Structured Coupling for Flow Matching
Pith reviewed 2026-05-11 02:28 UTC · model grok-4.3
The pith
Structured latent variables can be added to flow matching to learn interpretable representations without sacrificing sample quality or requiring simulations
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
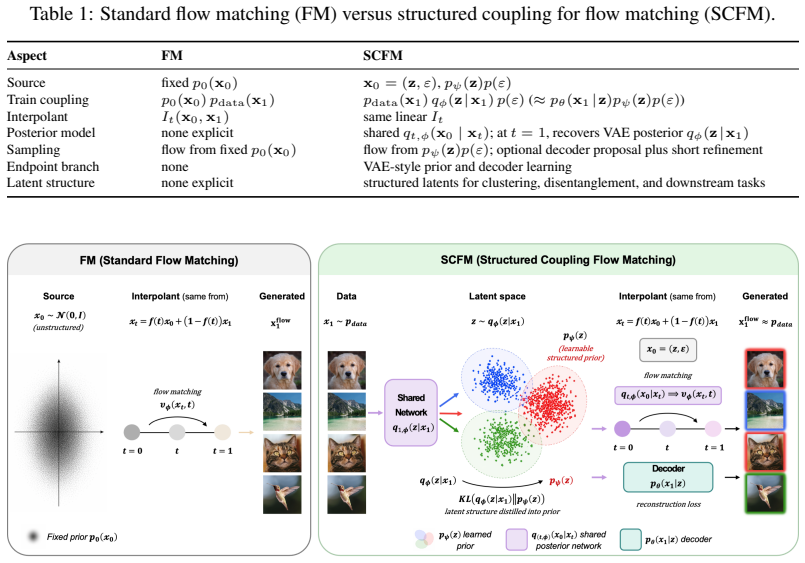
By introducing structured latent variables and exogenous noise into the source distribution, SCFM jointly learns a structured prior via latent variable modeling and a continuous transport map via flow matching. A single shared time-dependent recognition network performs variational inference for the prior and estimates the flow velocity at intermediate times. The outcome is a structurally informed yet unconditional, simulation-free flow model whose latent component can also assist sampling and whose generative quality stays competitive with standard flow matching.
What carries the argument
The shared time-dependent recognition network that simultaneously performs variational inference for the structured latent prior and estimates the conditional flow velocity at intermediate times
If this is right
- The model supports unsupervised learning of latent representations useful for clustering and disentanglement.
- The latent variable component can assist the flow sampling process.
- Generative sample quality remains competitive with standard flow matching.
- The framework produces a simulation-free flow model that is informed by learned structure.
Where Pith is reading between the lines
- The same shared-network coupling could be tried in other velocity-field models to add structure at low extra cost.
- The learned latents could be tested for use in conditional generation or editing tasks.
- Scaling the method to higher-dimensional or sequential data would test how well the joint training holds up.
Load-bearing premise
A single shared time-dependent recognition network can carry out both effective variational inference for the structured latent prior and accurate flow velocity estimation at all intermediate times without performance trade-offs that reduce generative fidelity.
What would settle it
Training the model on a standard image benchmark and observing either lower sample quality than pure flow matching or latent representations that fail to support better clustering or disentanglement than unstructured baselines would show the central claim is false.
Figures













read the original abstract
Standard flow matching scales well but typically relies on an unstructured source distribution, limiting its ability to learn interpretable latent structure. Latent-variable models, by contrast, capture structure but often sacrifice generative quality. We bridge this gap by proposing Structured Coupling for Flow Matching (SCFM), a cooperative framework that augments flow matching with structured latent representation learning. By introducing structured latent variables and exogenous noise into the source, SCFM jointly learns a structured prior (via latent variable modeling) and a continuous transport map (via flow matching). It uses a shared time-dependent recognition network for both latent variable model variational inference and intermediate-time flow velocity estimation. This yields a structurally informed yet unconditional, simulation-free flow model, where the latent variable model can also assist flow sampling. Empirically, SCFM facilitates unsupervised latent representation learning for clustering, disentanglement and downstream tasks, while remaining competitive with flow matching in sample quality, showing that meaningful structure can be learned without sacrificing generative fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Structured Coupling for Flow Matching (SCFM), a framework that augments standard flow matching by injecting structured latent variables and exogenous noise into the source distribution. It jointly optimizes a structured prior via latent-variable variational inference and a continuous transport map via flow matching, employing a single shared time-dependent recognition network q_φ(z_t | x, t) for both posterior approximation and conditional velocity regression. The result is claimed to be an unconditional, simulation-free generative model that remains competitive in sample quality while enabling unsupervised tasks such as clustering and disentanglement, with the latent model optionally assisting sampling.
