Recognition: no theorem link
DRNet: All-in-One Image Restoration via Prior-Guided Dynamic Reparameterization
Pith reviewed 2026-05-12 00:49 UTC · model grok-4.3
The pith
DRNet creates a single network for all-in-one image restoration by reconfiguring once at initialization and using a task modulator to balance general and specific goals without runtime overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
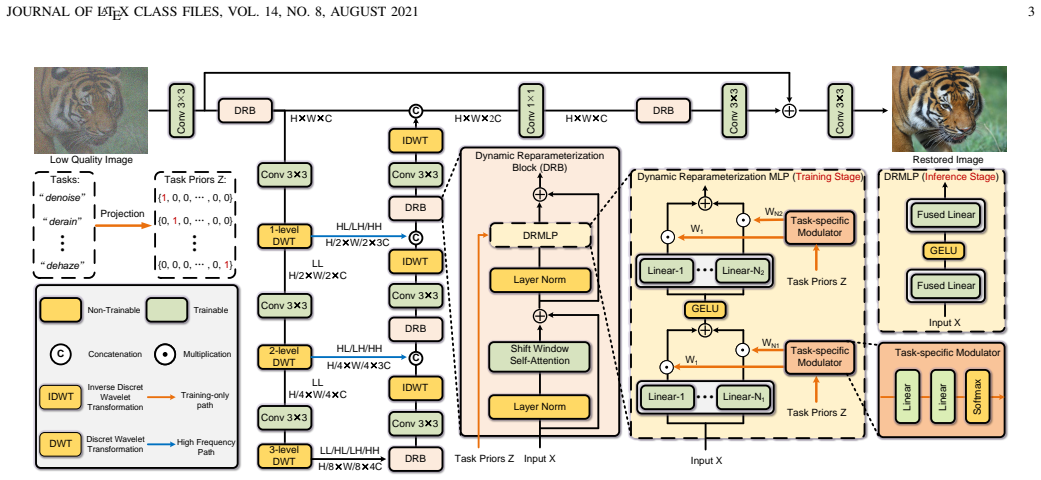
DRNet operates on an initialization-stage reconfiguration paradigm that fundamentally eliminates per-input overhead, at its core using a Dynamic Reparameterization MLP guided by a Task-Specific Modulator that orchestrates both specific restoration goals and a versatile general-purpose mode within a unified architecture, together with a Continuous Wavelet Transform Encoder that explicitly leverages frequency characteristics via wavelet decomposition for a lightweight yet powerful design, achieving state-of-the-art performance across five restoration tasks.
What carries the argument
The initialization-stage dynamic reparameterization using DRMLP guided by TSM, supported by CWTE for frequency-aware encoding, which allows task adaptation without per-input cost or separate models.
Where Pith is reading between the lines
- The same reconfiguration idea could apply to other multi-task settings such as joint denoising and super-resolution where switching costs are high.
- Connecting the modulator to user inputs at test time might allow real-time control over restoration strength without retraining.
- The wavelet encoder's frequency focus could be tested on video sequences to see if it reduces temporal artifacts compared to standard convolutions.
- If the general-purpose mode proves robust, it may support incremental addition of new degradation types with only modulator updates rather than full retraining.
Load-bearing premise
The initialization-stage reconfiguration paradigm combined with the Task-Specific Modulator can simultaneously eliminate per-input overhead and resolve optimization challenges from task heterogeneity without introducing new trade-offs.
What would settle it
Running DRNet on the same five tasks and measuring both per-image inference latency and accuracy metrics against prior dynamic methods; the central claim fails if latency remains comparable to per-input estimation methods or if accuracy falls below reported SOTA on any task.
