Recognition: no theorem link
SAMOFT: Robust Multi-Object Tracking via Region and Flow
Pith reviewed 2026-05-12 03:05 UTC · model grok-4.3
The pith
SAMOFT improves multi-object tracking by using pixel-level motion cues from the Segment Anything Model and optical flow to refine predictions under deformation and occlusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAMOFT demonstrates that integrating SAM-derived masks with dense optical flow inside a Pixel Motion Matching module, a Centroid Distance Matching module, a Distribution-Based Correction module, and a Cluster-Aware ReID strategy produces more robust trajectory association than instance-level baselines alone, yielding consistent gains on DanceTrack and MOTChallenge benchmarks.
What carries the argument
The Pixel Motion Matching module, which fuses Segment Anything Model masks with dense optical flow to compute instantaneous foreground pixel motion and correct Kalman filter state estimates.
If this is right
- Kalman filter motion predictions become more accurate without learning new motion models.
- Low-confidence detections can still contribute to trajectories via mask centroid distances.
- Historical flow statistics allow online correction of atypical motion without retraining.
- Appearance features gain stability through clustering-aware re-identification.
Where Pith is reading between the lines
- The same pixel-level correction idea could be grafted onto other association paradigms such as graph-based or transformer trackers.
- If optical flow quality is the limiting factor, swapping in newer flow estimators might produce further gains on the same benchmarks.
- The training-free distribution correction suggests that purely statistical motion models remain viable when paired with strong instantaneous cues.
Load-bearing premise
That the Segment Anything Model will produce usable foreground masks and that dense optical flow will supply accurate instantaneous motion even when objects deform, move nonlinearly, or are partially occluded.
What would settle it
Run SAMOFT on a sequence containing rapid nonlinear deformations and heavy occlusions where both SAM segmentation and optical flow visibly break down; if identity switches or track fragmentation exceed those of the unmodified baseline tracker, the pixel-cue benefit disappears.
Figures






read the original abstract
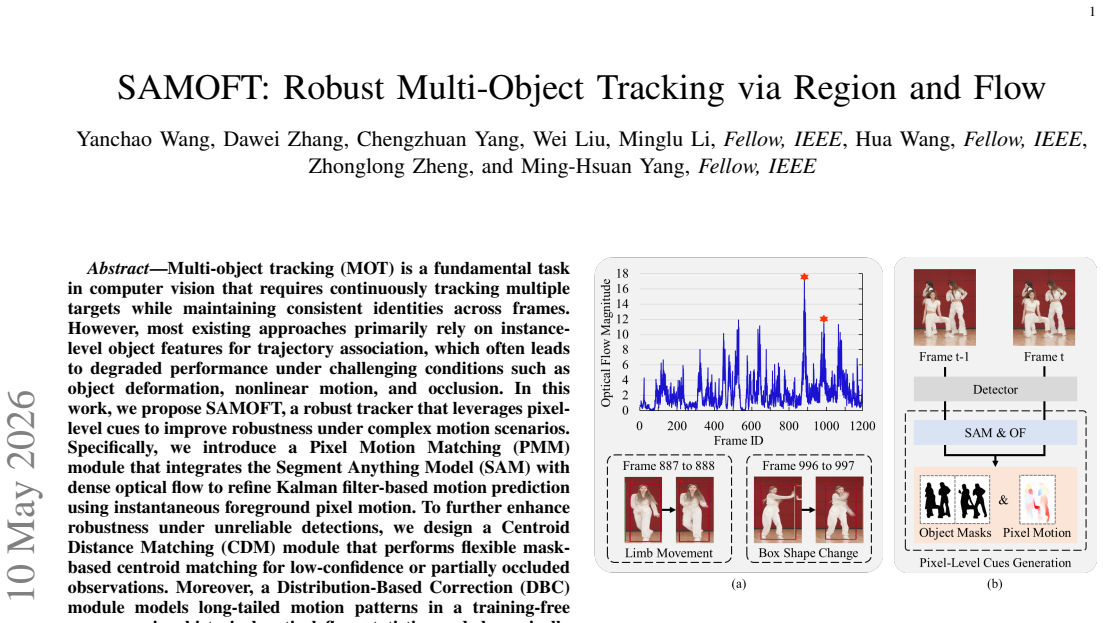
Multi-object tracking (MOT) is a fundamental task in computer vision that requires continuously tracking multiple targets while maintaining consistent identities across frames. However, most existing approaches primarily rely on instance-level object features for trajectory association, which often leads to degraded performance under challenging conditions such as object deformation, nonlinear motion, and occlusion. In this work, we propose SAMOFT, a robust tracker that leverages pixel-level cues to improve robustness under complex motion scenarios. Specifically, we introduce a Pixel Motion Matching (PMM) module that integrates the Segment Anything Model (SAM) with dense optical flow to refine Kalman filter-based motion prediction using instantaneous foreground pixel motion. To further enhance robustness under unreliable detections, we design a Centroid Distance Matching (CDM) module that performs flexible mask-based centroid matching for low-confidence or partially