Recognition: 2 theorem links
· Lean TheoremScaleGANN: Accelerate Large-Scale ANN Indexing by Cost-effective Cloud GPUs
Pith reviewed 2026-05-12 04:49 UTC · model grok-4.3
The pith
A cloud-based system accelerates the construction of graph indexes for large-scale approximate nearest neighbor search by up to nine times while reducing costs by a factor of six through the use of inexpensive spot GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ScaleGANN constructs graph indexes for large high-dimensional datasets by splitting vectors into partitions, indexing each on separate spot GPUs in parallel, merging the results, and managing resources with a cost-aware scheduler, achieving up to 9x faster builds at 6x lower price than state-of-the-art methods while keeping index quality intact.
What carries the argument
The divide-and-merge strategy with optimized vector partitioning, which allows parallel GPU processing without compromising the final index's recall or search efficiency.
If this is right
- Index construction for datasets too large for single machines becomes practical on cloud infrastructure.
- Total expenses for setting up ANNS systems drop substantially, making them accessible to more users.
- Build times decrease enough to support more frequent updates to indexes as data changes.
Where Pith is reading between the lines
- Other types of indexes or machine learning models might benefit from similar data partitioning on variable cloud resources.
- Cloud providers could use the cost model to optimize pricing for GPU spot instances in data processing workloads.
Load-bearing premise
The assumption that partitioning the vectors optimally maintains the same level of index quality as building the index on the complete dataset at once.
What would settle it
If testing reveals that the merged indexes from partitioned builds have significantly worse recall or slower query times than full builds, or if the effective cost exceeds the claimed savings, the main results would not hold.
Figures




read the original abstract
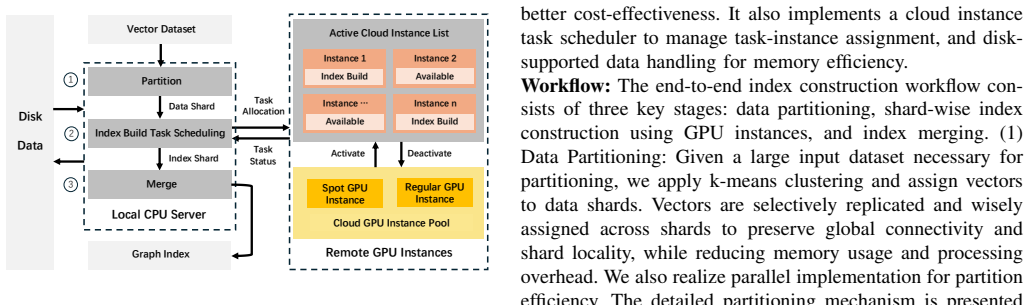
Graph-based ANNS algorithms have gained increasing research interest and market adoption due to their efficiency and accuracy in retrieval. Existing approaches primarily rely on CPUs for graph index construction and retrieval, but this often requires significant time, especially for large-scale and high-dimensional datasets. Some studies have explored GPU-based solutions. However, GPUs are costly and their limited memory makes handling large datasets challenging. In this paper, we propose a novel end-to-end system ScaleGANN that enables users to efficiently construct graph indexes for large-scale, high-dimensional datasets by leveraging low-cost spot GPU resources in a distributed cloud system. ScaleGANN utilized the idea of divide-and-merge, with an optimized vector partitioning algorithm to further improve the indexing time and space efficiency while guaranteeing good index quality. Its novel resource allocation strategy realized multi-GPU indexing parallelism and overall cost-effectiveness for both build and query. Besides, we designed a task scheduler and cost model for better spot instance management and evaluation. We tested our system on large real-world datasets. Experiment results show that our approach can significantly accelerate the index build time to up to 9x times at even 6x lower price compared with the state-of-the-art extendable ANNS benchmark DiskANN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ScaleGANN, a system for constructing graph-based ANNS indexes on large-scale high-dimensional datasets by leveraging low-cost spot GPU instances via a divide-and-merge strategy with an optimized vector partitioning algorithm. The system incorporates multi-GPU resource allocation, task scheduling, and a cost model for spot-instance management. Experiments on real-world datasets claim up to 9x faster index build time at 6x lower cost versus the DiskANN benchmark while preserving index quality.
