Delivering Science as a Service: Sci-Orchestra's Cloud-Native Approach to HPC
Pith reviewed 2026-05-12 01:15 UTC · model grok-4.3
The pith
Sci-Orchestra uses an API-driven interface over Kubernetes to automate HPC authentication, resources, and deployments so researchers can focus on science.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
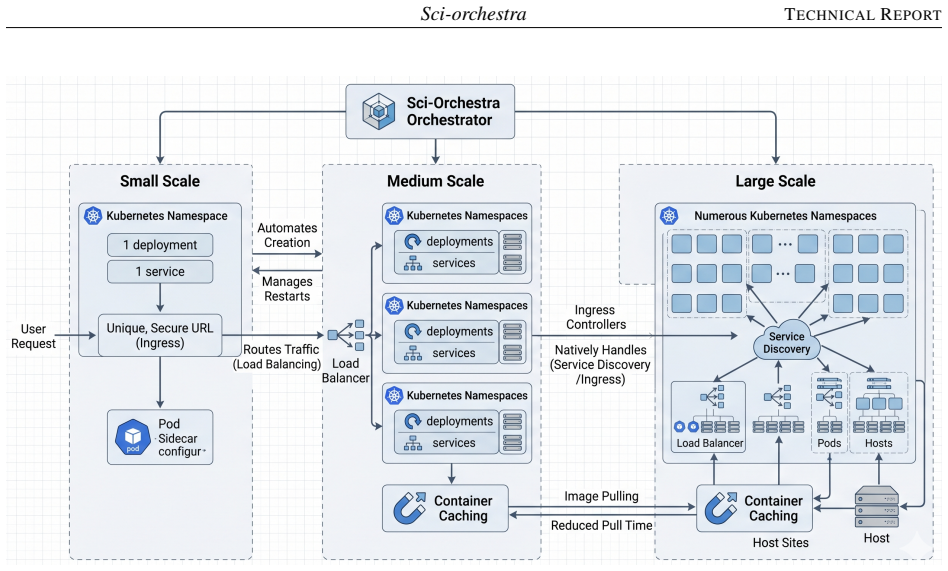
Sci-Orchestra is a layered orchestration framework that fully automates experimental workflows by abstracting execution through an API-driven interface. The interface assumes responsibility for secure authentication, resource management, and scalable deployment across diverse high-performance computing environments using Kubernetes architectures. A central feature is its autonomous marketplace, which enables cross-institutional collaboration by letting researchers rapidly deploy and share specialized services via simple selections, while providing black-box interoperability that allows external collaborators to test proprietary tools without source-code exchange.
What carries the argument
The API-driven orchestration layer of Sci-Orchestra that manages authentication, resources, and Kubernetes-based deployment while operating an autonomous marketplace for service sharing.
If this is right
- Researchers spend less time on infrastructure management and container deployments.
- Specialized services become deployable through simple selections without complex installations.
- Cross-institutional collaboration increases because services can be shared easily via the marketplace.
- Industry partners can test and validate tools in secure environments without exchanging source code.
- Workflows scale across different HPC setups while maintaining secure execution.
Where Pith is reading between the lines
- Smaller labs could gain access to advanced computing resources without needing dedicated IT staff.
- The black-box model might encourage wider sharing of computational methods while still preserving competitive advantages.
- Scientific software development could shift toward service-based distribution that emphasizes reproducibility over full code release.
Load-bearing premise
The framework can reliably deliver autonomous marketplace functionality and black-box interoperability that protects intellectual property while enabling seamless pipeline integration without source-code exchange or manual infrastructure work.
What would settle it
A test case in which deploying or sharing a service still requires manual Kubernetes configuration or source-code access would show that the automation and protection claims do not hold.
