When (and How) to Trust the Expert: Diagnosing Query-Time Expert-Guided Reinforcement Learning
Pith reviewed 2026-05-12 02:32 UTC · model grok-4.3
The pith
Expert-guided RL methods each succeed only in specific regimes of expert quality and task structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Harmonized benchmarking of query-time expert-guided RL methods on a shared backbone with degradation sweeps over undertuning, action bias, and observation noise shows that each method has regime-specific failure modes, with no single method dominating across all cases and no method clearing RL-near-ceiling experts within a 1M-step budget; this spread is converted into a testable decision rule keyed on expert quality, task termination, and perturbation type.
What carries the argument
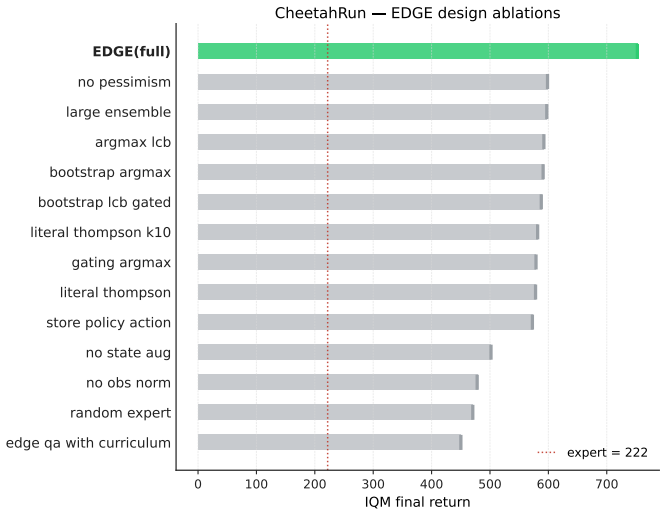
The taxonomy of three failure modes (critic blind spot under argmax-plus-bootstrap, residual saturation, and warm-start buffer poisoning) together with the decision rule based on three pre-training observables that selects the appropriate guidance method.
If this is right
- Practitioners should measure how close the expert is to the RL performance ceiling before selecting a guidance method.
- Training-time handoff methods risk collapse if the expert is undertuned at deployment time.
- Design choices in gate form and scoring rules can be tuned separately to mitigate specific failure modes.
- On tasks with near-ceiling experts, query-time methods may need longer budgets or different architectures to produce gains.
Where Pith is reading between the lines
- In real deployments, pre-deployment checks of expert quality against RL baselines become a necessary step for method selection.
- The observed limit on near-ceiling experts may be budget-dependent rather than fundamental, suggesting tests at higher step counts.
- The decision rule could be implemented as an automated selector in RL toolkits for users who have an existing expert controller.
Load-bearing premise
The three degradation axes of undertuning, action bias, and observation noise along with the chosen continuous-control environments represent the main variations practitioners will encounter when using expert-guided RL.
What would settle it
A controlled experiment in which one query-time method consistently surpasses the expert on RL-near-ceiling tasks such as FourTank within the 1M-step budget would falsify the observed performance limit.