occluded observations. Moreover, a Distribution-Based Correction (DBC) module models long-tailed motion patterns in a training-free manner using historical optical flow statistics and dynamically corrects trajectory states online. We also incorporate a Cluster-Aware ReID (CA-ReID) strategy to improve the stability and discriminative power of trajectory appearance features. Extensive experiments on the DanceTrack and MOTChallenge benchmarks demonstrate that SAMOFT consistently improves baseline trackers and achieves competitive performance compared with recent state-of-the-art methods, validating the effectiveness of leveraging pixel-level cues for robust multi-object tracking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAMOFT, a multi-object tracker that augments Kalman-filter-based methods with pixel-level cues derived from the Segment Anything Model (SAM) and dense optical flow. It introduces a Pixel Motion Matching (PMM) module to refine motion predictions using instantaneous foreground pixel motion, a Centroid Distance Matching (CDM) module for mask-based centroid association under low-confidence or occluded detections, a Distribution-Based Correction (DBC) module that uses historical optical flow statistics to model and correct long-tailed motion patterns in a training-free manner, and a Cluster-Aware ReID (CA-ReID) strategy to enhance appearance feature stability. The central claim is that these components yield consistent improvements over baselines and competitive results against recent state-of-the-art methods on the DanceTrack and MOTChallenge benchmarks, validating the utility of pixel-level cues where instance-level features fail.
Significance. If the reported benchmark gains are supported by controlled ablations and the modules demonstrably address the targeted failure modes, the work would be significant for the MOT community. It provides a practical demonstration of integrating a foundation model (SAM) with classical motion models and flow without requiring retraining, and the training-free DBC component is a clear strength that could be adopted more broadly. The approach also offers a concrete path for hybrid region-and-flow trackers in deformation and occlusion scenarios.
major comments (2)
- [§3.1 and §3.2] §3.1 (PMM) and §3.2 (CDM): The central robustness claim rests on SAM producing reliable foreground masks and centroids under object deformation, nonlinear motion, and occlusion—the exact conditions the paper targets. No quantitative evaluation of SAM mask quality (e.g., IoU against ground-truth or failure rate on DanceTrack/MOTChallenge sequences) is provided, leaving open the possibility that observed gains derive primarily from the underlying SAM and flow models rather than the proposed matching logic.
- [§4] §4 Experiments: The abstract and results claim “consistent improvements” and “competitive performance,” yet the manuscript supplies no error bars, statistical significance tests, or per-sequence breakdowns. Without these, it is impossible to determine whether the reported deltas exceed typical tracker variance or are driven by a few easy sequences.
minor comments (3)
- [Figure 1] Figure 1 (overview): The diagram is too compressed; the flow arrows between PMM, CDM, and DBC are difficult to follow. Enlarging the figure and adding explicit labels for each data path would improve readability.