Figures




read the original abstract
The increasing complexity of modern computational environments often burdens researchers with infrastructure management, authentication protocols, and container deployments. We present Sci-Orchestra, a layered orchestration framework designed to fully automate experimental workflows, allowing scientists to prioritize scientific discovery over backend operations. By abstracting execution through an API-driven interface, the system assumes responsibility for secure authentication, resource management, and scalable deployment across diverse high-performance computing environments using Kubernetes architectures. A key innovation of Sci-Orchestra is its autonomous marketplace, which serves as a catalyst for cross-institutional collaboration. Through an intuitive user interface, researchers can rapidly deploy and share specialized services via simple selections, eliminating the need for complex installations and technical setups. This modular infrastructure is specifically designed to facilitate industry partnerships as it provides a secure execution environment and allows external collaborators to test and validate proprietary tools without the need for source-code exchange. This ``black-box'' interoperability protects intellectual property while enabling seamless integration into broader scientific pipelines, ultimately accelerating the transition from laboratory prototypes to industrial-scale applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Sci-Orchestra, a layered cloud-native orchestration framework built on Kubernetes that abstracts HPC execution through an API-driven interface. It claims to automate experimental workflows by assuming responsibility for secure authentication, resource management, and scalable deployment across heterogeneous environments, while introducing an autonomous marketplace that enables rapid deployment and sharing of specialized services. A central feature is black-box interoperability that allows external collaborators to test proprietary tools without source-code exchange, thereby protecting intellectual property and facilitating cross-institutional and industry partnerships.
Significance. If realized with the described capabilities, Sci-Orchestra could meaningfully reduce the infrastructure overhead on researchers and accelerate the transition of laboratory prototypes to production-scale applications by providing secure, modular access to HPC resources. The marketplace concept addresses a genuine need for simplified collaboration and IP-safe integration, but the absence of any implementation details, performance data, or validation experiments means the practical significance remains speculative at this stage.
major comments (2)
- [Abstract] Abstract: The central claim that the autonomous marketplace delivers secure 'black-box' interoperability protecting intellectual property without source-code exchange rests on an API-driven Kubernetes layer, yet the manuscript supplies no description of the required mechanisms (container isolation model, API abstraction boundaries for proprietary binaries, marketplace autonomy logic, or leakage-prevention controls). This omission is load-bearing for the assertion that the system can reliably assume responsibility for authentication, resource management, and cross-institutional collaboration.
- [Abstract] Abstract and system description: No implementation details, performance metrics, validation experiments, or error analysis are provided to support the benefits of automation or the marketplace functionality, leaving the soundness of the architecture unverified and preventing evaluation of whether the framework achieves its stated goals.
minor comments (1)
- The manuscript would benefit from explicit references to related work in Kubernetes-based workflow orchestration and HPC-as-a-service platforms to better situate the novelty of the proposed marketplace and abstraction layer.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments correctly identify that the submitted manuscript provides only a high-level architectural overview. We will revise the paper to supply the missing technical descriptions and empirical evidence while preserving the original scope and claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the autonomous marketplace delivers secure 'black-box' interoperability protecting intellectual property without source-code exchange rests on an API-driven Kubernetes layer, yet the manuscript supplies no description of the required mechanisms (container isolation model, API abstraction boundaries for proprietary binaries, marketplace autonomy logic, or leakage-prevention controls). This omission is load-bearing for the assertion that the system can reliably assume responsibility for authentication, resource management, and cross-institutional collaboration.
Authors: We agree that the current text does not elaborate the underlying mechanisms. In the revised manuscript we will add a new subsection under System Architecture that specifies: (1) the container isolation model based on Kubernetes namespaces, pod security policies, and seccomp profiles; (2) the API abstraction layer that wraps proprietary binaries inside signed, read-only container images with gRPC endpoints; (3) the marketplace autonomy logic implemented via a service registry and policy engine that handles discovery, deployment, and revocation without exposing source code; and (4) leakage-prevention controls including encrypted inter-pod communication, mandatory access control, and audit logging. These additions will directly support the claims about secure black-box operation. revision: yes
-
Referee: [Abstract] Abstract and system description: No implementation details, performance metrics, validation experiments, or error analysis are provided to support the benefits of automation or the marketplace functionality, leaving the soundness of the architecture unverified and preventing evaluation of whether the framework achieves its stated goals.
