to finite transformers would require additional approximation theory, which we leave for future work. This addresses the load-bearing aspect by clarifying the idealized nature of the model. revision: yes
-
Referee: [Definition 2.3 and Theorem 3.1] Colored collision graph construction (Definition 2.3 and Theorem 3.1): The graph encodes overlaps to control the perturbation term, but the manuscript does not demonstrate that the graph construction is independent of label information or that its geometry is preserved under the data distribution; without this, the separation between vocabulary size and margin preservation rests on an unverified modeling choice.
Authors: The construction of the colored collision graph in Definition 2.3 is based exclusively on the observed token overlaps in the training set inputs and does not incorporate label information; labels are assigned at the template level independently of symbol identities. The geometry of the graph is analyzed probabilistically in Theorem 3.1, where we show that under the data distribution, with high probability the perturbation is controlled when the average collision rate (governed by vocabulary size) and the margin conditions (governed by geometry) are satisfied. The separation is thus a consequence of the theorem rather than an unverified choice. To make this explicit, we will add a clarifying paragraph after Definition 2.3 explaining the label-independence and the role of the data distribution in preserving the relevant geometric properties. revision: yes
Circularity Check
No significant circularity; derivation self-contained under stated assumptions
full rationale
The paper derives a decomposition of the learned predictor into an ideal template classifier plus perturbation from overlaps (modeled via colored collision graph) and proves margin-transfer guarantees, all explicitly conditioned on the transformer-kernel regime. This is a standard theoretical proof structure with no reduction of the central claim to its inputs by construction, no fitted parameters renamed as predictions, and no load-bearing self-citations or ansatzes smuggled via prior work. The analysis remains independent within its modeling framework and does not equate the result to the assumptions themselves.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization strength
axioms (2)
- domain assumption The model operates in the transformer-kernel regime
- standard math High-probability concentration inequalities apply to margin transfer
invented entities (1)
-
colored collision graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Emmanuel Abbe, Samy Bengio, Aryo Lotfi, and Kevin Rizk. Generalization on the Unseen, Logic Reasoning and Degree Curriculum.Journal of Machine Learning Research, 25(331):1–58, 2024
work page 2024
-
[2]
Emergence of Symbolic Abstraction Heads for In-Context Learning in Large Language Models
Ali Al-Saeedi and Aki Härmä. Emergence of Symbolic Abstraction Heads for In-Context Learning in Large Language Models. InProceedings of Bridging Neurons and Symbols for Natural Language Processing and Knowledge Graphs Reasoning @ COLING 2025, pages 86–96, Association for Computational Linguistics, 2025
work page 2025
-
[3]
Lepori, Jack Merullo, and Ellie Pavlick
Suraj Anand, Michael A. Lepori, Jack Merullo, and Ellie Pavlick. Dual Process Learning: Controlling Use of In- Context vs. In-Weights Strategies with Weight Forgetting. InInternational Conference on Learning Representations, 2025
work page 2025
-
[4]
Du, Wei Hu, Zhiyuan Li, Ruslan Salakhutdinov, and Ruosong Wang
Sanjeev Arora, Simon S. Du, Wei Hu, Zhiyuan Li, Ruslan Salakhutdinov, and Ruosong Wang. On Exact Computation with an Infinitely Wide Neural Net. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[5]
Self-Concordant Analysis for Logistic Regression.Electronic Journal of Statistics, 4:384–414, 2010
Francis Bach. Self-Concordant Analysis for Logistic Regression.Electronic Journal of Statistics, 4:384–414, 2010
work page 2010
-
[6]
Neural Machine Translation by Jointly Learning to Align and Translate
Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. InProceedings of the International Conference on Learning Representations (ICLR), 2014
work page 2014
-
[7]
Dzmitry Bahdanau, Shikhar Murty, Michael Noukhovitch, Thien Huu Nguyen, Harm de Vries, and Aaron Courville. Systematic Generalization: What Is Required and Can It Be Learned? InInternational Conference on Learning Representations, 2019
work page 2019
-
[8]
Peter L. Bartlett, Michael I. Jordan, and Jon D. McAuliffe. Convexity, Classification, and Risk Bounds.Journal of the American Statistical Association, 101(473):138–156, 2006
