Recognition: unknown
Explainable Knowledge Tracing via Probabilistic Embeddings and Pattern-based Reasoning
Pith reviewed 2026-05-12 03:02 UTC · model grok-4.3
The pith
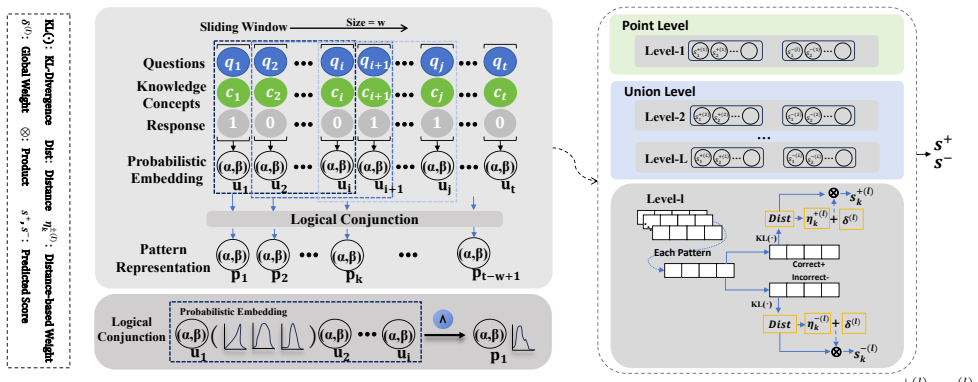
PLKT represents student knowledge states as Beta-distributed probabilistic embeddings and applies explicit logical operations on historical interactions to produce accurate predictions with transparent reasoning paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PLKT formulates prediction as a goal-conditioned evidence reasoning process over historical learning behaviors, replacing deterministic vector embeddings with robust Beta-distributed probabilistic embeddings that support explicit logical operations such as conjunction and thereby construct transparent reasoning paths from specific past interactions to the final prediction.
What carries the argument
Beta-distributed probabilistic embeddings that enable direct logical operations on historical interaction sequences within a goal-conditioned reasoning process.
If this is right
- PLKT reports higher predictive accuracy than state-of-the-art KT methods on standard benchmarks.
- The model produces explicit reasoning paths that show how particular past interactions contribute to each prediction.
- Uncertainty in historical behaviors is modeled directly through the Beta distributions rather than hidden in deterministic vectors.
- Logical operations such as conjunction can be applied transparently to the probabilistic representations.
Where Pith is reading between the lines
- The explicit paths could let teachers identify recurring patterns of error in a student's record and target specific remediation.
- The same probabilistic-plus-logical structure might transfer to other sequential prediction domains that need both accuracy and auditability.
- If the Beta distributions prove stable across datasets, the approach could reduce reliance on post-hoc explanation techniques in educational AI.
Load-bearing premise
Robust Beta-distributed embeddings together with explicit logical operations will simultaneously raise predictive accuracy and deliver genuinely human-interpretable reasoning paths without creating new opacity or overfitting to the chosen patterns.
What would settle it
An experiment in which PLKT matches or exceeds baseline accuracy but human experts rate its generated reasoning paths as no more aligned with actual student learning sequences than the paths of a standard black-box KT model.
Figures






read the original abstract
Knowledge Tracing (KT) models students' knowledge states based on learning interactions to predict performance. While deep learning-based KT models have boosted predictive accuracy, most models rely on deterministic vector embeddings and opaque latent state transitions, limiting interpretability regarding how specific past behaviors influence predictions. To address this limitation, we propose Probabilistic Logical Knowledge Tracing (PLKT), an interpretable KT framework that formulates prediction as a goal-conditioned evidence reasoning process over historical learning behaviors. Instead of representing knowledge states as deterministic vector embeddings, PLKT employs robust Beta-distributed probabilistic embeddings to represent student knowledge states. This probabilistic foundation allows us to model the uncertainty of historical behaviors and perform explicit logical operations (e.g., conjunction), constructing transparent reasoning paths that reveal how specific past interactions contribute to the prediction. Extensive experiments show that PLKT outperforms state-of-the-art KT methods while achieving superior interpretability. Our code is available at https://anonymous.4open.science/r/PLKT-D3CE/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Probabilistic Logical Knowledge Tracing (PLKT), a KT framework that replaces deterministic embeddings with Beta-distributed probabilistic embeddings for student knowledge states. Prediction is formulated as goal-conditioned evidence reasoning over historical interactions using explicit logical operations (e.g., conjunction) on these distributions to produce transparent reasoning paths. The central claim is that PLKT simultaneously achieves higher predictive accuracy than SOTA KT methods and superior interpretability, supported by extensive experiments; code is released.
