Recognition: no theorem link
TENNOR: Trustworthy Execution for Neural Networks through Obliviousness and Retrievals
Pith reviewed 2026-05-11 00:51 UTC · model grok-4.3
The pith
TENNOR turns sparse neuron activation into doubly oblivious LSH retrievals to train wide networks privately in untrusted clouds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
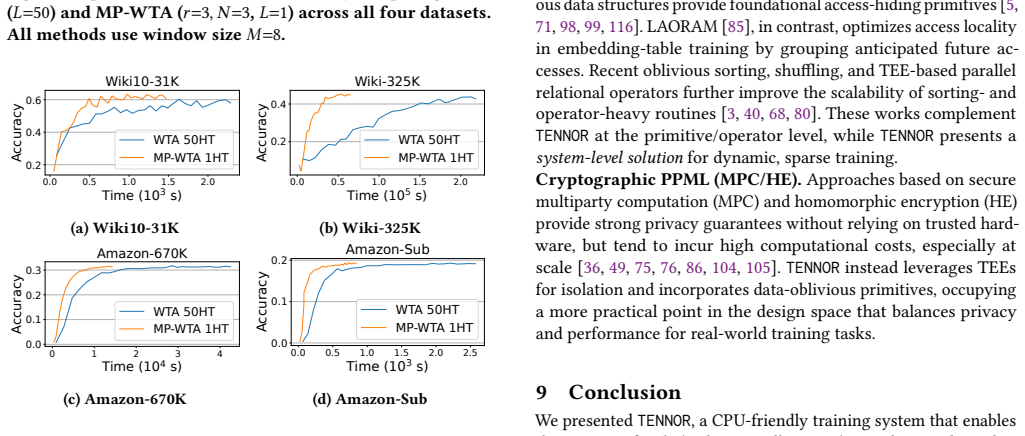
TENNOR recasts sparse neuron activation as a locality-sensitive hashing retrieval problem, reducing secure sparsification to doubly oblivious accesses over an LSH data structure. To remove the high storage cost of multi-table LSH, it introduces Multi-Probe Winner-Take-All, the first multi-probe scheme for rank-based LSH, which achieves a 50x reduction in hash-table memory while preserving model accuracy. Inside an Intel TDX Trusted Domain the system reaches speedups of 13x-470x over Path ORAM and shortens a 208-hour run to roughly 26 minutes on benchmarks with output layers of up to 325K neurons.
What carries the argument
Multi-Probe Winner-Take-All (MP-WTA), a multi-probe method for rank-based locality-sensitive hashing that replaces multi-table structures and enables low-memory doubly oblivious retrievals for sparse activation.
If this is right
- Secure training of wide output layers becomes practical inside TEEs without access-pattern leakage.
- Hash-table storage for the LSH structure drops by a factor of fifty while accuracy stays the same.
- Training runs that previously took days finish in tens of minutes on the same hardware.
- Doubly oblivious primitives can be applied to other irregular access patterns that arise in neural network training.
Where Pith is reading between the lines
- The same LSH-recasting idea could be tried on other privacy-sensitive operations such as private inference or gradient aggregation.
- MP-WTA might reduce memory in non-private approximate-nearest-neighbor applications that already use rank-based LSH.
- The approach suggests a general template for turning data-dependent control flow into oblivious retrievals over compact data structures.
Load-bearing premise
That recasting sparsification as LSH retrieval and using MP-WTA still produces models whose accuracy matches the non-secure baseline on the target tasks.
What would settle it
Measure accuracy of a model trained with TENNOR on an extreme multi-label benchmark and compare it directly to the accuracy obtained with standard non-oblivious sparsification on the same data and architecture.
