Recognition: no theorem link
Noise-Started One-Step Real-World Super-Resolution via LR-Conditioned SplitMeanFlow and GAN Refinement
Pith reviewed 2026-05-12 04:00 UTC · model grok-4.3
The pith
SMFSR achieves state-of-the-art perceptual quality among one-step diffusion-based real-world super-resolution methods by preserving noise-started generation with LR-conditioned SplitMeanFlow and GAN refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SMFSR preserves the random-noise starting point of diffusion models and learns a direct noise-to-HR mapping conditioned on the LR image. Interval Splitting Consistency distills the multi-step generative trajectory into a single average-velocity prediction, enabling efficient one-step generation. A subsequent GAN refinement stage, using a DINOv3-based discriminator to enhance realistic texture synthesis and variational score distillation to align outputs with the natural image distribution under a frozen diffusion teacher, compensates for reduced progressive refinement. This yields state-of-the-art perceptual quality among one-step diffusion-based Real-ISR methods while keeping fast single-in
What carries the argument
LR-Conditioned SplitMeanFlow, which distills multi-step diffusion trajectories into a single average-velocity prediction under low-resolution image conditioning to support noise-started one-step generation.
If this is right
- Real-world low-resolution images can be upscaled in one fast inference pass while retaining the one-to-many mapping and realistic detail synthesis of diffusion models.
- The efficiency-quality gap narrows for conditional generative restoration tasks that previously required many denoising steps.
- GAN-based post-processing can substitute for some of the progressive refinement lost when compressing diffusion trajectories into one step.
- Applications needing both speed and natural image statistics, such as real-time photo enhancement, become more practical with single-step diffusion.
Where Pith is reading between the lines
- Hybrid diffusion-then-GAN pipelines may prove useful for other conditional generation problems where full multi-step sampling is too slow for deployment.
- The distillation approach could extend to video super-resolution or other temporal tasks by applying similar interval splitting under conditioning signals.
- If the single-step mapping generalizes well, large pre-trained diffusion models might be adapted for practical super-resolution with far lower inference cost than iterative sampling.
Load-bearing premise
The single average-velocity prediction from Interval Splitting Consistency keeps enough stochasticity and refinement potential that the later GAN stage can fully recover or surpass the quality of multi-step iterative denoising.
What would settle it
An ablation where the GAN refinement stage is removed and SMFSR perceptual scores or texture diversity fall below those of established multi-step diffusion baselines on standard real-world super-resolution benchmarks.
Figures




read the original abstract
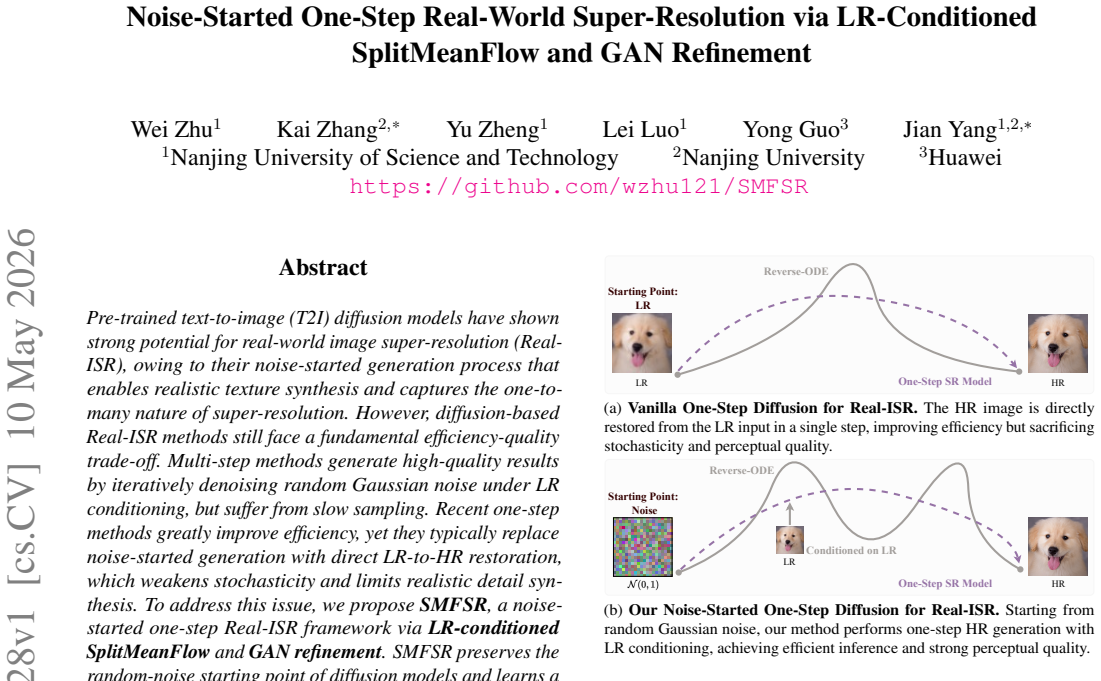
Pre-trained text-to-image (T2I) diffusion models have shown strong potential for real-world image super-resolution (Real-ISR), owing to their noise-started generation process that enables realistic texture synthesis and captures the one-to-many nature of super-resolution. However, diffusion-based Real-ISR methods still face a fundamental efficiency-quality trade-off. Multi-step methods generate high-quality results by iteratively denoising random Gaussian noise under LR conditioning, but suffer from slow sampling. Recent one-step methods greatly improve efficiency, yet they typically replace noise-started generation with direct LR-to-HR restoration, which weakens stochasticity and limits realistic detail synthesis. To address this issue, we propose SMFSR, a noise-started one-step