Significance. If the empirical claims and interpretability validation hold, the work would meaningfully advance interpretable educational AI by combining probabilistic uncertainty modeling with logical pattern-based reasoning. This addresses a key limitation of deep KT models (opacity of latent transitions) while preserving or improving accuracy. The release of code is a positive step toward reproducibility.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The abstract asserts that 'extensive experiments show that PLKT outperforms state-of-the-art KT methods' yet reports no numerical results, specific baselines, effect sizes, or statistical significance tests. This makes the central performance claim impossible to evaluate from the provided text; the full manuscript must include these details (e.g., AUC, accuracy deltas, and p-values) for the outperformance assertion to be load-bearing.
- [§3.2] §3.2 (Logical Operations on Beta Embeddings): The claim that explicit logical operations (conjunction etc.) on Beta distributions yield 'transparent reasoning paths' is not accompanied by any quantitative interpretability metric (explanation fidelity, rule coverage, or inter-rater agreement with educators) or user study. If operations are implemented via t-norms or moment-matching, the propagated Beta parameters may remain non-intuitive, undermining the interpretability advantage over attention weights.
- [§3.1] §3.1 (Beta-distributed Embeddings): The framework relies on free Beta shape parameters (as noted in the axiom ledger) yet presents the approach as introducing new components rather than re-expressing fitted quantities. The manuscript must clarify whether performance gains reduce to these parameters by construction and provide ablation results isolating the contribution of the probabilistic embedding versus the logical reasoning layer.
minor comments (2)
- [§3] Notation for Beta parameters (α, β) should be explicitly defined at first use and distinguished from any other shape parameters in the model.
- [Abstract and §3] The abstract mentions 'pattern-based reasoning' but the full text should include a clear definition or pseudocode for how historical behaviors are mapped to logical patterns.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The abstract asserts that 'extensive experiments show that PLKT outperforms state-of-the-art KT methods' yet reports no numerical results, specific baselines, effect sizes, or statistical significance tests. This makes the central performance claim impossible to evaluate from the provided text; the full manuscript must include these details (e.g., AUC, accuracy deltas, and p-values) for the outperformance assertion to be load-bearing.
Authors: We agree that the abstract should be more self-contained with concrete performance evidence. In the revised version we will expand the abstract to report key results, including AUC and accuracy improvements over the main baselines (DKT, AKT, and others), the magnitude of the deltas, and confirmation that statistical significance was assessed via paired t-tests (p < 0.05) as detailed in §4. The full experimental tables, baselines, effect sizes, and p-values are already present in §4; the revision will simply surface the most salient numbers in the abstract for immediate evaluability. revision: yes
-
Referee: [§3.2] §3.2 (Logical Operations on Beta Embeddings): The claim that explicit logical operations (conjunction etc.) on Beta distributions yield 'transparent reasoning paths' is not accompanied by any quantitative interpretability metric (explanation fidelity, rule coverage, or inter-rater agreement with educators) or user study. If operations are implemented via t-norms or moment-matching, the propagated Beta parameters may remain non-intuitive, undermining the interpretability advantage over attention weights.