Figures




















read the original abstract
Training wide neural networks on sensitive data in untrusted cloud environments requires simultaneously achieving computational efficiency and rigorous privacy guarantees. Sparsification techniques, essential for scalable training of wide layers, expose input-dependent memory-access patterns (i.e., leakage) that are visible and can be exploited by a host OS/hypervisor, even when computation is protected by a Trusted Execution Environment. We present TENNOR, a system that resolves this tension by co-designing the neural network training pipeline with doubly oblivious primitives, eliminating access-pattern leakage while also utilizing adaptive sparsification. TENNOR recasts sparse neuron activation as a locality-sensitive hashing (LSH) retrieval problem, reducing secure sparsification to doubly oblivious accesses over an LSH data structure. To eliminate the prohibitive storage cost of ``multi-table'' LSH, we introduce Multi-Probe Winner-Take-All (MP-WTA): the first multi-probe scheme for rank-based LSH, achieving a 50x reduction in (hash table) memory while preserving model accuracy. We evaluate TENNOR on extreme multi-label classification benchmarks with output layers of up to 325K neurons inside an Intel TDX Trusted Domain, achieving speedups of 13x--470x over a Path ORAM baseline and reducing a 208-hour run to about 26 minutes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TENNOR, a system for secure training of wide neural networks in untrusted cloud environments protected by TEEs such as Intel TDX. It recasts input-dependent sparse neuron activation as a locality-sensitive hashing (LSH) retrieval problem, reduces secure sparsification to doubly oblivious accesses, and introduces the Multi-Probe Winner-Take-All (MP-WTA) primitive—the first multi-probe scheme for rank-based LSH—to achieve a claimed 50x reduction in hash-table memory while preserving accuracy. Evaluations on extreme multi-label classification benchmarks with output layers up to 325K neurons report speedups of 13x–470x over a Path ORAM baseline, reducing a 208-hour run to ~26 minutes.
Significance. If the accuracy-preservation and leakage-elimination claims hold, TENNOR would enable practical, scalable training of wide models with rigorous access-pattern privacy against a host OS/hypervisor adversary. The MP-WTA construction is a novel primitive for rank-based LSH that directly addresses the storage bottleneck of multi-table schemes; the reported speedups and memory savings, if reproducible, represent a substantial practical advance over generic ORAM baselines for this workload.
major comments (3)
- [§4 (Evaluation) and Table 3] §4 (Evaluation) and Table 3: The accuracy results report only absolute test accuracies for TENNOR; no quantitative deltas, error bars, or direct comparisons to exact top-k sparsification are provided. This makes it impossible to verify whether the MP-WTA approximation error is small enough for training to converge to the same accuracy as the non-oblivious baseline.
- [§3.3 (MP-WTA Construction)] §3.3 (MP-WTA Construction): The design of the multi-probe schedule and winner-take-all ranking lacks any approximation guarantee, concentration bound, or empirical distribution of rank error relative to exact top-k. Without such analysis, the central claim that LSH retrieval can safely replace exact sparsification remains unsubstantiated.
- [§5 (Security Argument)] §5 (Security Argument): The claim that doubly oblivious accesses over the LSH data structure eliminate all input-dependent leakage of neuron indices is presented without a formal reduction, simulation-based proof, or exhaustive channel analysis under the stated TEE threat model. A concrete argument showing that probe patterns, hash-table accesses, and retrieval results reveal nothing beyond what the TEE already hides is required.
minor comments (3)
- [Abstract] Abstract: The phrase 'preserving model accuracy' should be accompanied by the specific datasets and observed accuracy deltas to avoid overstatement.
- [Figure 4 and §4.1] Figure 4 and §4.1: Legends and axis labels are difficult to read at print size; increasing font size and adding a direct 'exact top-k' reference line would improve clarity.
- [§2 (Related Work)] §2 (Related Work): Several recent papers on oblivious RAM for ML inference and LSH-based secure retrieval are not cited; adding them would better situate the novelty of MP-WTA.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We appreciate the recognition of TENNOR's practical contributions and the novelty of MP-WTA. We address each major comment below and commit to revisions that strengthen empirical validation, analysis, and the security argument without misrepresenting the current manuscript.
read point-by-point responses
-
Referee: [§4 (Evaluation) and Table 3] §4 (Evaluation) and Table 3: The accuracy results report only absolute test accuracies for TENNOR; no quantitative deltas, error bars, or direct comparisons to exact top-k sparsification are provided. This makes it impossible to verify whether the MP-WTA approximation error is small enough for training to converge to the same accuracy as the non-oblivious baseline.