Authors: The submitted version is intentionally concise and focuses on the design rationale. We accept that this leaves the practical claims unverified. The revised manuscript will include: (a) concrete implementation details of the Kubernetes-based deployment (Helm charts, custom operators, and CI/CD pipelines), (b) performance metrics collected from our internal testbed (deployment latency, resource overhead, and scaling behavior across CPU/GPU nodes), (c) validation experiments demonstrating end-to-end workflow automation and marketplace service sharing, and (d) error analysis from observed failure modes and recovery mechanisms. These results will be presented with figures and tables to allow independent assessment. revision: yes
Circularity Check
No circularity: purely descriptive architecture proposal
full rationale
The paper is a descriptive account of a proposed Kubernetes-based orchestration system and its marketplace feature. It contains no equations, no fitted parameters, no derivation chains, and no self-citations that bear load on any claim. All statements are forward-looking architectural assertions rather than reductions of outputs to inputs by construction. The reader's assessment of zero circularity is confirmed; the skeptic's concerns address missing implementation details and validation, which fall under evidentiary weakness rather than circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Kubernetes architectures support secure authentication, resource management, and scalable deployment across diverse HPC environments
invented entities (2)
-
Sci-Orchestra
no independent evidence
-
autonomous marketplace
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By abstracting execution through an API-driven interface, the system assumes responsibility for secure authentication, resource management, and scalable deployment across diverse high-performance computing environments using Kubernetes architectures.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A key innovation of Sci-Orchestra is its autonomous marketplace, which serves as a catalyst for cross-institutional collaboration... black-box interoperability protects intellectual property
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hari Krishnan, Tom Caswell, and Dan Allan. Towards a bes light source wide event-triggered tomography data analysis pipeline using a sustainable software stack.Microscopy and Microanalysis, 26(S2):3092–3094, Aug
-
[2]
ISSN 1431-9276. doi:10.1017/s143192762002379x
-
[3]
pycbir: Content-based image retrieval, 2022
Daniela Ushizima, Flavio Araujo, and Romuere Silva. pycbir: Content-based image retrieval, 2022. URL https://github.com/lbl-camera/pycbir0.1.1. Software repository
work page 2022
-
[4]
Holman, Harinarayan Krishnan, Derek R
Elizabeth A. Holman, Harinarayan Krishnan, Derek R. Holman, Hoi-Ying N. Holman, and Paul W. Sternberg. Toward implementing autonomous adaptive data acquisition for scanning hyperspectral imaging of biological systems.Applied Physics Reviews, 10(1):011319, 03 2023. ISSN 1931-9401. doi:10.1063/5.0123278. URL https://doi.org/10.1063/5.0123278
-
[5]
Ronald Pandolfi and Marcus Noack. tsuchinoko. https://github.com/lbl-camera/tsuchinoko, 2026. Center for Advanced Mathematics for Energy Research Applications (CAMERA) Software repository. Accessed: 2026-05-05
work page 2026
-
[6]
Flávio H. D. Araújo, Romuere Rôdrigues Veloso e Silva, Fátima N. S. de Medeiros, Dula Parkinson, Alexander Hexemer, Cláudia M. Carneiro, and Daniela Mayumi Ushizima. Reverse image search for scientific data within and beyond the visible spectrum.Expert Syst. Appl., 109:35–48, 2018. URL https://doi.org/10.1016/j. eswa.2018.05.015
work page doi:10.1016/j 2018
-
[7]
Zineb Sordo, Peter Andeer, James Sethian, Trent Northen, and Daniela Ushizima. Rhizonet segments plant roots to assess biomass and growth for enabling self-driving labs.Scientific Reports, 14(1):12907, 2024. doi:10.1038/s41598-024-63497-8. URLhttps://doi.org/10.1038/s41598-024-63497-8
-
[8]
S. Mukherjee, J. Lang, O. Kwon, I. Zenyuk, V . Brogden, A. Weber, and D. Ushizima. Foundation models for zero-shot segmentation of scientific images without AI-ready data. InProceedings of the 54th International Conference on Parallel Processing (ICPP-DRAI), 2025. doi:10.1145/3750720.3757283. URL https://doi. org/10.1145/3750720.3757283
-
[9]
Eric Chagnon, Ronald Pandolfi, Jeffrey Donatelli, and Daniela Ushizima. Benchmarking topic models on scientific articles using berteley.Natural Language Processing Journal, 6:100044, 2024. ISSN 2949-7191. doi:https://doi.org/10.1016/j.nlp.2023.100044. URL https://www.sciencedirect.com/science/article/ pii/S2949719123000419
-
[10]
Nextflow enables reproducible computational workflows.Nature biotechnology, 35(4):316–319, 2017
