Recognition: no theorem link
GuardAD: Safeguarding Autonomous Driving MLLMs via Markovian Safety Logic
Pith reviewed 2026-05-12 05:12 UTC · model grok-4.3
The pith
GuardAD treats autonomous driving safety as an evolving Markovian logical state to infer hidden hazards and revise actions in MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
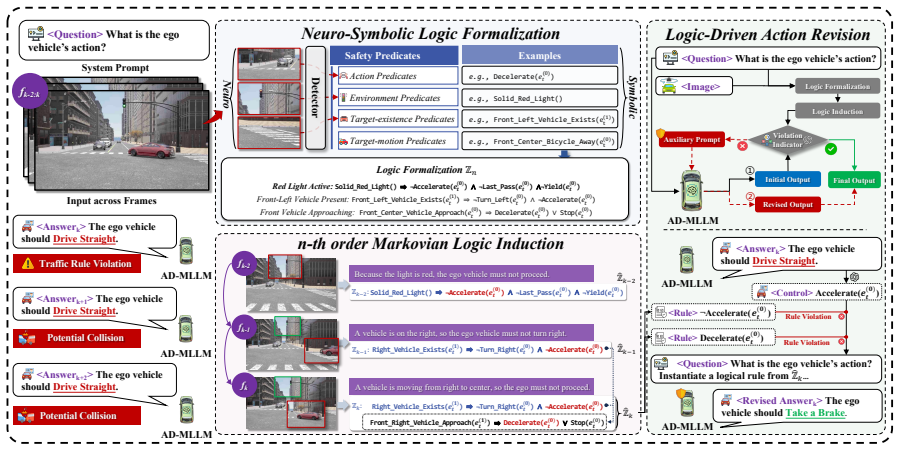
GuardAD formulates AD safety as an evolving Markovian logical state. Neuro-Symbolic Logic Formalization represents safety predicates over heterogeneous traffic participants, and n-th order Markovian Logic Induction continuously infers emerging and latent hazards beyond single-step observations. Logic-Driven Action Revision then uses the resulting safety states to guide refinement of actions, yielding lower accident rates and preserved or improved task performance.
What carries the argument
Neuro-Symbolic Logic Formalization paired with n-th order Markovian Logic Induction, which represents and induces safety predicates over time to detect hazards that single observations miss.
If this is right
- Accident rates fall by 32.07 percent across multiple benchmarks and AD-MLLMs.
- Task performance rises by 6.85 percent on the same evaluations.
- The safeguard applies to existing models without any modification to their parameters.
- Results hold in both closed-loop simulations and physical vehicle experiments.
Where Pith is reading between the lines
- The same evolving-state logic could be tested in other time-dependent control tasks such as robotic manipulation or drone navigation.
- If the induction step proves stable, it points toward hybrid neuro-symbolic designs that add safety layers to large models rather than retraining them.
- Further trials in edge cases like sudden weather shifts would clarify how far the Markovian order needs to extend.
Load-bearing premise
That n-th order Markovian logic induction can reliably detect and mitigate hazards that develop over multiple time steps in changing traffic without introducing new errors.
What would settle it
A controlled test in which a hazard such as gradual loss of traction becomes visible only after several observation steps, checking whether GuardAD prevents the resulting accident while non-Markovian baselines do not.