Figures









read the original abstract
All-in-one image restoration aims to handle diverse degradations within a single model. However, existing methods often suffer from three key limitations: 1) per-input computational overhead from dynamic degradation estimation; 2) optimization challenges due to task heterogeneity; and 3) inefficient, frequency-agnostic encoder designs. To overcome these, we introduce the Dynamic Reparameterization Network (DRNet), a novel framework operating on an initialization-stage reconfiguration paradigm that fundamentally eliminates per-input overhead. At its core, a Dynamic Reparameterization MLP (DRMLP) guided by a Task-Specific Modulator (TSM), which effectively mitigates task heterogeneity by orchestrating both specific restoration goals and a versatile general-purpose mode within a unified architecture. Furthermore, we incorporate a Continuous Wavelet Transform Encoder (CWTE) that explicitly leverages frequency characteristics via wavelet decomposition for a lightweight yet powerful design. Extensive experiments demonstrate that DRNet achieves state-of-the-art performance across five restoration tasks with superior parameter efficiency. Crucially, it showcases unique flexibility, excelling as both a highly competitive foundation model for blind restoration and a top-performing user-guided specialist.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DRNet for all-in-one image restoration to address per-input dynamic estimation overhead, task heterogeneity optimization challenges, and frequency-agnostic encoders. It proposes an initialization-stage reconfiguration paradigm using a Dynamic Reparameterization MLP (DRMLP) guided by a Task-Specific Modulator (TSM) that supports both task-specific and general-purpose modes in one architecture, plus a Continuous Wavelet Transform Encoder (CWTE) for frequency-aware processing. The authors claim SOTA results across five restoration tasks with superior parameter efficiency, plus flexibility as a competitive blind-restoration foundation model and user-guided specialist.
Significance. If the central claims hold with rigorous validation, the work could meaningfully advance practical all-in-one restoration by removing per-input overhead while unifying heterogeneous tasks, offering a lightweight alternative to existing dynamic or multi-model approaches.
major comments (3)
- [Abstract and §3 (method)] The core claim that initialization-stage reconfiguration plus TSM eliminates per-input overhead and resolves task heterogeneity without new trade-offs (abstract) is load-bearing but unsupported by any mechanism details, training-objective formulation, or ablation isolating the general-purpose regime across degradations; this directly affects whether the efficiency and SOTA assertions can be verified.
- [Abstract and §4 (experiments)] No quantitative results, baselines, ablation tables, or dataset specifics appear to support the SOTA and efficiency claims (abstract); without these, the performance assertions cannot be assessed against standard metrics such as PSNR/SSIM on the five tasks.
- [§3.3] The CWTE is presented as addressing frequency-agnostic designs, but without equations showing how wavelet decomposition integrates with the reparameterization or comparisons to standard frequency encoders, its contribution to the claimed lightweight design remains unverified.
minor comments (2)
- [Throughout] Define all acronyms (DRMLP, TSM, CWTE) at first use and ensure consistent notation between text and figures.
- [§3.2] Clarify whether the TSM operates in a purely static post-initialization mode or retains any conditional computation for the blind-restoration case.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to provide additional mechanism details, explicit quantitative support, and mathematical formulations as requested. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract and §3 (method)] The core claim that initialization-stage reconfiguration plus TSM eliminates per-input overhead and resolves task heterogeneity without new trade-offs (abstract) is load-bearing but unsupported by any mechanism details, training-objective formulation, or ablation isolating the general-purpose regime across degradations; this directly affects whether the efficiency and SOTA assertions can be verified.
Authors: We agree that the abstract is concise and that further elaboration strengthens verifiability. In the revised §3.1–3.2 we now explicitly describe the initialization-stage reconfiguration process: the TSM produces a one-time modulation vector at model initialization that reparameterizes the DRMLP weights for either task-specific or general-purpose operation, after which no per-input estimation occurs. The training objective is formulated as a weighted sum of L1 reconstruction loss, perceptual loss, and a task-heterogeneity regularizer that encourages the general-purpose mode to remain competitive. We have added a dedicated ablation (new Table 4) that isolates the general-purpose regime across all five degradations and shows negligible accuracy drop relative to task-specific modes while preserving the reported parameter efficiency. These additions directly substantiate the abstract claims. revision: yes
-
Referee: [Abstract and §4 (experiments)] No quantitative results, baselines, ablation tables, or dataset specifics appear to support the SOTA and efficiency claims (abstract); without these, the performance assertions cannot be assessed against standard metrics such as PSNR/SSIM on the five tasks.
