Parallel Lifted Planning via Semi-Naive Datalog Evaluation
Pith reviewed 2026-05-11 01:56 UTC · model grok-4.3
The pith
Lifted planners using parallel semi-naive Datalog evaluation solve more tasks than baselines, with speedups increasing on multiple cores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
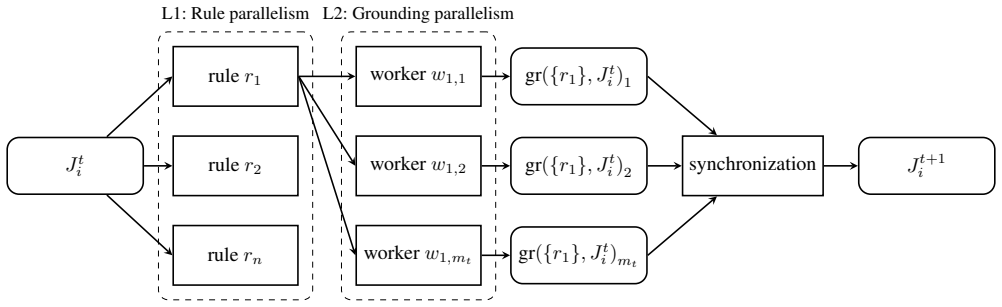
The central claim is that introducing two levels of parallelism in semi-naive Datalog evaluation, combined with a planning-specific grounder based on clique enumeration, enables lifted planners to solve more tasks and achieve substantial speedups on multi-core systems compared to existing approaches.
What carries the argument
Two-level parallel execution model (rule-level parallelism and grounding parallelism) for semi-naive Datalog evaluation, powered by a clique-enumeration grounder.
If this is right
- The implementation solves more tasks than baselines using greedy best-first search with the FF heuristic.
- The performance gap widens as additional cores are used.
- On hard-to-ground tasks, an average parallel fraction of 92.4% is achieved where Datalog takes 97.6% of runtime.
- Up to a 6-fold speedup is realized on 8 cores in practice.
Where Pith is reading between the lines
- This parallel Datalog approach could be applied to other lifted or relational reasoning tasks in artificial intelligence.
- Integrating it with different heuristics or search algorithms might yield further gains in planning efficiency.
- The technique suggests lifted planning can scale better with hardware parallelism, potentially reducing reliance on full grounding methods.
Load-bearing premise
The measured parallel fraction and speedups will generalize beyond the chosen benchmark set and that the overhead of the new grounder and parallelism management remains negligible when Datalog is not the dominant cost.
What would settle it
Evaluating the planner on a different set of planning benchmarks with varying ratios of grounding time to see if task coverage and speedups still exceed those of the baselines.
Figures

read the original abstract
Lifted classical planners operate directly on first-order planning tasks to avoid the computationally demanding grounding step. However, lifted planning is typically slower, as planners must repeatedly instantiate ground structures during search. Many core components of lifted classical planning, such as successor generation, axiom evaluation, task grounding, and delete-relaxed heuristics, have previously been studied through the lens of Datalog evaluation. We build upon this line of work and extend it by developing and analyzing an execution model with two levels of parallelism: rule-level parallelism and grounding parallelism. We further specialize this solver for planning-specific workloads with a grounder based on clique enumeration, which we extend to support semi-naive Datalog evaluation. Our experimental evaluation using greedy best-first search with the FF heuristic shows that our implementation already solves more tasks than the baselines on a single core, and the gap widens as additional cores are used. Moreover, on hard-to-ground tasks where on average 97.6% of the total runtime is spent in Datalog execution, the proposed execution model exhibits an average parallel fraction of 92.4%, while achieving up to a 6-fold speedup on 8 cores in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a two-level parallel execution model (rule-level and grounding parallelism) for lifted classical planning by extending semi-naive Datalog evaluation. It introduces a planning-specialized grounder based on clique enumeration that supports semi-naive evaluation, and evaluates the resulting planner using greedy best-first search with the FF heuristic on standard benchmarks. The central empirical claims are that the implementation already solves more tasks than baselines on a single core (with the advantage increasing with core count), that Datalog execution dominates runtime (97.6% on hard-to-ground tasks), and that the model achieves an average parallel fraction of 92.4% with up to 6-fold speedup on 8 cores.
