Recognition: no theorem link
EnvSimBench: A Benchmark for Evaluating and Improving LLM-Based Environment Simulation
Pith reviewed 2026-05-11 01:30 UTC · model grok-4.3
The pith
LLMs achieve near-perfect accuracy simulating static environments but fail when actions require updating multiple states at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
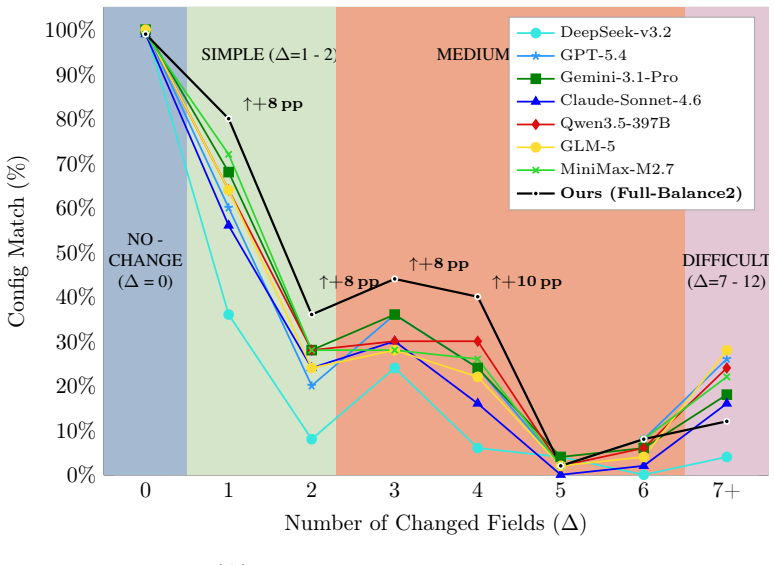
Environment Simulation Ability is formally defined as the capacity of an LLM to generate accurate environmental feedback and maintain consistent state transitions in response to agent actions. Systematic testing on EnvSimBench shows that state-of-the-art models achieve near-perfect performance on invariant-state tasks but suffer catastrophic failures on multi-state update tasks, revealing a universal state change cliff. A constraint-driven simulation pipeline reduces hallucinations, increases environment synthesis yield by 6.8 percent, and cuts costs by more than 90 percent.
What carries the argument
The state change cliff, the observed sharp accuracy drop when LLMs must track and update several environment variables simultaneously rather than leaving the state invariant.
If this is right
- LLM-based environment construction becomes practical for scalable agent training only after the multi-state update failure is mitigated.
- Agent reward signals remain uncorrupted when the constraint-driven pipeline is applied during simulation.
- The three-axis difficulty stratification in EnvSimBench allows targeted diagnosis of where current models break.
- Construction costs for interactive environments fall by more than 90 percent once the pipeline replaces manual design.
Where Pith is reading between the lines
- If the cliff proves fundamental to transformer architectures, hybrid LLM-symbolic state trackers may be required for any complex simulation task.
- The same benchmark structure could be applied to test simulation fidelity in planning domains or multi-agent games beyond the current 167 environments.
- Addressing the cliff may improve LLM performance on other tasks that demand consistent tracking of changing facts, such as long-horizon reasoning.
Load-bearing premise
The 400 samples across 167 environments, with their verifiable labels and three-axis stratification, represent the broader space of interactive environments without selection or labeling bias.
What would settle it
Re-running the full evaluation suite on a fresh collection of 500 environments that each require at least two simultaneous state updates and checking whether the accuracy cliff still appears across the same models.
