Recognition: no theorem link
AnyDepth-DETR/-YOLO: Any-depth object detection with a single network
Pith reviewed 2026-05-12 03:16 UTC · model grok-4.3
The pith
A single object detector can run at any depth by splitting stages into essential and skippable paths, trained via self-distillation between extremes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
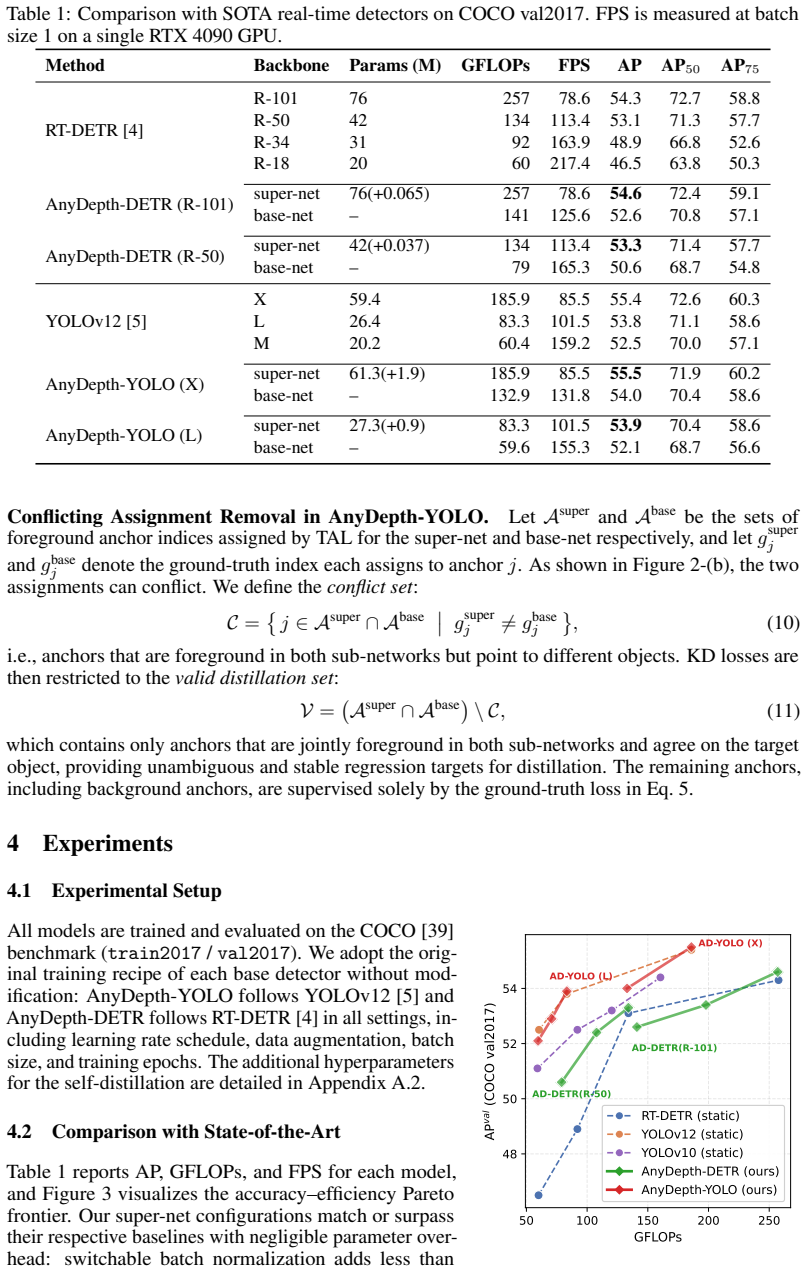
By decomposing every backbone and neck stage into an essential path that always runs and a skippable refinement path, and by training the resulting family of sub-networks with prediction-level and feature-level self-distillation losses applied only between the full-depth and minimal-depth extremes, a single set of weights produces compatible outputs at every intermediate depth; the full-depth version matches or exceeds the accuracy of prior SOTA detectors on RT-DETR and YOLOv12 while the shallowest version reaches up to 1.82 times speedup at a 2.0 AP drop.
What carries the argument
Stage-wise decomposition of backbone and neck into an essential path that always executes plus skippable refinement paths, trained with self-distillation alignment losses between only the full and minimal depth extremes to enforce modularity.
If this is right
- Full-depth configurations match or surpass the accuracy of separate SOTA baselines with negligible parameter overhead.
- Reduced-depth configurations deliver up to 1.82 times inference speedup at a cost of only 2.0 AP points.
- All accuracy-efficiency points are obtained from one trained set of weights with no retraining required.
- The full multi-scale feature hierarchy remains available at every chosen depth because entire stages are never discarded.