Authors: We apologize if the experimental content was not immediately apparent. Section 4 already contains full quantitative tables reporting PSNR and SSIM on the five tasks (deraining on Rain100L/H, dehazing on SOTS, denoising on BSD68, deblurring on GoPro, low-light enhancement on LOL), together with comparisons against Restormer, Uformer, and other all-in-one baselines, plus ablation tables on DRMLP, TSM, and CWTE. Dataset details and training protocols are listed in §4.1. In the revision we have added an explicit cross-reference from the abstract to these results and inserted a compact summary table (new Table 1) that highlights the key SOTA margins and parameter counts for quick verification. revision: partial
-
Referee: [§3.3] The CWTE is presented as addressing frequency-agnostic designs, but without equations showing how wavelet decomposition integrates with the reparameterization or comparisons to standard frequency encoders, its contribution to the claimed lightweight design remains unverified.
Authors: We have expanded §3.3 with the explicit integration equations: the continuous wavelet transform decomposes the input into sub-bands whose coefficients are concatenated and fed to the TSM, which then produces the modulation vector that reparameterizes the subsequent DRMLP layers. We also added a direct comparison (new Table 5) against FFT-based and DCT-based frequency encoders, demonstrating that CWTE achieves comparable or better restoration quality at lower parameter overhead. These additions verify the lightweight contribution of the wavelet design. revision: yes
Circularity Check
No significant circularity; claims rest on new modules and empirical results
full rationale
The paper introduces architectural innovations (initialization-stage reconfiguration, DRMLP with TSM, CWTE) to address stated limitations in all-in-one restoration. No equations or definitions reduce claimed performance, efficiency, or flexibility to quantities defined by the outputs themselves or by fitted parameters renamed as predictions. No load-bearing self-citations or uniqueness theorems are invoked in the provided text. The SOTA and flexibility claims are presented as outcomes of experiments, keeping the derivation chain independent and self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Neural networks can be reparameterized at initialization to alter runtime behavior without changing the core architecture or incurring per-input cost.
- domain assumption Wavelet decomposition can be integrated into an encoder to capture frequency characteristics more efficiently than standard convolutional designs.
invented entities (3)
-
Dynamic Reparameterization MLP (DRMLP)
no independent evidence
-
Task-Specific Modulator (TSM)
no independent evidence
-
Continuous Wavelet Transform Encoder (CWTE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Swinir: Image restoration using swin transformer,
J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, and R. Timofte, “Swinir: Image restoration using swin transformer,” inICCVW, 2021, pp. 1833–1844
work page 2021
-
[2]
Uformer: A general u-shaped transformer for image restoration,
Z. Wang, X. Cun, J. Bao, W. Zhou, J. Liu, and H. Li, “Uformer: A general u-shaped transformer for image restoration,” inCVPR, 2022, pp. 17 683–17 693
work page 2022
-
[3]
Restormer: Efficient transformer for high-resolution image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” inCVPR, 2022, pp. 5728–5739
work page 2022
-
[4]