Paolo Di Tommaso, Maria Chatzou, Evan W Floden, Pablo Prieto Barja, Emilio Palumbo, and Cedric Notredame. Nextflow enables reproducible computational workflows.Nature biotechnology, 35(4):316–319, 2017
work page 2017
-
[11]
Snakemake—a scalable bioinformatics workflow engine.Bioinformatics, 28(19):2520–2522, 2012
Johannes Köster and Sven Rahmann. Snakemake—a scalable bioinformatics workflow engine.Bioinformatics, 28(19):2520–2522, 2012
work page 2012
-
[12]
Pegasus, a workflow management system for science automation
Ewa Deelman, Karan Vahi, Gideon Juve, Mats Rynge, Scott Callaghan, Philip J Maechling, Rajiv Mayani, Weiwei Chen, Rafael Ferreira Da Silva, and Miron Livny. Pegasus, a workflow management system for science automation. Future Generation Computer Systems, 46:17–35, 2015
work page 2015
-
[13]
Jupyter notebooks-a publishing format for reproducible computational workflows
Thomas Kluyver, Benjamin Ragan-Kelley, Fernando Pérez, Brian Granger, Matthias Bussonnier, Jonathan Frederic, Kyle Kelley, Jessica Hamrick, Jason Grout, and Sylvain Corlay. Jupyter notebooks-a publishing format for reproducible computational workflows. InPositioning and Power in Academic Publishing: Players, Agents and Agendas, pages 87–90. IOS Press, 2016
work page 2016
-
[14]
Binder 2.0 - reproducible, interactive, sharable environments for science at scale
Project Jupyter et al. Binder 2.0 - reproducible, interactive, sharable environments for science at scale. In Proceedings of the 17th Python in Science Conference, volume 113, page 120, 2018. 12 Sci-orchestraTECHNICALREPORT
work page 2018
-
[15]
Chris Holdgraf, Aaron Culich, Ariel Rokem, Fatma Deniz, Maryana Alegro, and Dani Ushizima. Portable learning environments for hands-on computational instruction: Using container- and cloud-based technology to teach data science. InPractice and Experience in Advanced Research Computing 2017 on Sustainability, Success and Impact, PEARC ’17, pages 1–9, New Y...
-
[16]
Daniela Ushizima, Ke Xu, and Paulo Monteiro. Materials data science for microstructural characterization of archaeological concrete.MRS Advancements - special issue: Materials Data Science, pages 1–14, 2020
work page 2020
-
[17]
Workflow orchestration engines: A comprehensive survey.Journal of Cloud Computing, 10 (1):1–22, 2021
Leandro Silva et al. Workflow orchestration engines: A comprehensive survey.Journal of Cloud Computing, 10 (1):1–22, 2021
work page 2021
-
[18]
ACM SIGOPS Operating Systems Review49(1), 71–79 (2015) https://doi.org/10.1145/2723872.2723882
Carl Boettiger. An introduction to docker for reproducible research.ACM SIGOPS Operating Systems Review, 49 (1):71–79, 2015. doi:10.1145/2723872.2723882
-
[19]
Dirk Merkel. Docker: lightweight linux containers for consistent development and deployment.Linux journal, 2014(239):2, 2014
work page 2014
-
[20]
O’Reilly Media, Inc., Sebastopol, CA, 2nd edition, 2020
Kief Morris.Infrastructure as Code: Dynamic Systems for the Cloud Age. O’Reilly Media, Inc., Sebastopol, CA, 2nd edition, 2020
work page 2020
-
[21]
Breno B. N. de Farias et al. Infrastructure as code: A systematic mapping study.ACM Computing Surveys, 55(11): 1–38, 2023. doi:10.1145/3579993
- [22]
-
[23]
Authenticating mcp oauth clients with spiffe/spire
Christian Posta. Authenticating mcp oauth clients with spiffe/spire. LinkedIn Pulse, 2024. URL https://www.linkedin.com/pulse/ authenticating-mcp-oauth-clients-spiffe-spire-christian-posta-juvsc . Accessed: 2026- 04-23
work page 2024
-
[24]
The national research platform (nrp)
National Research Platform. The national research platform (nrp). https://nationalresearchplatform. org/, 2026. Supported by the National Science Foundation under Award No. 2112167
work page 2026
-
[25]
Larry Smarr, Thomas DeFanti, Dmitry Mishin, Phil Hutton, Frank Wuerthwein, et al. The pacific research platform: A regional, national, and international science dmz.IEEE/ACM Innovating the Network for Data-Intensive Science (INDIS), pages 28–41, 2018
work page 2018
-
[26]
Experiment tracking with weights and biases
Lukas Biewald. Experiment tracking with weights and biases. https://www.wandb.com/, 2020. Software available from wandb.com
work page 2020
-
[27]
MM Noack, H Krishnan, MD Risser, and KG Reyes. Exact gaussian processes for massive datasets via non-stationary sparsity-discovering kernels.Scientific Reports, 13(1):3155, Jan 2023. ISSN 2045-2322. doi:10.1038/s41598-023-30062-8
-
[28]
Marcus M. Noack, Petrus H. Zwart, Daniela M. Ushizima, Masafumi Fukuto, Kevin G. Yager, Katherine C. Elbert, Christopher B. Murray, Aaron Stein, Gregory S. Doerk, Esther H. R. Tsai, Ruipeng Li, Guillaume Freychet, Mikhail Zhernenkov, Hoi-Ying N. Holman, Steven Lee, Liang Chen, Eli Rotenberg, Tobias Weber, Yannick Le Goc, Martin Boehm, Paul Steffens, Paolo...