Authors: We acknowledge the absence of quantitative interpretability metrics in the original submission. We will add a new paragraph in §4 that quantifies explanation fidelity on synthetic data (where ground-truth logical patterns are known) by measuring how often the constructed reasoning paths recover the injected conjunction/disjunction structure, together with rule-coverage statistics. We also clarify in §3.2 that the logical operations are realized via closed-form Beta-parameter updates (lower-bound min for conjunction, etc.) rather than generic t-norms, so the resulting distributions remain directly interpretable as combined evidence. A full educator user study lies outside the scope of the current work and will be noted as future research; we therefore mark this revision as partial. revision: partial
-
Referee: [§3.1] §3.1 (Beta-distributed Embeddings): The framework relies on free Beta shape parameters (as noted in the axiom ledger) yet presents the approach as introducing new components rather than re-expressing fitted quantities. The manuscript must clarify whether performance gains reduce to these parameters by construction and provide ablation results isolating the contribution of the probabilistic embedding versus the logical reasoning layer.
Authors: We appreciate the request for clarification. The Beta shape parameters are indeed learned end-to-end, but the modeling contribution is the use of full Beta distributions that enable the subsequent logical operations; deterministic embeddings cannot support the same explicit reasoning. We will revise §3.1 to state this distinction explicitly. In addition, we will insert two ablation experiments in §4: (1) replacing the logical-reasoning layer with simple aggregation while keeping Beta embeddings, and (2) replacing Beta embeddings with deterministic vectors while retaining the logical layer. These results will demonstrate that both components are necessary for the observed gains and that the improvements are not reducible to the mere presence of extra parameters. revision: yes
Circularity Check
No circularity; new probabilistic embedding and reasoning framework is self-contained without reduction to fitted inputs or self-citations
full rationale
The abstract and description introduce PLKT as a novel framework that replaces deterministic embeddings with Beta-distributed probabilistic ones and adds explicit logical operations for goal-conditioned reasoning. No equations, derivation steps, or self-citations are visible that would allow any performance claim or interpretability path to reduce by construction to prior fitted parameters or author-defined uniqueness theorems. The central claims rest on experimental outperformance and the explicitness of the new components rather than re-labeling or self-referential fitting, making the derivation independent and non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- Beta distribution shape parameters
axioms (2)
- domain assumption Beta distributions provide a robust probabilistic representation of knowledge state uncertainty
- domain assumption Explicit logical operations such as conjunction can be performed directly on probabilistic embeddings to construct transparent reasoning paths
invented entities (1)
-
Probabilistic Logical Knowledge Tracing (PLKT) framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
[Baiet al., 2025 ] Youheng Bai, Xueyi Li, Zitao Liu, Yaying Huang, Teng Guo, Mingliang Hou, Feng Xia, and Weiqi Luo. cskt: Addressing cold-start problem in knowledge tracing via kernel bias and cone attention.Expert Systems with Applications, 266:125988,
work page 2025
-
[2]
Knowledge-enhanced multi-view graph neural networks for session-based recommendation
[Chenet al., 2023 ] Qian Chen, Zhiqiang Guo, Jianjun Li, and Guohui Li. Knowledge-enhanced multi-view graph neural networks for session-based recommendation. In Proceedings of the 46th international ACM SIGIR con- ference on research and development in information re- trieval, pages 352–361,