R. Yasarla and V . M. Patel, “Uncertainty guided multi-scale residual learning-using a cycle spinning cnn for single image de-raining,” in CVPR, 2019, pp. 8405–8414
work page 2019
-
[5]
Drt: A lightweight single image deraining recursive transformer,
Y . Liang, S. Anwar, and Y . Liu, “Drt: A lightweight single image deraining recursive transformer,” inCVPR, 2022, pp. 589–598
work page 2022
-
[6]
Griddehazenet: Attention-based multi-scale network for image dehazing,
X. Liu, Y . Ma, Z. Shi, and J. Chen, “Griddehazenet: Attention-based multi-scale network for image dehazing,” inICCV, 2019, pp. 7314– 7323
work page 2019
-
[7]
Region-based dehazing via dual- supervised triple-convolutional network,
J. Shin, H. Park, and J. Paik, “Region-based dehazing via dual- supervised triple-convolutional network,”IEEE TMM, vol. 24, pp. 245– 260, 2021
work page 2021
-
[8]
A survey on all-in- one image restoration: Taxonomy, evaluation and future trends,
J. Jiang, Z. Zuo, G. Wu, K. Jiang, and X. Liu, “A survey on all-in- one image restoration: Taxonomy, evaluation and future trends,”IEEE TPAMI, 2025
work page 2025
-
[9]
Instructir: High-quality image restoration following human instructions,
M. V . Conde, G. Geigle, and R. Timofte, “Instructir: High-quality image restoration following human instructions,” inECCV, 2024
work page 2024
-
[10]
arXiv preprint arXiv:2312.05038 (2023) MMFE-IR 17
Z. Li, Y . Lei, C. Ma, J. Zhang, and H. Shan, “Prompt-in-prompt learning for universal image restoration,”arXiv preprint arXiv:2312.05038, 2023
-
[11]
Perceive-ir: Learning to perceive degradation better for all-in-one image restoration,
X. Zhang, J. Ma, G. Wang, Q. Zhang, H. Zhang, and L. Zhang, “Perceive-ir: Learning to perceive degradation better for all-in-one image restoration,”IEEE TIP, 2025
work page 2025
-
[12]
Tape: Task-agnostic prior embedding for image restoration,
L. Liu, L. Xie, X. Zhang, S. Yuan, X. Chen, W. Zhou, H. Li, and Q. Tian, “Tape: Task-agnostic prior embedding for image restoration,” inECCV, 2022, pp. 447–464
work page 2022
-
[13]
Ingredient-oriented multi-degradation learning for image restoration,
J. Zhang, J. Huang, M. Yao, Z. Yang, H. Yu, M. Zhou, and F. Zhao, “Ingredient-oriented multi-degradation learning for image restoration,” inCVPR, 2023, pp. 5825–5835
work page 2023
-
[14]
Subspace constraint and contribution estimation for heterogeneous federated learning,
X. Zhang, S. Li, A. Li, Y . Liu, F. Zhang, C. Zhu, and L. Zhang, “Subspace constraint and contribution estimation for heterogeneous federated learning,” inCVPR, 2025, pp. 1–1
work page 2025
-
[15]
All-in-one medical image restoration via task-adaptive routing,
Z. Yang, H. Chen, Z. Qian, Y . Yi, H. Zhang, D. Zhao, B. Wei, and Y . Xu, “All-in-one medical image restoration via task-adaptive routing,” in International Conference on Medical Image Computing and Computer- Assisted Intervention. Springer, 2024, pp. 67–77
work page 2024
-
[16]
X. Kong, C. Dong, and L. Zhang, “Towards effective multiple-in-one image restoration: A sequential and prompt learning strategy,”arXiv preprint arXiv:2401.03379, 2024
-
[17]
Transweather: Transformer-based restoration of images degraded by adverse weather conditions,
J. M. J. Valanarasu, R. Yasarla, and V . M. Patel, “Transweather: Transformer-based restoration of images degraded by adverse weather conditions,” inCVPR, 2022, pp. 2353–2363
work page 2022
-
[18]
Promptir: Prompting for all-in-one image restoration,
V . Potlapalli, S. W. Zamir, S. H. Khan, and F. Shahbaz Khan, “Promptir: Prompting for all-in-one image restoration,”NeurIPS, 2023