-
[29]
Foundation models for zero-shot segmentation of scientific images without ai-ready data, 2025
Shubhabrata Mukherjee, Jack Lang, Obeen Kwon, Iryna Zenyuk, Valerie Brogden, Adam Weber, and Daniela Ushizima. Foundation models for zero-shot segmentation of scientific images without ai-ready data, 2025. URL https://arxiv.org/abs/2506.24039
-
[30]
Emiliano Casalicchio and Stefano Iannucci. The state-of-the-art in container technologies: Application, or- chestration and security.Concurrency and Computation: Practice and Experience, 32(17):e5668, 2020. doi:10.1002/cpe.5668
-
[31]
Containers in research: Hpc and beyond.Computing in Science & Engineering, 23(2): 66–70, 2021
Abdulrahman Azab et al. Containers in research: Hpc and beyond.Computing in Science & Engineering, 23(2): 66–70, 2021. doi:10.1109/MCSE.2021.3060938
-
[32]
Zineb Sordo, Eric Chagnon, Zixi Hu, Jeffrey J. Donatelli, Peter Andeer, Peter S. Nico, Trent Northen, and Daniela Ushizima. Synthetic scientific image generation with vae, gan, and diffusion model architectures.Journal of Imaging, 11(8), 2025. ISSN 2313-433X. doi:10.3390/jimaging11080252. URL https://www.mdpi.com/ 2313-433X/11/8/252. 13 Sci-orchestraTECHN...
-
[33]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representa- tions (ICLR), 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9
work page 2022
-
[34]
Oscar Ramírez-Ayala, Iván González-Hernández, Sergio Salazar, Jonathan Flores, and Rogelio Lozano. Real-time person detection in wooded areas using thermal images from an aerial perspective.Sensors, 23(22), 2023. ISSN 1424-8220. doi:10.3390/s23229216. URLhttps://www.mdpi.com/1424-8220/23/22/9216
-
[35]
Data set of thermal images of people in forested areas.Figshare, 11 2023
Oscar Ramirez. Data set of thermal images of people in forested areas.Figshare, 11 2023. doi:10.6084/m9.figshare.24473002.v1. URL https://figshare.com/articles/dataset/Data_set_of_ thermal_images_of_people_in_forested_areas_/24473002
-
[36]
E. R. Keydel, S. W. Lee, and J. T. Moore. MSTAR extended operating conditions: a tutorial. InAlgorithms for Synthetic Aperture Radar Imagery III, volume 2757, pages 228–242. SPIE, 1996
work page 1996
-
[37]
Review of recent advances in AI/ML using the MSTAR data
Erik Blasch, Uttam Majumder, Edmund Zelnio, and Vincent Velten. Review of recent advances in AI/ML using the MSTAR data. InAlgorithms for Synthetic Aperture Radar Imagery XXVII, volume 11393, page 113930C. SPIE, 2020. doi:10.1117/12.2559035. SPIE Defense + Commercial Sensing, 2020, Online Only
-
[38]
Air Force Research Laboratory and Defense Advanced Research Projects Agency. MSTAR public dataset. Sensor Data Management System (SDMS), 1997. URL https://www.sdms.afrl.af.mil/index.php? collection=mstar. Accessed via the Air Force Research Laboratory Sensor Data Management System
work page 1997
-
[39]
APPFL: Advanced Privacy-Preserving Federated Learning.https://appfl.ai/, 2026
APPFL Team. APPFL: Advanced Privacy-Preserving Federated Learning.https://appfl.ai/, 2026. Accessed: 2026-04-17
work page 2026
-
[40]
Berkeley Synchrotron Infrared Structural Biology Imaging Program.https://bsisb.lbl.gov/, 2026
Berkeley Synchrotron Infrared Structural Biology (BSISB). Berkeley Synchrotron Infrared Structural Biology Imaging Program.https://bsisb.lbl.gov/, 2026. 14
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.