Real-ISR framework via LR-conditioned SplitMeanFlow and GAN refinement. SMFSR preserves the random-noise starting point of diffusion models and learns a direct noise-to-HR mapping conditioned on the LR image. To this end, Interval Splitting Consistency distills the multi-step generative trajectory into a single average-velocity prediction, enabling efficient one-step generation. To compensate for the reduced opportunity for progressive refinement, we further introduce a GAN refinement stage, where a DINOv3-based discriminator enhances realistic texture synthesis and variational score distillation aligns the generated outputs with the natural image distribution under a frozen diffusion teacher. Extensive experiments demonstrate that SMFSR achieves state-of-the-art perceptual quality among one-step diffusion-based Real-ISR methods while retaining fast single-step inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SMFSR, a noise-started one-step Real-ISR framework that preserves the random Gaussian noise initialization of diffusion models. It employs LR-conditioned SplitMeanFlow with Interval Splitting Consistency to distill multi-step generative trajectories into a single average-velocity prediction, followed by a GAN refinement stage using a DINOv3-based discriminator and variational score distillation to enhance realistic textures and align outputs with the natural image distribution under a frozen diffusion teacher. The central claim is that this achieves state-of-the-art perceptual quality among one-step diffusion-based Real-ISR methods while retaining fast single-step inference.
Significance. If the experimental claims hold with proper validation, the work would be significant for practical Real-ISR applications by resolving the efficiency-quality trade-off in diffusion models. It retains the stochastic noise-starting point (unlike direct LR-to-HR one-step methods) while adding targeted distillation and refinement components, offering a potentially balanced approach that could enable faster inference without fully sacrificing generative diversity.
major comments (2)
- [Abstract] Abstract: The central claim of SOTA perceptual quality among one-step diffusion-based Real-ISR methods is asserted without any quantitative metrics, baselines, ablation studies, or experimental details. This absence makes it impossible to assess whether the data support the claim that SMFSR outperforms prior one-step methods in perceptual quality while preserving stochasticity.
- [Method (Interval Splitting Consistency)] Method description of Interval Splitting Consistency: The approach assumes that averaging velocities over fixed intervals approximates the full noise-to-HR distribution without mode collapse or loss of high-frequency stochastic components. No diversity metrics (e.g., output variance across random seeds or perceptual mode coverage) are referenced to validate that the one-to-many mapping required for realistic Real-ISR textures survives the distillation; the subsequent GAN stage cannot recover lost modes if averaging smooths them out.
minor comments (1)
- [Abstract] The description of the GAN refinement stage references 'variational score distillation' but does not provide the exact loss formulation or implementation details relative to the frozen diffusion teacher.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below with clarifications drawn directly from the work and indicate where revisions will be made to improve transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of SOTA perceptual quality among one-step diffusion-based Real-ISR methods is asserted without any quantitative metrics, baselines, ablation studies, or experimental details. This absence makes it impossible to assess whether the data support the claim that SMFSR outperforms prior one-step methods in perceptual quality while preserving stochasticity.
