Recognition: no theorem link
Muon-OGD: Muon-based Spectral Orthogonal Gradient Projection for LLM Continual Learning
Pith reviewed 2026-05-12 02:07 UTC · model grok-4.3
The pith
Muon-OGD uses spectral-norm geometry in orthogonal projections to limit catastrophic forgetting during sequential LLM adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
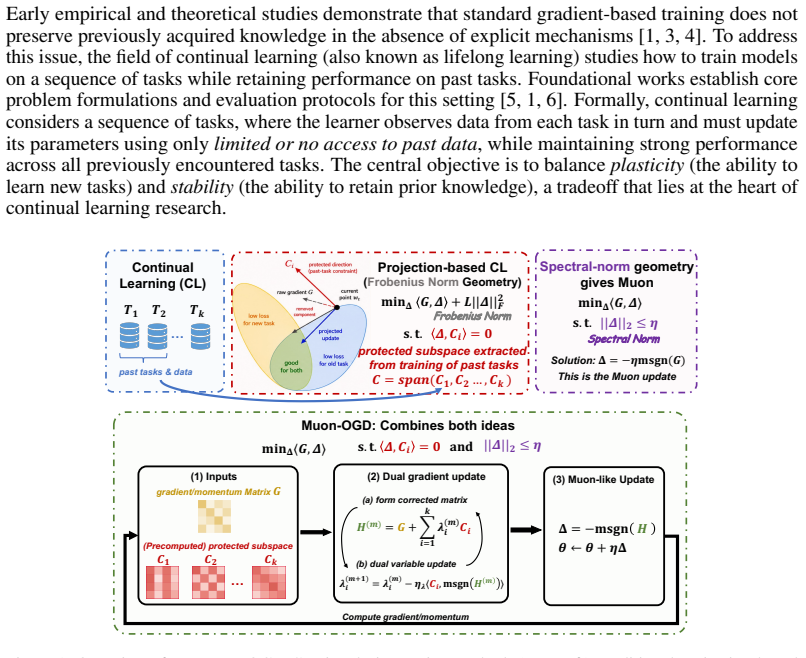
Muon-OGD formulates each update as a spectral-norm-constrained optimization problem subject to linear non-interference constraints from prior tasks, solved efficiently by dual iterations and Newton-Schulz approximations that produce orthogonalized momentum steps under Muon-style operator-norm geometry.
What carries the argument
Spectral-norm-constrained dual iteration with Newton-Schulz matrix-sign approximations that generates orthogonalized updates while respecting non-interference constraints from past tasks.
If this is right
- LLM parameters updated with spectral-norm orthogonal steps retain higher accuracy on earlier tasks after learning new ones.
- The method remains computationally scalable enough to apply to both encoder-decoder and decoder-only models on standard continual learning suites.
- Spectral geometry supplies a concrete alternative to Euclidean projections that consistently outperforms competitive orthogonal-gradient baselines.
- Dual-iteration solves with Newton-Schulz approximations keep the overhead modest while enforcing the non-interference constraints.
Where Pith is reading between the lines
- The same spectral-norm framing might be tested on other matrix-heavy continual learning settings such as vision transformers or graph models.
- If the advantage persists across longer task sequences, it could motivate replacing Frobenius norms in other projection-based regularizers.
- The dual solver structure may extend to additional matrix optimization problems that already use spectral or operator norms.
Load-bearing premise
That spectral-norm geometry together with the dual-iteration solver will produce a better stability-plasticity trade-off than Frobenius-norm methods without introducing hidden instabilities or excessive overhead on real LLM parameter matrices.
What would settle it
If Muon-OGD yields no measurable improvement in final performance on prior tasks or requires substantially more wall-clock time than Frobenius-based baselines when run on the same TRACE or domain curricula, the claimed practical advantage would not hold.
