Recognition: no theorem link
ProDG: Prototypes for Data-Free Generative Post-Hoc Explainability
Pith reviewed 2026-05-12 01:19 UTC · model grok-4.3
The pith
ProDG generates high-fidelity visual prototypes for explaining neural network decisions using only the model's weights and no real data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ProDG leverages generative models to synthesize pure, high-fidelity prototypes directly from the frozen model's weights, completely eliminating the dependency on any external data for prototype-based post-hoc explainability.
What carries the argument
Generative models that synthesize prototypes directly from the frozen model's weights to replace the data-dependent search step in prototype selection.
Load-bearing premise
Synthetic prototypes produced from the model weights will match the visual and semantic properties that real data prototypes would have for the same model decisions.
What would settle it
Apply both ProDG and a data-based prototype method to the same pretrained image classifier on a public dataset, then compare whether the resulting prototypes produce equivalent nearest-prototype classification accuracy and human-rated explanation faithfulness.
Figures
















read the original abstract
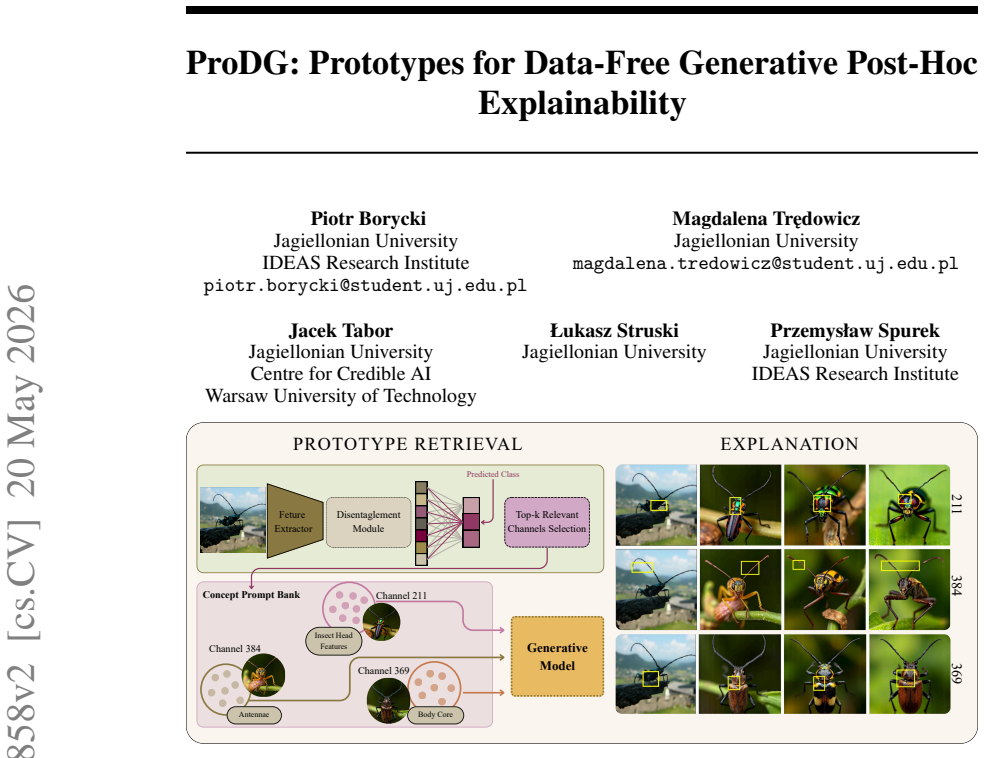
Ante-hoc interpretability methods based on prototypes provide highly accurate explanations by utilizing the intuitive "this looks like that" reasoning paradigm. On the other hand, post-hoc models can explain predictions for a single image without relying on an underlying dataset or requiring costly neural network retraining. Recent approaches successfully solve the retraining problem for prototype-based networks. However, they still face a fundamental limitation: they require access to a subset of data (e.g., a test or validation set) to search for and extract the visual prototypes. In this paper, we address this issue and introduce ProDG: Generative Prototypes for Data-Free Post-Hoc Explainability, a novel framework that leverages generative models to synthesize pure, high-fidelity prototypes directly from the frozen model's weights, completely eliminating the dependency on any external data. By establishing this new frontier in Data-Free XAI, ProDG unlocks robust visual interpretability for privacy-sensitive domains, where original data is strictly restricted or fundamentally inaccessible. Project page: https://github.com/piotr310100/ProDG
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ProDG, a framework for data-free post-hoc explainability that employs generative models to synthesize high-fidelity visual prototypes directly from the weights of a frozen classifier, removing any need for training, validation, or test data to select or extract prototypes for 'this looks like that' style explanations.
Significance. If validated, the data-free property would be a meaningful advance for prototype-based XAI in privacy-restricted settings (e.g., medical or proprietary data), extending prior post-hoc prototype methods that still require data access. The manuscript receives credit for clearly identifying the data-dependency limitation in existing work and for proposing a generative synthesis route, but the significance is currently undercut by the complete absence of any empirical support.
major comments (2)
- [Abstract and §3 (Method)] Abstract and §3 (Method): the central claim that generative synthesis 'directly from the frozen model's weights' produces prototypes whose visual and semantic content align with real-data selections is load-bearing, yet no optimization objective, latent-space constraint, or regularization term is specified that would anchor generations to the training distribution and prevent out-of-distribution or spurious outputs.