Authors: We agree that the abstract would benefit from more concrete support for the SOTA claim. While the full manuscript provides extensive quantitative comparisons (including perceptual metrics such as LPIPS and FID against one-step diffusion baselines, plus ablation studies on the SplitMeanFlow and GAN components) in the Experiments section, the abstract itself remains high-level. We will revise the abstract to include a brief mention of key quantitative improvements to allow readers to immediately assess the claim. revision: yes
-
Referee: [Method (Interval Splitting Consistency)] Method description of Interval Splitting Consistency: The approach assumes that averaging velocities over fixed intervals approximates the full noise-to-HR distribution without mode collapse or loss of high-frequency stochastic components. No diversity metrics (e.g., output variance across random seeds or perceptual mode coverage) are referenced to validate that the one-to-many mapping required for realistic Real-ISR textures survives the distillation; the subsequent GAN stage cannot recover lost modes if averaging smooths them out.
Authors: We appreciate this important point on validating stochasticity preservation. Interval Splitting Consistency is formulated to compute an average velocity over noise intervals while retaining the random Gaussian noise initialization and LR conditioning, which are intended to maintain the one-to-many generative capacity of the original diffusion process. The subsequent GAN refinement with DINOv3 discriminator and variational score distillation is added precisely to restore and enhance high-frequency textures. We acknowledge that explicit diversity metrics (output variance across seeds or mode coverage) were not reported in the original submission. We will add these analyses in the revision to directly demonstrate that the distillation does not induce mode collapse. revision: yes
Circularity Check
No circularity detected in the derivation
full rationale
The paper presents SMFSR as a novel combination of LR-conditioned SplitMeanFlow (via Interval Splitting Consistency distillation) and a subsequent GAN refinement stage built on top of pre-trained T2I diffusion models. No equations or claims reduce a result to its own fitted inputs by construction, no load-bearing uniqueness theorems are imported via self-citation, and no ansatz is smuggled through prior author work. The central claims rest on the proposed components' ability to preserve noise-started stochasticity while enabling one-step inference, which is positioned as an empirical extension rather than a definitional tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The perception-distortion tradeoff
Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6228–6237, 2018. 7
work page 2018
-
[2]
Toward real-world single image super-resolution: A new benchmark and a new model
Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. Toward real-world single image super-resolution: A new benchmark and a new model. In2019 IEEE/CVF International Conference on Computer Vision, pages 3086– 3095, 2020. 6
work page 2020
-
[3]
arXiv preprint arXiv:2512.14061 (2025)
Hao Chen, Junyang Chen, Jinshan Pan, and Jiangxin Dong. Bridging fidelity-reality with controllable one-step diffusion for image super-resolution.arXiv preprint arXiv:2512.14061,
-
[4]
Reproducible scal- ing laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scal- ing laws for contrastive language-image learning. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023. 4
work page 2023
-
[5]
Diffusion mod- els beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion mod- els beat gans on image synthesis. InAdvances in Neural Information Processing Systems, pages 8780–8794. Curran Associates, Inc., 2021. 2
work page 2021
-
[6]
Tsd-sr: One-step diffusion with target score distillation for real-world image super-resolution
Linwei Dong, Qingnan Fan, Yihong Guo, Zhonghao Wang, Qi Zhang, Jinwei Chen, Yawei Luo, and Changqing Zou. Tsd-sr: One-step diffusion with target score distillation for real-world image super-resolution. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23174–23184, 2025. 2, 3
work page 2025
-
[7]
Dit4sr: Taming diffusion transformer for real-world image super-resolution
Zheng-Peng Duan, Jiawei Zhang, Xin Jin, Ziheng Zhang, Zheng Xiong, Dongqing Zou, Jimmy Ren, Chun-Le Guo, and Chongyi Li. Dit4sr: Taming diffusion transformer for real-world image super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision,
-
[8]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim En- tezari, Jonas M¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InPro- ceedings of the 41st International Conference on Machine Learning....