work page 2023
-
[19]
T. Wang, K. Zhang, Z. Shao, W. Luo, B. Stenger, T. Lu, T.-K. Kim, W. Liu, and H. Li, “Gridformer: Residual dense transformer with grid structure for image restoration in adverse weather conditions,”IJCV, pp. 1–23, 2024
work page 2024
-
[20]
Adair: Adaptive all-in-one image restoration via frequency mining and modulation,
Y . Cui, S. W. Zamir, S. Khan, A. Knoll, M. Shah, and F. S. Khan, “Adair: Adaptive all-in-one image restoration via frequency mining and modulation,” inICLR, 2025
work page 2025
-
[21]
Repvgg: Making vgg-style convnets great again,
X. Ding, X. Zhang, N. Ma, J. Han, G. Ding, and J. Sun, “Repvgg: Making vgg-style convnets great again,” inCVPR, 2021, pp. 13 733– 13 742
work page 2021
-
[22]
Scaling up your kernels to 31x31: Revisiting large kernel design in cnns,
X. Ding, X. Zhang, J. Han, and G. Ding, “Scaling up your kernels to 31x31: Revisiting large kernel design in cnns,” inCVPR, 2022, pp. 11 963–11 975
work page 2022
-
[23]
Mobileone: An improved one millisecond mobile backbone,
P. K. A. Vasu, J. Gabriel, J. Zhu, O. Tuzel, and A. Ranjan, “Mobileone: An improved one millisecond mobile backbone,” inCVPR, 2023, pp. 7907–7917
work page 2023
-
[24]
X. Liu, A. Li, Z. Wu, Y . Du, L. Zhang, Y . Zhang, R. Timofte, and C. Zhu, “Pasta: Towards flexible and efficient hdr imaging via progressively aggregated spatio-temporal aligment,”arXiv preprint arXiv:2403.10376, 2024
-
[25]
Multi-scale residual low-pass filter network for image deblurring,
J. Dong, J. Pan, Z. Yang, and J. Tang, “Multi-scale residual low-pass filter network for image deblurring,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 12 345–12 354
work page 2023
-
[26]
Efficient and explicit modelling of image hierarchies for image restoration,
Y . Li, Y . Fan, X. Xiang, D. Demandolx, R. Ranjan, R. Timofte, and L. Van Gool, “Efficient and explicit modelling of image hierarchies for image restoration,” inCVPR, 2023, pp. 18 278–18 289
work page 2023
-
[27]
Omni-kernel network for image restoration,
Y . Cui, W. Ren, and A. Knoll, “Omni-kernel network for image restoration,” inAAAI, vol. 38, no. 2, 2024, pp. 1426–1434
work page 2024
-
[28]
Maxim: Multi-axis mlp for image processing,
Z. Tu, H. Talebi, H. Zhang, F. Yang, P. Milanfar, A. Bovik, and Y . Li, “Maxim: Multi-axis mlp for image processing,” inCVPR, 2022, pp. 5769–5780. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
work page 2022
-
[29]
One-step effective diffusion network for real-world image super-resolution,
R. Wu, L. Sun, Z. Ma, and L. Zhang, “One-step effective diffusion network for real-world image super-resolution,”NeurIPS, vol. 37, pp. 92 529–92 553, 2024
work page 2024
-
[30]
J. Li, B. Li, Z. Tu, X. Liu, Q. Guo, F. Juefei-Xu, R. Xu, and H. Yu, “Light the night: A multi-condition diffusion framework for unpaired low-light enhancement in autonomous driving,” inCVPR, 2024, pp. 15 205–15 215
work page 2024
-
[31]
All-in-one image restoration for unknown corruption,
B. Li, X. Liu, P. Hu, Z. Wu, J. Lv, and X. Peng, “All-in-one image restoration for unknown corruption,” inCVPR, 2022, pp. 17 452–17 462
work page 2022
-
[32]
D. Park, B. H. Lee, and S. Y . Chun, “All-in-one image restoration for unknown degradations using adaptive discriminative filters for specific degradations,” inCVPR, 2023, pp. 5815–5824
work page 2023
-
[33]
Controlling vision-language models for multi-task image restoration,