work page 2023
-
[3]
Uncertainty-aware knowledge tracing
[Chenget al., 2025 ] Weihua Cheng, Hanwen Du, Chunxiao Li, Ersheng Ni, Liangdi Tan, Tianqi Xu, and Yongxin Ni. Uncertainty-aware knowledge tracing. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27905–27913,
work page 2025
-
[4]
Towards an appropriate query, key, and value computation for knowledge tracing
[Choiet al., 2020 ] Youngduck Choi, Youngnam Lee, Junghyun Cho, Jineon Baek, Byungsoo Kim, Yeongmin Cha, Dongmin Shin, Chan Bae, and Jaewe Heo. Towards an appropriate query, key, and value computation for knowledge tracing. InProceedings of the seventh ACM conference on learning@ scale, pages 341–344,
work page 2020
-
[5]
[Duanet al., 2024 ] Zhiyi Duan, Xiaoxiao Dong, Hengnian Gu, Xiong Wu, Zhen Li, and Dongdai Zhou. Towards more accurate and interpretable model: Fusing multiple knowledge relations into deep knowledge tracing.Expert Systems with Applications, 243:122573,
work page 2024
-
[6]
[Duanet al., 2025 ] Zhangqi Duan, Nigel Fernandez, Arun Balajiee Lekshmi Narayanan, Mohammad Hassany, Rafaella Sampaio de Alencar, Peter Brusilovsky, Bita Akram, and Andrew Lan. Automated knowledge compo- nent generation and knowledge tracing for coding prob- lems.arXiv preprint arXiv:2502.18632,
-
[7]
[Fosnot, 2013] Catherine Twomey Fosnot.Constructivism: Theory, perspectives, and practice. Teachers College Press,
work page 2013
-
[8]
Knowledge interaction enhanced knowledge tracing for learner performance prediction
[Ganet al., 2020 ] Wenbin Gan, Yuan Sun, and Yi Sun. Knowledge interaction enhanced knowledge tracing for learner performance prediction. In2020 7th International conference on behavioural and social computing (BESC), pages 1–6. IEEE,
work page 2020
-
[9]
Context-aware attentive knowledge tracing
[Ghoshet al., 2020 ] Aritra Ghosh, Neil Heffernan, and An- drew S Lan. Context-aware attentive knowledge tracing. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2330–2339,
work page 2020
-
[10]
Question difficulty prediction for reading prob- lems in standard tests
[Huanget al., 2017 ] Zhenya Huang, Qi Liu, Enhong Chen, Hongke Zhao, Mingyong Gao, Si Wei, Yu Su, and Guop- ing Hu. Question difficulty prediction for reading prob- lems in standard tests. InProceedings of the AAAI confer- ence on artificial intelligence, volume 31,
work page 2017
-
[11]
Towards robust knowl- edge tracing models via k-sparse attention
[Huanget al., 2023 ] Shuyan Huang, Zitao Liu, Xiangyu Zhao, Weiqi Luo, and Jian Weng. Towards robust knowl- edge tracing models via k-sparse attention. InProceed- ings of the 46th international ACM SIGIR conference on research and development in information retrieval, pages 2441–2445,
work page 2023
-
[12]
[Huanget al., 2024 ] Changqin Huang, Hangjie Wei, Qiong- hao Huang, Fan Jiang, Zhongmei Han, and Xiaodi Huang. Learning consistent representations with temporal and causal enhancement for knowledge tracing.Expert Sys- tems with Applications, 245:123128,
work page 2024
-
[13]
A method for stochastic optimization
[Kingaet al., 2015 ] Diederik Kinga, Jimmy Ba Adam, et al. A method for stochastic optimization. InInternational conference on learning representations (ICLR), volume
work page 2015
-
[14]
[Liet al., 2025a ] Aodong Li, Abishek Sankararaman, and Balakrishnan Narayanaswamy. Probabilistic hash embed- dings for online learning of categorical features.arXiv preprint arXiv:2511.20893,
-
[15]
[Liet al., 2025b ] Runze Li, Siyu Wu, Jun Wang, and Wei Zhang. Cikt: A collaborative and iterative knowledge trac- ing framework with large language models.arXiv preprint arXiv:2505.17705,
-
[16]
[Liuet al., 2022 ] Zitao Liu, Qiongqiong Liu, Jiahao Chen, Shuyan Huang, Jiliang Tang, and Weiqi Luo. pykt: a python library to benchmark deep learning based knowl- edge tracing models.Advances in Neural Information Pro- cessing Systems, 35:18542–18555,