Authors: We agree that comparative metrics are necessary to validate the approximation. The current evaluation emphasizes end-to-end speedups and absolute accuracies on extreme multi-label tasks, but we will revise §4 and Table 3 to include: direct side-by-side test accuracy for TENNOR (MP-WTA) versus exact top-k sparsification on the same benchmarks; error bars from multiple random seeds; and quantitative deltas (absolute and relative) demonstrating that MP-WTA-induced rank errors remain small enough for training convergence to comparable accuracy. These additions will be supported by the existing experimental setup. revision: yes
-
Referee: [§3.3 (MP-WTA Construction)] §3.3 (MP-WTA Construction): The design of the multi-probe schedule and winner-take-all ranking lacks any approximation guarantee, concentration bound, or empirical distribution of rank error relative to exact top-k. Without such analysis, the central claim that LSH retrieval can safely replace exact sparsification remains unsubstantiated.
Authors: We acknowledge the absence of formal guarantees or detailed error analysis in the submitted version. MP-WTA is a heuristic multi-probe extension of rank-based WTA LSH that trades storage for controlled approximation. In the revision we will augment §3.3 with: (i) an empirical distribution (e.g., CDFs and histograms) of per-neuron rank error versus exact top-k across all evaluated layers and datasets; (ii) discussion of probabilistic rank preservation derived from the underlying LSH family; and (iii) any derivable concentration bounds on the probability of large rank deviations. This will directly substantiate that the retrieval safely approximates sparsification for the training workloads considered. revision: yes
-
Referee: [§5 (Security Argument)] §5 (Security Argument): The claim that doubly oblivious accesses over the LSH data structure eliminate all input-dependent leakage of neuron indices is presented without a formal reduction, simulation-based proof, or exhaustive channel analysis under the stated TEE threat model. A concrete argument showing that probe patterns, hash-table accesses, and retrieval results reveal nothing beyond what the TEE already hides is required.
Authors: We agree a more rigorous presentation is warranted. The manuscript's security argument rests on the fact that all LSH accesses are made doubly oblivious (input- and data-independent), so probe sequences, hash-table reads, and retrieval results are independent of neuron indices. In revision we will expand §5 with: an exhaustive enumeration of observable channels under the TEE threat model; a simulation argument showing that any adversary view can be produced without knowledge of the input; and a sketch reducing the claim to the security of the underlying oblivious primitives. This will supply the concrete, simulation-based argument requested while remaining within the scope of a systems paper. revision: yes
Circularity Check
No circularity: new system primitives and empirical evaluation stand independently
full rationale
The paper's core claims rest on introducing MP-WTA as a novel multi-probe LSH scheme and recasting sparsification as doubly oblivious LSH retrievals, followed by system implementation and benchmark evaluation on TDX. No equations reduce a claimed prediction or uniqueness result back to fitted inputs or self-citations by construction. The 50x memory reduction and accuracy preservation are presented as outcomes of the new design, not tautological re-statements of inputs. Self-citations, if present in the full text, are not load-bearing for the central derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Trusted Execution Environments such as Intel TDX isolate computation from the host OS/hypervisor
- domain assumption Locality-sensitive hashing can approximate sparse neuron activations with negligible accuracy loss
invented entities (1)
-
Multi-Probe Winner-Take-All (MP-WTA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AMD. 2020. Strengthening VM Isolation with Integrity Protection and More. White paper (SEV-SNP). https://docs.amd.com/v/u/en-US/SEV-SNP-strength ening-vm-isolation-with-integrity-protection-and-more
2020
-
[2]
Alexandr Andoni, Piotr Indyk, Thijs Laarhoven, Ilya Razenshteyn, and Ludwig Schmidt. 2015. Practical and optimal LSH for angular distance.Advances in neural information processing systems28 (2015)
2015
-
[3]
Gilad Asharov, TH Hubert Chan, Kartik Nayak, Rafael Pass, Ling Ren, and Elaine Shi. 2020. Bucket oblivious sort: An extremely simple oblivious sort. In Symposium on Simplicity in Algorithms. SIAM, 8–14
2020
-
[4]
Gilad Asharov, Ilan Komargodski, Wei-Kai Lin, Kartik Nayak, Enoch Peserico, and Elaine Shi. 2020. OptORAMa: optimal oblivious RAM. InAdvances in Cryptology–EUROCRYPT 2020: 39th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Zagreb, Croatia, May 10–14, 2020, Proceedings, Part II 30. Springer, 403–432
2020
-
[5]
Gilad Asharov, Ilan Komargodski, and Yehuda Michelson. 2023. Futorama: A concretely efficient hierarchical oblivious ram. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security. 3313–3327
2023
-
[6]
Rohit Babbar and Bernhard Schölkopf. 2017. Dismec: Distributed sparse ma- chines for extreme multi-label classification. InProceedings of the tenth ACM international conference on web search and data mining. 721–729
2017
-
[7]
Juyang Bai, Md Hafizul Islam Chowdhuryy, Jingtao Li, Fan Yao, Chaitali Chakrabarti, and Deliang Fan. 2025. Phantom: Privacy-Preserving Deep Neural Network Model Obfuscation in Heterogeneous TEE and GPU System. In34th USENIX Security Symposium (USENIX Security 2025), Seattle, W A, USA, August 13- 15, 2025, Lujo Bauer and Giancarlo Pellegrino (Eds.). USENIX...