work page 2024
-
[9]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
SplitMeanFlow: Interval splitting consistency in few-step generative modeling, 2025
Yi Guo, Wei Wang, Zhihang Yuan, Rong Cao, Kuan Chen, Zhengyang Chen, Yuanyuan Huo, Yang Zhang, Yuping Wang, Shouda Liu, et al. Splitmeanflow: Interval splitting con- sistency in few-step generative modeling.arXiv preprint arXiv:2507.16884, 2025. 4
-
[11]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4396–4405, 2019. 6
work page 2019
-
[12]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. In International Conference on Computer Vision, 2021. 6
work page 2021
-
[13]
Xiangtao Kong, Rongyuan Wu, Shuaizheng Liu, Lingchen Sun, and Lei Zhang. Nsarm: Next-scale autoregressive mod- eling for robust real-world image super-resolution.arXiv preprint arXiv:2510.00820, 2025. 3
-
[14]
Black Forest Labs. Flux. https://github.com/ black-forest-labs/flux, 2024. 2
work page 2024
-
[15]
Approaching the limit of im- age rescaling via flow guidance
Shangzhou Li, Guixuan Zhang, Zhengxiong Luo, Jie Liu, Zhi Zeng, and Shuwu Zhang. Approaching the limit of im- age rescaling via flow guidance. InBritish Machine Vision Conference, 2021. 1
work page 2021
-
[16]
Lsdir: A large scale dataset for image restoration
Yawei Li, Kai Zhang, Jingyun Liang, Jiezhang Cao, Ce Liu, Rui Gong, Yulun Zhang, Hao Tang, Yun Liu, Denis Deman- dolx, Rakesh Ranjan, Radu Timofte, and Luc Van Gool. Lsdir: A large scale dataset for image restoration. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 1775–1787, 2023. 6 10
work page 2023
-
[17]
Swinir: Image restoration using swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. In2021 IEEE/CVF International Confer- ence on Computer Vision Workshops, pages 1833–1844, 2021. 6
work page 2021
-
[18]
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution.2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 1132–1140,
work page 2017
-
[19]
Xinqi Lin, Fanghua Yu, Jinfan Hu, Zhiyuan You, Wu Shi, Jimmy S Ren, Jinjin Gu, and Chao Dong. Harnessing diffusion-yielded score priors for image restoration.ACM Transactions on Graphics (TOG), 44(6):1–21, 2025. 6
work page 2025
-
[20]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxim- ilian Nickel, and Matthew Le. Flow matching for genera- tive modeling. InThe Eleventh International Conference on Learning Representations, 2023. 2
work page 2023
-
[21]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InProceedings of the 37th International Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2023. Curran Associates Inc. 6, 9
work page 2023
-
[22]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InNeurIPS 2022 Workshop on Score-Based Methods,
work page 2022
-
[23]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[25]
Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2024
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2024. 7
work page 2024
-
[26]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, and Jack Clark. Learning transferable visual models from natural language supervision. InIn 38th International Conference on Machine Learning, pages 8748–8763, 2021. 4
work page 2021
-
[27]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct prefer- ence optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023. 10
work page 2023
-
[28]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020. 4
work page 2020
-
[29]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 7
work page 2022
-
[30]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part LXXXVI, page 87–103. Springer-Verlag, 2024. 7
work page 2024
-
[31]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha¨el Ramamonjisoa, et al. Di- nov3.arXiv preprint arXiv:2508.10104, 2025. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations,
-
[33]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. In AAAI, 2023. 6
work page 2023
-
[34]
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin C.K. Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution. InInternational Journal of Computer Vision, page 5929–5949, 2024. 1, 2, 6
work page 2024
-
[35]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In2021 IEEE/CVF International Con- ference on Computer Vision Workshops, pages 1905–1914,
work page 1905
-
[36]
Sinsr: diffusion-based image super- resolution in a single step