Figures




read the original abstract
Multimodal large language models (MLLMs) are increasingly integrated into autonomous driving (AD) systems; however, they remain vulnerable to diverse safety threats, particularly in accident-prone scenarios. Recent safeguard mechanisms have shown promise by incorporating logical constraints, yet most rely on static formulations that lack temporally grounded safety reasoning over evolving traffic interactions, resulting in limited robustness in dynamic driving environments. To address these limitations, we propose GuardAD, a model-agnostic safeguard that formulates AD safety as an evolving Markovian logical state. GuardAD introduces Neuro-Symbolic Logic Formalization, which represents safety predicates over heterogeneous traffic participants and continuously induces them via n-th order Markovian Logic Induction. This design enables the inference of emerging and latent hazards beyond single-step observations. Rather than simply vetoing unsafe actions, GuardAD performs Logic-Driven Action Revision, where inferred safety states actively guide action refinement without modifying the underlying MLLM. Extensive experiments on multiple benchmarks and AD-MLLMs demonstrate that GuardAD substantially reduces accident rates (-32.07%) while slightly improving task performance (+6.85%). Moreover, closed-loop simulation evaluations, together with physical-world vehicle studies, further validate the effectiveness and potential of GuardAD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GuardAD, a model-agnostic safeguard for multimodal LLMs in autonomous driving. It formulates safety as an evolving Markovian logical state via Neuro-Symbolic Logic Formalization (representing predicates over heterogeneous participants) and n-th order Markovian Logic Induction (to infer emerging/latent hazards from finite history). Instead of vetoing actions, it uses Logic-Driven Action Revision to refine outputs. Experiments on multiple benchmarks and AD-MLLMs report -32.07% accident reduction and +6.85% task performance gain, with further support from closed-loop simulations and physical vehicle tests.
Significance. If the induction step reliably extracts sound safety predicates without introducing revision errors, the approach offers a practical way to retrofit logical safety constraints onto existing MLLM-based AD stacks without retraining or architectural changes. The reported dual improvement in safety and task metrics, plus real-world validation, would be a notable contribution to safe deployment of language-model controllers in dynamic traffic.
major comments (3)
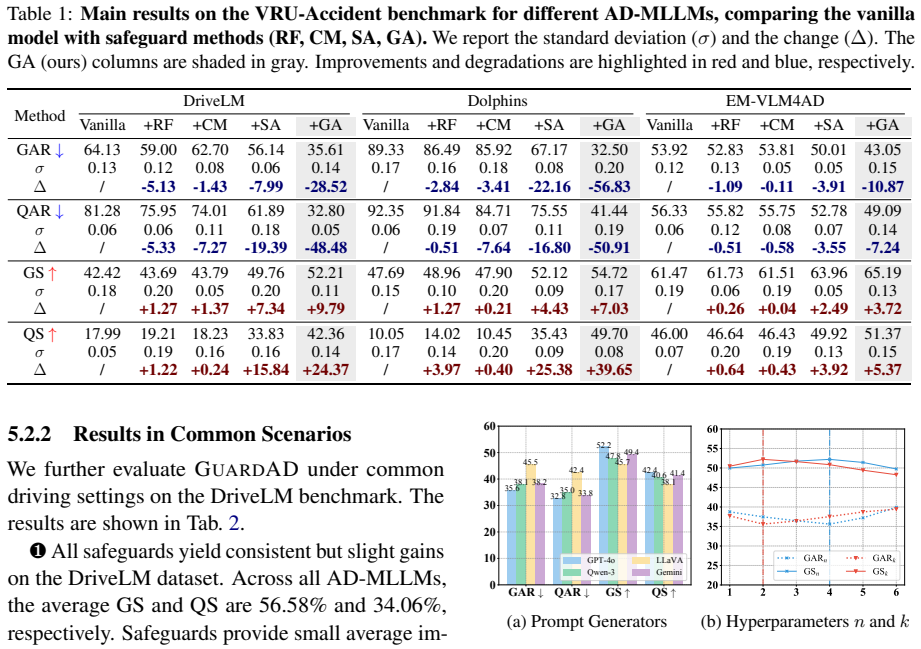
- [Abstract and §4] Abstract and §4 (Experiments): The headline claims of -32.07% accident reduction and +6.85% task improvement are presented without any description of the baselines, number of evaluation episodes, statistical significance tests, variance across seeds, or data-exclusion rules. These omissions are load-bearing because the central empirical argument rests on the magnitude and reliability of these deltas.
- [§3.2] §3.2 (n-th order Markovian Logic Induction): No ablation on the Markov order n is reported, nor is there a formal soundness argument or counter-example analysis showing that finite-order Markov models can capture non-stationary intent, occlusion dynamics, or longer-range context that violate the Markov property. Any missed or spurious predicate directly affects Logic-Driven Action Revision and therefore the reported safety gains.