2025
-
[8]
https://www.usenix.org/conference/usenixsecurity25/presentation/bai- juyang
-
[9]
Kenneth E Batcher. 1968. Sorting networks and their applications. InProceedings of the April 30–May 2, 1968, spring joint computer conference. 307–314
1968
-
[10]
Roberto J Bayardo, Yiming Ma, and Ramakrishnan Srikant. 2007. Scaling up all pairs similarity search. InProceedings of the 16th international conference on World Wide Web. 131–140
2007
- [11]
-
[12]
Bhatia, K
K. Bhatia, K. Dahiya, H. Jain, P. Kar, A. Mittal, Y. Prabhu, and M. Varma. 2016. The extreme classification repository: Multi-label datasets and code. http: //manikvarma.org/downloads/XC/XMLRepository.html
2016
-
[13]
How Query Distribution Knowledge Breaks Multidimensional Encrypted Range Queries, With Guarantees
Daniel Blackley, Nathaniel Moyer, Charalampos Papamanthou, and Evgenios M. Kornaropoulos. 2026. How Query Distribution Knowledge Breaks Multidimen- sional Encrypted Range Queries, With Guarantees. arXiv:2508.11563 [cs.CR] https://arxiv.org/abs/2508.11563
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Thomas Bourgeat, Ilia Lebedev, Andrew Wright, Sizhuo Zhang, Arvind, and Srinivas Devadas. 2019. Mi6: Secure enclaves in a speculative out-of-order processor. InProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture. 42–56
2019
-
[15]
Ferdinand Brasser, Urs Müller, Alexandra Dmitrienko, Kari Kostiainen, Srdjan Capkun, and Ahmad-Reza Sadeghi. 2017. Software grand exposure: {SGX} cache attacks are practical. In11th USENIX workshop on offensive technologies (WOOT 17)
2017
-
[16]
Andrei Z Broder, Moses Charikar, Alan M Frieze, and Michael Mitzenmacher
-
[17]
InProceedings of the thirtieth annual ACM symposium on Theory of computing
Min-wise independent permutations. InProceedings of the thirtieth annual ACM symposium on Theory of computing. 327–336
-
[18]
Ran Canetti. 2000. Security and composition of multiparty cryptographic protocols.Journal of CRYPTOLOGY13, 1 (2000), 143–202
2000
-
[19]
David Cash, Paul Grubbs, Jason Perry, and Thomas Ristenpart. 2015. Leakage- Abuse Attacks Against Searchable Encryption. InProc. of the 22nd ACM CCS. 668–679
2015
-
[20]
Javad Ghareh Chamani, Ioannis Demertzis, Dimitrios Papadopoulos, Charalam- pos Papamanthou, and Rasool Jalili. 2023. GraphOS: Towards Oblivious Graph Processing.Proceedings of the VLDB Endowment16, 13 (2023), 4324–4338
2023
-
[21]
T-H Hubert Chan, Yue Guo, Wei-Kai Lin, and Elaine Shi. 2017. Oblivious hashing revisited, and applications to asymptotically efficient ORAM and OPRAM. In Advances in Cryptology–ASIACRYPT 2017: 23rd International Conference on the Theory and Applications of Cryptology and Information Security, Hong Kong, China, December 3-7, 2017, Proceedings, Part I 23. S...