- Depth can be chosen at inference time, enabling a continuous spectrum of trade-offs on the same model.
Where Pith is reading between the lines
- The same essential-plus-refinement decomposition could be applied to other dense prediction tasks such as instance segmentation or depth estimation to obtain depth-adaptive versions of those models.
- Because depth selection occurs after training, the approach could support runtime adaptation where the network chooses its own depth based on input difficulty or available compute budget.
- The self-distillation recipe that enforces stage-wise compatibility may transfer to other dynamic network families that also suffer from conflicting gradients during joint training.
- On-device systems with variable power or latency constraints could host one model instead of multiple fixed-depth variants, reducing storage and update overhead.
Load-bearing premise
That forcing alignment only between the full-depth and minimal-depth outputs is enough to keep every intermediate depth configuration both accurate and internally consistent.
What would settle it
Run the trained network at several intermediate depths on a validation set and measure both final AP and the compatibility of features leaving each stage; a sharp accuracy cliff or large mismatch between stage outputs at those depths would falsify the claim that the two-extreme distillation suffices.
Figures





read the original abstract
Modern object detectors are static, fixed-depth networks optimized for a single operating point, requiring separate models for different deployment scenarios. We present an any-depth detection framework that enables a single network to span a continuous range of accuracy--efficiency trade-offs by controlling depth at inference time without retraining. Each backbone and neck stage is divided into an essential path, which always executes, and a skippable refinement path; this decomposition preserves the full multi-scale feature hierarchy at every depth configuration, unlike conventional early exiting that discards entire stages. To train such a network, jointly optimizing many sub-networks of varying depth introduces conflicting gradient signals. We address this via self-distillation between only the two extremes, with prediction-level and feature-level alignment losses that enforce stage-wise modularity, ensuring the outputs of each stage remain compatible regardless of the paths taken. Instantiated on RT-DETR and YOLOv12, our full-depth configurations match or surpass their respective SOTA baselines with negligible parameter overhead, while the most efficient configurations achieve up to $1.82\times$ speedup at a cost of only 2.0 AP, all from a single set of weights.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an any-depth object detection framework instantiated on RT-DETR and YOLOv12. Each backbone/neck stage is decomposed into an always-executed essential path and skippable refinement paths, preserving the full multi-scale feature hierarchy at any chosen depth. Joint optimization of sub-networks is handled by self-distillation (prediction-level and feature-level alignment) applied exclusively between the full-depth and minimal-depth extremes to enforce stage-wise modularity. The central empirical claim is that a single set of weights yields full-depth performance matching or exceeding SOTA baselines with negligible overhead, while the shallowest configurations deliver up to 1.82× speedup at a cost of only 2.0 AP.
Significance. If the training procedure truly produces compatible outputs across all intermediate depths, the work would provide a practical solution to the fixed-depth limitation of modern detectors, enabling a single model to serve diverse hardware constraints without retraining or multiple deployments. The preservation of the complete feature hierarchy (as opposed to conventional early-exit discarding of stages) is a constructive design choice that could generalize beyond the two evaluated detectors.
major comments (2)
- [Abstract / Training Methodology] Abstract / Training Methodology: self-distillation is performed only between the full-depth and minimal-depth configurations via prediction-level and feature-level alignment losses. No mechanism is described that directly regularizes intermediate depths when only a subset of refinement paths is skipped; this is load-bearing for the claim that 'the outputs of each stage remain compatible regardless of the paths taken' and that a continuous accuracy-efficiency curve is achieved from one set of weights.
- [Experimental claims] Experimental claims: the abstract states concrete results (full-depth parity with SOTA, 1.82× speedup at 2.0 AP drop) but provides no ablation on the contribution of each alignment loss, no verification that gradient conflicts are resolved for depths between the extremes, and no explicit list of tested depth configurations or datasets. These omissions make the central performance claims difficult to assess without additional evidence.
minor comments (2)
- The abstract would be clearer if it named the exact datasets (e.g., COCO) and the precise depth settings (e.g., number of refinement stages) used for the reported AP and speedup numbers.
- Notation for the essential vs. refinement paths and the precise form of the alignment losses should be introduced with equations in the main text rather than left at a high-level description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical value of an any-depth detector that preserves the full feature hierarchy. We address the two major comments point by point below, providing clarifications grounded in the manuscript while indicating the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Training Methodology] Abstract / Training Methodology: self-distillation is performed only between the full-depth and minimal-depth configurations via prediction-level and feature-level alignment losses. No mechanism is described that directly regularizes intermediate depths when only a subset of refinement paths is skipped; this is load-bearing for the claim that 'the outputs of each stage remain compatible regardless of the paths taken' and that a continuous accuracy-efficiency curve is achieved from one set of weights.