- [§5 (Experiments)] Absence of §5 (Experiments) and all associated tables/figures: no quantitative results, ablation studies, fidelity metrics, or comparisons against data-dependent prototype baselines are reported, so there is no evidence that the synthesized prototypes yield faithful explanations for the original model's decisions.
minor comments (1)
- [Abstract] The GitHub project page is referenced; including even preliminary qualitative examples or pseudocode in the main text would improve clarity.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough review and constructive criticism. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] Abstract and §3 (Method): the central claim that generative synthesis 'directly from the frozen model's weights' produces prototypes whose visual and semantic content align with real-data selections is load-bearing, yet no optimization objective, latent-space constraint, or regularization term is specified that would anchor generations to the training distribution and prevent out-of-distribution or spurious outputs.
Authors: We agree that the central claim requires a clear specification of the optimization process to ensure the generated prototypes align with the model's decision boundaries and the data distribution. The current manuscript describes the high-level approach but does not detail the objective function. We will update §3 with the full mathematical formulation, including the loss terms, latent constraints, and regularization to prevent out-of-distribution outputs. revision: yes
-
Referee: [§5 (Experiments)] Absence of §5 (Experiments) and all associated tables/figures: no quantitative results, ablation studies, fidelity metrics, or comparisons against data-dependent prototype baselines are reported, so there is no evidence that the synthesized prototypes yield faithful explanations for the original model's decisions.
Authors: We acknowledge that the current version of the manuscript does not include an experimental section, as it primarily presents the novel framework and its data-free approach. This is a valid concern regarding empirical support. In the revised manuscript, we will add a full §5 with experiments, including quantitative metrics for prototype fidelity, comparisons to data-dependent baselines, and ablation studies to validate that the generated prototypes provide faithful explanations. revision: yes
Circularity Check
No circularity: purely methodological framework introduction
full rationale
The paper describes a new framework (ProDG) for synthesizing prototypes via generative models from frozen classifier weights alone. No equations, derivations, fitted parameters, or predictions appear in the provided text. The central claim is the existence and utility of this data-free approach itself; it does not reduce any result to its own inputs by construction, nor rely on self-citation chains or imported uniqueness theorems. The description is self-contained as an independent methodological contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generative models can synthesize prototypes whose explanatory value equals or exceeds that of prototypes extracted from real data samples.
Reference graph
Works this paper leans on
-
[1]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[2]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. "why should i trust you?" explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1135–1144, 2016
work page 2016
-
[3]
Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PLoS One, 10(7):e0130140, 2015
work page 2015
-
[4]
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization.International Journal of Computer Vision, 128:336–359, 2020
work page 2020
-
[5]
Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, and Jonathan K Su. This looks like that: deep learning for interpretable image recognition.Advances in neural information processing systems, 32, 2019
work page 2019
-
[6]
Interpretable image classification with differentiable prototypes assignment
Dawid Rymarczyk, Łukasz Struski, Michał Górszczak, Koryna Lewandowska, Jacek Tabor, and Bartosz Zieli´nski. Interpretable image classification with differentiable prototypes assignment. InEuropean Conference on Computer Vision, pages 351–368. Springer, 2022
work page 2022
-
[7]
Dawid Rymarczyk, Łukasz Struski, Jacek Tabor, and Bartosz Zieli´nski. Protopshare: Prototypi- cal parts sharing for similarity discovery in interpretable image classification. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 1420–1430, 2021
work page 2021
-
[8]
Neural prototype trees for interpretable fine-grained image recognition
Meike Nauta, Ron Van Bree, and Christin Seifert. Neural prototype trees for interpretable fine-grained image recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14933–14943, 2021
work page 2021
-
[9]
This looks like it rather than that: Protoknn for similarity-based classifiers
Yuki Ukai, Tsubasa Hirakawa, Takayoshi Yamashita, and Hironobu Fujiyoshi. This looks like it rather than that: Protoknn for similarity-based classifiers. InThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[10]
Pip-net: Patch-based intuitive prototypes for interpretable image classification
Meike Nauta, Jörg Schlötterer, Maurice Van Keulen, and Christin Seifert. Pip-net: Patch-based intuitive prototypes for interpretable image classification. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2744–2753, 2023
work page 2023
-
[11]
Łukasz Struski, Dawid Rymarczyk, and Jacek Tabor. Infodisent: Explainability of image classification models by information disentanglement.arXiv preprint arXiv:2409.10329, 2024
-
[12]
Viktar Dubovik, Łukasz Struski, Jacek Tabor, and Dawid Rymarczyk. Side: Sparse information disentanglement for explainable artificial intelligence.arXiv preprint arXiv:2507.19321, 2025
-
[13]
Epic: Explanation of pretrained image classification networks via prototypes
Piotr Borycki, Magdalena Tr˛ edowicz, Szymon Janusz, Jacek Tabor, Przemysław Spurek, Arka- diusz Lewicki, and Łukasz Struski. Epic: Explanation of pretrained image classification networks via prototypes. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 17366–17373, 2026
work page 2026
-
[14]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024. 10 l o o k s l i k e z o o m r e g i o n l o o k s l i k e l o o k s l i k e l o o k s l i k e prototype no. 1 prototype no. 2 prototype no. 3 prototype no. 4 Figure 7:User study instructions and guide.Illustrative guide presented prior to the user-study questionnaire, demonstrating ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.