Figures




read the original abstract
A central challenge in continual learning for large language models (LLMs) is catastrophic forgetting, where adapting to new tasks can substantially degrade performance on previously learned ones. Existing projection-based methods mitigate such interference by restricting parameter updates to subspaces that are orthogonal to directions associated with past tasks. However, these methods are typically formulated under Euclidean parameter geometry, with update magnitudes and projections governed by the Frobenius norm. The recent empirical success of the Muon optimizer, which applies orthogonalized matrix updates and admits a spectral-norm interpretation, suggests that Frobenius geometry may not be the most effective choice for matrix-valued LLM parameters. Motivated by this observation, we propose Muon-OGD, a spectral-norm-aware continual learning framework that integrates Muon-style operator-norm geometry with orthogonal projection constraints. Our method formulates each update as a spectral-norm-constrained optimization problem with linear non-interference constraints, and solves it efficiently through dual iterations and Newton--Schulz matrix-sign approximations. By applying orthogonalized momentum updates that avoid protected directions associated with prior tasks, Muon-OGD aims to improve the stability--plasticity trade-off in sequential LLM adaptation. We evaluate the proposed method on standard continual learning benchmarks, TRACE, and domain-specific Coding--Math--Medical curricula using both encoder--decoder and decoder-only architectures. Empirically, Muon-OGD consistently improves over sequential fine-tuning and competitive orthogonal-gradient baselines, while remaining computationally scalable. These results suggest that spectral-norm-aware update geometry provides a practical and effective alternative to Frobenius-norm projection for continual learning in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Muon-OGD, a continual learning method for LLMs that replaces Frobenius-norm orthogonal gradient projection with a spectral-norm-constrained optimization problem solved via dual iterations and Newton-Schulz matrix-sign approximations. The approach integrates Muon-style orthogonalized updates to enforce non-interference with past-task directions while aiming for improved stability-plasticity trade-offs. It reports evaluation on TRACE and domain curricula (Coding-Math-Medical) across encoder-decoder and decoder-only models, claiming consistent gains over sequential fine-tuning and existing orthogonal baselines together with computational scalability.
Significance. If the empirical claims and scalability assertions hold after verification, the work would provide a concrete alternative geometry for projection-based continual learning in LLMs, potentially tightening the stability-plasticity frontier beyond Frobenius-based OGD. No machine-checked proofs, open reproducible code, or parameter-free derivations are described, so the contribution rests entirely on the empirical and algorithmic novelty.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the dual-iteration solver for the spectral-norm-constrained problem with linear non-interference constraints is described only at high level; no convergence bounds, iteration counts, or flop-count analysis versus standard Frobenius OGD are supplied for typical LLM matrices (4096×4096 or larger). This directly undermines the central scalability claim.
- [Abstract and §4] Abstract and §4 (experiments): the strongest claim—that Muon-OGD 'consistently improves' over baselines—is stated without any numerical results, error bars, ablation tables, or statistical tests. The central empirical assertion therefore cannot be evaluated from the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional detail will improve the manuscript. We address each major comment below and describe the revisions we will implement.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the dual-iteration solver for the spectral-norm-constrained problem with linear non-interference constraints is described only at high level; no convergence bounds, iteration counts, or flop-count analysis versus standard Frobenius OGD are supplied for typical LLM matrices (4096×4096 or larger). This directly undermines the central scalability claim.
Authors: We agree that the current description in Section 3 is high-level. In the revised manuscript we will expand the method section with explicit flop-count analysis for 4096×4096 matrices, observed iteration counts for the dual solver and Newton-Schulz matrix-sign approximation (typically 5–10 iterations in our runs), and a side-by-side computational comparison to standard Frobenius OGD. Although we do not supply theoretical convergence bounds, we will add empirical convergence curves in the appendix to demonstrate practical behavior on LLM-scale matrices. These additions will directly support the scalability claim. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (experiments): the strongest claim—that Muon-OGD 'consistently improves' over baselines—is stated without any numerical results, error bars, ablation tables, or statistical tests. The central empirical assertion therefore cannot be evaluated from the manuscript.