Figures





read the original abstract
Scalable AI agents training relies on interactive environments that faithfully simulate the consequences of agent actions. Manually crafted environments are expensive to build, brittle to extend, and fundamentally limited in diversity. A promising direction is to replace manually crafted environments with LLM-simulated counterparts. However, this paradigm hinges on an unexamined core assumption: LLMs can accurately simulate environmental feedback. In practice, LLM-simulated environments suffer from hallucinations, logical inconsistencies, and silent state drift failures that corrupt agent reward signals and compound the construction costs that the paradigm was designed to eliminate. To address this gap, we propose EnvSimBench with four contributions: 1) We provide the first formal definition and operationalization of Environment Simulation Ability (EnvSim Ability) as a quantifiable research objective. 2) We construct EnvSimBench, a rigorous benchmark covering 400 samples across 167 diverse environments, equipped with verifiable labels and fine-grained difficulty stratification along three axes. 3) Systematic evaluations reveal that all state-of-the-art language models suffer from a universal state change cliff: they achieve near-perfect accuracy on tasks when the environment state remains invariant, yet fail catastrophically when multiple states need simultaneous updates. This finding exposes EnvSim Ability as a critical yet largely unaddressed capability gap. 4) We design a constraint-driven simulation pipeline that substantially reduces hallucination, boosts environment synthesis yield by 6.8%, and cuts costs by over 90%. Overall, EnvSimBench serves as both a diagnostic framework and a practical optimization path for reliable LLM-based environment simulation, establishing a foundation for scalable agent training. Code and data are available at https://github.com/cookieApril/EnvSimBench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EnvSimBench as the first benchmark for quantifying Environment Simulation Ability (EnvSim Ability) in LLMs used for interactive agent environments. It formally defines the ability, constructs a dataset of 400 samples drawn from 167 environments equipped with verifiable labels and three-axis difficulty stratification, reports systematic evaluations showing that all tested state-of-the-art LLMs exhibit a 'state change cliff' (near-perfect accuracy on invariant-state tasks but catastrophic failure on tasks requiring simultaneous multi-state updates), and presents a constraint-driven simulation pipeline that raises environment synthesis yield by 6.8% while cutting costs by over 90%. Code and data are released publicly.
Significance. If the benchmark successfully isolates the number of simultaneous state updates as the causal variable, the identification of a universal state change cliff would constitute a substantive contribution by exposing a previously unaddressed limitation in LLM-based environment simulation, a prerequisite for scalable agent training. The open release of code and data at the cited GitHub repository is a clear strength that supports reproducibility and follow-on work. The practical pipeline offers an immediately usable optimization route. Significance is tempered by the need for stronger validation that the observed cliff is not an artifact of benchmark construction.
major comments (2)
- [§3.2] §3.2 (Benchmark Construction): The central claim of a universal state change cliff requires that the 400 samples isolate the count of simultaneous state updates while holding constant or controlling for confounders such as prompt length, description complexity, and action-space size. The manuscript states that the benchmark uses 'verifiable labels' and 'fine-grained difficulty stratification along three axes,' yet provides no quantitative controls (e.g., correlation matrices between update count and the three axes, inter-annotator agreement for labels, or ablation removing label-source effects). Without these, the performance drop cannot be confidently attributed to state-update multiplicity rather than selection or labeling bias in the 167 environments.
- [§4] §4 (Experimental Results): The assertion that 'all state-of-the-art language models suffer from a universal state change cliff' is load-bearing for the paper's diagnostic contribution. The abstract reports 'near-perfect accuracy' on invariant tasks and 'catastrophic' failure on multi-update tasks, but the evaluation section must supply per-model accuracy tables, exact percentages, error bars, and statistical tests (e.g., paired t-tests or Wilcoxon ranks) comparing the two regimes. Absent these details, the universality and effect-size claims cannot be assessed.
minor comments (3)
- [§3.2] The three difficulty axes are referenced but never explicitly named or defined in the abstract or early sections; a table or paragraph listing them with example items would improve clarity.
- [§5] The 6.8% yield gain and >90% cost reduction are presented without a side-by-side baseline description or measurement protocol (e.g., how 'yield' is operationalized and what resources are counted in 'cost'). A short methods paragraph or supplementary table would suffice.
- [§2] Related-work discussion should explicitly contrast EnvSim Ability with adjacent notions such as world-model learning or causal reasoning to avoid potential overlap confusion.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and have revised the paper accordingly to strengthen the rigor of our claims regarding the state change cliff and benchmark validation.
read point-by-point responses
-
Referee: §3.2 (Benchmark Construction): The central claim requires isolating the count of simultaneous state updates while controlling for confounders like prompt length, description complexity, and action-space size. No quantitative controls such as correlation matrices, inter-annotator agreement, or ablations are provided, raising concerns about selection or labeling bias.
Authors: We agree that quantitative controls are necessary to confidently attribute the performance drop to state-update multiplicity. In the revised manuscript, we will add: (1) correlation matrices and analyses between update count and the three difficulty axes; (2) inter-annotator agreement scores for the verifiable labels; and (3) ablation studies isolating label-source effects. These will demonstrate that the benchmark isolates the intended variable and that the cliff is not an artifact of construction or bias. revision: yes
-
Referee: §4 (Experimental Results): The evaluation section must supply per-model accuracy tables, exact percentages, error bars, and statistical tests comparing invariant and multi-update regimes to support the universality and effect-size claims.