- [§3.3] Notation in §3.3 (DBC): The long-tailed distribution is described only qualitatively; a short equation or pseudocode showing how the historical flow histogram is maintained and used for online correction would remove ambiguity.
- [Related Work] Related work: Several recent MOT papers that also combine optical flow or mask cues (e.g., those building on RAFT or Mask2Former) are not cited, weakening the positioning of the novelty.
Simulated Author's Rebuttal
Thank you for your detailed and constructive review. We appreciate the feedback on strengthening the empirical validation of our modules. We address each major comment below.
read point-by-point responses
-
Referee: [§3.1 and §3.2] §3.1 (PMM) and §3.2 (CDM): The central robustness claim rests on SAM producing reliable foreground masks and centroids under object deformation, nonlinear motion, and occlusion—the exact conditions the paper targets. No quantitative evaluation of SAM mask quality (e.g., IoU against ground-truth or failure rate on DanceTrack/MOTChallenge sequences) is provided, leaving open the possibility that observed gains derive primarily from the underlying SAM and flow models rather than the proposed matching logic.
Authors: We acknowledge the value of direct quantitative validation of SAM mask quality. However, DanceTrack and MOTChallenge provide only bounding-box annotations and lack pixel-level ground-truth masks, precluding IoU computation without new annotations. Our ablation studies (Table 3) isolate the contribution of PMM and CDM by comparing against baselines that use identical SAM and flow inputs, showing consistent metric gains attributable to the matching logic rather than the foundation models alone. In revision we will add a qualitative analysis of mask reliability under deformation/occlusion together with selected failure cases. revision: partial
-
Referee: [§4] §4 Experiments: The abstract and results claim “consistent improvements” and “competitive performance,” yet the manuscript supplies no error bars, statistical significance tests, or per-sequence breakdowns. Without these, it is impossible to determine whether the reported deltas exceed typical tracker variance or are driven by a few easy sequences.
Authors: We agree that error bars, significance testing, and per-sequence breakdowns would increase rigor. In the revised manuscript we will report standard deviations (where stochasticity exists, e.g., ReID clustering), per-sequence MOTA/IDF1 on DanceTrack and MOT17, and paired t-tests confirming that the observed deltas are statistically significant and consistent across sequences rather than driven by outliers. revision: yes
- Quantitative IoU evaluation of SAM masks against ground truth cannot be performed because the standard MOT benchmarks supply only bounding-box annotations.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an applied MOT system that composes external pretrained components (SAM, dense optical flow, Kalman filter) with four processing modules whose outputs are defined by independent image-processing operations rather than by the final tracking metric. No equations, parameter fits, or self-citations are shown to reduce the claimed benchmark gains to the inputs by construction; the validation rests on controlled experiments and ablations on public datasets whose ground truth is external to the method. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SAM produces accurate pixel-level foreground masks suitable for motion matching
- domain assumption Dense optical flow provides instantaneous foreground pixel motion that improves Kalman predictions
Reference graph
Works this paper leans on
-
[1]
MOT16: A Benchmark for Multi-Object Tracking