Authors: The self-distillation is deliberately restricted to the two extremes to avoid the prohibitive cost of jointly optimizing every possible sub-network. Because each stage is explicitly decomposed into a shared essential path and additive refinement paths, aligning the full-depth and minimal-depth outputs at both prediction and feature levels induces the desired modularity: the refinement paths learn residual improvements that can be included or excluded without breaking compatibility with the essential representation. This design choice is what enables the continuous accuracy-efficiency curve from a single set of weights. We agree that the manuscript would benefit from an expanded explanation of this inductive bias. In the revision we will add a dedicated paragraph in the training methodology section and include an ablation table showing performance at all intermediate depths to empirically confirm the continuous trade-off. revision: partial
-
Referee: [Experimental claims] Experimental claims: the abstract states concrete results (full-depth parity with SOTA, 1.82× speedup at 2.0 AP drop) but provides no ablation on the contribution of each alignment loss, no verification that gradient conflicts are resolved for depths between the extremes, and no explicit list of tested depth configurations or datasets. These omissions make the central performance claims difficult to assess without additional evidence.
Authors: The abstract is intentionally concise and therefore omits supporting experimental details that appear in the full manuscript. The experiments section already enumerates the tested depth configurations (full, ¾, ½, and minimal) and the evaluation datasets (COCO and the standard benchmarks used by the RT-DETR and YOLOv12 baselines). Nevertheless, we acknowledge that dedicated ablations on loss contributions and explicit verification of intermediate-depth behavior would strengthen the central claims. We will therefore expand the experimental section with (i) an ablation isolating the prediction-level versus feature-level alignment losses, (ii) performance curves or tables for every intermediate depth to demonstrate that gradient conflicts are resolved, and (iii) a clear summary table of all depth configurations and datasets. These additions will be included in the revised version. revision: yes
Circularity Check
No circularity: architecture and training defined independently of performance claims
full rationale
The paper defines an any-depth framework by decomposing each backbone/neck stage into an always-executed essential path plus skippable refinement paths, then trains the resulting family of sub-networks via self-distillation losses applied exclusively between the full-depth and minimal-depth extremes. These losses (prediction-level and feature-level alignment) are introduced as an explicit design choice to enforce stage-wise compatibility; the reported accuracy-efficiency numbers are obtained by evaluating the resulting single set of weights against external SOTA baselines on standard datasets. No equation or claim reduces by construction to its own inputs, no load-bearing result is justified solely by self-citation, and no fitted parameter is relabeled as a prediction. The derivation chain therefore remains self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Dividing backbone and neck stages into essential and skippable refinement paths preserves the full multi-scale feature hierarchy at every depth configuration.
- domain assumption Self-distillation between only the full and minimal depth extremes is sufficient to resolve conflicting gradients and enforce stage-wise modularity.
Reference graph
Works this paper leans on
-
[1]
Kang, W., H. Lee. Adaptive depth networks with skippable sub-paths. InAdvances in Neural Information Processing Systems, vol. 37, pages 33213–33231. 2024
work page 2024
- [2]
-
[3]
Yu, J., L. Yang, N. Xu, et al. Slimmable neural networks. InInternational Conference on Learning Representations (ICLR). 2019
work page 2019
-
[4]
Zhao, Y ., W. Lv, S. Xu, et al. DETRs Beat YOLOs on real-time object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16965–16974. 2024
work page 2024
-
[5]
Tian, Y ., Q. Ye, D. Doermann. YOLOv12: Attention-centric real-time object detectors.arXiv preprint arXiv:2502.12524, 2025
work page internal anchor Pith review arXiv 2025
- [6]
-
[7]
Liu, S., L. Qi, H. Qin, et al. Path aggregation network for instance segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018
work page 2018
- [8]
-
[9]
Liu, S., F. Li, H. Zhang, et al. DAB-DETR: Dynamic anchor boxes are better queries for DETR. InInternational Conference on Learning Representations. 2022
work page 2022
- [10]
-
[11]
Zhang, H., F. Li, S. Liu, et al. DINO: DETR with improved denoising anchor boxes for end-to-end object detection. InInternational Conference on Learning Representations. 2023
work page 2023
-
[12]
Tan, M., R. Pang, Q. V . Le. Efficientdet: Scalable and efficient object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2020