Authors: We acknowledge the need for more granular reporting. The revised §4 will include per-model accuracy tables with exact percentages for invariant-state versus multi-update tasks, error bars from repeated runs, and statistical tests (paired t-tests and Wilcoxon signed-rank) comparing the regimes. This will allow precise evaluation of universality and effect sizes. revision: yes
Circularity Check
No circularity: empirical benchmark construction and evaluation are self-contained
full rationale
The paper defines EnvSim Ability, constructs EnvSimBench with 400 new samples across 167 environments plus verifiable labels and three-axis stratification, runs evaluations on existing SOTA LLMs to report the state-change cliff observation, and introduces a constraint-driven pipeline. None of these steps reduce by definition, by fitted-parameter renaming, or by self-citation chain to the paper's own inputs; the central empirical claim is an external measurement on the newly created benchmark rather than an algebraic or definitional identity. The derivation chain therefore remains independent of the patterns that would trigger a positive circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM outputs can be treated as environment simulators when properly constrained
invented entities (1)
-
EnvSim Ability
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, Rongcheng Tu, Xiao Luo, Wei Ju, Zhiping Xiao, Yifan Wang, Meng Xiao, Chenwu Liu, Jingyang Yuan, Shichang Zhang, Yiqiao Jin, Fan Zhang, Xian Wu, Hanqing Zhao, Dacheng Tao, Philip S. Yu, and Ming Zhang. Large language model agent: A surve...
work page 2025
-
[2]
τ-bench: A benchmark for tool- agent-user interaction in real-world domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R Narasimhan. τ-bench: A benchmark for tool- agent-user interaction in real-world domains. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[3]
Userbench: An interactive gym environment for user-centric agents, 2025
Cheng Qian, Zuxin Liu, Akshara Prabhakar, Zhiwei Liu, Jianguo Zhang, Haolin Chen, Heng Ji, Weiran Yao, Shelby Heinecke, Silvio Savarese, Caiming Xiong, and Huan Wang. Userbench: An interactive gym environment for user-centric agents, 2025
work page 2025
-
[4]
Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[5]
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Felix Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, Zirui Wang, and Ruoming Pang. Toolsandbox: A stateful, conversational, interactive evaluation benchmark for llm tool use capabilities, 2025
work page 2025
-
[6]
Yuchen Huang, Sijia Li, Zhiyuan Fan, Minghao LIU, Wei Liu, and Yi R. Fung. Scaling environments for LLM agents: Fundamentals, approaches, and future directions. InWorkshop on Scaling Environments for Agents, 2025
work page 2025
-
[7]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
work page 2025
-
[8]
Are: Scaling up agent environments and evaluations, 2025
Romain Froger, Pierre Andrews, Matteo Bettini, Amar Budhiraja, Ricardo Silveira Cabral, Virginie Do, Emilien Garreau, Jean-Baptiste Gaya, Hugo Laurençon, Maxime Lecanu, Kunal Malkan, Dheeraj Mekala, Pierre Ménard, Gerard Moreno-Torres Bertran, Ulyana Piterbarg, Mikhail Plekhanov, Mathieu Rita, Andrey Rusakov, Vladislav V orotilov, Mengjue Wang, Ian Yu, Am...