work page 2022
-
[17]
[Liuet al., 2023 ] Zitao Liu, Qiongqiong Liu, Jiahao Chen, Shuyan Huang, and Weiqi Luo. simplekt: a simple but tough-to-beat baseline for knowledge tracing.arXiv preprint arXiv:2302.06881,
-
[18]
[Maet al., 2025 ] Kun Ma, Cong Xu, Zeyuan Chen, and Wei Zhang. Pattern-wise transparent sequential recommenda- tion.IEEE Transactions on Knowledge and Data Engi- neering,
work page 2025
-
[19]
Interpretable knowledge tracing: Simple and efficient student modeling with causal relations
[Minnet al., 2022 ] Sein Minn, Jill-J ˆenn Vie, Koh Takeuchi, Hisashi Kashima, and Feida Zhu. Interpretable knowledge tracing: Simple and efficient student modeling with causal relations. InProceedings of the AAAI conference on arti- ficial intelligence, volume 36, pages 12810–12818,
work page 2022
-
[20]
[Nedungadi and Remya, 2014] Prema Nedungadi and MS Remya. Predicting students’ performance on intelli- gent tutoring system—personalized clustered bkt (pc-bkt) model. In2014 IEEE frontiers in education conference (FIE) proceedings, pages 1–6. IEEE,
work page 2014
-
[21]
A Self-Attentive model for Knowledge Tracing
[Pandey and Karypis, 2019] Shalini Pandey and George Karypis. A self-attentive model for knowledge tracing. arXiv preprint arXiv:1907.06837,
work page Pith review arXiv 2019
-
[22]
Rkt: relation-aware self-attention for knowl- edge tracing
[Pandey and Srivastava, 2020] Shalini Pandey and Jaideep Srivastava. Rkt: relation-aware self-attention for knowl- edge tracing. InProceedings of the 29th ACM interna- tional conference on information & knowledge manage- ment, pages 1205–1214,
work page 2020
-
[23]
Deep knowledge trac- ing.Advances in neural information processing systems, 28,
[Piechet al., 2015 ] Chris Piech, Jonathan Bassen, Jonathan Huang, Surya Ganguli, Mehran Sahami, Leonidas J Guibas, and Jascha Sohl-Dickstein. Deep knowledge trac- ing.Advances in neural information processing systems, 28,
work page 2015
-
[24]
[Ren and Leskovec, 2020] Hongyu Ren and Jure Leskovec. Beta embeddings for multi-hop logical reasoning in knowledge graphs.Advances in Neural Information Pro- cessing Systems, 33:19716–19726,
work page 2020
-
[25]
Learning process-consistent knowledge tracing
[Shenet al., 2021 ] Shuanghong Shen, Qi Liu, Enhong Chen, Zhenya Huang, Wei Huang, Yu Yin, Yu Su, and Shijin Wang. Learning process-consistent knowledge tracing. InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, pages 1452–1460,
work page 2021
-
[26]
[Shenet al., 2024 ] Shuanghong Shen, Qi Liu, Zhenya Huang, Yonghe Zheng, Minghao Yin, Minjuan Wang, and Enhong Chen. A survey of knowledge tracing: Models, variants, and applications.IEEE Transactions on Learn- ing Technologies, 17:1858–1879,
work page 2024
-
[27]
[Shenet al., 2025 ] Xiaoxuan Shen, Fenghua Yu, Yaqi Liu, Ruxia Liang, Qian Wan, Tianhao Yang, Mengtian Shi, and Jianwen Sun. Enhancing knowledge tracing with question- based contrastive learning.Knowledge-Based Systems, page 113899,
work page 2025
-
[28]
[Suet al., 2021 ] Yu Su, Zeyu Cheng, Pengfei Luo, Jinze Wu, Lei Zhang, Qi Liu, and Shijin Wang. Time-and-concept enhanced deep multidimensional item response theory for interpretable knowledge tracing.Knowledge-Based Sys- tems, 218:106819,
work page 2021
-
[29]
[Sunet al., 2022 ] Jianwen Sun, Rui Zou, Ruxia Liang, Lu Gao, Sannyuya Liu, Qing Li, Kai Zhang, and Lulu Jiang. Ensemble knowledge tracing: Modeling interac- tions in learning process.Expert Systems with Applica- tions, 207:117680,
work page 2022
-
[30]
Interpretable knowledge tracing with multiscale state representation
[Sunet al., 2024b ] Jianwen Sun, Fenghua Yu, Qian Wan, Qing Li, Sannyuya Liu, and Xiaoxuan Shen. Interpretable knowledge tracing with multiscale state representation. In Proceedings of the ACM Web Conference 2024, pages 3265–3276,