2017
-
[22]
Charikar
Moses S. Charikar. 2002. Similarity Estimation Techniques from Rounding Algorithms. InProceedings of the thirty-fourth annual ACM symposium on Theory of computing
2002
-
[23]
Beidi Chen, Zichang Liu, Binghui Peng, Zhaozhuo Xu, Jonathan Lingjie Li, Tri Dao, Zhao Song, Anshumali Shrivastava, and Christopher Re. 2020. Mongoose: A learnable lsh framework for efficient neural network training. InInternational Conference on Learning Representations
2020
-
[24]
Beidi Chen, Tharun Medini, James Farwell, Charlie Tai, Anshumali Shrivastava, et al. 2020. Slide: In defense of smart algorithms over hardware acceleration for large-scale deep learning systems.Proceedings of Machine Learning and Systems 2 (2020), 291–306
2020
-
[25]
Sanchuan Chen, Xiaokuan Zhang, Michael K Reiter, and Yinqian Zhang. 2017. Detecting privileged side-channel attacks in shielded execution with Déjá Vu. InProceedings of the 2017 ACM on Asia Conference on Computer and Communi- cations Security. 7–18
2017
-
[26]
Pau-Chen Cheng, Wojciech Ozga, Enriquillo Valdez, Salman Ahmed, Zhongshu Gu, Hani Jamjoom, Hubertus Franke, and James Bottomley. 2024. Intel tdx demystified: A top-down approach.Comput. Surveys56, 9 (2024), 1–33
2024
-
[27]
Graeme Connell. 2022. Technology Deep Dive: Building a Faster ORAM Layer for Enclaves. https://signal.org/blog/building-faster-oram/. Accessed: 2026-04-17
2022
-
[28]
Victor Costan and Srinivas Devadas. 2016. Intel SGX explained.Cryptology ePrint Archive(2016)
2016
-
[29]
Victor Costan, Ilia Lebedev, and Srinivas Devadas. 2016. Sanctum: Minimal hardware extensions for strong software isolation. In25th USENIX Security Symposium (USENIX Security 16). 857–874
2016
-
[30]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. InProceedings of the 10th ACM conference on recommender systems. 191–198
2016
-
[31]
Natacha Crooks, Matthew Burke, Ethan Cecchetti, Sitar Harel, Rachit Agarwal, and Lorenzo Alvisi. 2018. Obladi: Oblivious serializable transactions in the cloud. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). 727–743
2018
-
[32]
Shabnam Daghaghi, Tharun Medini, Nicholas Meisburger, Beidi Chen, Mengnan Zhao, and Anshumali Shrivastava. 2021. A tale of two efficient and informa- tive negative sampling distributions. InInternational Conference on Machine Learning. PMLR, 2319–2329
2021
- [33]
-
[34]
Emma Dauterman, Vivian Fang, Ioannis Demertzis, Natacha Crooks, and Raluca Ada Popa. 2021. Snoopy: Surpassing the scalability bottleneck of oblivi- ous storage. InProceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles. 655–671
2021
- [35]
-
[36]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
2022
-
[37]
Jonathan Frankle and Michael Carbin. 2018. The lottery ticket hypothesis: Finding sparse, trainable neural networks.arXiv preprint arXiv:1803.03635 (2018)
work page Pith review arXiv 2018
-
[38]
Ran Gilad-Bachrach, Nathan Dowlin, Kim Laine, Kristin Lauter, Michael Naehrig, and John Wernsing. 2016. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. InInternational confer- ence on machine learning. PMLR, 201–210
2016
-
[39]
Oded Goldreich and Rafail Ostrovsky. 1996. Software protection and simulation on oblivious RAMs.Journal of the ACM (JACM)43, 3 (1996), 431–473
1996
-
[40]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. 2017.Accu- rate, Large Minibatch SGD: Training ImageNet in 1 Hour. Technical Report arXiv:1706.02677. Facebook AI Research. https://arxiv.org/abs/1706.02677
work page internal anchor Pith review arXiv 2017
-
[41]
Grubbs, M
P. Grubbs, M. Lacharité, B. Minaud, and K. G. Paterson. 2019. Learning to Reconstruct: Statistical Learning Theory and Encrypted Database Attacks. In Proc. of the 40th IEEE S&P. 496–512
2019
-
[42]
Tianyao Gu, Yilei Wang, Afonso Tinoco, Bingnan Chen, Ke Yi, and Elaine Shi
-
[43]
In34th USENIX Security Symposium (USENIX Security 2025), Seattle, W A, USA, August 13- 15, 2025, Lujo Bauer and Giancarlo Pellegrino (Eds.)