Significance. If the quality-preservation claim holds, the work offers a practical route to cost-effective large-scale ANNS indexing by exploiting commodity cloud spot resources, which could broaden adoption in retrieval and recommendation systems. The emphasis on distributed GPU parallelism and spot-instance handling addresses deployment realities not fully covered by prior CPU- or single-GPU ANNS constructions.
major comments (2)
- Abstract: the assertion that the optimized vector partitioning 'guarantees good index quality' is load-bearing for the 9x/6x claims, yet no quantitative evidence (recall@K, query latency, or graph-connectivity metrics) is supplied comparing the merged index to a monolithic full-dataset build. Without such data the speedup cannot be interpreted as apples-to-apples versus DiskANN.
- Results / Experimental Evaluation: the reported speedups and cost figures lack error bars, number of trials, exact dataset cardinalities and dimensionalities, and explicit controls for spot-instance preemption overhead. These omissions prevent verification that the observed gains are robust and not artifacts of particular runs or unaccounted management costs.
minor comments (1)
- Abstract: the phrase 'large real-world datasets' should be accompanied by concrete names, sizes, and dimensions to allow readers to assess the scale at which the 9x/6x gains were measured.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit quality comparisons and improved experimental reporting. We address each major comment below and will incorporate revisions to strengthen the claims and reproducibility of the manuscript.
read point-by-point responses
-
Referee: Abstract: the assertion that the optimized vector partitioning 'guarantees good index quality' is load-bearing for the 9x/6x claims, yet no quantitative evidence (recall@K, query latency, or graph-connectivity metrics) is supplied comparing the merged index to a monolithic full-dataset build. Without such data the speedup cannot be interpreted as apples-to-apples versus DiskANN.
Authors: We agree that the abstract phrasing is too strong without direct supporting data and that an explicit apples-to-apples comparison is required. The full manuscript (Section 5.3) already reports recall@10, query latency, and index quality metrics for the merged indexes on SIFT1M, GloVe, and DEEP1B datasets, showing the divide-and-merge results stay within 1-3% of monolithic DiskANN quality. However, these are not presented as a head-to-head table against a full-dataset build. We will add a new subsection (5.4) with a direct comparison table including recall@K, query latency, average graph degree, and clustering coefficient for both merged and monolithic indexes. We will also revise the abstract to state that the partitioning 'preserves index quality within 3% of monolithic builds' with a reference to the new table rather than using 'guarantees'. revision: yes
-
Referee: Results / Experimental Evaluation: the reported speedups and cost figures lack error bars, number of trials, exact dataset cardinalities and dimensionalities, and explicit controls for spot-instance preemption overhead. These omissions prevent verification that the observed gains are robust and not artifacts of particular runs or unaccounted management costs.
