Arrow: A Foundation Model for Causal Discovery
Pith reviewed 2026-05-11 02:49 UTC · model grok-4.3
The pith
A transformer pretrained on synthetic causal graphs can discover directed acyclic structures zero-shot on new tabular datasets by predicting skeletons and topological orders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Arrow factorizes a directed acyclic graph into an undirected skeleton and a topological order, guaranteeing acyclicity by construction. Given a new dataset, it uses a transformer-based architecture to contextualize variables within and across observations, then predicts skeleton edge probabilities and node order scores that together define a graph. Arrow is trained in a supervised fashion on synthetic datasets with ground-truth graphs, using an end-to-end differentiable directed edge composite likelihood induced by the skeleton-order factorization. The training distribution spans diverse graph families, functional forms, noise models, and dataset shapes.
What carries the argument
Skeleton-order factorization of a DAG, which separates undirected edge presence from direction via a consistent ordering and allows a transformer to predict both components separately.
If this is right
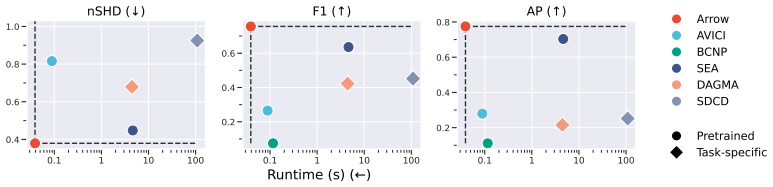
- Arrow achieves matching or superior accuracy to existing causal discovery algorithms on in-distribution, out-of-distribution synthetic, semi-synthetic, and real tabular data.
- Inference cost is substantially lower than that of competitive alternatives while maintaining accuracy.
- The model can be applied directly to new datasets without retraining or fine-tuning.
- Large-scale supervised pretraining on diverse synthetic causal data produces reusable zero-shot models.
Where Pith is reading between the lines
- This approach suggests that causal discovery could shift toward reusable pretrained models rather than per-dataset optimization.
- It opens the possibility of scaling the same architecture to higher-dimensional or streaming data where traditional search-based methods become intractable.
- Domain adaptation techniques could be applied on top of the zero-shot model to handle specific real-world data regimes not captured in the original synthetic mix.
Load-bearing premise
The distribution of synthetic training graphs, functional forms, noise models, and dataset shapes is representative enough of real-world observational data that the pretrained model generalizes zero-shot without domain-specific fine-tuning.
What would settle it
Performance of Arrow falling below competitive baselines on a collection of real-world observational datasets whose variable distributions and causal mechanisms lie outside the span of the synthetic training families.
Figures





read the original abstract
We introduce Arrow, a foundation model for zero-shot causal discovery on observational tabular data. Arrow factorizes a directed acyclic graph into an undirected skeleton and a topological order, guaranteeing acyclicity by construction. Given a new dataset, it uses a transformer-based architecture to contextualize variables within and across observations, then predicts skeleton edge probabilities and node order scores that together define a graph. Arrow is trained in a supervised fashion on synthetic datasets with ground-truth graphs, using an end-to-end differentiable directed edge composite likelihood induced by the skeleton-order factorization. The training distribution spans diverse graph families, functional forms, noise models, and dataset shapes. Across in- and out-of-distribution synthetic, semi-synthetic, and real datasets, Arrow matches or outperforms existing causal discovery methods at substantially lower inference cost than competitive alternatives. Our results demonstrate that large-scale pretraining on diverse synthetic data can yield zero-shot causal discovery models that are fast, accurate, and reusable on new datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Arrow, a foundation model for zero-shot causal discovery on observational tabular data. It factorizes a directed acyclic graph into an undirected skeleton and a topological order to guarantee acyclicity by construction. A transformer-based architecture contextualizes variables within and across observations to predict skeleton edge probabilities and node order scores. The model is trained in a supervised fashion on synthetic datasets spanning diverse graph families, functional forms, noise models, and dataset shapes, using an end-to-end differentiable directed edge composite likelihood. The central claim is that across in- and out-of-distribution synthetic, semi-synthetic, and real datasets, Arrow matches or outperforms existing causal discovery methods at substantially lower inference cost.