A. Milan, L. Leal-Taix ´e, I. Reid, S. Roth, and K. Schindler, “Mot16: A benchmark for multi-object tracking,”arXiv preprint arXiv:1603.00831,
-
[2]
Dancetrack: Multi-object tracking in uniform appearance and diverse motion,
P. Sun, J. Cao, Y . Jiang, Z. Yuan, S. Bai, K. Kitani, and P. Luo, “Dancetrack: Multi-object tracking in uniform appearance and diverse motion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 20 993–21 002. 1, 2, 7
work page 2022
-
[3]
Simple online and realtime tracking,
A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, “Simple online and realtime tracking,” inIEEE International Conference on Image Processing, 2016, pp. 3464–3468. 1, 2
work page 2016
-
[4]
Observation- centric sort: Rethinking sort for robust multi-object tracking,
J. Cao, J. Pang, X. Weng, R. Khirodkar, and K. Kitani, “Observation- centric sort: Rethinking sort for robust multi-object tracking,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9686–9696. 1, 2, 3, 6, 7, 8
work page 2023
-
[5]
Hybrid-sort: Weak cues matter for online multi-object tracking,
M. Yang, G. Han, B. Yan, W. Zhang, J. Qi, H. Lu, and D. Wang, “Hybrid-sort: Weak cues matter for online multi-object tracking,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 7, 2024, pp. 6504–6512. 1, 3, 6, 7, 8
work page 2024
-
[6]
YOLOX: Exceeding YOLO Series in 2021
Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “Yolox: Exceeding yolo series in 2021,”arXiv preprint arXiv:2107.08430, 2021. 1, 2, 6
work page internal anchor Pith review arXiv 2021
-
[7]
Bytetrack: Multi-object tracking by associating every detection box,
Y . Zhang, P. Sun, Y . Jiang, D. Yu, F. Weng, Z. Yuan, P. Luo, W. Liu, and X. Wang, “Bytetrack: Multi-object tracking by associating every detection box,” inEuropean Conference on Computer Vision, 2022, pp. 1–21. 1, 2, 3, 5, 6, 7, 8, 9
work page 2022
-
[8]
Deep oc-sort: Multi- pedestrian tracking by adaptive re-identification,
G. Maggiolino, A. Ahmad, J. Cao, and K. Kitani, “Deep oc-sort: Multi- pedestrian tracking by adaptive re-identification,” inIEEE International Conference on Image Processing, 2023, pp. 3025–3029. 1, 3, 6, 7
work page 2023
-
[9]
Quo vadis: Is trajectory forecasting the key towards long-term multi-object track- ing?
P. Dendorfer, V . Yugay, A. Osep, and L. Leal-Taix ´e, “Quo vadis: Is trajectory forecasting the key towards long-term multi-object track- ing?”Advances in Neural Information Processing Systems, vol. 35, pp. 15 657–15 671, 2022. 1, 3
work page 2022
-
[10]
Thermal pedestrian multiple object tracking challenge (tp-mot),
W. El Ahmar, A. Sappa, and R. Hammoud, “Thermal pedestrian multiple object tracking challenge (tp-mot),” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 4602–4609. 1
work page 2025
-
[11]
Visible–thermal multiple object tracking: Large-scale video dataset and progressive fusion approach,
Y . Zhu, Q. Wang, C. Li, J. Tang, C. Gu, and Z. Huang, “Visible–thermal multiple object tracking: Large-scale video dataset and progressive fusion approach,”Pattern Recognition, vol. 161, p. 111330, 2025. 1
work page 2025
-
[12]
Multi-target multi- camera tracking by tracklet-to-target assignment,
Y . He, X. Wei, X. Hong, W. Shi, and Y . Gong, “Multi-target multi- camera tracking by tracklet-to-target assignment,”IEEE Transactions on Image Processing, vol. 29, pp. 5191–5205, 2020. 1
work page 2020
-
[13]
Omnidirectional multi-object tracking,
K. Luo, H. Shi, S. Wu, F. Teng, M. Duan, C. Huang, Y . Wang, K. Wang, and K. Yang, “Omnidirectional multi-object tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 21 959–21 969. 1
work page 2025
-
[14]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015–4026. 2, 3, 6
work page 2023
-
[15]
arXiv preprint arXiv:2003.09003 (2020)