Authors: We acknowledge these reporting gaps reduce verifiability. The manuscript uses standard datasets (SIFT1M: 1M vectors, 128 dimensions; GloVe: 1.2M vectors, 300 dimensions; DEEP1B: 10M vectors, 96 dimensions) but does not tabulate them explicitly or report variance. We will add a dataset summary table with exact cardinalities and dimensions. We will re-run the key experiments (build time and cost) for 5 independent trials per configuration, include error bars (standard deviation) in all speedup and cost figures, and add a dedicated paragraph in Section 5.2 describing the cost-aware scheduler's preemption handling, measured overhead (under 5% of total build time in our traces), and how preempted tasks are rescheduled without full restarts. These changes will be included in the revised experimental evaluation. revision: yes
Circularity Check
No circularity: empirical systems paper with external benchmarks
full rationale
The paper describes a distributed GPU system for graph-based ANNS index construction using divide-and-merge partitioning. All central claims (9x build speedup, 6x cost reduction vs. DiskANN) rest on direct experimental measurements of wall-clock time, monetary cost, recall@K, and query latency on real-world datasets. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing theorems appear in the provided text. Quality preservation is asserted as an experimental outcome rather than a definitional or self-referential result. The work is therefore self-contained against external baselines and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- vector partitioning parameters
axioms (1)
- domain assumption Spot GPU instances can be reliably acquired and managed for parallel indexing tasks without excessive preemption
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ScaleGANN utilized the idea of divide-and-merge, with an optimized vector partitioning algorithm... up to 9x times at even 6x lower price compared with... DiskANN
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
selective replication strategy... tunable threshold... distance constraint d' < ϵ·d
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Query by image and video content: The qbic system,
M. Flickner, H. Sawhney, W. Niblack, J. Ashleyet al., “Query by image and video content: The qbic system,”computer, vol. 28, no. 9, pp. 23– 32, 1995
work page 1995
-
[2]
arXiv preprint arXiv:2101.12631 , title =
M. Wang, X. Xu, Q. Yue, and Y . Wang, “A comprehensive survey and experimental comparison of graph-based approximate nearest neighbor search,”arXiv preprint arXiv:2101.12631, 2021
-
[3]
Nearest neighbor pattern classification,
T. Cover and P. Hart, “Nearest neighbor pattern classification,”IEEE transactions on information theory, vol. 13, no. 1, pp. 21–27, 1967
work page 1967
-
[4]
Approximate nearest neighbor search on high dimensional data—experiments, analyses, and improvement,
W. Li, Y . Zhang, Y . Sun, W. Wanget al., “Approximate nearest neighbor search on high dimensional data—experiments, analyses, and improvement,”IEEE Transactions on Knowledge and Data Engineering, vol. 32, no. 8, pp. 1475–1488, 2019
work page 2019
-
[5]
Deep neural networks for youtube recommendations,
P. Covington, J. Adams, and E. Sargin, “Deep neural networks for youtube recommendations,” inProceedings of the 10th ACM conference on recommender systems, 2016, pp. 191–198
work page 2016
-
[6]
Approximate nearest neighbor search under neural similarity metric for large-scale recommendation,
R. Chen, B. Liu, H. Zhu, Y . Wanget al., “Approximate nearest neighbor search under neural similarity metric for large-scale recommendation,” in Proceedings of the 31st ACM International Conference on Information & Knowledge Management, 2022, pp. 3013–3022
work page 2022
-
[7]
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval, December 2024
D. Liu, M. Chen, B. Lu, H. Jianget al., “Retrievalattention: Accel- erating long-context llm inference via vector retrieval,”arXiv preprint arXiv:2409.10516, 2024
-
[8]
N. Li, B. Kang, and T. De Bie, “Skillgpt: a restful api service for skill extraction and standardization using a large language model,”arXiv preprint arXiv:2304.11060, 2023
-
[9]
Fast approximate nearest neighbor search with the navigating spreading-out graph,