Significance. If the zero-shot generalization results hold, the work is significant because it shows that large-scale pretraining on synthetic data can produce a fast, reusable model for causal discovery, addressing the high per-dataset computational cost of traditional methods. The skeleton-order factorization provides a clean architectural guarantee of acyclicity, and the transformer contextualization is a natural fit for tabular data. Explicit credit is due for the end-to-end differentiable training objective and the breadth of the synthetic training ensemble.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central performance claim asserts that Arrow 'matches or outperforms' baselines across dataset types at lower inference cost, yet the manuscript supplies no quantitative metrics, baseline details, statistical significance tests, ablation studies, or error bars in the abstract and only limited reporting in §4. This is load-bearing for the empirical contribution and prevents assessment of post-hoc selection or robustness.
- [§3.2] §3.2 (Training Distribution): The zero-shot generalization to real datasets is the load-bearing assumption. The description of the synthetic ensemble (graph families, functional forms, noise models, dataset shapes) does not include any coverage analysis, ablation, or diagnostic showing that properties such as hidden confounding, non-additive mechanisms, or distribution shifts typical of real observational data are adequately represented. Without this, the transfer claim rests on an untested coverage assumption rather than demonstrated robustness.
minor comments (2)
- [§3.1] §3.1: The composite likelihood objective is described at a high level; an explicit equation defining the factorization into skeleton and order terms would improve clarity and reproducibility.
- [Figure 1 and §2] Figure 1 and §2: The diagram of the skeleton-order factorization is helpful but would benefit from an accompanying equation reference showing how the predicted probabilities are combined into a final DAG.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below and outline the revisions we will make to strengthen the empirical presentation and justification of generalization.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central performance claim asserts that Arrow 'matches or outperforms' baselines across dataset types at lower inference cost, yet the manuscript supplies no quantitative metrics, baseline details, statistical significance tests, ablation studies, or error bars in the abstract and only limited reporting in §4. This is load-bearing for the empirical contribution and prevents assessment of post-hoc selection or robustness.
Authors: We agree that the abstract is high-level and omits specific metrics to remain concise. In the revised manuscript we will update the abstract to include key quantitative highlights such as average performance gains (e.g., in SHD or F1) and inference-time reductions relative to competitive baselines. Section 4 already contains tables and figures comparing Arrow to multiple methods across in-distribution, out-of-distribution, semi-synthetic, and real datasets; however, we acknowledge that additional statistical significance tests, error bars, and ablation studies would improve transparency. We will add these elements, including ablations on the skeleton-order factorization and training diversity, to allow readers to assess robustness and rule out post-hoc selection. revision: yes
-
Referee: [§3.2] §3.2 (Training Distribution): The zero-shot generalization to real datasets is the load-bearing assumption. The description of the synthetic ensemble (graph families, functional forms, noise models, dataset shapes) does not include any coverage analysis, ablation, or diagnostic showing that properties such as hidden confounding, non-additive mechanisms, or distribution shifts typical of real observational data are adequately represented. Without this, the transfer claim rests on an untested coverage assumption rather than demonstrated robustness.
Authors: The synthetic training distribution was constructed to span a wide variety of graph families, functional forms, noise models, and dataset shapes precisely to support generalization. While §3.2 describes these choices, we recognize that it lacks explicit coverage diagnostics or targeted ablations for properties such as hidden confounding and non-additive mechanisms. We will revise §3.2 to include a more detailed discussion of how the ensemble addresses these aspects, supported by citations to the empirical results on semi-synthetic and real datasets that serve as the primary evidence of transfer. We will not introduce entirely new large-scale ablations if they fall outside the scope of a revision. revision: partial
Circularity Check
No significant circularity; supervised training and external evaluation are independent of inputs
full rationale
The paper trains a transformer model in supervised fashion on synthetic datasets that include ground-truth graphs, using a composite likelihood derived from the skeleton-order factorization. This factorization guarantees acyclicity by construction as an architectural choice, but the reported performance claims (matching or outperforming baselines on held-out synthetic, semi-synthetic, and real datasets) are measured against external methods and data, not derived tautologically from the training inputs or fitted parameters. No load-bearing self-citations, ansatzes smuggled via prior work, or predictions that reduce to the model's own definitions are present in the abstract or described methodology. The zero-shot generalization to real data is an empirical result, not a self-referential derivation.