P. Dendorfer, H. Rezatofighi, A. Milan, J. Shi, D. Cremers, I. Reid, S. Roth, K. Schindler, and L. Leal-Taix ´e, “Mot20: A bench- mark for multi object tracking in crowded scenes,”arXiv preprint arXiv:2003.09003, 2020. 2
-
[16]
Motr: End-to-end multiple-object tracking with transformer,
F. Zeng, B. Dong, Y . Zhang, T. Wang, X. Zhang, and Y . Wei, “Motr: End-to-end multiple-object tracking with transformer,” inEuropean Conference on Computer Vision, 2022, pp. 659–675. 2, 7, 8
work page 2022
-
[17]
Motrv2: Bootstrapping end-to-end multi-object tracking by pretrained object detectors,
Y . Zhang, T. Wang, and X. Zhang, “Motrv2: Bootstrapping end-to-end multi-object tracking by pretrained object detectors,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 056–22 065. 2, 7, 8
work page 2023
-
[18]
Inference-domain network evolution: A new perspective for one-shot multi-object tracking,
R. Li, B. Zhang, J. Liu, W. Liu, and Z. Teng, “Inference-domain network evolution: A new perspective for one-shot multi-object tracking,”IEEE Transactions on Image Processing, vol. 32, pp. 2147–2159, 2023. 2
work page 2023
-
[19]
Pro2diff: Proposal propagation for multi-object tracking via the diffusion model,
H. Liu, C. Zhang, B. Fan, and J. Xu, “Pro2diff: Proposal propagation for multi-object tracking via the diffusion model,”IEEE Transactions on Image Processing, vol. 33, pp. 6508–6520, 2024. 2
work page 2024
-
[20]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”Advances in Neural Information Processing Systems, vol. 28, 2015. 2
work page 2015
-
[21]
Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,
C.-Y . Wang, A. Bochkovskiy, and H.-Y . M. Liao, “Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7464–7475. 2
work page 2023
-
[22]
The hungarian method for the assignment problem,
H. W. Kuhn, “The hungarian method for the assignment problem,”Naval Research Logistics Quarterly, vol. 2, no. 1-2, pp. 83–97, 1955. 2
work page 1955
-
[23]
Contributions to the theory of optimal control,
R. E. Kalmanet al., “Contributions to the theory of optimal control,” Bol. Soc. Mat. Mexicana, vol. 5, no. 2, pp. 102–119, 1960. 3
work page 1960
-
[24]
Strong- sort: Make deepsort great again,
Y . Du, Z. Zhao, Y . Song, Y . Zhao, F. Su, T. Gong, and H. Meng, “Strong- sort: Make deepsort great again,”IEEE Transactions on Multimedia, vol. 25, pp. 8725–8737, 2023. 3, 7, 8
work page 2023
-
[25]
Conftrack: Kalman filter-based multi-person tracking by utilizing confidence score of detection box,
H. Jung, S. Kang, T. Kim, and H. Kim, “Conftrack: Kalman filter-based multi-person tracking by utilizing confidence score of detection box,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 6583–6592. 3
work page 2024
-
[26]
Bpmtrack: Multi-object tracking with detection box application pattern mining,
Y . Gao, H. Xu, J. Li, and X. Gao, “Bpmtrack: Multi-object tracking with detection box application pattern mining,”IEEE Transactions on Image Processing, vol. 33, pp. 1508–1521, 2024. 3
work page 2024
-
[27]
Sampling-resilient multi-object tracking,
Z. Li, D. Zhang, S. Wu, M. Song, and G. Chen, “Sampling-resilient multi-object tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 4, 2024, pp. 3297–3305. 3
work page 2024
-
[28]
ikun: Speak to trackers without retraining,
Y . Du, C. Lei, Z. Zhao, and F. Su, “ikun: Speak to trackers without retraining,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 135–19 144. 3
work page 2024
-
[29]
Diffmot: A real-time diffusion-based multiple object tracker with non-linear prediction,
W. Lv, Y . Huang, N. Zhang, R.-S. Lin, M. Han, and D. Zeng, “Diffmot: A real-time diffusion-based multiple object tracker with non-linear prediction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 321–19 330. 3, 7
work page 2024