Figures











read the original abstract
Many continuous-control problems ship with a competent but suboptimal controller (a tuned PID, a hand-designed gait). A growing family of methods uses such controllers as queryable experts during RL, but each method has been proposed in isolation, on a different benchmark, without imperfect-expert testing. We harmonize the comparison on a shared SAC backbone, common HPO and evaluation protocols, 100/50 seeds per (env, method), and a degradation sweep over expert undertuning, action bias, and observation noise. The comparison surfaces three failure modes single-paper evaluations miss: (F1) a critic blind spot under argmax-plus-bootstrap that drags IBRL below no-expert SAC on experts close to the no-expert-RL ceiling (RL-near-ceiling, distinct from the absolute physical ceiling); (F2) residual saturation on far-from-optimal experts; and (F3) warm-start buffer poisoning that collapses training-time-handoff methods under deployment-time expert undertuning. No single method dominates: each wins on one task-structure regime and fails predictably elsewhere; on RL-near-ceiling experts (FourTank, GlassFurnace) no query-time method clears the expert within our 1M-step budget, leaving open whether this is a fundamental wall or a budget effect. We convert the spread into a testable decision rule keyed on three pre-training observables (expert quality, task termination, perturbation type). The benchmark, taxonomy, and decision rule are the primary contribution; we additionally describe EDGE, a softmax-over-ensemble-LCB design point used to demonstrate that both axes the taxonomy points to (gate form, scoring rule) are individually exploitable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript harmonizes empirical comparisons of query-time expert-guided RL methods on a shared SAC backbone across continuous-control tasks. Using degradation sweeps over expert undertuning, action bias, and observation noise, with 100/50 seeds per (env, method) and common HPO/evaluation protocols, it identifies three failure modes (F1: critic blind spot under argmax-plus-bootstrap on RL-near-ceiling experts; F2: residual saturation on far-from-optimal experts; F3: warm-start buffer poisoning under deployment-time undertuning). No method dominates; each succeeds in specific regimes. The authors derive a testable decision rule from three pre-training observables and introduce EDGE (softmax-over-ensemble-LCB) to show that gate form and scoring rule are exploitable axes.
Significance. If the findings hold, the work is significant for moving expert-guided RL beyond isolated proposals to a comparative taxonomy and practical decision rule that surfaces regime-dependent failure modes missed by single-paper evaluations. The shared backbone, large seed counts, and controlled degradation sweeps provide stronger evidence than prior work. Credit is given for the reproducible protocol and for framing falsifiable predictions around the failure modes and decision rule.
major comments (1)
- [Results on FourTank and GlassFurnace (failure mode F1)] The central claim that no query-time method clears the expert on RL-near-ceiling experts (FourTank, GlassFurnace) and the diagnosis of failure mode F1 both rest on classifying these experts as close to the no-expert-RL performance limit within the 1M-step budget. The manuscript provides no evidence that the no-expert SAC baselines have plateaued (e.g., flat learning curves, statistical tests for no further improvement, or convergence diagnostics). If the baselines are still rising at 1M steps, the experts are not demonstrably RL-near-ceiling, which undercuts both F1 and the conclusion that query-time guidance hits a wall.
minor comments (2)
- [Abstract] The abstract summarizes findings qualitatively but reports no quantitative metrics, effect sizes, or error bars to support the claims about failure modes, regime-specific wins, or the decision rule.
- [Decision rule derivation] The decision rule is described as keyed on three pre-training observables, but the exact thresholds, how the observables are computed from data, and the rule's cross-validation procedure should be stated more explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The feedback highlights an important point about supporting evidence for our classification of experts as RL-near-ceiling. We address this below and will revise the manuscript to strengthen the presentation.
read point-by-point responses
-
Referee: [Results on FourTank and GlassFurnace (failure mode F1)] The central claim that no query-time method clears the expert on RL-near-ceiling experts (FourTank, GlassFurnace) and the diagnosis of failure mode F1 both rest on classifying these experts as close to the no-expert-RL performance limit within the 1M-step budget. The manuscript provides no evidence that the no-expert SAC baselines have plateaued (e.g., flat learning curves, statistical tests for no further improvement, or convergence diagnostics). If the baselines are still rising at 1M steps, the experts are not demonstrably RL-near-ceiling, which undercuts both F1 and the conclusion that query-time guidance hits a wall.