C. Fu, C. Xiang, C. Wang, and D. Cai, “Fast approximate nearest neighbor search with the navigating spreading-out graph,”arXiv preprint arXiv:1707.00143, 2017
-
[10]
Y . A. Malkov and D. A. Yashunin, “Efficient and robust approxi- mate nearest neighbor search using hierarchical navigable small world graphs,”IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 4, pp. 824–836, 2018
work page 2018
-
[11]
Cagra: Highly parallel graph construction and approximate nearest neighbor search for gpus,
H. Ootomo, A. Naruse, C. Nolet, R. Wanget al., “Cagra: Highly parallel graph construction and approximate nearest neighbor search for gpus,” in 2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 2024, pp. 4236–4247
work page 2024
-
[12]
Approximate nearest neighbor algorithm based on navigable small world graphs,
Y . Malkov, A. Ponomarenko, A. Logvinov, and V . Krylov, “Approximate nearest neighbor algorithm based on navigable small world graphs,” Information Systems, vol. 45, pp. 61–68, 2014
work page 2014
-
[13]
J. Arthurs, S. Drakopoulou, and A. Gandini, “Researching youtube,” pp. 3–15, 2018
work page 2018
-
[14]
Laion-5b: An open large-scale dataset for training next generation image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordonet al., “Laion-5b: An open large-scale dataset for training next generation image-text models,” Advances in neural information processing systems, vol. 35, pp. 25 278– 25 294, 2022
work page 2022
-
[16]
Diskann: Fast accurate billion-point nearest neighbor search on a single node,
S. Jayaram Subramanya, F. Devvrit, H. V . Simhadri, R. Krishnawamy et al., “Diskann: Fast accurate billion-point nearest neighbor search on a single node,”Advances in neural information processing Systems, vol. 32, 2019
work page 2019
-
[17]
M. Wang, W. Xu, X. Yi, S. Wuet al., “Starling: An i/o-efficient disk- resident graph index framework for high-dimensional vector similarity search on data segment,”Proceedings of the ACM on Management of Data, vol. 2, no. 1, pp. 1–27, 2024
work page 2024
-
[18]
CVPR. (2023) Cvpr 2023 tutorial. [Online]. Available: https://matsui528.github.io/cvpr2023 tutorial neural search/ assets/pdf/billion scale ann.pdf
work page 2023
-
[19]
Ggnn: Graph- based gpu nearest neighbor search,
F. Groh, L. Ruppert, P. Wieschollek, and H. P. Lensch, “Ggnn: Graph- based gpu nearest neighbor search,”IEEE Transactions on Big Data, vol. 9, no. 1, pp. 267–279, 2022
work page 2022
-
[20]
Song: Approximate nearest neighbor search on gpu,
W. Zhao, S. Tan, and P. Li, “Song: Approximate nearest neighbor search on gpu,” in2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 2020, pp. 1033–1044
work page 2020
-
[21]
Gpu-accelerated proximity graph approximate nearest neighbor search and construction,
Y . Yu, D. Wen, Y . Zhang, L. Qinet al., “Gpu-accelerated proximity graph approximate nearest neighbor search and construction,” in2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2022, pp. 552–564
work page 2022
-
[22]
(2024) Amazon ec2 spot instances
AWS. (2024) Amazon ec2 spot instances. [Online]. Available: https://aws.amazon.com/cn/ec2/spot/
work page 2024
-
[23]
A. Cloud. (2025) Alibaba cloud elastic compute service. [On- line]. Available: https://www.alibabacloud.com/help/en/ecs/user-guide/ what-is-a-spot-instance
work page 2025
-
[24]
Memanns: Enhancing billion-scale anns efficiency with practical pim hardware,
S. Chen, A. C. Zhou, Y . Shi, Y . Li, and X. Yao, “Memanns: Enhancing billion-scale anns efficiency with practical pim hardware,”arXiv preprint arXiv:2410.23805, 2024
-
[25]
Spotserve: Serving generative large language models on preemptible instances,
X. Miao, C. Shi, J. Duan, X. Xiet al., “Spotserve: Serving generative large language models on preemptible instances,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2024, pp. 1112–1127
work page 2024
-
[26]
M. Douze, A. Guzhva, C. Deng, J. Johnsonet al., “The faiss library,” arXiv preprint arXiv:2401.08281, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
A survey on nearest neighbor search methods,
M. R. Abbasifard, B. Ghahremani, and H. Naderi, “A survey on nearest neighbor search methods,”International Journal of Computer Applications, vol. 95, no. 25, 2014
work page 2014
-
[28]