work page 2006
-
[9]
Enric Boix-Adserà, Omid Saremi, Emmanuel Abbe, Samy Bengio, Etai Littwin, and Joshua Susskind. When can transformers reason with abstract symbols? InProceedings of the International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[10]
Andrea Caponnetto and Ernesto De Vito. Optimal Rates for the Regularized Least-Squares Algorithm.Foundations of Computational Mathematics, 7(3):331–368, 2007
work page 2007
-
[11]
Toward Understanding In-Context vs
Bryan Chan, Xinyi Chen, András György, and Dale Schuurmans. Toward Understanding In-Context vs. In-Weight Learning. InInternational Conference on Learning Representations, 2025
work page 2025
-
[12]
On Lazy Training in Differentiable Programming
Lénaïc Chizat and Francis Bach. On Lazy Training in Differentiable Programming. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[13]
Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic Reasoning
Subhabrata Dutta, Ishan Pandey, Joykirat Singh, Sunny Manchanda, Soumen Chakrabarti, and Tanmoy Chakraborty. Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic Reasoning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, number 16, pages 17951–17959, 2024
work page 2024
-
[14]
Hwang, Soumya Sanyal, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D. Hwang, Soumya Sanyal, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi. Faith and Fate: Limits of Transformers on Compositionality. InAdvances in Neural Information Processing Systems, vol...
work page 2023
-
[15]
Efficient Tool Use with Chain-of-Abstraction Reasoning
Silin Gao, Jane Dwivedi-Yu, Ping Yu, Xiaoqing Ellen Tan, Ramakanth Pasunuru, Olga Golovneva, Koustuv Sinha, Asli Celikyilmaz, Antoine Bosselut, and Tianlu Wang. Efficient Tool Use with Chain-of-Abstraction Reasoning. In Proceedings of the 31st International Conference on Computational Linguistics, pages 2727–2743, 2025. 18 WENJIE GUAN AND JELENA BRADIC
work page 2025
-
[16]
AbstRaL: Augmenting LLMs’ Reasoning by Reinforcing Abstract Thinking
Silin Gao, Antoine Bosselut, Samy Bengio, and Emmanuel Abbe. AbstRaL: Augmenting LLMs’ Reasoning by Reinforcing Abstract Thinking. InProceedings of the International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[17]
On the Compositional Generalization Gap of In-Context Learning
Arian Hosseini, Ankit Vani, Dzmitry Bahdanau, Alessandro Sordoni, and Aaron Courville. On the Compositional Generalization Gap of In-Context Learning. InProceedings of the Fifth BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, pages 272–280, Association for Computational Linguistics, Abu Dhabi, United Arab Emirates (Hybrid), 2022
work page 2022
-
[18]
Dieuwke Hupkes, Mario Giulianelli, Verna Dankers, Mikel Artetxe, Yanai Elazar, Tiago Pimentel, Christos Christodoulopoulos, Karim Lasri, Koustuv Sinha, Leila Khalatbari, Maria Ryskina, Rita Frieske, Ryan Cotterell, Zhijing Jin, and others. A Taxonomy and Review of Generalization Research in NLP.Nature Machine Intelligence, 5:1161–1174, 2023
work page 2023
-
[19]
Interchangeable Token Embeddings for Extendable Vocabulary and Alpha-Equivalence
İlker Işık, Ramazan Gokberk Cinbis, and Ebru Aydin Gol. Interchangeable Token Embeddings for Extendable Vocabulary and Alpha-Equivalence. InProceedings of the 42nd International Conference on Machine Learning, Proceedings of Machine Learning Research, volume 267, pages 26523–26541, PMLR, 2025
work page 2025
-
[20]
Names Don’t Matter: Symbol-Invariant Transformer for Open-Vocabulary Learning
İlker Işık and Wenchao Li. Names Don’t Matter: Symbol-Invariant Transformer for Open-Vocabulary Learning. arXiv preprint arXiv:2601.23169, 2026
-
[21]
Neural Tangent Kernel: Convergence and Generalization in Neural Networks
Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural Tangent Kernel: Convergence and Generalization in Neural Networks. InAdvances in Neural Information Processing Systems, volume 31, pages 8580–8589, 2018
work page 2018
-
[22]
Su, Camillo Jose Taylor, and Dan Roth
Bowen Jiang, Yangxinyu Xie, Zhuoqun Hao, Xiaomeng Wang, Tanwi Mallick, Weijie J. Su, Camillo Jose Taylor, and Dan Roth. A peek into token bias: Large language models are not yet genuine reasoners. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
work page 2024
-
[23]
Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
Daniel Keysers, Nathanael Schärli, Nathan Scales, Hylke Buisman, Daniel Furrer, Sergii Kashubin, Nikola Momchev, Danila Sinopalnikov, Lukasz Stafiniak, Tibor Tihon, Dmitry Tsarkov, Xiao Wang, Marc van Zee, and Olivier Bousquet. Measuring Compositional Generalization: A Comprehensive Method on Realistic Data. InInternational Conference on Learning Represen...