Z. Luo, F. K. Gustafsson, Z. Zhao, J. Sj ¨olund, and T. B. Sch ¨on, “Controlling vision-language models for multi-task image restoration,” inICLR, 2024
work page 2024
-
[34]
Continual all-in-one adverse weather removal with knowledge replay on a unified network structure,
D. Cheng, Y . Ji, D. Gong, Y . Li, N. Wang, J. Han, and D. Zhang, “Continual all-in-one adverse weather removal with knowledge replay on a unified network structure,”IEEE TMM, 2024
work page 2024
-
[35]
All-in-one weather-degraded image restoration via adaptive degradation-aware self- prompting model,
Y . Wen, T. Gao, Z. Li, J. Zhang, K. Zhang, and T. Chen, “All-in-one weather-degraded image restoration via adaptive degradation-aware self- prompting model,”IEEE TMM, pp. 1–13, 2025
work page 2025
-
[36]
Ada4dir: An adaptive model-driven all-in-one image restora- tion network for remote sensing images,
Z. Lihe, Q. Yuan, J. He, X. Jin, Y . Xiao, Y . Chen, H. Shen, and L. Zhang, “Ada4dir: An adaptive model-driven all-in-one image restora- tion network for remote sensing images,”Information Fusion, vol. 118, p. 102930, 2025
work page 2025
-
[37]
Uniuir: Considering underwater image restoration as an all-in-one learner,
X. Zhang, H. Zhang, G. Wang, Q. Zhang, L. Zhang, and B. Du, “Uniuir: Considering underwater image restoration as an all-in-one learner,”IEEE Transactions on Image Processing, vol. 34, pp. 6963–6977, 2025
work page 2025
-
[38]
Restoration of multiple image distortions using a semi-dynamic deep neural network,
H. Luo, F. Zhou, Z. Zhou, K.-M. Lam, and G. Qiu, “Restoration of multiple image distortions using a semi-dynamic deep neural network,” inProceedings of the ACM International Conference on Multimedia (ACMMM), 2023, pp. 7871–7880
work page 2023
-
[39]
Edge-oriented convolution block for real-time super resolution on mobile devices,
X. Zhang, H. Zeng, and L. Zhang, “Edge-oriented convolution block for real-time super resolution on mobile devices,” inACM MM, 2021, pp. 4034–4043
work page 2021
-
[40]
H. Yan, A. Li, X. Zhang, Z. Liu, Z. Shi, C. Zhu, and L. Zhang, “Mobileie: An extremely lightweight and effective convnet for real-time image enhancement on mobile devices,” inICCV, 2025
work page 2025
-
[41]
Stochastic frequency masking to improve super-resolution and denoising networks,
M. E. Helou, R. Zhou, and S. S ¨usstrunk, “Stochastic frequency masking to improve super-resolution and denoising networks,” inProceedings of the European Conference on Computer Vision (ECCV), 2020, pp. 749– 766
work page 2020
-
[42]
Embedded block resid- ual network: A recursive restoration model for single-image super- resolution,
Y . Qiu, R. Wang, D. Tao, and J. Cheng, “Embedded block resid- ual network: A recursive restoration model for single-image super- resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision (ICCV), 2019, pp. 4180–4189
work page 2019
-
[43]
Learning frequency-aware dynamic network for efficient super-resolution,
W. Xie, D. Song, C. Xu, C. Xu, H. Zhang, and Y . Wang, “Learning frequency-aware dynamic network for efficient super-resolution,” in Proceedings of the IEEE/CVF Conference on Computer Vision (ICCV), 2021, pp. 4308–4317
work page 2021
-
[44]
A. Li, L. Zhang, Y . Liu, and C. Zhu, “Exploring frequency-inspired optimization in transformer for efficient single image super-resolution,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 4, pp. 3141–3158, 2025
work page 2025
-
[45]
Dynamic high-pass filtering and multi-spectral attention for image super-resolution,