An investigation of practical approximate nearest neighbor algorithms,
T. Liu, A. Moore, K. Yang, and A. Gray, “An investigation of practical approximate nearest neighbor algorithms,”Advances in neural informa- tion processing systems, vol. 17, 2004
work page 2004
-
[29]
EFANNA : An Extremely Fast Approximate Nearest Neighbor Search Algorithm Based on kNN Graph
C. Fu and D. Cai, “Efanna: An extremely fast approximate near- est neighbor search algorithm based on knn graph,”arXiv preprint arXiv:1609.07228, 2016
work page Pith review arXiv 2016
-
[30]
Fast approx- imate nearest-neighbor search with k-nearest neighbor graph,
K. Hajebi, Y . Abbasi-Yadkori, H. Shahbazi, and H. Zhang, “Fast approx- imate nearest-neighbor search with k-nearest neighbor graph,” inIJCAI Proceedings-International Joint Conference on Artificial Intelligence, vol. 22, no. 1, 2011, p. 1312
work page 2011
-
[31]
(2024) Use azure spot virtual machines
Azure. (2024) Use azure spot virtual machines. [Online]. Available: https://learn.microsoft.com/en-us/azure/virtual-machines/spot-vms
work page 2024
- [32]
- [33]
-
[34]
“Laion5b data,” https://the-eye.eu/public/AI/cah/laion5b/embeddings/ laion1B-nolang/img emb/
- [35]
-
[36]
(2025) Scalegann anonymous code repo
Anonymous. (2025) Scalegann anonymous code repo. [Online]. Available: https://github.com/AnonymousAuthor1111/ICDCS26
work page 2025
-
[37]
Lm-diskann: Low memory footprint in disk- native dynamic graph-based ann indexing,
Y . Pan, J. Sun, and H. Yu, “Lm-diskann: Low memory footprint in disk- native dynamic graph-based ann indexing,” in2023 IEEE International Conference on Big Data (BigData). IEEE, 2023, pp. 5987–5996
work page 2023
-
[38]
Aisaq: All- in-storage anns with product quantization for dram-free information retrieval,
K. Tatsuno, D. Miyashita, T. Ikeda, K. Ishiyamaet al., “Aisaq: All- in-storage anns with product quantization for dram-free information retrieval,”arXiv preprint arXiv:2404.06004, 2024
-
[39]
Spann: Highly-efficient billion-scale approximate nearest neighborhood search,
Q. Chen, B. Zhao, H. Wang, M. Liet al., “Spann: Highly-efficient billion-scale approximate nearest neighborhood search,”Advances in Neural Information Processing Systems, vol. 34, pp. 5199–5212, 2021
work page 2021
-
[40]
B. Tian, H. Liu, Y . Tang, S. Xiaoet al., “Towards high-throughput and low-latency billion-scale vector search via cpu/gpu collaborative filtering and re-ranking,” inFAST ’25: Proceedings of the 23rd USENIX Conference on File and Storage Technologies, 2025, pp. 171–185
work page 2025
-
[41]
Hm-ann: Efficient billion-point nearest neighbor search on heterogeneous memory,
J. Ren, M. Zhang, and D. Li, “Hm-ann: Efficient billion-point nearest neighbor search on heterogeneous memory,”Advances in Neural Infor- mation Processing Systems, vol. 33, pp. 10 672–10 684, 2020
work page 2020
-
[42]
J. Jang, H. Choi, H. Bae, S. Leeet al., “{CXL-ANNS}:{Software- Hardware}collaborative memory disaggregation and computation for {Billion-Scale}approximate nearest neighbor search,” in2023 USENIX Annual Technical Conference (USENIX ATC 23), 2023, pp. 585–600
work page 2023
-
[43]
Scalable billion-point approximate nearest neighbor search using{SmartSSDs},
B. Tian, H. Liu, Z. Duan, X. Liaoet al., “Scalable billion-point approximate nearest neighbor search using{SmartSSDs},” in2024 USENIX Annual Technical Conference (USENIX ATC 24), 2024, pp. 1135–1150
work page 2024
-
[44]
Shredder: Gpu- accelerated incremental storage and computation,
P. Bhatotia, R. Rodrigues, and A. Verma, “Shredder: Gpu- accelerated incremental storage and computation,” in10th USENIX Conference on File and Storage Technologies (FAST 12). San Jose, CA: USENIX Association, feb
-
[45]
[Online]. Available: https://www.usenix.org/conference/fast12/ shredder-gpu-accelerated-incremental-storage-and-computation
-
[46]
Seraph: Towards scalable and efficient fully-external graph computation via on- demand processing,
T.-Y . Yang, Y . Chen, Y . Liang, and M.-C. Yang, “Seraph: Towards scalable and efficient fully-external graph computation via on- demand processing,” in22nd USENIX Conference on File and Storage Technologies (FAST 24). Santa Clara, CA: USENIX Association, feb 2024, pp. 373–387. [Online]. Available: https: //www.usenix.org/conference/fast24/presentation/y...