Yufei Wang, Wenhan Yang, Xinyuan Chen, Yaohui Wang, Lanqing Guo, Lap-Pui Chau, Ziwei Liu, Yu Qiao, Alex C Kot, and Bihan Wen. Sinsr: diffusion-based image super- resolution in a single step. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25796–25805, 2024. 2, 6
work page 2024
-
[37]
Zhou Wang, Alan Conrad Bovik, Hamid Rahim Sheikh, and Eero P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Trans Image Process, 13(4):600–612, 2004. 6
work page 2004
-
[38]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.Advances in Neural Information Processing Systems, 36,
-
[39]
Component divide-and- conquer for real-world image super-resolution
Pengxu Wei, Ziwei Xie, Hannan Lu, Zongyuan Zhan, Qixiang Ye, Wangmeng Zuo, and Liang Lin. Component divide-and- conquer for real-world image super-resolution. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VIII 16, pages 101–117, 2020. 6
work page 2020
-
[40]
One-step effective diffusion network for real-world image super-resolution
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution. InAdvances in Neural Information Process- ing Systems, pages 92529–92553. Curran Associates, Inc.,
-
[41]
Seesr: Towards semantics-aware real-world image super-resolution
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. Seesr: Towards semantics-aware real-world image super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 25456–25467, 2024. 1, 2, 6, 7, 9 11
work page 2024
-
[42]
Maniqa: Multi-dimension at- tention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shu Shi, Shan Gong, Ming Cao, Ji- ahao Wang, and Yujiu Yang. Maniqa: Multi-dimension at- tention network for no-reference image quality assessment. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 1190–1199, 2022. 6
work page 2022
-
[43]
Pixel-aware stable diffusion for realistic image super- resolution and personalized stylization
Tao Yang, Rongyuan Wu, Peiran Ren, Xuansong Xie, and Lei Zhang. Pixel-aware stable diffusion for realistic image super- resolution and personalized stylization. InThe European Conference on Computer Vision (ECCV) 2024, 2024. 1, 2, 6
work page 2024
-
[44]
Consistency trajectory match- ing for one-step generative super-resolution
Weiyi You, Mingyang Zhang, Leheng Zhang, Xingyu Zhou, Kexuan Shi, and Shuhang Gu. Consistency trajectory match- ing for one-step generative super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 12747–12756, 2025. 3, 6
work page 2025
-
[45]
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo- realistic image restoration in the wild. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25669–25680, 2024. 1, 2, 6, 7
work page 2024
-
[46]
Resshift: Efficient diffusion model for image super-resolution by resid- ual shifting
Zongsheng Yue, Jianyi Wang, and Chen Change Loy. Resshift: Efficient diffusion model for image super-resolution by resid- ual shifting. InAdvances in Neural Information Processing Systems, pages 13294–13307, 2023. 6
work page 2023
-
[47]
Arbitrary- steps image super-resolution via diffusion inversion
Zongsheng Yue, Kang Liao, and Chen Change Loy. Arbitrary- steps image super-resolution via diffusion inversion. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 23153–23163, 2025. 6
work page 2025
-
[48]
Degradation-guided one-step image super- resolution with diffusion priors, 2024
Aiping Zhang, Zongsheng Yue, Renjing Pei, Wenqi Ren, and Xiaochun Cao. Degradation-guided one-step image super- resolution with diffusion priors, 2024. 6
work page 2024
-
[49]
Designing a practical degradation model for deep blind im- age super-resolution
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timofte. Designing a practical degradation model for deep blind im- age super-resolution. InIEEE International Conference on Computer Vision, pages 4791–4800, 2021. 1, 6
work page 2021
-
[50]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 6
work page 2018
-
[51]
Perception- distortion balanced admm optimization for single-image super-resolution
Yuehan Zhang, Bo Ji, Jia Hao, and Angela Yao. Perception- distortion balanced admm optimization for single-image super-resolution. InEuropean Conference on Computer Vi- sion, pages 108–125. Springer, 2022. 7
work page 2022
-
[52]
DiffusionNFT: Online diffusion re- inforcement with forward process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. DiffusionNFT: Online diffusion re- inforcement with forward process. InThe Fourteenth In- ternational Conference on Learning Representations, 2026. 10 12
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.