-
[30]
Simple online and realtime track- ing with a deep association metric,
N. Wojke, A. Bewley, and D. Paulus, “Simple online and realtime track- ing with a deep association metric,” inIEEE International Conference on Image Processing, 2017, pp. 3645–3649. 3
work page 2017
-
[31]
Towards real-time multi-object tracking,
Z. Wang, L. Zheng, Y . Liu, Y . Li, and S. Wang, “Towards real-time multi-object tracking,” inEuropean Conference on Computer Vision, 2020, pp. 107–122. 3
work page 2020
-
[32]
Bot-sort: R obust associations multi-pedestrian tracking
N. Aharon, R. Orfaig, and B.-Z. Bobrovsky, “Bot-sort: Robust associa- tions multi-pedestrian tracking,”arXiv preprint arXiv:2206.14651, 2022. 3, 6 12
-
[33]
Simple cues lead to a strong multi-object tracker,
J. Seidenschwarz, G. Bras ´o, V . C. Serrano, I. Elezi, and L. Leal-Taix ´e, “Simple cues lead to a strong multi-object tracker,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 13 813–13 823. 3, 7, 8
work page 2023
-
[34]
Stat: Multi-object tracking based on spatio-temporal topological constraints,
J. Zhang, M. Wang, H. Jiang, X. Zhang, C. Yan, and D. Zeng, “Stat: Multi-object tracking based on spatio-temporal topological constraints,” IEEE Transactions on Multimedia, vol. 26, pp. 4445–4457, 2023. 3, 7, 8
work page 2023
-
[35]
X. Cao, Y . Zheng, Y . Yao, H. Qin, X. Cao, and S. Guo, “Topic: A parallel association paradigm for multi-object tracking under complex motions and diverse scenes,”IEEE Transactions on Image Processing, vol. 34, pp. 743–758, 2025. 3, 7, 8
work page 2025
-
[36]
Focusing on tracks for online multi-object tracking,
K. Shim, K. Ko, Y . Yang, and C. Kim, “Focusing on tracks for online multi-object tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 11 687–11 696. 3, 7
work page 2025
-
[37]
Deconfusetrack: Dealing with confusion for multi-object tracking,
C. Huang, S. Han, M. He, W. Zheng, and Y . Wei, “Deconfusetrack: Dealing with confusion for multi-object tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 290–19 299. 3, 7, 8
work page 2024
-
[38]
Sparsetrack: Multi- object tracking by performing scene decomposition based on pseudo- depth,
Z. Liu, X. Wang, C. Wang, W. Liu, and X. Bai, “Sparsetrack: Multi- object tracking by performing scene decomposition based on pseudo- depth,”IEEE Transactions on Circuits and Systems for Video Technol- ogy, vol. 35, no. 5, pp. 4870–4882, 2025. 3
work page 2025
-
[39]
Deep kalman filter with optical flow for multiple object tracking,
Y . Chen, D. Zhao, and H. Li, “Deep kalman filter with optical flow for multiple object tracking,” in2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), 2019, pp. 3036–3041. 3
work page 2019
-
[40]
Folt: Fast multiple object tracking from uav-captured videos based on optical flow,
M. Yao, J. Wang, J. Peng, M. Chi, and C. Liu, “Folt: Fast multiple object tracking from uav-captured videos based on optical flow,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 3375–3383. 3
work page 2023
-
[41]
Temporal coherent object flow for multi-object tracking,
Z. Song, R. Luo, L. Ma, Y . Tang, Y .-P. P. Chen, J. Yu, and W. Yang, “Temporal coherent object flow for multi-object tracking,” inProceed- ings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 7, 2025, pp. 6978–6986. 3, 7, 8
work page 2025
-
[42]
Mode-track: Robust multi-object tracking with motion decoupling in uav videos,
Z. Song, Y . Li, S. Zhou, W. Tang, and L. Wang, “Mode-track: Robust multi-object tracking with motion decoupling in uav videos,”IEEE Transactions on Multimedia, pp. 1–11, 2026. 3
work page 2026
-
[43]
Samu- rai: Motion-aware memory for training-free visual object tracking with sam 2,