Axiom & Free-Parameter Ledger
free parameters (2)
- Transformer architecture hyperparameters
- Composite likelihood weighting
axioms (2)
- standard math Any DAG can be exactly represented by an undirected skeleton plus a topological order.
- domain assumption The synthetic data generator spans the relevant characteristics of real observational data.
Reference graph
Works this paper leans on
-
[1]
Ralph Allan Bradley and Milton E Terry , title =. Biometrika , volume =
-
[2]
Mathematical Programming , volume =
Xiaoye Jiang and Lek-Heng Lim and Yuan Yao and Yinyu Ye , title =. Mathematical Programming , volume =
-
[3]
Léon Bottou and Frank E Curtis and Jorge Nocedal , journal =
-
[4]
Kyle Cranmer and Johann Brehmer and Gilles Louppe , journal =
-
[5]
Noah Hollmann and Samuel Müller and Katharina Eggensperger and Frank Hutter , booktitle =
-
[6]
Jordan Hoffmann and Sebastian Borgeaud and Arthur Mensch and Elena Buchatskaya and Trevor Cai and Eliza Rutherford and Diego de Las Casas and Lisa Anne Hendricks and Johannes Welbl and Aidan Clark and Tom Hennigan and Eric Noland and Katie Millican and George van den Driessche and Bogdan Damoc and Aurelia Guy and Simon Osindero and Karen Simonyan and Eric...
-
[7]
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , note =
-
[8]
Samuel Müller and Noah Hollmann and Sebastian Pineda Arango and Josif Grabocka and Frank Hutter , booktitle =
-
[9]
Ryan L Murphy and Balasubramaniam Srinivasan and Vinayak Rao and Bruno Ribeiro , booktitle =
-
[10]
Xun Zheng and Bryon Aragam and Pradeep Ravikumar and Eric P Xing , booktitle =
-
[11]
Kevin Bello and Bryon Aragam and Pradeep Ravikumar , booktitle =
-
[12]
Menghua Wu and Yujia Bao and Regina Barzilay and Tommi S Jaakkola , journal =
-
[13]
Lars Lorch and Scott Sussex and Jonas Rothfuss and Andreas Krause and Bernhard Schölkopf , booktitle =
-
[14]
Bryan Andrews and Joseph Ramsey and Ruben Sanchez-Romero and Jazmin Camchong and Erich Kummerfeld , booktitle =
-
[15]
Ilya Loshchilov and Frank Hutter , booktitle =
-
[16]
Dan Hendrycks and Kevin Gimpel , title =
-
[17]
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N Gomez and Łukasz Kaiser and Illia Polosukhin , booktitle =
-
[18]
Karen Sachs and Omar Perez and Dana Pe'er and Douglas A Lauffenburger and Garry P Nolan , number =. Science , pages =
-
[19]
R Duncan Luce , title =
-
[20]
Journal of the Royal Statistical Society: Series C (Applied Statistics) , pages =
R L Plackett , number =. Journal of the Royal Statistical Society: Series C (Applied Statistics) , pages =
-
[21]
Peter Spirtes and Clark Glymour and Richard Scheines , address =
-
[22]
Judea Pearl , address =
-
[23]
Developmental Psychology , pages =
E Michael Foster , number =. Developmental Psychology , pages =
-
[24]
Journal of Economic Literature , pages =
Guido W Imbens , number =. Journal of Economic Literature , pages =
-
[25]
International Journal of Epidemiology , pages =
Peter W G Tennant and Eleanor J Murray and Kellyn F Arnold and Laurie Berrie and Matthew P Fox and Sarah C Gadd and Wendy J Harrison and Claire Keeble and Lynsie R Ranker and Johannes Textor and Georgia D Tomova and Mark S Gilthorpe and George T H Ellison , number =. International Journal of Epidemiology , pages =
-
[26]
Anish Dhir and Matthew Ashman and James Requeima and Mark van der Wilk , booktitle =
-
[27]
Achille Nazaret and Justin Hong and Elham Azizi and David Blei , booktitle =
-
[28]
Graham Brightwell and Peter Winkler , journal =
-
[29]
Cristiano Varin and Nancy Reid and David Firth , journal =
-
[30]
Publicationes Mathematicae Debrecen , pages =
P Erdős and A Rényi , number =. Publicationes Mathematicae Debrecen , pages =
- [31]
-
[32]
Juho Lee and Yoonho Lee and Jungtaek Kim and Adam R Kosiorek and Seungjin Choi and Yee Whye Teh , booktitle =