Significance. If the reported speedups and coverage gains hold under scrutiny, the work would be a meaningful step toward making lifted planning competitive by exploiting parallelism in the dominant Datalog components. The concrete metrics on parallel fraction and Datalog dominance on a recognizable benchmark subset provide a clear, falsifiable basis for assessing the approach's practical value.
major comments (2)
- §5 (Experimental Evaluation), paragraph on hard-to-ground task selection: the criteria used to identify the subset where Datalog accounts for 97.6% of runtime are not stated explicitly. Without this, it is impossible to verify that the reported parallel fraction and speedups are not an artifact of post-hoc filtering, which directly affects the strength of the scaling claim.
- §4.2 (Grounder based on clique enumeration) and §5.1 (baseline implementations): the paper does not provide sufficient detail on how the new grounder and the baseline lifted planners were implemented or whether they share the same underlying Datalog engine. This makes it difficult to isolate whether the observed single-core advantage stems from the parallel model, the clique-based grounder, or implementation differences.
minor comments (2)
- Figure 3 (speedup plots): axis labels and legend entries should explicitly state the number of cores and the exact metric (wall-clock time or CPU time) to avoid ambiguity in interpreting the 6-fold speedup.
- Table 1 (coverage results): include the total number of tasks per domain and the number of tasks solved by each configuration to allow direct computation of coverage percentages.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below with clarifications and commit to revisions that improve transparency without altering the core claims or results.
read point-by-point responses
-
Referee: §5 (Experimental Evaluation), paragraph on hard-to-ground task selection: the criteria used to identify the subset where Datalog accounts for 97.6% of runtime are not stated explicitly. Without this, it is impossible to verify that the reported parallel fraction and speedups are not an artifact of post-hoc filtering, which directly affects the strength of the scaling claim.
Authors: We agree that the selection criteria must be stated explicitly to permit verification and rule out post-hoc concerns. In the revised manuscript we will add a precise description of the criteria applied to the IPC benchmarks (based on runtime profiling that identified tasks with high Datalog dominance). This addition will make the subset reproducible and strengthen the empirical support for the reported parallel fraction and speedups. revision: yes
-
Referee: §4.2 (Grounder based on clique enumeration) and §5.1 (baseline implementations): the paper does not provide sufficient detail on how the new grounder and the baseline lifted planners were implemented or whether they share the same underlying Datalog engine. This makes it difficult to isolate whether the observed single-core advantage stems from the parallel model, the clique-based grounder, or implementation differences.
Authors: We acknowledge that the current level of detail is insufficient for isolating contributions and ensuring reproducibility. Our grounder is a planning-specialized clique-enumeration implementation extended to support semi-naive evaluation and integrated into our Datalog engine; baselines were evaluated within comparable search frameworks. In the revision we will expand §4.2 with additional algorithmic description of the grounder and §5.1 with explicit statements on shared versus distinct components of the Datalog engine. These changes will clarify the sources of the single-core coverage gains. revision: yes
Circularity Check
No significant circularity; purely empirical claims
full rationale
The paper's core contribution is an implementation of a two-level parallel execution model for lifted planning via semi-naive Datalog, together with a clique-enumeration grounder. All reported results (more tasks solved than baselines, 92.4% average parallel fraction, up to 6x speedup on 8 cores) are direct measurements on IPC benchmarks under greedy best-first search with FF heuristic. No equations, uniqueness theorems, or ansatzes are invoked whose outputs are definitionally identical to their inputs; the work cites prior Datalog-planning literature for context but does not rely on any self-citation chain to establish its measured performance. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard semantics of Datalog and semi-naive evaluation
Reference graph
Works this paper leans on