work page 2020
-
[24]
COGS: A Compositional Generalization Challenge Based on Semantic Interpretation
Najoung Kim and Tal Linzen. COGS: A Compositional Generalization Challenge Based on Semantic Interpretation. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9087–9105, Association for Computational Linguistics, Online, 2020
work page 2020
-
[25]
To See the Unseen: on the Generalization Ability of Transformers in Symbolic Reasoning
Nevena Lazić, Liam Fowl, András György, and Csaba Szepesvári. To See the Unseen: On the Generalization Ability of Transformers in Symbolic Reasoning. arXiv preprint arXiv:2604.21632, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [26]
-
[27]
When Does Compositional Structure Yield Compositional Generalization? A Kernel Theory
Samuel Lippl and Kim Stachenfeld. When Does Compositional Structure Yield Compositional Generalization? A Kernel Theory. InInternational Conference on Learning Representations, 2025
work page 2025
-
[28]
GSM- Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. GSM- Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. InProceedings of the International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[29]
Parthe Pandit, Zhichao Wang, and Yizhe Zhu. Universality of Kernel Random Matrices and Kernel Regression in the Quadratic Regime.Journal of Machine Learning Research, 26:1–73, 2025
work page 2025
-
[30]
ICLR: In-Context Learning of Representations
Core Francisco Park, Andrew Lee, Ekdeep Singh Lubana, Yongyi Yang, Maya Okawa, Kento Nishi, Martin Wattenberg, and Hidenori Tanaka. ICLR: In-Context Learning of Representations. InInternational Conference on Learning Representations, 2025
work page 2025
-
[31]
Generalization Properties of Learning with Random Features
Alessandro Rudi and Lorenzo Rosasco. Generalization Properties of Learning with Random Features. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[32]
Laura Ruis, Jacob Andreas, Marco Baroni, Diane Bouchacourt, and Brenden M. Lake. A Benchmark for Systematic Generalization in Grounded Language Understanding. InAdvances in Neural Information Processing Systems, volume 33, pages 19861–19872, 2020
work page 2020
-
[33]
Bernhard Schölkopf, Ralf Herbrich, and Alexander J. Smola. A Generalized Representer Theorem. InComputational Learning Theory, Lecture Notes in Computer Science, volume 2111, pages 416–426, Springer, 2001
work page 2001
-
[34]
Paul Smolensky, Roland Fernandez, Zhenghao Herbert Zhou, Mattia Opper, Adam Davies, and Jianfeng Gao. Mechanisms of Symbol Processing for In-Context Learning in Transformer Networks.Journal of Artificial Intelligence Research, 84(23), 2025
work page 2025
-
[35]
Ingo Steinwart and Andreas Christmann.Support Vector Machines. Springer, New York, 2008
work page 2008
-
[36]
Schema-Learning and Rebinding as Mechanisms of In-Context Learning and Emergence
Sivaramakrishnan Swaminathan, Antoine Dedieu, Rajkumar Vasudeva Raju, Murray Shanahan, Miguel Lázaro- Gredilla, and Dileep George. Schema-Learning and Rebinding as Mechanisms of In-Context Learning and Emergence. InAdvances in Neural Information Processing Systems, volume 36, pages 28785–28804, 2023
work page 2023
-
[37]
Eric Todd, Jannik Brinkmann, Rohit Gandikota, and David Bau. In-Context Algebra. arXiv preprint arXiv:2512.16902, 2025. WHEN SYMBOL NAMES SHOULD NOT MATTER 19
-
[38]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017
work page 2017
-
[39]
Transformers Learn In-Context by Gradient Descent