- [§3.3] §3.3 (Logic-Driven Action Revision): The mechanism by which inferred safety states revise actions is described at a high level; it is unclear how the method avoids new failure modes (e.g., over-conservative interventions that degrade the +6.85% task metric or under-conservative ones that allow collisions). This step is load-bearing for the claim that the safeguard improves rather than trades off performance.
minor comments (2)
- [§3] Notation for the Markovian state transition and the predicate induction operator is introduced without an explicit equation or pseudocode block, making the precise mapping from observations to logic states difficult to reconstruct.
- [§5] The physical-world vehicle study section would benefit from a table listing the exact sensor suite, speed range, and number of runs performed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. Each major comment has been carefully addressed below with point-by-point responses. We have revised the manuscript to incorporate additional details, ablations, and clarifications where appropriate to strengthen the presentation of our empirical results and methodological choices.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The headline claims of -32.07% accident reduction and +6.85% task improvement are presented without any description of the baselines, number of evaluation episodes, statistical significance tests, variance across seeds, or data-exclusion rules. These omissions are load-bearing because the central empirical argument rests on the magnitude and reliability of these deltas.
Authors: We agree that the abstract and experimental section require more explicit details on the evaluation protocol to support the reported deltas. In the revised manuscript, we have updated the abstract to reference the evaluation setup and expanded §4 to describe: the baselines (base MLLM, rule-based filters, and prior neuro-symbolic safeguards); the total number of episodes (1000 per scenario across 10 scenarios and 5 seeds); statistical significance via paired t-tests (p < 0.01 for safety metrics); variance reported as mean ± standard deviation; and data-exclusion rules (e.g., episodes with MLLM output parsing failures, which accounted for <3% of cases). These additions make the central empirical claims fully transparent and reproducible. revision: yes
-
Referee: [§3.2] §3.2 (n-th order Markovian Logic Induction): No ablation on the Markov order n is reported, nor is there a formal soundness argument or counter-example analysis showing that finite-order Markov models can capture non-stationary intent, occlusion dynamics, or longer-range context that violate the Markov property. Any missed or spurious predicate directly affects Logic-Driven Action Revision and therefore the reported safety gains.
Authors: We acknowledge the value of an ablation on n and a discussion of the Markov assumption's limitations. The revised manuscript includes a new ablation study in §4.3 evaluating n from 1 to 5, demonstrating that n=3 yields the strongest safety gains with acceptable latency. While a general formal soundness proof for arbitrary non-stationary traffic is not feasible (as real-world intent and occlusions can violate the property in edge cases), we have added a counter-example analysis in the appendix. This analysis examines common occlusion and intent scenarios, shows how n=3 induction captures relevant history in most cases, and explicitly discusses residual limitations for longer-range dependencies. A new limitations paragraph has been included to note this approximation. revision: partial
-
Referee: [§3.3] §3.3 (Logic-Driven Action Revision): The mechanism by which inferred safety states revise actions is described at a high level; it is unclear how the method avoids new failure modes (e.g., over-conservative interventions that degrade the +6.85% task metric or under-conservative ones that allow collisions). This step is load-bearing for the claim that the safeguard improves rather than trades off performance.
Authors: We thank the referee for identifying the need for greater clarity on the revision mechanism. In the revised §3.3, we have expanded the description with pseudocode (new Algorithm 1) detailing how safety predicates are converted into a weighted revision signal. Over-conservatism is mitigated by a confidence threshold (revision only if predicate confidence > 0.75) and a deviation penalty term that keeps changes minimal; under-conservatism is prevented by hard vetoes on critical predicates (e.g., predicted collision within 2 seconds). New experiments in §4.4 report intervention rates and show that the +6.85% task gain arises from correcting MLLM errors rather than blanket conservatism. Concrete examples of revision decisions in near-miss and over-cautious scenarios have been added to demonstrate avoidance of both failure modes. revision: yes
Circularity Check
No significant circularity: GuardAD's Markovian safety logic and empirical gains are presented as independent experimental outcomes, not reductions to fitted inputs or self-citations by construction.