Flexway O-Sort: Enclave-Friendly and Optimal Oblivious Sorting. In34th USENIX Security Symposium (USENIX Security 2025), Seattle, W A, USA, August 13- 15, 2025, Lujo Bauer and Giancarlo Pellegrino (Eds.). USENIX Association, 7563–
2025
-
[44]
https://www.usenix.org/conference/usenixsecurity25/presentation/gu- tianyao
-
[45]
Song Han, Huizi Mao, and William J Dally. 2015. Deep compression: Com- pressing deep neural networks with pruning, trained quantization and huffman coding.arXiv preprint arXiv:1510.00149(2015)
work page internal anchor Pith review arXiv 2015
-
[46]
Song Han, Jeff Pool, John Tran, and William Dally. 2015. Learning both weights and connections for efficient neural network.Advances in neural information processing systems28 (2015)
2015
- [47]
-
[48]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[49]
Torsten Hoefler, Dan Alistarh, Tal Ben-Nun, Nikoli Dryden, and Alexandra Peste. 2021. Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks.Journal of Machine Learning Research22, 241 (2021), 1–124
2021
-
[50]
Le, Yonghui Wu, and Zhifeng Chen
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, and Zhifeng Chen. 2019. GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 32
2019
- [51]
-
[52]
Piotr Indyk and Rajeev Motwani. 1998. Approximate nearest neighbors: towards removing the curse of dimensionality. InProceedings of the thirtieth annual ACM symposium on Theory of computing. 604–613
1998
-
[53]
Chiraag Juvekar, Vinod Vaikuntanathan, and Anantha Chandrakasan. 2018. {GAZELLE}: A low latency framework for secure neural network inference. In27th USENIX Security Symposium (USENIX Security 18). 1651–1669
2018
-
[54]
Matti Karppa, Martin Aumüller, and Rasmus Pagh. 2022. Deann: Speeding up kernel-density estimation using approximate nearest neighbor search. In International Conference on Artificial Intelligence and Statistics. PMLR, 3108– 3137
2022
-
[55]
Fumiyuki Kato, Yang Cao, and Masatoshi Yoshikawa. 2023. Olive: Oblivious Federated Learning on Trusted Execution Environment Against the Risk of Sparsification.Proc. VLDB Endow.16, 10 (2023), 2404–2417. doi:10.14778/36035 81.3603583
-
[56]
Georgios Kellaris, George Kollios, Kobbi Nissim, and Adam O’Neill. 2016. Generic Attacks on Secure Outsourced Databases. InProc. of the 23rd ACM CCS. 1329–1340
2016
-
[57]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[58]
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. 2020. Reformer: The efficient transformer.arXiv preprint arXiv:2001.04451(2020)
work page internal anchor Pith review arXiv 2020
-
[59]
Andreas Kogler, Jonas Juffinger, Lukas Giner, Lukas Gerlach, Martin Schwarzl, Michael Schwarz, Daniel Gruss, and Stefan Mangard. 2023. Collide+Power: Leaking Inaccessible Data with Software-based Power Side Channels. In32nd USENIX security symposium (USENIX Security 2023). 7285–7302
2023
-
[61]
Data Recovery on Encrypted Databases With 𝑘-Nearest Neighbor Query Leakage. InProc. of the 40th IEEE S&P
-
[63]
The State of the Uniform: Attacks on Encrypted Databases Beyond the Uniform Query Distribution. InProc. of the 41th IEEE S&P
-
[64]
Kornaropoulos, Charalampos Papamanthou, and Roberto Tamassia
Evgenios M. Kornaropoulos, Charalampos Papamanthou, and Roberto Tamassia
-
[65]
Response-Hiding Encrypted Ranges: Revisiting Security via Parametrized Leakage-Abuse Attacks. InProc. of the 42nd IEEE S&P
-
[66]
Dayeol Lee, Dongha Jung, Ian T Fang, Chia-Che Tsai, and Raluca Ada Popa
-
[67]
In29th USENIX Security Symposium (USENIX Security 20)
An {Off-Chip} attack on hardware enclaves via the memory bus. In29th USENIX Security Symposium (USENIX Security 20)