C.-Y . Yang, H.-W. Huang, W. Chai, Z. Jiang, and J.-N. Hwang, “Samu- rai: Motion-aware memory for training-free visual object tracking with sam 2,”IEEE Transactions on Image Processing, vol. 35, pp. 970–982,
-
[44]
Matching anything by segmenting anything,
S. Li, L. Ke, M. Danelljan, L. Piccinelli, M. Segu, L. Van Gool, and F. Yu, “Matching anything by segmenting anything,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 963–18 973. 3
work page 2024
-
[45]
Sam2mot: A novel paradigm of multi-object tracking by segmentation,
J. Jiang, Z. Wang, M. Zhao, Y . Li, and D. Jiang, “Sam2mot: A novel paradigm of multi-object tracking by segmentation,”arXiv preprint arXiv:2504.04519, 2025. 3
-
[46]
Delving into the trajectory long-tail distribution for muti-object tracking,
S. Chen, E. Yu, J. Li, and W. Tao, “Delving into the trajectory long-tail distribution for muti-object tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 341–19 351. 3
work page 2024
-
[47]
Nettrack: Tracking highly dynamic objects with a net,
G. Zheng, S. Lin, H. Zuo, C. Fu, and J. Pan, “Nettrack: Tracking highly dynamic objects with a net,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 145–19 155. 3
work page 2024
-
[48]
Cotracker: It is better to track together,
N. Karaev, I. Rocco, B. Graham, N. Neverova, A. Vedaldi, and C. Rup- precht, “Cotracker: It is better to track together,” inEuropean Conference on Computer Vision, 2024, pp. 18–35. 3
work page 2024
-
[49]
Sea-raft: Simple, efficient, accurate raft for optical flow,
Y . Wang, L. Lipson, and J. Deng, “Sea-raft: Simple, efficient, accurate raft for optical flow,” inEuropean Conference on Computer Vision, 2024, pp. 36–54. 3, 6
work page 2024
-
[50]
Hota: A higher order metric for evaluating multi-object tracking,
J. Luiten, A. Osep, P. Dendorfer, P. Torr, A. Geiger, L. Leal-Taix ´e, and B. Leibe, “Hota: A higher order metric for evaluating multi-object tracking,”International Journal of Computer Vision, vol. 129, no. 2, pp. 548–578, 2021. 6
work page 2021
-
[51]
Performance measures and a data set for multi-target, multi-camera tracking,
E. Ristani, F. Solera, R. Zou, R. Cucchiara, and C. Tomasi, “Performance measures and a data set for multi-target, multi-camera tracking,” in European Conference on Computer Vision, 2016, pp. 17–35. 6
work page 2016
-
[52]
Evaluating multiple object tracking performance: The clear mot metrics,
K. Bernardin and R. Stiefelhagen, “Evaluating multiple object tracking performance: The clear mot metrics,”EURASIP Journal on Image and Video Processing, vol. 2008, no. 1, p. 246309, 2008. 6
work page 2008
-
[53]
X. Zhou, T. Yin, V . Koltun, and P. Kr ¨ahenb¨uhl, “Global tracking transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8771–8780. 7, 8
work page 2022
-
[54]
Unifying short and long- term tracking with graph hierarchies,
O. Cetintas, G. Bras ´o, and L. Leal-Taix ´e, “Unifying short and long- term tracking with graph hierarchies,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 877–22 887. 7, 8
work page 2023
-
[55]
Diffusiontrack: Diffusion model for multi-object tracking,
R. Luo, Z. Song, L. Ma, J. Wei, W. Yang, and M. Yang, “Diffusiontrack: Diffusion model for multi-object tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 5, 2024, pp. 3991–
work page 2024
-
[56]
Multiple object tracking as id prediction,
R. Gao, J. Qi, and L. Wang, “Multiple object tracking as id prediction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 27 883–27 893. 7, 8
work page 2025
-
[57]
Focus on details: Online multi-object tracking with diverse fine-grained repre- sentation,
H. Ren, S. Han, H. Ding, Z. Zhang, H. Wang, and F. Wang, “Focus on details: Online multi-object tracking with diverse fine-grained repre- sentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 11 289–11 298. 7
work page 2023
-
[58]