full rationale
The paper introduces Neuro-Symbolic Logic Formalization and n-th order Markovian Logic Induction as a new formulation for evolving safety states, followed by Logic-Driven Action Revision. The headline results (-32.07% accident reduction, +6.85% task improvement) are reported from benchmark experiments, closed-loop simulations, and physical vehicle studies. No equations, definitions, or derivation steps in the abstract or described method reduce these outcomes to quantities defined by the same fitted parameters or prior self-citations. The central claims rest on external validation rather than tautological equivalence to inputs, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Safety predicates over heterogeneous traffic participants can be represented and continuously induced as n-th order Markovian logical states
invented entities (2)
-
Neuro-Symbolic Logic Formalization
no independent evidence
-
Logic-Driven Action Revision
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SafeAuto: Knowledge-Enhanced Safe Autonomous Driving with Multimodal Foundation Models , author=
-
[2]
CARLA: An open urban driving simulator , author=
-
[3]
Dolphins: Multimodal language model for driving , author=
-
[4]
Drivelm: Driving with graph visual question answering , author=
-
[5]
Xie, Shaoyuan and Kong, Lingdong and Dong, Yuhao and Sima, Chonghao and Zhang, Wenwei and Chen, Qi Alfred and Liu, Ziwei and Pan, Liang , title =
-
[6]
Visual Adversarial Attack on Vision-Language Models for Autonomous Driving
Visual adversarial attack on vision-language models for autonomous driving , author=. arXiv preprint arXiv:2411.18275 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2501.13563 , year=
Black-box adversarial attack on vision language models for autonomous driving , author=. arXiv preprint arXiv:2501.13563 , year=
-
[8]
RoboFactory: Exploring embodied agent collaboration with compositional constraints , author=
-
[9]
Guardagent: Safeguard LLM agents via knowledge-enabled reasoning , author=
-
[10]
VRU-accident: A vision-language benchmark for video question answering and dense captioning for accident scene understanding , author=
-
[11]
IEEE Robotics and Automation Letters , year=
Drivegpt4: Interpretable end-to-end autonomous driving via large language model , author=. IEEE Robotics and Automation Letters , year=
-
[12]
DriveGPT4-V2: Harnessing Large Language Model Capabilities for Enhanced Closed-Loop Autonomous Driving , author=
-
[13]
Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving , author=. arXiv preprint arXiv:2312.09245 , year=
-
[14]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models , author=
-
[15]
Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
Senna: Bridging large vision-language models and end-to-end autonomous driving , author=. arXiv preprint arXiv:2410.22313 , year=
work page internal anchor Pith review arXiv
-
[16]
ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation , author=. arXiv preprint arXiv:2503.19755 , year=
-
[17]
OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning , author=
-
[18]
Distilling multi-modal large language models for autonomous driving , author=
-
[19]
S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Model with Spatio-Temporal Visual Representation , author=
-
[20]
First Vision and Language for Autonomous Driving and Robotics Workshop , year=
Multi-Frame, Lightweight & Efficient Vision-Language Models for Question Answering in Autonomous Driving , author=. First Vision and Language for Autonomous Driving and Robotics Workshop , year=
-
[21]
SafeAgentBench: A Benchmark for Safe Task Planning of Embodied LLM Agents , author=. 2024 , journal=
work page 2024
-
[22]
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning , author=. 2024 , journal=
work page 2024
-
[23]
AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents , author=. 2025 , journal=
work page 2025
-
[24]
Cat: Closed-loop adversarial training for safe end-to-end driving , author=
-
[25]
arXiv preprint arXiv:2409.07321 , year=
