Recognition: no theorem link
Stable Long-Horizon PDE Forecasting via Latent Structured Spectral Propagators
Pith reviewed 2026-05-12 03:19 UTC · model grok-4.3
The pith
Reformulating PDE rollout as evolution of structured spectral modes in a compact latent space produces stable long-horizon forecasts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
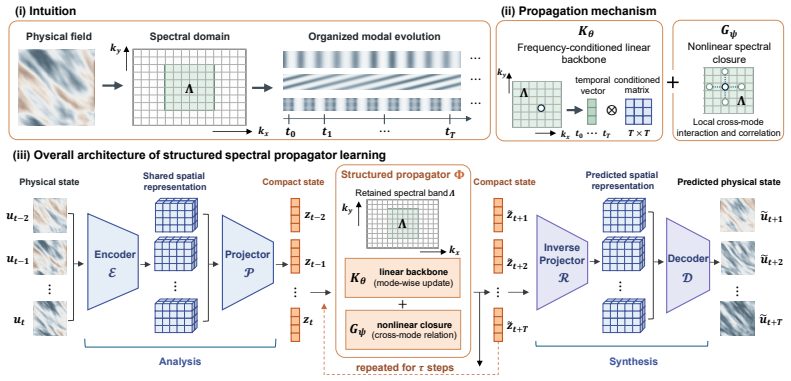
The central claim is that PDE forecasting can be recast as learning a Structured Spectral Propagator inside a propagation-oriented latent space. Following an analysis-propagation-synthesis pipeline, the method maps physical states into a time-consistent spatial representation, projects this into a compact state that isolates recurrent dynamics from fine spatial details, and evolves the retained spectral modes with a frequency-conditioned linear operator augmented by a nonlinear spectral closure that accounts for truncated interactions. The resulting explicit inductive bias for coherent modal evolution yields lower relative L2 errors and greater stability when the model is deployed autorecess
What carries the argument
The Structured Spectral Propagator, a latent-space mechanism that projects PDE states into a compact representation and evolves only its spectral modes via a frequency-conditioned linear backbone plus nonlinear closure.
If this is right
- Relative L2 errors drop by as much as 48.9 percent relative to current state-of-the-art neural operators.
- Forecasts remain stable when extrapolated well beyond the length of the training trajectories.
- The separation of reconstruction fidelity from rollout regularity prevents rapid dynamic drift.
- Explicit spectral structuring supplies an inductive bias that favors physically coherent modal evolution.
Where Pith is reading between the lines
- The same latent spectral structure could be applied to other time-evolving systems whose governing equations are not strictly PDEs, such as discretized agent-based models.
- If the nonlinear closure term proves sufficient, the framework may reduce the need for full-resolution spatial supervision during training.
- Hybrid models that occasionally inject fine-scale details back into the latent state might further extend the stable horizon on chaotic PDEs.
Load-bearing premise
That the projection into a compact propagation state successfully isolates recurrent dynamics from fine-grained spatial details without discarding information essential for long-term coherent evolution.
What would settle it
On standard benchmarks such as the Navier-Stokes equations, measure whether the relative L2 error of SSP rollouts after twice the supervised horizon exceeds the error of baseline neural operators under identical autoregressive deployment.
Figures


read the original abstract
Long-horizon forecasting of time-dependent partial differential equations (PDEs) is critical for characterizing the sustained evolution of physical systems. While neural operators have emerged as efficient surrogates, they typically learn implicit finite-time transitions from discrete observations. When deployed autoregressively, such propagators often suffer from rapid error accumulation and dynamic drift. To address this, we propose a neural forecasting framework that reformulates PDE rollout as learning a Structured Spectral Propagator (SSP) in a propagation-oriented latent space. Following an analysis-propagation-synthesis design, our framework: (i) maps physical states into a shared, time-consistent spatial representation; (ii) projects this space into a compact propagation state to isolate recurrent dynamics from fine-grained spatial details, thereby decoupling reconstruction fidelity from rollout regularity; and (iii) evolves retained spectral modes using a frequency-conditioned linear backbone complemented by a nonlinear spectral closure to account for truncated interactions. This explicit structuring endows the propagator with a strong inductive bias for coherent modal evolution. Extensive experiments demonstrate that SSP significantly outperforms state-of-the-art baselines, reducing relative $L_2$ errors by up to 48.9% and exhibiting improved stability in temporal extrapolation beyond the supervised horizon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Structured Spectral Propagator (SSP) framework for long-horizon time-dependent PDE forecasting. It employs an analysis-propagation-synthesis pipeline that maps physical states to a time-consistent spatial representation, projects this into a compact latent propagation state to isolate recurrent dynamics from fine-grained spatial details, and evolves retained spectral modes via a frequency-conditioned linear backbone augmented by a nonlinear spectral closure for truncated interactions. The central claim is that this explicit inductive bias yields stable autoregressive rollouts, with experiments showing up to 48.9% relative L2 error reduction versus state-of-the-art baselines and improved extrapolation stability beyond the training horizon.