S. A. Magidet al., “Dynamic high-pass filtering and multi-spectral attention for image super-resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision (ICCV), 2021, pp. 4288–4297
work page 2021
-
[46]
Joint sub-bands learning with clique structures for wavelet domain super-resolution,
Z. Zhong, T. Shen, Y . Yang, Z. Lin, and C. Zhang, “Joint sub-bands learning with clique structures for wavelet domain super-resolution,” in Proceedings of the Conference and Workshop on Neural Information Processing Systems (NeurIPS), 2018, pp. 165–175
work page 2018
-
[47]
Y . Chen, Q. Yuan, Y . Tang, X. Wang, Y . Xiao, J. He, Z. Lihe, and X. Jin, “Profit: A prompt-guided frequency-aware filtering and template- enhanced interaction framework for hyperspectral video tracking,”IS- PRS Journal of Photogrammetry and Remote Sensing, vol. 226, pp. 164– 186, 2025
work page 2025
-
[48]
Multi-scale grid network for image deblurring with high-frequency guidance,
Y . Liu, F. Fang, T. Wang, J. Li, Y . Sheng, and G. Zhang, “Multi-scale grid network for image deblurring with high-frequency guidance,”IEEE Transactions on Multimedia, vol. 24, pp. 2890–2901, 2021
work page 2021
-
[49]
Frequency and spatial dual guidance for image dehazing,
H. Yu, N. Zheng, M. Zhou, J. Huang, Z. Xiao, and F. Zhao, “Frequency and spatial dual guidance for image dehazing,” inProceedings of the European Conference on Computer Vision (ECCV), 2022, pp. 181–198
work page 2022
-
[50]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inICCV, 2021, pp. 9992–10 002
work page 2021
-
[51]
Parameter-efficient transfer learning for nlp,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for nlp,” inProceedings of the International Conference on Machine Learning (ICML), 2019, pp. 2790–2799
work page 2019
-
[52]
Dynamic convolution: Attention over convolution kernels,
Y . Chen, X. Dai, M. Liu, D. Chen, L. Yuan, and Z. Liu, “Dynamic convolution: Attention over convolution kernels,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 11 030–11 039
work page 2020
-
[53]
Deep joint rain detection and removal from a single image,
W. Yang, R. T. Tan, J. Feng, J. Liu, Z. Guo, and S. Yan, “Deep joint rain detection and removal from a single image,” inCVPR, 2017, pp. 1357–1366
work page 2017
-
[54]
Benchmarking single-image dehazing and beyond,
B. Li, W. Ren, D. Fu, D. Tao, D. Feng, W. Zeng, and Z. Wang, “Benchmarking single-image dehazing and beyond,”IEEE TIP, vol. 28, no. 1, pp. 492–505, 2018
work page 2018
-
[55]
D. Martin, C. Fowlkes, D. Tal, and J. Malik, “A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics,” inICCV, vol. 2, 2001, pp. 416–423
work page 2001
-
[56]
Deep multi-scale convolutional neural network for dynamic scene deblurring,
S. Nah, T. Hyun Kim, and K. Mu Lee, “Deep multi-scale convolutional neural network for dynamic scene deblurring,” inCVPR, 2017, pp. 3883–3891
work page 2017
-
[57]
Deep retinex decomposition for low-light enhancement,
C. Wei, W. Wang, W. Yang, and J. Liu, “Deep retinex decomposition for low-light enhancement,” inBMVC, 2018
work page 2018
-
[58]
Learning enriched features for real image restoration and enhancement,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, and L. Shao, “Learning enriched features for real image restoration and enhancement,” inECCV, 2020, pp. 492–511
work page 2020
-
[59]
Deep generalized unfolding networks for image restoration,
C. Mou, Q. Wang, and J. Zhang, “Deep generalized unfolding networks for image restoration,” inCVPR, 2022, pp. 17 399–17 410
work page 2022
-
[60]
Simple baselines for image restoration,