Authors: The referee is correct that the abstract presents the claim without supporting numbers. Section 4 already reports comparative results on TRACE and the Coding-Math-Medical curricula, but to make the empirical assertion fully evaluable we will add error bars to all tables and figures, include ablation studies isolating the spectral-norm component, and report statistical significance tests (paired t-tests across seeds). We will also revise the abstract to reference the key quantitative improvements. These changes will allow readers to assess the strength of the reported gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper motivates Muon-OGD from the empirical success of the Muon optimizer (external reference), then defines a new spectral-norm constrained optimization problem with linear non-interference constraints. It solves this via dual iterations and Newton-Schulz approximations, which are standard numerical tools. The central claims of improved stability-plasticity trade-off are supported by empirical evaluation on benchmarks rather than any derivation that reduces to the inputs by construction. No equations or steps in the provided abstract or description exhibit self-definition, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the result. The approach is a standard algorithmic proposal with external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Newton-Schulz iterations converge to a sufficiently accurate matrix sign function for the dual problem
Reference graph
Works this paper leans on
-
[1]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
work page 2017
-
[2]
An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks
Ian J Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio. An empirical investigation of catastrophic forgetting in gradient-based neural networks.arXiv preprint arXiv:1312.6211, 2013
work page Pith review arXiv 2013
-
[3]
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generative replay.Advances in neural information processing systems, 30, 2017
work page 2017
-
[4]
Lifelong learning with dynamically expandable networks
Jaehong Yoon, Eunho Yang, Jeongtae Lee, and Sung Ju Hwang. Lifelong learning with dynamically expandable networks. In6th International Conference on Learning Representations, ICLR 2018, 2018
work page 2018
-
[5]
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
work page 2017
-
[6]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. Advances in neural information processing systems, 30, 2017
work page 2017
-
[7]
Efficient Lifelong Learning with A-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-gem.arXiv preprint arXiv:1812.00420, 2018
work page Pith review arXiv 2018
-
[8]
Orthogonal gradient descent for continual learning
Mehrdad Farajtabar, Navid Azizan, Alex Mott, and Ang Li. Orthogonal gradient descent for continual learning. InInternational conference on artificial intelligence and statistics, pages 3762–3773. PMLR, 2020
work page 2020
-
[9]
Yifeng Xiong and Xiaohui Xie. Oplora: Orthogonal projection lora prevents catastrophic forgetting during parameter-efficient fine-tuning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 34088–34096, 2026
work page 2026
-
[10]
Sculpting subspaces: Constrained full fine-tuning in llms for continual learning, 2025
Nikhil Shivakumar Nayak, Krishnateja Killamsetty, Ligong Han, Abhishek Bhandwaldar, Prateek Chanda, Kai Xu, Hao Wang, Aldo Pareja, Oleg Silkin, Mustafa Eyceoz, et al. Sculpt- ing subspaces: Constrained full fine-tuning in llms for continual learning.arXiv preprint arXiv:2504.07097, 2025
-
[11]
Muon: An optimizer for hidden layers in neural networks
Keller Jordan. Muon: An optimizer for hidden layers in neural networks. URL https: //kellerjordan.github.io/posts/muon/. Blog post
-
[12]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of muon.arXiv preprint arXiv:2505.23737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Weijie Su. Isotropic curvature model for understanding deep learning optimization: Is gradient orthogonalization optimal?arXiv preprint arXiv:2511.00674, 2025
-
[16]
When do spectral gradient updates help in deep learning?arXiv preprint arXiv:2512.04299, 2025
Damek Davis and Dmitriy Drusvyatskiy. When do spectral gradient updates help in deep learning?arXiv preprint arXiv:2512.04299, 2025
-
[17]
Continual lifelong learning with neural networks: A review.Neural networks, 113:54–71, 2019
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural networks, 113:54–71, 2019
work page 2019
-
[18]
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE transactions on pattern analysis and machine intelligence, 44(7): 3366–3385, 2021. 10
work page 2021
-
[19]
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE transactions on pattern analysis and machine intelligence, 46(8):5362–5383, 2024
work page 2024
-
[20]
Continual learning through synaptic intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. InInternational conference on machine learning, pages 3987–3995. Pmlr, 2017
work page 2017
-
[21]
Memory aware synapses: Learning what (not) to forget
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuyte- laars. Memory aware synapses: Learning what (not) to forget. InProceedings of the European conference on computer vision (ECCV), pages 139–154, 2018
work page 2018
-
[22]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Learning to prompt for continual learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 139–149, 2022
work page 2022
-
[23]
Dualprompt: Complementary prompting for rehearsal-free continual learning
Zifeng Wang, Zizhao Zhang, Sayna Ebrahimi, Ruoxi Sun, Han Zhang, Chen-Yu Lee, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, et al. Dualprompt: Complementary prompting for rehearsal-free continual learning. InEuropean conference on computer vision, pages 631–648. Springer, 2022
work page 2022
-
[24]
Progressive prompts: Continual learning for language models.arXiv preprint arXiv:2301.12314, 2023
Anastasia Razdaibiedina, Yuning Mao, Rui Hou, Madian Khabsa, Mike Lewis, and Amjad Almahairi. Progressive prompts: Continual learning for language models.arXiv preprint arXiv:2301.12314, 2023
-
[25]
Chengwei Qin and Shafiq Joty. Lfpt5: A unified framework for lifelong few-shot language learning based on prompt tuning of t5.arXiv preprint arXiv:2110.07298, 2021
-
[26]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[27]
arXiv preprint arXiv:2310.06762 , year=
Xiao Wang, Yuansen Zhang, Tianze Chen, Songyang Gao, Senjie Jin, Xianjun Yang, Zhiheng Xi, Rui Zheng, Yicheng Zou, Tao Gui, et al. Trace: A comprehensive benchmark for continual learning in large language models.arXiv preprint arXiv:2310.06762, 2023
-
[28]
Orthogonal subspace learning for language model continual learning
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuan-Jing Huang. Orthogonal subspace learning for language model continual learning. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10658–10671, 2023
work page 2023
-
[29]
Jeremy Bernstein and Laker Newhouse. Modular duality in deep learning.arXiv preprint arXiv:2410.21265, 2024
-
[30]
Muon optimizes under spectral norm constraints
Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm constraints. arXiv preprint arXiv:2506.15054, 2025
-
[31]
Orthogonal gradient descent for continual learning
Mehrdad Farajtabar, Navid Azizan, Alex Mott, and Ang Li. Orthogonal gradient descent for continual learning. In Silvia Chiappa and Roberto Calandra, editors,Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 of Proceedings of Machine Learning Research, pages 3762–3773. PMLR, 26–28 Aug 2020. URL h...