Significance. If the performance and stability claims hold under rigorous validation, the work offers a meaningful advance in neural operator methods for PDEs by explicitly structuring the latent space to promote coherent modal evolution and decouple reconstruction from rollout regularity. The design provides a clear inductive bias that addresses a known weakness of implicit finite-time neural propagators. The paper supplies extensive experiments across multiple PDEs, which strengthens the empirical case.
major comments (2)
- [§3.2] §3.2 (Projection to compact propagation state): The claim that this step successfully isolates recurrent dynamics without discarding scale-coupling information essential for long-term coherence lacks a supporting bound or analysis. In nonlinear PDEs, truncated high-frequency modes can couple back into retained modes; without a derivation showing that the retained spectral modes plus the nonlinear closure prevent accumulation of drift over long horizons, the 48.9% L2 reduction and extrapolation stability cannot be guaranteed to generalize beyond the tested regimes.
- [§4] §4 (Experimental validation): The headline performance numbers (48.9% relative L2 reduction and improved stability) are load-bearing for the central claim, yet the section provides insufficient detail on baseline implementations, exact dataset characteristics, number of independent runs, error bars, and statistical tests. This makes it impossible to assess whether the gains are robust or sensitive to hyperparameter choices in the projection and closure.
minor comments (2)
- [Abstract] Abstract: The statement of 'extensive experiments' would benefit from naming the specific PDE families and horizons tested to give readers immediate context.
- [§3] Notation: The frequency-conditioned linear backbone and nonlinear spectral closure would be easier to follow if a compact symbol table were added near the beginning of §3.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments help us clarify the theoretical motivations and strengthen the experimental reporting. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Projection to compact propagation state): The claim that this step successfully isolates recurrent dynamics without discarding scale-coupling information essential for long-term coherence lacks a supporting bound or analysis. In nonlinear PDEs, truncated high-frequency modes can couple back into retained modes; without a derivation showing that the retained spectral modes plus the nonlinear closure prevent accumulation of drift over long horizons, the 48.9% L2 reduction and extrapolation stability cannot be guaranteed to generalize beyond the tested regimes.
Authors: We appreciate the referee's emphasis on theoretical grounding. The SSP projection is motivated by classical spectral decomposition, where dominant low-frequency modes govern long-term evolution while the nonlinear spectral closure approximates the backscatter from truncated modes (analogous to eddy-viscosity or subgrid closures in fluid dynamics). This design provides an explicit inductive bias for modal coherence without requiring a full Galerkin projection. However, deriving a general bound on drift accumulation for arbitrary nonlinear PDEs would necessitate strong assumptions on the closure error and the underlying operator that do not hold universally; such analysis lies beyond the scope of the current work. Instead, we rely on the architecture's structure plus extensive empirical validation across diverse PDEs. In the revision we will add a dedicated paragraph in §3.2 discussing the closure's role in mitigating scale coupling and explicitly noting the absence of a rigorous stability bound as a limitation. revision: partial
-
Referee: [§4] §4 (Experimental validation): The headline performance numbers (48.9% relative L2 reduction and improved stability) are load-bearing for the central claim, yet the section provides insufficient detail on baseline implementations, exact dataset characteristics, number of independent runs, error bars, and statistical tests. This makes it impossible to assess whether the gains are robust or sensitive to hyperparameter choices in the projection and closure.