work page 2025
-
[9]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[10]
Webarena: A realistic web environment for building autonomous agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[11]
{ALFW}orld: Aligning text and embodied environments for interactive learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Cote, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. {ALFW}orld: Aligning text and embodied environments for interactive learning. In International Conference on Learning Representations, 2021
work page 2021
-
[12]
Simulating environments with reasoning models for agent training, 2025
Yuetai Li, Huseyin A Inan, Xiang Yue, Wei-Ning Chen, Lukas Wutschitz, Janardhan Kulkarni, Radha Poovendran, Robert Sim, and Saravan Rajmohan. Simulating environments with reasoning models for agent training, 2025
work page 2025
-
[13]
Envscaler: Scaling tool-interactive environments for llm agent via programmatic synthesis, 2026
Xiaoshuai Song, Haofei Chang, Guanting Dong, Yutao Zhu, Ji-Rong Wen, and Zhicheng Dou. Envscaler: Scaling tool-interactive environments for llm agent via programmatic synthesis, 2026
work page 2026
-
[14]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, March 2023
work page 2023
-
[15]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review arXiv 2023
-
[16]
Siren’s song in the ai ocean: A survey on hallucination in large language models, 2025
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Chen Xu, Yulong Chen, Longyue Wang, Anh Tuan Luu, Wei Bi, Freda Shi, and Shuming Shi. Siren’s song in the ai ocean: A survey on hallucination in large language models, 2025
work page 2025
-
[17]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of lm agents with an lm-emulated sandbox, 2024
work page 2024
-
[18]
Yanai Elazar, Nora Kassner, Shauli Ravfogel, Abhilasha Ravichander, Eduard Hovy, Hinrich Schütze, and Yoav Goldberg. Measuring and improving consistency in pretrained language models.Transactions of the Association for Computational Linguistics, 9:1012–1031, 2021
work page 2021
-
[19]
Apigen-mt: Agentic pipeline for multi-turn data generation via simulated agent-human interplay, 2025
Akshara Prabhakar, Zuxin Liu, Ming Zhu, Jianguo Zhang, Tulika Awalgaonkar, Shiyu Wang, Zhiwei Liu, Haolin Chen, Thai Hoang, Juan Carlos Niebles, Shelby Heinecke, Weiran Yao, Huan Wang, Silvio Savarese, and Caiming Xiong. Apigen-mt: Agentic pipeline for multi-turn data generation via simulated agent-human interplay, 2025
work page 2025
-
[20]
Frans A Oliehoek and Christopher Amato.A Concise Introduction to Decentralized POMDPs. Springer, 2016
work page 2016
-
[21]
Interactive fiction games: A colossal adventure, 2020
Matthew Hausknecht, Prithviraj Ammanabrolu, Marc-Alexandre Côté, and Xingdi Yuan. Interactive fiction games: A colossal adventure, 2020
work page 2020
-
[22]
Webshop: Towards scalable real-world web interaction with grounded language agents, 2023
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents, 2023
work page 2023
-
[23]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2024. 11
work page 2024
-
[24]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?, 2024
work page 2024
-
[25]
Agentbench: Evaluating llms as agents, 2025
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating llms as agents, 2025
work page 2025
-
[26]
Mind2web: Towards a generalist agent for the web, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web, 2023
work page 2023
-
[27]
Agenttuning: Enabling generalized agent abilities for llms, 2023
Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. Agenttuning: Enabling generalized agent abilities for llms, 2023
work page 2023
-
[28]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, dahai li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, ...
work page 2024
-
[29]
Metatool benchmark for large language models: Deciding whether to use tools and which to use
Yue Huang, Jiawen Shi, Yuan Li, Chenrui Fan, Siyuan Wu, Qihui Zhang, Yixin Liu, Pan Zhou, Yao Wan, Neil Zhenqiang Gong, and Lichao Sun. Metatool benchmark for large language models: Deciding whether to use tools and which to use. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[30]
τ 2-bench: Evaluating conversational agents in a dual-control environment, 2025
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Evaluating conversational agents in a dual-control environment, 2025
work page 2025
-
[31]
APIGen-MT: Agentic pipeline for multi-turn data generation via simulated agent-human interplay
Akshara Prabhakar, Zuxin Liu, Ming Zhu, Jianguo Zhang, Tulika Manoj Awalgaonkar, Shiyu Wang, Zhiwei Liu, Haolin Chen, Thai Quoc Hoang, Juan Carlos Niebles, Shelby Heinecke, Weiran Yao, Huan Wang, Silvio Savarese, and Caiming Xiong. APIGen-MT: Agentic pipeline for multi-turn data generation via simulated agent-human interplay. InThe Thirty-ninth Annual Con...
work page 2026
-
[32]
LlamaFactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. LlamaFactory: Unified efficient fine-tuning of 100+ language models. In Yixin Cao, Yang Feng, and Deyi Xiong, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 400–410, Bangkok, Thailand, August 2024...
work page 2024
-
[33]
add blocked entries for 2025-05-01 through 2025-05-10
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: memory optimizations toward training trillion parameter models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’20. IEEE Press, 2020. 12 A Detailed Per-Delta Experimental Results A.1 Simple Group (∆∈ {1,2}) Table 5: R...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.