Ahor: Online multi- object tracking with authenticity hierarchizing and occlusion recovery,
H. Jin, X. Nie, Y . Yan, X. Chen, Z. Zhu, and D. Qi, “Ahor: Online multi- object tracking with authenticity hierarchizing and occlusion recovery,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 9, pp. 8253–8265, 2024. 7
work page 2024
-
[59]
A confidence-aware matching strategy for generalized multi-object tracking,
K. Shim, J. Hwang, K. Ko, and C. Kim, “A confidence-aware matching strategy for generalized multi-object tracking,” inIEEE International Conference on Image Processing, 2024, pp. 4042–4048. 7
work page 2024
-
[60]
Towards generalizable multi-object tracking,
Z. Qin, L. Wang, S. Zhou, P. Fu, G. Hua, and W. Tang, “Towards generalizable multi-object tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 995–19 004. 7, 8
work page 2024
-
[61]
Ucmc- track: Multi-object tracking with uniform camera motion compensation,
K. Yi, K. Luo, X. Luo, J. Huang, H. Wu, R. Hu, and W. Hao, “Ucmc- track: Multi-object tracking with uniform camera motion compensation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 7, 2024, pp. 6702–6710. 7
work page 2024
-
[62]
Y . Gao, H. Xu, J. Li, N. Wang, and X. Gao, “Multi-scene generalized trajectory global graph solver with composite nodes for multiple object tracking,” inProceedings of the AAAI Conference on Artificial Intelli- gence, vol. 38, no. 3, 2024, pp. 1842–1850. 7
work page 2024
-
[63]
Dftrack: Deconfused data association framework for multi-object tracking,
C. Huang, S. Han, M. He, W. Zheng, and Y . Wei, “Dftrack: Deconfused data association framework for multi-object tracking,”IEEE Transac- tions on Circuits and Systems for Video Technology, vol. 35, no. 10, pp. 10 367–10 381, 2025. 7
work page 2025
-
[64]
Smiletrack: Similarity learning for occlusion-aware multiple object tracking,
Y .-H. Wang, J.-W. Hsieh, P.-Y . Chen, M.-C. Chang, H.-H. So, and X. Li, “Smiletrack: Similarity learning for occlusion-aware multiple object tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 6, 2024, pp. 5740–5748. 8
work page 2024
-
[65]
Tgformer: Transformer with track query group for multi-object tracking,
R. Zeng, Y . Huang, and S. Pei, “Tgformer: Transformer with track query group for multi-object tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9824–9832. 8
work page 2025
-
[66]
Foundation model driven ap- pearance extraction for robust multiple object tracking,
T. Fu, H. Yu, K. Niu, B. Li, and X. Xue, “Foundation model driven ap- pearance extraction for robust multiple object tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 3, 2025, pp. 3031–3039. 8
work page 2025
-
[67]
La-motr: End-to- end multi-object tracking by learnable association,
P. Wang, Y . Wang, H. Cao, W. Chen, and D. Li, “La-motr: End-to- end multi-object tracking by learnable association,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 12 438–12 448. 8
work page 2025
-
[68]
Motiontrack: Learning robust short-term and long-term motions for multi-object tracking,
Z. Qin, S. Zhou, L. Wang, J. Duan, G. Hua, and W. Tang, “Motiontrack: Learning robust short-term and long-term motions for multi-object tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 939–17 948. 7, 8
work page 2023
-
[69]
Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo,
L. Mehl, J. Schmalfuss, A. Jahedi, Y . Nalivayko, and A. Bruhn, “Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4981–4991. 6
work page 2023
-
[70]
Large scale real-world multi-person tracking,
B. Shuai, A. Bergamo, U. Buechler, A. Berneshawi, A. Boden, and J. Tighe, “Large scale real-world multi-person tracking,” inEuropean Conference on Computer Vision, 2022, pp. 504–521. 7
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.