Authors: We agree that reproducibility and robustness assessment require fuller disclosure. The original manuscript includes baseline code, dataset generation scripts, and hyperparameter tables in the supplementary material and appendix, but the main-text description of §4 is indeed concise. We will revise §4 to explicitly state: (i) baseline implementations with exact architectures, training schedules, and hyperparameter values; (ii) precise dataset characteristics including spatial resolution, temporal sampling, train/validation/test splits, and forcing terms; (iii) results averaged over 5 independent runs with different random seeds; (iv) error bars as standard deviation across runs; and (v) statistical significance via paired t-tests against the strongest baseline. These additions will be placed in the main text with pointers to the appendix for full tables. revision: yes
Circularity Check
No circularity: SSP is a new architectural construction validated empirically
full rationale
The paper introduces SSP via an explicit analysis-propagation-synthesis pipeline that maps states to a latent representation, projects to a compact propagation state, and evolves modes with a linear backbone plus nonlinear closure. These are presented as design choices endowing inductive bias, not as derivations or predictions that reduce to fitted inputs by construction. No equations, self-citations, or uniqueness theorems are invoked in the abstract or described chain that collapse the claimed L2 reductions or stability gains to tautologies. Experimental outperformance is reported separately and does not rely on load-bearing self-references or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep learning for physical processes: Incorporating prior scientific knowledge,
E. De Bézenac, A. Pajot, and P. Gallinari, “Deep learning for physical processes: Incorporating prior scientific knowledge,”Journal of Statistical Mechanics: Theory and Experiment, vol. 2019, no. 12, p. 124009, 2019
work page 2019
-
[2]
Machine learning for partial differential equations,
S. L. Brunton and J. N. Kutz, “Machine learning for partial differential equations,” arXiv preprint arXiv:2303.17078, 2023
-
[3]
L. Lu, P. Jin, and G. E. Karniadakis, “Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators,”arXiv preprint arXiv:1910.03193, 2019
work page internal anchor Pith review arXiv 1910
-
[4]
Neural operator: Learning maps between function spaces with applications to pdes,
N. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. Stuart, and A. Anandkumar, “Neural operator: Learning maps between function spaces with applications to pdes,”Journal of Machine Learning Research, vol. 24, no. 89, pp. 1–97, 2023
work page 2023
-
[5]
Fourier Neural Operator for Parametric Partial Differential Equations
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anandkumar, “Fourier neural operator for parametric partial differential equations,” arXiv preprint arXiv:2010.08895, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
Convolutional neural operators for robust and accurate learning of pdes,
B. Raonic, R. Molinaro, T. De Ryck, T. Rohner, F. Bartolucci, R. Alaifari, S. Mishra, and E. De Bézenac, “Convolutional neural operators for robust and accurate learning of pdes,”Advances in Neural Information Processing Systems, vol. 36, pp. 77187–77200, 2023
work page 2023
-
[7]
Gnot: A general neural operator transformer for operator learning,
Z. Hao, Z. Wang, H. Su, C. Ying, Y. Dong, S. Liu, Z. Cheng, J. Song, and J. Zhu, “Gnot: A general neural operator transformer for operator learning,” inInternational conference on machine learning, pp. 12556–12569, PMLR, 2023
work page 2023
-
[8]
A neural pde solver with temporal stencil modeling,
Z. Sun, Y. Yang, and S. Yoo, “A neural pde solver with temporal stencil modeling,” in International Conference on Machine Learning, pp. 33135–33155, PMLR, 2023
work page 2023
-
[9]
Message passing neural pde solvers
J. Brandstetter, D. Worrall, and M. Welling, “Message passing neural pde solvers,” arXiv preprint arXiv:2202.03376, 2022
-
[10]
Transfer learning enhanced deeponet for long-time prediction of evolution equations,
W. Xu, Y. Lu, and L. Wang, “Transfer learning enhanced deeponet for long-time prediction of evolution equations,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, pp. 10629–10636, 2023