-
[68]
Dayeol Lee, David Kohlbrenner, Shweta Shinde, Krste Asanović, and Dawn Song. 2020. Keystone: An open framework for architecting trusted execution environments. InProceedings of the Fifteenth European Conference on Computer Systems. 1–16
2020
-
[69]
Sangho Lee, Ming-Wei Shih, Prasun Gera, Taesoo Kim, Hyesoon Kim, and Mar- cus Peinado. 2017. Inferring fine-grained control flow inside {SGX} enclaves with branch shadowing. In26th USENIX Security Symposium (USENIX Security 17). 557–574
2017
-
[70]
Ding Li, Ziqi Zhang, Mengyu Yao, Yifeng Cai, Yao Guo, and Xiangqun Chen
-
[71]
Teeslice: Protecting sensitive neural network models in trusted execution environments when attackers have pre-trained models.ACM Transactions on Software Engineering and Methodology34, 6 (2025), 1–49
2025
-
[72]
Ji Lin, Yongming Rao, Jiwen Lu, and Jie Zhou. 2017. Runtime neural pruning. Advances in neural information processing systems30 (2017)
2017
-
[73]
Yehuda Lindell. 2017. How to simulate it–a tutorial on the simulation proof technique.Tutorials on the Foundations of Cryptography: Dedicated to Oded Goldreich(2017), 277–346
2017
-
[74]
Moritz Lipp, Andreas Kogler, David Oswald, Michael Schwarz, Catherine Eas- don, Claudio Canella, and Daniel Gruss. 2021. PLATYPUS: Software-based power side-channel attacks on x86. In2021 IEEE Symposium on Security and Privacy (SP). IEEE, 355–371
2021
-
[75]
Qin Lv, William Josephson, Zhe Wang, Moses Charikar, and Kai Li. 2007. Multi- probe LSH: efficient indexing for high-dimensional similarity search. InPro- ceedings of the 33rd international conference on Very large data bases. 950–961
2007
-
[76]
Sinisa Matetic, Mansoor Ahmed, Kari Kostiainen, Aritra Dhar, David Sommer, Arthur Gervais, Ari Juels, and Srdjan Capkun. 2017. {ROTE}: Rollback protec- tion for trusted execution. In26th USENIX Security Symposium (USENIX Security 17). 1289–1306
2017
-
[77]
Apostolos Mavrogiannakis, Xian Wang, Ioannis Demertzis, Dimitrios Pa- padopoulos, and Minos Garofalakis. 2025. {OBLIVIATOR}:{OBLIVIous} Par- allel Joins and other {OperATORs} in Shared Memory Environments. In34th USENIX Security Symposium (USENIX Security 25). 8521–8540
2025
-
[78]
Tharun Kumar Reddy Medini, Qixuan Huang, Yiqiu Wang, Vijai Mohan, and Anshumali Shrivastava. 2019. Extreme Classification in Log Memory using Count-Min Sketch: A Case Study of Amazon Search with 50M Products. In Advances in Neural Information Processing Systems. 13244–13254
2019
-
[79]
Nicholas Meisburger, Vihan Lakshman, Benito Geordie, Joshua Engels, David Torres Ramos, Pratik Pranav, Benjamin Coleman, Benjamin Meisburger, Shubh Gupta, Yashwanth Adunukota, et al. 2023. BOLT: An Automated Deep Learning Framework for Training and Deploying Large-Scale Search and Rec- ommendation Models on Commodity CPU Hardware. InProceedings of the 32n...
2023
-
[80]
Pratyush Mishra, Rishabh Poddar, Jerry Chen, Alessandro Chiesa, and Raluca Ada Popa. 2018. Oblix: An efficient oblivious search index. In2018 IEEE Symposium on Security and Privacy (SP). IEEE, 279–296
2018
-
[81]
Sparsh Mittal, Poonam Rajput, and Sreenivas Subramoney. 2021. A survey of deep learning on CPUs: opportunities and co-optimizations.IEEE Transactions on Neural Networks and Learning Systems33, 10 (2021), 5095–5115
2021
-
[82]
Ahmad Moghimi, Gorka Irazoqui, and Thomas Eisenbarth. 2017. Cachezoom: How SGX amplifies the power of cache attacks. InCryptographic Hardware and Embedded Systems–CHES 2017: 19th International Conference, Taipei, Taiwan, September 25-28, 2017, Proceedings. Springer, 69–90
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.