Authors: We agree that explicit evidence of plateauing strengthens the claim. The manuscript defines RL-near-ceiling relative to the 1M-step budget (distinct from absolute optimality) and already notes that longer training might close the gap. In the revision we will add the full learning curves for no-expert SAC on FourTank and GlassFurnace, which show stabilization well before 1M steps, together with a simple statistical check (e.g., no significant improvement over the final 200k steps). This directly supports the F1 diagnosis while preserving the manuscript's cautious framing that the observed wall may be budget-dependent. revision: yes
Circularity Check
No circularity: empirical comparisons and induced decision rule are self-contained
full rationale
The paper performs harmonized empirical evaluations of query-time expert-guided RL methods on continuous-control tasks with controlled expert degradations. Central claims rest on observed performance differences, failure-mode identification (F1-F3), and a decision rule induced from pre-training observables (expert quality, task termination, perturbation type). No equations, parameter fits, or derivations are presented that reduce by construction to the paper's own inputs or self-citations. The RL-near-ceiling classification is an empirical labeling based on 1M-step budgets rather than a self-definitional or fitted prediction. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
free parameters (1)
- decision-rule thresholds
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
No single method dominates: each wins on one task-structure regime and fails predictably elsewhere; on RL-near-ceiling experts (FourTank, GlassFurnace) no query-time method clears the expert within our 1M-step budget
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
F1: Critic blind spot (argmax-gating methods). IBRL combines argmax action selection with an expert-action TD bootstrap
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Akiba, Takuya and Sano, Shotaro and Yanase, Toshihiko and Ohta, Takeru and Koyama, Masanori , title =. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD) , year =
- [2]
-
[3]
Agarwal, Rishabh and Schwarzer, Max and Castro, Pablo Samuel and Courville, Aaron C. and Bellemare, Marc G. , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[4]
Fu, Justin and Kumar, Aviral and Nachum, Ofir and Tucker, George and Levine, Sergey , title =. 2020 , howpublished =
work page 2020
-
[5]
Conference on Robot Learning (CoRL) , year =
Mandlekar, Ajay and Xu, Danfei and Wong, Josiah and Nasiriany, Soroush and Wang, Chen and Kulkarni, Rohun and Fei-Fei, Li and Savarese, Silvio and Zhu, Yuke and Mart\'in-Mart\'in, Roberto , title =. Conference on Robot Learning (CoRL) , year =
-
[6]
and Smith, Laura and Kostrikov, Ilya and Levine, Sergey , title =
Ball, Philip J. and Smith, Laura and Kostrikov, Ilya and Levine, Sergey , title =. International Conference on Machine Learning (ICML) , year =
-
[7]
International Conference on Machine Learning (ICML) , year =
Haarnoja, Tuomas and Zhou, Aurick and Abbeel, Pieter and Levine, Sergey , title =. International Conference on Machine Learning (ICML) , year =
-
[8]
Robotics: Science and Systems (RSS) , year =
Hu, Hengyuan and Mirchandani, Suvir and Sadigh, Dorsa , title =. Robotics: Science and Systems (RSS) , year =
-
[9]
Frontiers in Robotics and AI , volume =
Shen, Chaoran and Sloth, Christoffer , title =. Frontiers in Robotics and AI , volume =. 2026 , note =
work page 2026
-
[10]
IEEE International Conference on Robotics and Automation (ICRA) , year =
Johannink, Tobias and Bahl, Shikhar and Nair, Ashvin and Luo, Jianlan and Kumar, Avinash and Loskyll, Matthias and Ojea, Juan Aparicio and Solowjow, Eugen and Levine, Sergey , title =. IEEE International Conference on Robotics and Automation (ICRA) , year =
-
[11]
International Conference on Machine Learning (ICML) , year =
Lee, Kimin and Laskin, Michael and Srinivas, Aravind and Abbeel, Pieter , title =. International Conference on Machine Learning (ICML) , year =