work page 2020
-
[13]
Wang, C.-Y ., A. Bochkovskiy, H.-Y . M. Liao. Scaled-YOLOv4: Scaling cross stage partial network. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13029–13038. 2021
work page 2021
-
[14]
Wang, X., J. Lin, J. Zhao, et al. EAutoDet: Efficient architecture search for object detection. In Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XX, page 668–684. Springer-Verlag, Berlin, Heidelberg, 2022
work page 2022
-
[15]
Huang, G., D. Chen, T. Li, et al. Multi-scale dense networks for resource efficient image classification. InInternational Conference on Learning Representations (ICLR). 2018
work page 2018
-
[16]
Lin, Z., Y . Wang, J. Zhang, et al. DynamicDet: A unified dynamic architecture for object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2023
work page 2023
- [17]
-
[18]
Heo, S., S. Cho, Y . Kim, et al. Real-time object detection system with multi-path neural networks. In2020 IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), pages 174–187. 2020
work page 2020
-
[19]
Liu, S., S. Yao, X. Fu, et al. On removing algorithmic priority inversion from mission-critical machine inference pipelines. In2020 IEEE Real-Time Systems Symposium (RTSS), pages 319–332. 2020
work page 2020
-
[20]
Liu, S., X. Fu, M. Wigness, et al. Self-cueing real-time attention scheduling in criticality-aware visual machine perception. In2022 IEEE 28th Real-Time and Embedded Technology and Applications Symposium (RTAS), pages 173–186. 2022. 10
work page 2022
-
[21]
Kang, W. Qos-aware inference acceleration using adaptive depth neural networks.IEEE Access, 12:49329–49340, 2024
work page 2024
- [22]
-
[23]
Chen, G., W. Choi, X. Yu, et al. Learning efficient object detection models with knowledge dis- tillation. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 742–751. Curran Associates Inc., Red Hook, NY , USA, 2017
work page 2017
- [24]
- [25]
-
[26]
Yang, Z., Z. Li, X. Jiang, et al. Focal and global knowledge distillation for detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4643–4652. 2022
work page 2022
-
[27]
Jia, Z., S. Sun, G. Liu, et al. MSSD: multi-scale self-distillation for object detection.Visual Intelligence, 2(8), 2024
work page 2024
-
[28]
Zheng, Z., R. Ye, P. Wang, et al. Localization distillation for dense object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9407–9416. 2022
work page 2022
-
[29]
Wang, J., Y . Chen, Z. Zheng, et al. CrossKD: Cross-head knowledge distillation for object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16520–16530. 2024
work page 2024
-
[30]
Wang, Y ., X. Li, S. Weng, et al. Kd-detr: Knowledge distillation for detection transformer with consistent distillation points sampling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16016–16025. 2024
work page 2024
-
[31]
Kornblith, S., M. Norouzi, H. Lee, et al. Similarity of neural network representations revisited. In Proceedings of the 36th International Conference on Machine Learning, vol. 97 ofProceedings of Machine Learning Research, pages 3519–3529. PMLR, 2019
work page 2019
-
[32]
YOLOv4: Optimal Speed and Accuracy of Object Detection
Bochkovskiy, A., C.-Y . Wang, H.-Y . M. Liao. YOLOv4: Optimal speed and accuracy of object detection.arXiv preprint arXiv:2004.10934, 2020
work page internal anchor Pith review arXiv 2004
-
[33]
Wang, C.-Y ., A. Bochkovskiy, H.-Y . M. Liao. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7464–7475. 2023
work page 2023
-
[34]
Yolov9: Learning what you want to learn us- ing programmable gradient information
Wang, C.-Y ., I.-H. Yeh, H.-Y . M. Liao. YOLOv9: Learning what you want to learn using programmable gradient information.arXiv preprint arXiv:2402.13616, 2024
-
[35]
Wang, C.-Y ., H.-Y . Mark Liao, Y .-H. Wu, et al. CSPNet: A new backbone that can enhance learning capability of cnn. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 390–391. 2020
work page 2020
-
[36]
Distilling the Knowledge in a Neural Network
Hinton, G., O. Vinyals, J. Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[37]
Li, X., C. Lv, W. Wang, et al. Generalized focal loss: Towards efficient representation learning for dense object detection.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3139–3153, 2023
work page 2023
-
[38]
Kuhn, H. W. The hungarian method for the assignment problem.Naval Research Logistics Quarterly, 2(1-2):83–97, 1955
work page 1955
- [39]
-
[40]
Knowledge distillation in PaddleClas
PaddlePaddle. Knowledge distillation in PaddleClas. https://paddleclas.readthedocs. io/en/latest/advanced_tutorials/distillation/distillation_en.html, 2024. Accessed: 2026-05-04
work page 2024
-
[41]
Yalniz, I. Z., H. Jégou, K. Chen, et al. Billion-scale semi-supervised learning for image classification.arXiv preprint arXiv:1905.00646, 2019. 11 A Appendix: Detailed Settings, Analysis, and Evaluation Results A.1 Implementation Details Architecture Configuration.Table 4 summarizes the per-stage architecture of AnyDepth-DETR (R-50) and AnyDepth-YOLO (L),...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.