work page 2024
-
[47]
Accelerating graph indexing for anns on modern cpus,
M. Wang, H. Wu, X. Ke, Y . Gaoet al., “Accelerating graph indexing for anns on modern cpus,”arXiv preprint arXiv:2502.18113, 2025
-
[48]
Y . Shi, Y . Sun, J. Du, X. Zhonget al., “Scalable overload-aware graph- based index construction for 10-billion-scale vector similarity search,” arXiv preprint arXiv:2502.20695, 2025
-
[49]
Spfresh: Incremental in-place update for billion-scale vector search,
Y . Xu, H. Liang, J. Li, S. Xuet al., “Spfresh: Incremental in-place update for billion-scale vector search,” inProceedings of the 29th Symposium on Operating Systems Principles, 2023, pp. 545–561
work page 2023
-
[50]
Bernstein, Badrish Chan- dramouli, Richard Wen, and Harsha Vardhan Simhadri
H. Xu, M. D. Manohar, P. A. Bernstein, B. Chandramouliet al., “In-place updates of a graph index for streaming approximate nearest neighbor search,”arXiv preprint arXiv:2502.13826, 2025
-
[51]
Freshdiskann: A fast and accurate graph-based ann index for streaming similarity search,
A. Singh, S. J. Subramanya, R. Krishnaswamy, and H. V . Simhadri, “Freshdiskann: A fast and accurate graph-based ann index for streaming similarity search,”arXiv preprint arXiv:2105.09613, 2021
-
[52]
Parcae: Proactive,{Liveput- Optimized}{DNN}training on preemptible instances,
J. Duan, Z. Song, X. Miao, X. Xiet al., “Parcae: Proactive,{Liveput- Optimized}{DNN}training on preemptible instances,” in21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), 2024, pp. 1121–1139
work page 2024
-
[53]
See spot run: Using spot instances for{MapReduce}workflows,
N. Chohan, C. Castillo, M. Spreitzer, M. Steinderet al., “See spot run: Using spot instances for{MapReduce}workflows,” in2nd USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 10), 2010
work page 2010
-
[54]
Spotmpi: A framework for auction-based hpc computing using amazon spot instances,
M. Taifi, J. Y . Shi, and A. Khreishah, “Spotmpi: A framework for auction-based hpc computing using amazon spot instances,” inIn- ternational Conference on Algorithms and Architectures for Parallel Processing. Springer, 2011, pp. 109–120
work page 2011
-
[55]
Skyserve: Serving ai models across regions and clouds with spot instances,
Z. Mao, T. Xia, Z. Wu, W.-L. Chianget al., “Skyserve: Serving ai models across regions and clouds with spot instances,” inProceedings of the Twentieth European Conference on Computer Systems, 2025, pp. 159–175
work page 2025
-
[56]
Aws ec2 spot instances for mission critical services,
J. Danysz, V . Del Rosal, and H. Gonz ´alez-V´elez, “Aws ec2 spot instances for mission critical services,” inProceedings of the 34th ECMS International Conference on Modelling and Simulation (ECMS 2020). European Council for Modeling and Simulation, 2020
work page 2020
-
[57]
C. Wang, Q. Liang, and B. Urgaonkar, “An empirical analysis of amazon ec2 spot instance features affecting cost-effective resource procurement,” ACM Transactions on Modeling and Performance Evaluation of Com- puting Systems (TOMPECS), vol. 3, no. 2, pp. 1–24, 2018
work page 2018
-
[58]
Making cloud spot instance interruption events visible,
K. Kim and K. Lee, “Making cloud spot instance interruption events visible,” inProceedings of the ACM Web Conference 2024, 2024, pp. 2998–3009
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.