-
[12]
Nair, Ashvin and Gupta, Abhishek and Dalal, Murtaza and Levine, Sergey , title =. 2020 , howpublished =
work page 2020
-
[13]
International Conference on Artificial Intelligence and Statistics (AISTATS) , year =
Ross, St\'ephane and Gordon, Geoffrey and Bagnell, Drew , title =. International Conference on Artificial Intelligence and Statistics (AISTATS) , year =
-
[14]
Automatic Tuning of Simple Regulators with Specifications on Phase and Amplitude Margins , journal =. 1984 , url =
work page 1984
- [15]
-
[16]
Mathematics of Operations Research , volume =
Russo, Daniel and Van Roy, Benjamin , title =. Mathematics of Operations Research , volume =. 2014 , url =
work page 2014
-
[17]
Foundations and Trends in Machine Learning , volume =
Russo, Daniel and Van Roy, Benjamin and Kazerouni, Abbas and Osband, Ian and Wen, Zheng , title =. Foundations and Trends in Machine Learning , volume =. 2018 , url =
work page 2018
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Osband, Ian and Blundell, Charles and Pritzel, Alexander and Van Roy, Benjamin , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , year =
An, Gaon and Moon, Seungyong and Kim, Jang-Hyun and Song, Hyun Oh , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[20]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Ghasemipour, Seyed Kamyar Seyed and Gu, Shixiang Shane and Nachum, Ofir , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[21]
Conservative Bandits , booktitle =
Wu, Yifan and Shariff, Roshan and Lattimore, Tor and Szepesv\'. Conservative Bandits , booktitle =. 2016 , url =
work page 2016
-
[22]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Kazerouni, Abbas and Ghavamzadeh, Mohammad and Abbasi-Yadkori, Yasin and Van Roy, Benjamin , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[23]
IEEE Transactions on Control Systems Technology , volume =
Johansson, Karl Henrik , title =. IEEE Transactions on Control Systems Technology , volume =. 2000 , url =
work page 2000
-
[24]
Journal of Global Optimization , volume =
Storn, Rainer and Price, Kenneth , title =. Journal of Global Optimization , volume =. 1997 , url =
work page 1997
-
[25]
International Conference on Machine Learning (ICML) , year =
Uchendu, Ikechukwu and Xiao, Ted and Lu, Yao and Zhu, Banghua and Yan, Mengyuan and Simon, Jos\'ephine and Bennice, Matthew and Fu, Chuyuan and Ma, Cong and Jiao, Jiantao and Levine, Sergey and Hausman, Karol , title =. International Conference on Machine Learning (ICML) , year =
-
[26]
International Conference on Learning Representations (ICLR) , year =
Zhang, Haichao and Xu, Wei and Yu, Haonan , title =. International Conference on Learning Representations (ICLR) , year =
-
[27]
International Conference on Learning Representations (ICLR) , year =
Rengarajan, Desik and Vaidya, Gargi and Sarvesh, Akshay and Kalathil, Dileep and Shakkottai, Srinivas , title =. International Conference on Learning Representations (ICLR) , year =
-
[28]
International Conference on Learning Representations (ICLR) , year =
Kostrikov, Ilya and Nair, Ashvin and Levine, Sergey , title =. International Conference on Learning Representations (ICLR) , year =
- [29]
-
[30]
Tassa, Yuval and Doron, Yotam and Muldal, Alistair and Erez, Tom and Li, Yazhe and de Las Casas, Diego and Budden, David and Abdolmaleki, Abbas and Merel, Josh and Lefrancq, Andrew and Lillicrap, Timothy and Riedmiller, Martin , title =. 2018 , howpublished =
work page 2018
-
[31]
Bradbury, James and Frostig, Roy and Hawkins, Peter and Johnson, Matthew James and Leary, Chris and Maclaurin, Dougal and Necula, George and Paszke, Adam and VanderPlas, Jake and Wanderman-Milne, Skye and Zhang, Qiao , title =. 2018 , url =
work page 2018
-
[32]
Virtanen, Pauli and others , title =. Nature Methods , volume =. 2020 , url =
work page 2020
- [33]
- [34]
-
[35]
Ijspeert, Auke Jan , title =. Neural Networks , volume =. 2008 , url =
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.