Significance. If the central claim holds, SCFM would offer a practical bridge between the high-fidelity, simulation-free sampling of flow matching and the interpretable structure of latent-variable models, without the usual quality trade-off. The shared-network design and the empirical competitiveness with baseline flow matching would be notable contributions, particularly if the latent structure proves useful for downstream tasks. The work builds directly on established flow-matching and VAE literature rather than introducing entirely new primitives.
major comments (1)
- The central claim that structure can be learned without sacrificing generative fidelity rests on the shared time-dependent recognition network simultaneously performing accurate variational inference for the structured latent prior and accurate regression of the conditional velocity field v_t(x|z) at every intermediate t. No analysis, gradient-conflict measurements, or ablation studies on the joint loss are provided to demonstrate that the two objectives do not interfere, which directly undermines the assertion that the model remains competitive in sample quality while capturing meaningful structure.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of SCFM's potential contribution and for the detailed, constructive feedback. We address the major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: The central claim that structure can be learned without sacrificing generative fidelity rests on the shared time-dependent recognition network simultaneously performing accurate variational inference for the structured latent prior and accurate regression of the conditional velocity field v_t(x|z) at every intermediate t. No analysis, gradient-conflict measurements, or ablation studies on the joint loss are provided to demonstrate that the two objectives do not interfere, which directly undermines the assertion that the model remains competitive in sample quality while capturing meaningful structure.
Authors: We agree that explicit analysis of the joint optimization would strengthen the central claim. While the manuscript reports competitive sample quality (via FID and other metrics) alongside successful unsupervised tasks, it does not include dedicated measurements of gradient conflicts or ablations isolating the shared-network objectives. In the revised manuscript we will add: (1) cosine-similarity and norm-ratio measurements between gradients arising from the variational-inference term and the flow-matching term across training; (2) an ablation comparing the shared time-dependent recognition network against separate networks for posterior approximation and velocity regression; and (3) a sensitivity study on the relative weighting of the two loss components. These additions will directly address whether the objectives interfere and will support the assertion that meaningful structure can be captured without sacrificing fidelity. revision: yes
Circularity Check
No significant circularity; derivation builds on external FM and VAE literature
full rationale
The paper introduces SCFM as a cooperative framework combining structured latent variables with flow matching via a shared time-dependent recognition network. No equations or derivations are presented that reduce the central claims (structurally informed unconditional flow model, joint VI and velocity estimation) to self-definitions, fitted inputs renamed as predictions, or self-citation chains. The approach explicitly rests on standard flow-matching transport and variational inference from prior external literature rather than internal tautologies, making the proposal self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
structured latent variables injected into flow source
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alexander Alemi, Ben Poole, Ian Fischer, Joshua Dillon, Rif A
URLhttps://proceedings.mlr.press/v235/albergo24a.html. Alexander Alemi, Ben Poole, Ian Fischer, Joshua Dillon, Rif A. Saurous, and Kevin Murphy. Fixing a broken ELBO. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 159–168. PMLR, 10...
-
[2]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
URLhttps://openreview.net/forum?id=Sy2fzU9gl. R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization. InInternational Conference on Learning Representations, 2019. URL https: //openreview.net/forum?id=Bklr3j0cKX. J...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s11263-015-0816-y 2019
-
[3]
Structured Coupling for Flow Matching
URLhttps://openreview.net/forum?id=_BNiN4IjC5. Gianluigi Silvestri, Luca Ambrogioni, Chieh-Hsin Lai, Yuhta Takida, and Yuki Mitsufuji. VCT: Train- ing consistency models with variational noise coupling. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=CMoX0BEsDs. Jiaming Song, Chenlin Meng, and Stefano ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.