L. Chen, X. Chu, X. Zhang, and J. Sun, “Simple baselines for image restoration,” inECCV, 2022, pp. 17–33
work page 2022
-
[61]
Image restoration via frequency selection,
Y . Cui, W. Ren, X. Cao, and A. Knoll, “Image restoration via frequency selection,”IEEE TPAMI, vol. 46, no. 2, pp. 1093–1108, 2024
work page 2024
-
[62]
Mambair: A simple baseline for image restoration with state-space model,
H. Guo, J. Li, T. Dai, Z. Ouyang, X. Ren, and S.-T. Xia, “Mambair: A simple baseline for image restoration with state-space model,” inECCV, 2024, pp. 222–241
work page 2024
-
[63]
A general decoupled learning framework for parameterized image operators,
Q. Fan, D. Chen, L. Yuan, G. Hua, N. Yu, and B. Chen, “A general decoupled learning framework for parameterized image operators,”IEEE TPAMI, vol. 43, no. 1, pp. 33–47, 2019
work page 2019
-
[64]
Multi-stage progressive image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, and L. Shao, “Multi-stage progressive image restoration,” inCVPR, 2021, pp. 14 821–14 831
work page 2021
-
[65]
Contour detection and hierarchical image segmentation,
P. Arbelaez, M. Maire, C. Fowlkes, and J. Malik, “Contour detection and hierarchical image segmentation,”IEEE TPAMI, vol. 33, no. 5, pp. 898–916, 2010
work page 2010
-
[66]
Waterloo exploration database: New challenges for image quality assessment models,
K. Ma, Z. Duanmu, Q. Wu, Z. Wang, H. Yong, H. Li, and L. Zhang, “Waterloo exploration database: New challenges for image quality assessment models,”IEEE TIP, vol. 26, no. 2, pp. 1004–1016, 2016
work page 2016
-
[67]
Single image super-resolution from transformed self-exemplars,
J.-B. Huang, A. Singh, and N. Ahuja, “Single image super-resolution from transformed self-exemplars,” inCVPR, 2015, pp. 5197–5206
work page 2015
-
[68]
Kodak lossless true color image suite,
R. Franzen, “Kodak lossless true color image suite,” http://r0k.us/ graphics/kodak/, 1999, online; accessed 24 October 2021
work page 1999
-
[69]
A high-quality denoising dataset for smartphone cameras,
A. Abdelhamed, S. Lin, and M. S. Brown, “A high-quality denoising dataset for smartphone cameras,” inCVPR, 2018, pp. 1692–1700
work page 2018
-
[70]
W. Li, Q. Zhang, J. Zhang, Z. Huang, X. Tian, and D. Tao, “Toward real-world single image deraining: A new benchmark and beyond,”arXiv preprint arXiv:2206.05514, 2022
-
[71]
Onerestore: A universal restoration framework for composite degradation,
Y . Guo, Y . Gao, Y . Lu, H. Zhu, R. W. Liu, and S. He, “Onerestore: A universal restoration framework for composite degradation,” inECCV. Springer, 2024, pp. 255–272
work page 2024
-
[72]
Learning deep CNN denoiser prior for image restoration,
K. Zhang, W. Zuo, S. Gu, and L. Zhang, “Learning deep CNN denoiser prior for image restoration,” inCVPR, 2017
work page 2017
-
[73]
Ffdnet: Toward a fast and flexible solution for cnn-based image denoising,
K. Zhang, W. Zuo, and L. Zhang, “Ffdnet: Toward a fast and flexible solution for cnn-based image denoising,”IEEE TIP, vol. 27, no. 9, pp. 4608–4622, 2018
work page 2018
-
[74]
Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,
K. Zhang, W. Zuo, Y . Chen, D. Meng, and L. Zhang, “Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,”IEEE TIP, vol. 26, no. 7, pp. 3142–3155, 2017
work page 2017
-
[75]
Hinet: Half instance normalization network for image restoration,
L. Chen, X. Lu, J. Zhang, X. Chu, and C. Chen, “Hinet: Half instance normalization network for image restoration,” inCVPR, 2021, pp. 182– 192
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.