-
[1]
Abiteboul, S.; Hull, R.; and Vianu, V. 1995. Foundations of Databases. Addison-Wesley
work page 1995
-
[2]
Bancilhon, F.; and Ramakrishnan, R. 1986. An amateur's introduction to recursive query processing strategies. In Proceedings of the 1986 ACM SIGMOD International Conference on Management of Data, 16--52. Association for Computing Machinery
work page 1986
-
[3]
Bron, C.; and Kerbosch, J. 1973. Algorithm 457: finding all cliques of an undirected graph. Communications of the ACM, 16: 575--577
work page 1973
-
[4]
Ceri, S.; Gottlob, G.; and Tanca, L. 1989. What you Always Wanted to Know About Datalog (And Never Dared to Ask). IEEE Trans. Knowl. Data Eng., 1: 146--166
work page 1989
-
[5]
B.; Franc \`e s, G.; Pommerening, F.; and Helmert, M
Corr \^e a, A. B.; Franc \`e s, G.; Pommerening, F.; and Helmert, M. 2021. Delete-Relaxation Heuristics for Lifted Classical Planning. In Goldman, R. P.; Biundo, S.; and Katz, M., eds., Proceedings of the Thirty-First International Conference on Automated Planning and Scheduling (ICAPS 2021), 94--102. AAAI Press
work page 2021
-
[6]
B.; Pommerening, F.; Helmert, M.; and Franc \`e s, G
Corr \^e a, A. B.; Pommerening, F.; Helmert, M.; and Franc \`e s, G. 2020. Lifted Successor Generation using Query Optimization Techniques. In Beck, J. C.; Karpas, E.; and Sohrabi, S., eds., Proceedings of the Thirtieth International Conference on Automated Planning and Scheduling (ICAPS 2020), 80--89. AAAI Press
work page 2020
-
[7]
B.; Pommerening, F.; Helmert, M.; and Franc \`e s, G
Corr \^e a, A. B.; Pommerening, F.; Helmert, M.; and Franc \`e s, G. 2022. The FF Heuristic for Lifted Classical Planning. In Honavar, V.; and Spaan, M., eds., Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence ( AAAI 2022) , 9716--9723. AAAI Press
work page 2022
-
[8]
Das, A.; and Zaniolo, C. 2019. A Case for Stale Synchronous Distributed Model for Declarative Recursive Computation. Theory and Practice of Logic Programming, 19: 1056--1072
work page 2019
-
[9]
Drexler, D. 2026. Loki: A PDDL Parser and Normalizer. https://doi.org/10.5281/zenodo.20081136
-
[10]
Gerevini, A.; Howe, A.; Cesta, A.; and Refanidis, I., eds. 2009. Proceedings of the Nineteenth International Conference on Automated Planning and Scheduling (ICAPS 2009). AAAI Press
work page 2009
-
[11]
Helmert, M. 2006. The Fast Downward Planning System. Journal of Artificial Intelligence Research, 26: 191--246
work page 2006
-
[12]
Helmert, M. 2009. Concise Finite-Domain Representations for PDDL Planning Tasks. Artificial Intelligence, 173: 503--535
work page 2009
-
[13]
Hoffmann, J.; and Nebel, B. 2001. The FF Planning System: Fast Plan Generation Through Heuristic Search. Journal of Artificial Intelligence Research, 14: 253--302
work page 2001
-
[14]
Jordan, H.; Scholz, B.; and Suboti \'c , P. 2016. Souffl \'e : On Synthesis of Program Analyzers. In International Conference on Computer Aided Verification
work page 2016
-
[15]
Kishimoto, A.; Fukunaga, A.; and Botea, A. 2009. Scalable, Parallel Best-First Search for Optimal Sequential Planning. In icaps2009 , 201--208
work page 2009
-
[16]
Kishimoto, A.; Fukunaga, A.; and Botea, A. 2013. Evaluation of a simple, scalable, parallel best-first search strategy. Artif. Intell., 195: 222--248
work page 2013
-
[17]
Q.; Porat, E.; R \' e , C.; and Rudra, A
Ngo, H. Q.; Porat, E.; R \' e , C.; and Rudra, A. 2018. Worst-case Optimal Join Algorithms. J. ACM , 65(3): 16:1--16:40
work page 2018
-
[18]
Phillips, C. A.; Wang, K.; Baker, E. J.; Bubier, J. A.; Chesler, E. J.; and Langston, M. A. 2019. On Finding and Enumerating Maximal and Maximum k-Partite Cliques in k-Partite Graphs. Algorithms, 12
work page 2019
-
[19]
Richter, S.; and Helmert, M. 2009. Preferred Operators and Deferred Evaluation in Satisficing Planning. In icaps2009 , 273--280
work page 2009
-
[20]
Shkapsky, A.; Yang, M.; Interlandi, M.; Chiu, H.; Condie, T.; and Zaniolo, C. 2016. Big Data Analytics with Datalog Queries on Spark. In \" O zcan, F.; Koutrika, G.; and Madden, S., eds., Proceedings of the 2016 International Conference on Management of Data, SIGMOD Conference 2016 , 1135--1149. ACM
work page 2016
-
[21]
St hlberg, S. 2023. Lifted Successor Generation by Maximum Clique Enumeration. In Gal, K.; Now \'e , A.; Nalepa, G. J.; Fairstein, R.; and R a dulescu, R., eds., Proceedings of the 26th European Conference on Artificial Intelligence ( ECAI 2023) , 2194--2201. IOS Press
work page 2023
-
[22]
Wang, K.; Yu, K.; and Long, C. 2024. Efficient k-Clique Listing: An Edge-Oriented Branching Strategy
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.