Johannes von Oswald, Eyvind Niklasson, Ettore Randazzo, João Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers Learn In-Context by Gradient Descent. InProceedings of the 40th International Conference on Machine Learning, Proceedings of Machine Learning Research, volume 202, pages 35151–35174, PMLR, 2023
work page 2023
-
[40]
Taylor Whittington Webb, Ishan Sinha, and Jonathan D. Cohen. Emergent Symbols through Binding in External Memory. InInternational Conference on Learning Representations, 2021
work page 2021
-
[41]
Optimal Learning of Kernel Logistic Regression for Complex Classification Scenarios
Hongwei Wen, Annika Betken, and Hanyuan Hang. Optimal Learning of Kernel Logistic Regression for Complex Classification Scenarios. InInternational Conference on Learning Representations, 2025
work page 2025
-
[42]
How do transformers learn variable binding in symbolic programs?arXiv preprint arXiv:2505.20896,
Yiwei Wu, Atticus Geiger, and Raphaël Millière. How Do Transformers Learn Variable Binding in Symbolic Programs? arXiv preprint arXiv:2505.20896, 2025
-
[43]
An Explanation of In-Context Learning as Implicit Bayesian Inference
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An Explanation of In-Context Learning as Implicit Bayesian Inference. InInternational Conference on Learning Representations, 2022
work page 2022
-
[44]
Cohen, and Taylor Whittington Webb
Yukang Yang, Declan Iain Campbell, Kaixuan Huang, Mengdi Wang, Jonathan D. Cohen, and Taylor Whittington Webb. Emergent Symbolic Mechanisms Support Abstract Reasoning in Large Language Models. InProceedings of the 42nd International Conference on Machine Learning, Proceedings of Machine Learning Research, volume 267, pages 70515–70549, PMLR, 2025
work page 2025
-
[45]
Dechen Zhang, Zhenmei Shi, Yi Zhang, Yingyu Liang, and Difan Zou. Kernel Regression in Structured Non-IID Settings: Theory and Implications for Denoising Score Learning. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[46]
Haobo Zhang, Yicheng Li, Weihao Lu, and Qian Lin. Optimal Rates of Kernel Ridge Regression under Source Condition in Large Dimensions.Journal of Machine Learning Research, 26:1–63, 2025
work page 2025
-
[47]
Statistical Behavior and Consistency of Classification Methods Based on Convex Risk Minimization
Tong Zhang. Statistical Behavior and Consistency of Classification Methods Based on Convex Risk Minimization. The Annals of Statistics, 32(1):56–85, 2004
work page 2004
-
[48]
Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein. Neural Module Networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 39–48, 2016
work page 2016
-
[49]
David G. T. Barrett, Felix Hill, Adam Santoro, Ari S. Morcos, and Timothy Lillicrap. Measuring Abstract Reasoning in Neural Networks. InProceedings of the 35th International Conference on Machine Learning, Proceedings of Machine Learning Research, volume 80, pages 511–520, PMLR, 2018
work page 2018
-
[50]
Oxford University Press, Oxford, 2013
Stéphane Boucheron, Gábor Lugosi, and Pascal Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, Oxford, 2013
work page 2013
-
[51]
F. R. K. Chung, R. L. Graham, and R. M. Wilson. Quasi-Random Graphs.Combinatorica, 9(4):345–362, 1989
work page 1989
-
[52]
Group Equivariant Convolutional Networks
Taco Cohen and Max Welling. Group Equivariant Convolutional Networks. InProceedings of the 33rd International Conference on Machine Learning, Proceedings of Machine Learning Research, volume 48, pages 2990–2999, PMLR, 2016
work page 2016
-
[53]
Jerry A. Fodor and Zenon W. Pylyshyn. Connectionism and Cognitive Architecture: A Critical Analysis.Cognition, 28(1–2):3–71, 1988
work page 1988
-
[54]
Robert Gens and Pedro Domingos. Deep Symmetry Networks. InAdvances in Neural Information Processing Systems, volume 27, 2014