work page 2020
-
[32]
Dynamic orthogonal continual fine-tuning for mitigating catastrophic forgettings, 2025
Zhixin Zhang, Zeming Wei, and Meng Sun. Dynamic orthogonal continual fine-tuning for mitigating catastrophic forgettings, 2025. URLhttps://arxiv.org/abs/2509.23893
-
[33]
Gem-style constraints for peft with dual gradient projection in lora
Brian Tekmen, Jason Yin, and Qianqian Tong. Gem-style constraints for peft with dual gradient projection in lora. In2025 IEEE International Conference on Data Mining Workshops (ICDMW), pages 2736–2743. IEEE, 2025
work page 2025
-
[34]
Matrix procrustes problems.Rapport technique, University of Manchester, 1995
Nick Higham and Pythagoras Papadimitriou. Matrix procrustes problems.Rapport technique, University of Manchester, 1995
work page 1995
-
[35]
Modular duality in deep learning
Jeremy Bernstein and Laker Newhouse. Modular duality in deep learning. InForty-second International Conference on Machine Learning. 11
-
[36]
Jeremy Bernstein. Deriving muon, 2025. URL https://jeremybernste.in/writing/ deriving-muon
work page 2025
-
[37]
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification.Advances in neural information processing systems, 28, 2015
work page 2015
-
[38]
Glue: A multi-task benchmark and analysis platform for natural language understanding
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP, pages 353–355, 2018
work page 2018
-
[39]
Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Superglue: A stickier benchmark for general-purpose language understanding systems.Advances in neural information processing systems, 32, 2019
work page 2019
-
[40]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, et al. Bigcodebench: Bench- marking code generation with diverse function calls and complex instructions.arXiv preprint arXiv:2406.15877, 2024
work page internal anchor Pith review arXiv 2024
-
[41]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[42]
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. Huatuogpt-o1, towards medical complex reasoning with llms, 2024. URL https://arxiv. org/abs/2412.18925
work page internal anchor Pith review arXiv 2024
-
[43]
Orthogonal subspace learning for language model continual learning,
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuanjing Huang. Orthogonal subspace learning for language model continual learning, 2023. URLhttps://arxiv.org/abs/2310.14152
-
[44]
Learn more, but bother less: parameter efficient continual learning
Fuli Qiao and Mehrdad Mahdavi. Learn more, but bother less: parameter efficient continual learning. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
-
[45]
URLhttps://openreview.net/forum?id=ZxtaNh5UYB
-
[46]
Gradient projection memory for continual learning.arXiv preprint arXiv:2103.09762, 2021
Gobinda Saha, Isha Garg, and Kaushik Roy. Gradient projection memory for continual learning. arXiv preprint arXiv:2103.09762, 2021. Declaration of LLM Usage. We used large language models as writing and coding assistants during the preparation of this manuscript. Specifically, LLMs were used to improve language clarity and presentation, assist with coding...
-
[47]
CORRECT: The response contains the key medical information from the reference answer, even if phrased differently or includes additional correct medical details
-
[48]
INCORRECT: The response is medically wrong, misses the main point, or provides incorrect medical information. Focus on medical accuracy and completeness, not on writing style or verbosity. [Medical Question] {question} [Reference Answer] {reference_answer} [Model Response] {model_response} Evaluate the model’s response. Output ONLY one of: "CORRECT" or "I...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.