-
[33]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Jingang Qu and David Holzmüller and Gaël Varoquaux and Marine. Proceedings of the 42nd International Conference on Machine Learning , pages =
-
[34]
Noah Hollmann and Samuel Müller and Lennart Purucker and Arjun Krishnakumar and Max Körfer and Shi Bin Hoo and Robin Tibor Schirrmeister and Frank Hutter , number =. Nature , pages =
-
[35]
Jimmy Lei Ba and Jamie Ryan Kiros and Geoffrey E Hinton , title =
-
[36]
Journal of Machine Learning Research , volume =
David Maxwell Chickering , title =. Journal of Machine Learning Research , volume =
-
[37]
Xun Zheng and Chen Dan and Bryon Aragam and Pradeep Ravikumar and Eric Xing , title =. Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics , volume =
-
[38]
Advances in Neural Information Processing Systems , volume =
Lars Lorch and Jonas Rothfuss and Bernhard Schölkopf and Andreas Krause , title =. Advances in Neural Information Processing Systems , volume =
-
[39]
International Conference on Learning Representations , year =
Bertrand Charpentier and Simon Kibler and Stephan Günnemann , title =. International Conference on Learning Representations , year =
-
[40]
Edwin V Bonilla and Pantelis Elinas and He Zhao and Maurizio Filippone and Vassili Kitsios and Terry O'Kane , title =
-
[41]
Advances in Neural Information Processing Systems , volume =
Ryan Thompson and Edwin V Bonilla and Robert Kohn , title =. Advances in Neural Information Processing Systems , volume =
-
[42]
Bo Peng and Sirui Chen and Jiaguo Tian and Yu Qiao and Chaochao Lu , title =
-
[43]
Proceedings of the 41st International Conference on Machine Learning , volume =
Alan Nawzad Amin and Andrew Gordon Wilson , title =. Proceedings of the 41st International Conference on Machine Learning , volume =
-
[44]
Proceedings of the 36th International Conference on Machine Learning , volume =
Yue Yu and Jie Chen and Tian Gao and Mo Yu , title =. Proceedings of the 36th International Conference on Machine Learning , volume =
-
[45]
Advances in Neural Information Processing Systems , volume =
Ignavier Ng and AmirEmad Ghassami and Kun Zhang , title =. Advances in Neural Information Processing Systems , volume =
-
[46]
Journal of Machine Learning Research , volume =
Markus Kalisch and Peter Bühlmann , title =. Journal of Machine Learning Research , volume =
-
[47]
International Conference on Learning Representations , year =
Bao Duong and Sunil Gupta and Thin Nguyen , title =. International Conference on Learning Representations , year =
-
[48]
International Conference on Learning Representations , year =
Nan Rosemary Ke and Silvia Chiappa and Jane X Wang and Jorg Bornschein and Anirudh Goyal and Melanie Rey and Theophane Weber and Matthew Botvinick and Michael Curtis Mozer and Danilo Jimenez Rezende , title =. International Conference on Learning Representations , year =
-
[49]
Journal of Data Science , volume =
Anne Helby Petersen and Joseph Ramsey and Claus Thorn Ekstrøm and Peter Spirtes , title =. Journal of Data Science , volume =
-
[50]
Naiyu Yin and Tian Gao and Yue Yu , title =
-
[51]
Wenbo Xu and Yue He and Yunhai Wang and Xingxuan Zhang and Kun Kuang and Yueguo Chen and Peng Cui , title =
-
[52]
Omar Swelam and Lennart Purucker and Jake Robertson and Hanne Raum and Joschka Boedecker and Frank Hutter , title =
-
[53]
Weronika Ormaniec and Scott Sussex and Lars Lorch and Bernhard Schölkopf and Andreas Krause , booktitle =
-
[54]
Yuqin Yang and Mohamed Nafea and AmirEmad Ghassami and Negar Kiyavash , booktitle =
-
[55]
Rebecca J Herman and Jonas Wahl and Urmi Ninad and Jakob Runge , booktitle =
- [56]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.