work page 2023
-
[11]
Recurrent neural operators: Stable long-term pde prediction,
Z. Ye, C.-S. Zhang, and W. Wang, “Recurrent neural operators: Stable long-term pde prediction,”arXiv preprint arXiv:2505.20721, 2025
-
[12]
On the difficulty of learning chaotic dynamics with rnns,
J. Mikhaeil, Z. Monfared, and D. Durstewitz, “On the difficulty of learning chaotic dynamics with rnns,”Advances in neural information processing systems, vol. 35, pp. 11297–11312, 2022
work page 2022
-
[13]
Pde-refiner: Achiev- ing accurate long rollouts with neural pde solvers,
P. Lippe, B. Veeling, P. Perdikaris, R. Turner, and J. Brandstetter, “Pde-refiner: Achiev- ing accurate long rollouts with neural pde solvers,”Advances in Neural Information Processing Systems, vol. 36, pp. 67398–67433, 2023
work page 2023
-
[14]
Coast: Intelligent time-adaptive neural operators,
Z. Wu, S. Zhang, S. He, S. Wang, M. Zhu, A. Jiao, L. Lu, and D. van Dijk, “Coast: Intelligent time-adaptive neural operators,” in2nd AI for Math Workshop@ ICML 2025, 2025
work page 2025
-
[15]
Learning to accelerate partial differential equations via latent global evolution,
T. Wu, T. Maruyama, and J. Leskovec, “Learning to accelerate partial differential equations via latent global evolution,”Advances in Neural Information Processing Systems, vol. 35, pp. 2240–2253, 2022
work page 2022
-
[16]
Latent neural pde solver: A reduced-order modeling framework for partial differential equations,
Z. Li, S. Patil, F. Ogoke, D. Shu, W. Zhen, M. Schneier, J. R. Buchanan Jr, and A. B. Farimani, “Latent neural pde solver: A reduced-order modeling framework for partial differential equations,”Journal of Computational Physics, vol. 524, p. 113705, 2025. 10
work page 2025
-
[17]
Latent neural operator for solving forward and inverse pde problems,
T. Wang and C. Wang, “Latent neural operator for solving forward and inverse pde problems,”Advances in Neural Information Processing Systems, vol. 37, pp. 33085–33107, 2024
work page 2024
-
[18]
Aroma: Preserving spatial structure for latent pde modeling with local neural fields,
L.Serrano, T.X.Wang, E.LeNaour, J.-N.Vittaut, andP.Gallinari, “Aroma: Preserving spatial structure for latent pde modeling with local neural fields,”Advances in Neural Information Processing Systems, vol. 37, pp. 13489–13521, 2024
work page 2024
-
[19]
Calm-pde: Continuous and adap- tive convolutions for latent space modeling of time-dependent pdes,
J. Hagnberger, D. Musekamp, and M. Niepert, “Calm-pde: Continuous and adap- tive convolutions for latent space modeling of time-dependent pdes,”arXiv preprint arXiv:2505.12944, 2025
-
[20]
Universal physics transformers: A framework for efficiently scaling neural operators,
B. Alkin, A. Fürst, S. Schmid, L. Gruber, M. Holzleitner, and J. Brandstetter, “Universal physics transformers: A framework for efficiently scaling neural operators,”Advances in Neural Information Processing Systems, vol. 37, pp. 25152–25194, 2024
work page 2024
-
[21]
Koopman neural operator as a mesh-free solver of non-linear partial differential equations,
W. Xiong, X. Huang, Z. Zhang, R. Deng, P. Sun, and Y. Tian, “Koopman neural operator as a mesh-free solver of non-linear partial differential equations,”Journal of Computational Physics, vol. 513, p. 113194, 2024
work page 2024
-
[22]
Invertible koopman neural operator for data-driven modeling of partial differential equations,
Y. Jin, A. Cong, L. Hou, Q. Gao, X. Ge, C. Zhu, Y. Feng, and J. Li, “Invertible koopman neural operator for data-driven modeling of partial differential equations,” arXiv preprint arXiv:2503.19717, 2025
-
[23]
Equivariance and partial observations in koopman operator theory for partial differential equations,
S. Peitz, H. Harder, F. Nüske, F. Philipp, M. Schaller, and K. Worthmann, “Equivariance and partial observations in koopman operator theory for partial differential equations,” arXiv preprint arXiv:2307.15325, 2023
-
[24]
Numerical solution partial differ- ential equations using the discrete fourier transform,
D. Rodriguez-Lara, I. Alvarez-Rios, and F. S. Guzman, “Numerical solution partial differ- ential equations using the discrete fourier transform,”arXiv preprint arXiv:2412.12308, 2024
-
[25]
U-fno—an en- hanced fourier neural operator-based deep-learning model for multiphase flow,