work page 2014
-
[55]
Invariant Kernel Functions for Pattern Analysis and Machine Learning
Bernard Haasdonk and Hans Burkhardt. Invariant Kernel Functions for Pattern Analysis and Machine Learning. Machine Learning, 68(1):35–61, 2007
work page 2007
-
[56]
Convolution Kernels on Discrete Structures
David Haussler. Convolution Kernels on Discrete Structures. Technical Report UCSC-CRL-99-10, University of California, Santa Cruz, 1999
work page 1999
-
[57]
Junkyung Kim, Matthew Ricci, and Thomas Serre. Not-So-CLEVR: Learning Same–Different Relations Strains Feedforward Neural Networks.Interface Focus, 8(4):20180011, 2018
work page 2018
-
[58]
BrendenM.LakeandMarcoBaroni.GeneralizationwithoutSystematicity: OntheCompositionalSkillsofSequence-to- Sequence Recurrent Networks. InProceedings of the 35th International Conference on Machine Learning, Proceedings of Machine Learning Research, volume 80, pages 2873–2882, PMLR, 2018
work page 2018
-
[59]
Compositional Generalization by Learning Analytical Expressions
Qian Liu, Bo An, Jian-Guang Lou, Bei Chen, Zhouhan Lin, Yan Gao, Bin Zhou, and Dongmei Zhang. Compositional Generalization by Learning Analytical Expressions. InAdvances in Neural Information Processing Systems, volume 33, pages 11416–11427, 2020
work page 2020
-
[60]
Text Classification Using String Kernels.Journal of Machine Learning Research, 2:419–444, 2002
Huma Lodhi, Craig Saunders, John Shawe-Taylor, Nello Cristianini, and Chris Watkins. Text Classification Using String Kernels.Journal of Machine Learning Research, 2:419–444, 2002
work page 2002
-
[61]
Toward Compositional Behavior in Neural Models: A Survey of Current Views
Kate McCurdy, Paul Soulos, Henry Conklin, Mattia Opper, Paul Smolensky, Jianfeng Gao, and Roland Fernandez. Toward Compositional Behavior in Neural Models: A Survey of Current Views. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9323–9339, Association for Computational Linguistics, 2024. 20 WENJIE GUAN AND...
work page 2024
-
[62]
Learning with Group Invariant Features: A Kernel Perspective
Youssef Mroueh, Stephen Voinea, and Tomaso Poggio. Learning with Group Invariant Features: A Kernel Perspective. InAdvances in Neural Information Processing Systems, volume 28, 2015
work page 2015
-
[63]
Maxwell Nye, Armando Solar-Lezama, Joshua B. Tenenbaum, and Brenden M. Lake. Learning Compositional Rules via Neural Program Synthesis. InAdvances in Neural Information Processing Systems, volume 33, pages 10832–10842, 2020
work page 2020
-
[64]
In-Context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
work page 2022
-
[65]
Adam Santoro, David Raposo, David G. T. Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap. A Simple Neural Network Module for Relational Reasoning. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[66]
Joel A. Tropp. An Introduction to Matrix Concentration Inequalities.Foundations and Trends in Machine Learning, 8(1–2):1–230, 2015
work page 2015
-
[67]
Gail Weiss, Yoav Goldberg, and Eran Yahav. Thinking Like Transformers. InProceedings of the 38th International Conference on Machine Learning, Proceedings of Machine Learning Research, volume 139, pages 11080–11090, PMLR, 2021
work page 2021
-
[68]
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Ruslan Salakhutdinov, and Alexander Smola. Deep Sets. InAdvances in Neural Information Processing Systems, volume 30, 2017. Contents Appendix A. Notation and standing objects 21 A.1. Notation summary 21 Appendix B. The collision graph as the perturbation object 23 Appendix C. Certificate b...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.