work page 2024
-
[31]
Exercise recommendation based on knowl- edge concept prediction.Knowledge-Based Systems, 210:106481,
[Wuet al., 2020 ] Zhengyang Wu, Ming Li, Yong Tang, and Qingyu Liang. Exercise recommendation based on knowl- edge concept prediction.Knowledge-Based Systems, 210:106481,
work page 2020
-
[32]
[Wuet al., 2023 ] Siyu Wu, Jun Wang, and Wei Zhang. Con- trastive personalized exercise recommendation with rein- forcement learning.IEEE Transactions on Learning Tech- nologies, 17:691–703,
work page 2023
-
[33]
[Wuet al., 2024 ] Siyu Wu, Yang Cao, Jiajun Cui, Runze Li, Hong Qian, Bo Jiang, and Wei Zhang. A comprehensive exploration of personalized learning in smart education: From student modeling to personalized recommendations. arXiv preprint arXiv:2402.01666,
-
[34]
[Xia and Li, 2025] Xiao-li Xia and Hou-biao Li. Flatformer: A flat transformer knowledge tracing model based on cog- nitive bias injection.arXiv preprint arXiv:2512.06629,
-
[35]
Geometric relational embeddings: A survey.arXiv preprint arXiv:2304.11949,
[Xionget al., 2023 ] Bo Xiong, Mojtaba Nayyeri, Ming Jin, Yunjie He, Michael Cochez, Shirui Pan, and Steffen Staab. Geometric relational embeddings: A survey.arXiv preprint arXiv:2304.11949,
-
[36]
Addressing two problems in deep knowledge tracing via prediction-consistent regularization
[Yeung and Yeung, 2018] Chun-Kit Yeung and Dit-Yan Ye- ung. Addressing two problems in deep knowledge tracing via prediction-consistent regularization. InProceedings of the fifth annual ACM conference on learning at scale, pages 1–10,
work page 2018
-
[37]
[Yeung, 2019] Chun-Kit Yeung. Deep-irt: Make deep learn- ing based knowledge tracing explainable using item re- sponse theory.arXiv preprint arXiv:1904.11738,
-
[38]
[Yuet al., 2025 ] Ganfeng Yu, Zhiwen Xie, Guangyou Zhou, Zhuo Zhao, and Jimmy Xiangji Huang. Exploring long- and short-term knowledge state graph representations with adaptive fusion for knowledge tracing.Information Pro- cessing & Management, 62(3):104074,
work page 2025
-
[39]
Dynamic key-value memory networks for knowledge tracing
[Zhanget al., 2017 ] Jiani Zhang, Xingjian Shi, Irwin King, and Dit-Yan Yeung. Dynamic key-value memory networks for knowledge tracing. InProceedings of the 26th inter- national conference on World Wide Web, pages 765–774,
work page 2017
-
[40]
Multi- factors aware dual-attentional knowledge tracing
[Zhanget al., 2021 ] Moyu Zhang, Xinning Zhu, Chunhong Zhang, Yang Ji, Feng Pan, and Changchuan Yin. Multi- factors aware dual-attentional knowledge tracing. InPro- ceedings of the 30th ACM international conference on in- formation & knowledge management, pages 2588–2597,
work page 2021
-
[41]
Disentangled knowledge tracing for alleviating cognitive bias
[Zhouet al., 2025 ] Yiyun Zhou, Zheqi Lv, Shengyu Zhang, and Jingyuan Chen. Disentangled knowledge tracing for alleviating cognitive bias. InProceedings of the ACM on Web Conference 2025, pages 2633–2645,
work page 2025
-
[42]
Correct” status for target questions (α− t+1,β − t+1)∈R 2d distribution of “Incorrect
Notation Description u∈ U,q∈ Q,c∈ C student, question, knowledge concept r∈ {0,1} response of student (1: Correct, 0: Incorrect) d vector dimension hq emb, hc emb question/concept embedding functions α,β∈R d parameters of the Beta distribution (α+ t+1,β + t+1)∈R 2d distribution of “Correct” status for target questions (α− t+1,β − t+1)∈R 2d distribution of...
work page 2009
-
[43]
It consists of 27,145 students, 50,966 questions, 245 knowledge concepts, and 2,627,118 interaction records. Owing to its scale and dense interaction structure, ASSIST12 is frequently used to evaluate the scalability and performance of knowledge tracing models in large learning environ- ments. •Junyi 3: The Junyi dataset is collected from the Junyi Academ...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.