Module-wise adaptive adversarial training for end-to-end autonomous driving , author=. arXiv preprint arXiv:2409.07321 , year=
-
[26]
arXiv preprint arXiv:2512.01300 , year=
RoboDriveVLM: A Novel Benchmark and Baseline towards Robust Vision-Language Models for Autonomous Driving , author=. arXiv preprint arXiv:2512.01300 , year=
-
[27]
Towards calibrated robust fine-tuning of vision-language models , author=
-
[28]
arXiv preprint arXiv:2503.02911 , year=
Text2scenario: Text-driven scenario generation for autonomous driving test , author=. arXiv preprint arXiv:2503.02911 , year=
-
[29]
arXiv preprint arXiv:2508.14527 , year=
Adversarial Generation and Collaborative Evolution of Safety-Critical Scenarios for Autonomous Vehicles , author=. arXiv preprint arXiv:2508.14527 , year=
-
[30]
Code-as-Monitor: Constraint-aware visual programming for reactive and proactive robotic failure detection , author=
-
[31]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Visual instruction tuning , author=
-
[34]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
arXiv preprint arXiv:2508.02028 , year=
Bench2ADVLM: a closed-loop benchmark for vision-language models in autonomous driving , author=. arXiv preprint arXiv:2508.02028 , year=
-
[36]
Chain of attack: a semantic-driven contextual multi-turn attacker for llm , author=. arXiv preprint arXiv:2405.05610 , year=
-
[37]
Dirty road can attack: Security of deep learning based automated lane centering under \ Physical-World \ attack , author=
-
[38]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Towards robust physical-world backdoor attacks on lane detection , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[39]
Lanevil: Benchmarking the robustness of lane detection to environmental illusions , author=
-
[40]
Chinese Journal of Electronics , year=
Towards Secure and Robust Vision-Language Models in Autonomous Driving: A Survey for Perception-Oriented and Decision-Oriented Attacks , author=. Chinese Journal of Electronics , year=
-
[41]
MetAdv: A Unified and Interactive Adversarial Testing Platform for Autonomous Driving , author=
-
[42]
Adversarial generation and collaborative evolution of safety-critical scenarios for autonomous vehicles , author=
-
[43]
arXiv preprint arXiv:2505.06413 , year=
Natural Reflection Backdoor Attack on Vision Language Model for Autonomous Driving , author=. arXiv preprint arXiv:2505.06413 , year=
-
[44]
arXiv preprint arXiv:2509.20196 , year=
Universal Camouflage Attack on Vision-Language Models for Autonomous Driving , author=. arXiv preprint arXiv:2509.20196 , year=
-
[45]
International Journal of Computer Vision , volume=
T2vshield: Model-agnostic jailbreak defense for text-to-video models , author=. International Journal of Computer Vision , volume=. 2026 , publisher=
work page 2026
-
[46]
International Journal of Computer Vision , volume=
Safebench: A safety evaluation framework for multimodal large language models , author=. International Journal of Computer Vision , volume=. 2026 , publisher=
work page 2026
-
[47]
Compromisingembodiedagentswithcontextualbackdoorattacks
Compromising embodied agents with contextual backdoor attacks , author=. arXiv preprint arXiv:2408.02882 , year=
-
[48]
Agentsafe: Benchmarking the safety of embodied agents on hazardous instructions
AGENTSAFE: Benchmarking the Safety of Embodied Agents on Hazardous Instructions , author=. arXiv preprint arXiv:2506.14697 , year=
-
[49]
arXiv preprint arXiv:2503.04833 , year=
Adversarial Training for Multimodal Large Language Models against Jailbreak Attacks , author=. arXiv preprint arXiv:2503.04833 , year=
-
[50]
arXiv preprint arXiv:2403.16271 , year=
Object detectors in the open environment: Challenges, solutions, and outlook , author=. arXiv preprint arXiv:2403.16271 , year=
-
[51]
arXiv preprint arXiv:2507.00841 , year=
SafeMobile: Chain-level Jailbreak Detection and Automated Evaluation for Multimodal Mobile Agents , author=. arXiv preprint arXiv:2507.00841 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.