G. Wen, Z. Li, K. Azizzadenesheli, A. Anandkumar, and S. M. Benson, “U-fno—an en- hanced fourier neural operator-based deep-learning model for multiphase flow,”Advances in Water Resources, vol. 163, p. 104180, 2022
work page 2022
-
[26]
U-no: U-shaped neural operators.arXiv preprint arXiv:2204.11127, 2022
M. A. Rahman, Z. E. Ross, and K. Azizzadenesheli, “U-no: U-shaped neural operators,” arXiv preprint arXiv:2204.11127, 2022
-
[27]
Factorized fourier neural operators.arXiv preprint arXiv:2111.13802, 2021
A. Tran, A. Mathews, L. Xie, and C. S. Ong, “Factorized fourier neural operators,” arXiv preprint arXiv:2111.13802, 2021
-
[28]
Mionet: Learning multiple-input operators via tensor product,
P. Jin, S. Meng, and L. Lu, “Mionet: Learning multiple-input operators via tensor product,”SIAM Journal on Scientific Computing, vol. 44, no. 6, pp. A3490–A3514, 2022
work page 2022
-
[29]
Physics-informed neural operator for learning partial differential equations,
Z. Li, H. Zheng, N. Kovachki, D. Jin, H. Chen, B. Liu, K. Azizzadenesheli, and A. Anandkumar, “Physics-informed neural operator for learning partial differential equations,”ACM/IMS Journal of Data Science, vol. 1, no. 3, pp. 1–27, 2024
work page 2024
-
[30]
Fourier neural operator with learned deformations for pdes on general geometries,
Z. Li, D. Z. Huang, B. Liu, and A. Anandkumar, “Fourier neural operator with learned deformations for pdes on general geometries,”Journal of Machine Learning Research, vol. 24, no. 388, pp. 1–26, 2023
work page 2023
-
[31]
Crom: Continuous reduced-order modeling of pdes using implicit neural representations,
P. Y. Chen, J. Xiang, D. H. Cho, Y. Chang, G. Pershing, H. T. Maia, M. M. Chiaramonte, K. Carlberg, and E. Grinspun, “Crom: Continuous reduced-order modeling of pdes using implicit neural representations,”arXiv preprint arXiv:2206.02607, 2022
-
[32]
Learning nonlinear reduced models from data with operator inference,
B. Kramer, B. Peherstorfer, and K. E. Willcox, “Learning nonlinear reduced models from data with operator inference,”Annual Review of Fluid Mechanics, vol. 56, no. 1, pp. 521–548, 2024
work page 2024
-
[33]
Physics-informed reduced order modeling of time-dependent pdes via differentiable solvers,
N. H. Dashtbayaz, H. Salehipour, A. Butscher, and N. Morris, “Physics-informed reduced order modeling of time-dependent pdes via differentiable solvers,”arXiv preprint arXiv:2505.14595, 2025. 11
-
[34]
Latent mamba operator for partial differential equations,
K. Tiwari, N. Dutta, N. Krishnan,et al., “Latent mamba operator for partial differential equations,”arXiv preprint arXiv:2505.19105, 2025
-
[35]
S. A. McQuarrie, P. Khodabakhshi, and K. E. Willcox, “Nonintrusive reduced-order models for parametric partial differential equations via data-driven operator inference,” SIAM Journal on Scientific Computing, vol. 45, no. 4, pp. A1917–A1946, 2023
work page 2023
-
[36]
N. Franco, A. Manzoni, and P. Zunino, “A deep learning approach to reduced or- der modelling of parameter dependent partial differential equations,”Mathematics of Computation, vol. 92, no. 340, pp. 483–524, 2023
work page 2023
-
[37]
L. N. Trefethen,Spectral methods in MATLAB. SIAM, 2000
work page 2000
- [38]
-
[39]
Sagaut,Large eddy simulation for incompressible flows: an introduction
P. Sagaut,Large eddy simulation for incompressible flows: an introduction. Springer, 2006
work page 2006
-
[40]
S. B. Pope, “Turbulent flows,”Measurement Science and Technology, vol. 12, no. 11, pp. 2020–2021, 2001
work page 2020
-
[41]
Optimal prediction of underresolved dynamics,
A. J. Chorin, A. P. Kast, and R. Kupferman, “Optimal prediction of underresolved dynamics,”Proceedings of the National Academy of Sciences, vol. 95, no. 8, pp. 4094– 4098, 1998
work page 1998
-
[42]
Neural ordinary differential equations,
R. T. Chen, Y. Rubanova, J. Bettencourt, and D. K. Duvenaud, “Neural ordinary differential equations,”Advances in neural information processing systems, vol. 31, 2018
work page 2018
-
[43]
Pdebench: An extensive benchmark for scientific machine learning,
M. Takamoto, T. Praditia, R. Leiteritz, D. MacKinlay, F. Alesiani, D. Pflüger, and M. Niepert, “Pdebench: An extensive benchmark for scientific machine learning,” Advances in neural information processing systems, vol. 35, pp. 1596–1611, 2022. 12
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.