Recognition: 1 theorem link
· Lean TheoremQuantifying Concentration Phenomena of Mean-Field Transformers in the Low-Temperature Regime
Pith reviewed 2026-05-12 03:19 UTC · model grok-4.3
The pith
Token distributions in mean-field transformers concentrate onto the push-forward of the initial distribution under a projection map in the low-temperature regime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
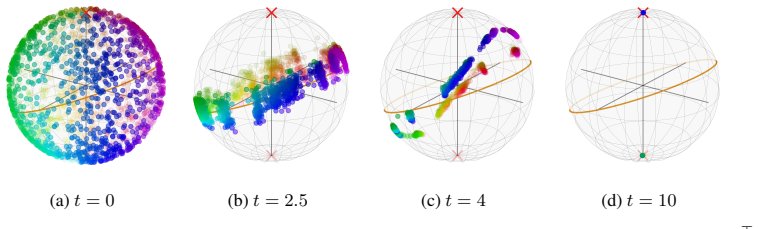
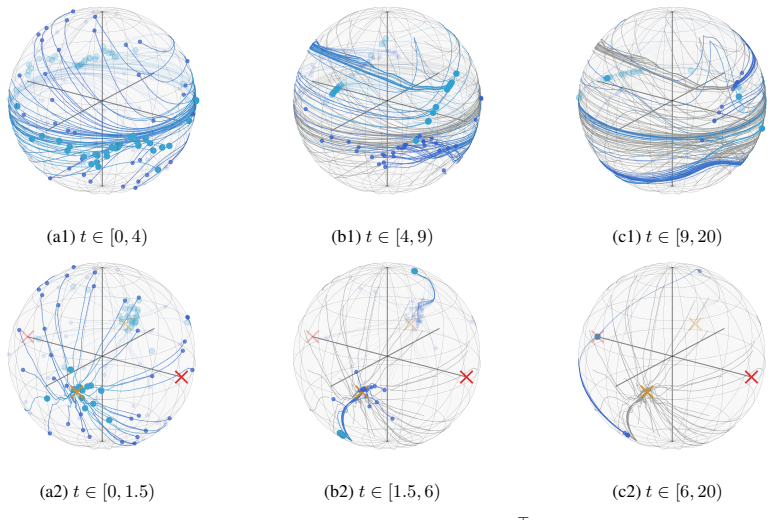
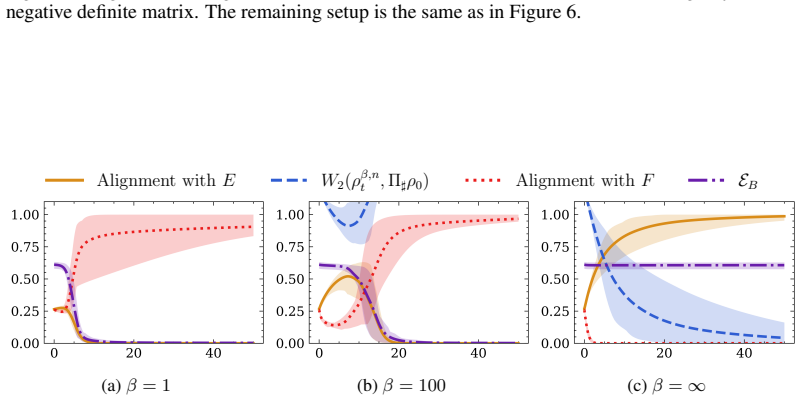
The token distribution rapidly concentrates onto the push-forward of the initial distribution under a projection map induced by the key, query, and value matrices, and remains metastable for moderate times. The Wasserstein distance between the distributions scales like √(log(β+1)/β) exp(Ct) + exp(-ct) as β^{-1}→0 and t≥0. The proof relies on Lyapunov-type estimates for the zero-temperature equation, identifying its long-time limit, and a stability estimate in Wasserstein space combined with a quantitative Laplace principle.
What carries the argument
The mean-field continuity equation governing the evolution of the token distribution, analyzed through Lyapunov estimates, Wasserstein stability, and the quantitative Laplace principle to establish concentration.
If this is right
- For timescales of order log β the token distribution concentrates at the identified limiting distribution.
- Numerical experiments confirm the concentration and show that for finite β and large t the dynamics enter a terminal phase dominated by the spectrum of the value matrix.
- The result applies in the large-token limit where the projection map is well-defined.
Where Pith is reading between the lines
- This suggests that transformer inference can be understood as a rapid projection followed by a metastable state, which might be used to design better temperature schedules.
- One could investigate whether similar concentration occurs in other attention-based architectures beyond the encoder-only case considered here.
Load-bearing premise
The token dynamics at inference are accurately described by the mean-field continuity equation in the large-token limit, with the projection map induced by the key, query, and value matrices being well-defined and stable.
What would settle it
A direct numerical check of whether the Wasserstein distance between the evolving token distribution and the projected initial distribution follows the scaling √(log(β+1)/β) exp(Ct) + exp(-ct) for increasing β and different t would confirm or refute the quantitative concentration result.
Figures







read the original abstract
Transformers with self-attention modules as their core components have become an integral architecture in modern large language and foundation models. In this paper, we study the evolution of tokens in deep encoder-only transformers at inference time which is described in the large-token limit by a mean-field continuity equation. Leveraging ideas from the convergence analysis of interacting multi-particle systems, with particles corresponding to tokens, we prove that the token distribution rapidly concentrates onto the push-forward of the initial distribution under a projection map induced by the key, query, and value matrices, and remains metastable for moderate times. Specifically, we show that the Wasserstein distance of the two distributions scales like $\sqrt{{\log(\beta+1)}/{\beta}}\exp(Ct)+\exp(-ct)$ in terms of the temperature parameter $\beta^{-1}\to 0$ and inference time $t\geq 0$. For the proof, we establish Lyapunov-type estimates for the zero-temperature equation, identify its limit as $t\to\infty$, and employ a stability estimate in Wasserstein space together with a quantitative Laplace principle to couple the two equations. Our result implies that for time scales of order $\log\beta$ the token distribution concentrates at the identified limiting distribution. Numerical experiments confirm this and, beyond that, complement our theory by showing that for finite $\beta$ and large $t$ the dynamics enter a different terminal phase, dominated by the spectrum of the value matrix.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the evolution of tokens in deep encoder-only transformers at inference time in the large-token limit via a mean-field continuity equation. It proves that the token distribution concentrates onto the push-forward of the initial distribution under a projection map from the key, query, and value matrices, with the Wasserstein distance scaling as √(log(β+1)/β) exp(Ct) + exp(-ct) as β^{-1} → 0. The proof uses Lyapunov estimates on the zero-temperature equation, its long-time limit, Wasserstein stability, and a quantitative Laplace principle. Numerical experiments confirm the concentration and show a different terminal phase dominated by the value matrix spectrum for finite β and large t.
Significance. If the claims hold, this provides a precise quantification of concentration in mean-field transformers, linking mathematical analysis of interacting systems to transformer dynamics. The explicit scaling with temperature and time, along with the identification of metastable and terminal phases, offers insights that could inform model design and analysis. The use of established tools like Lyapunov estimates and Wasserstein metrics, combined with numerics, adds rigor.
minor comments (1)
- The abstract mentions numerical experiments but provides no details on the experimental setup, such as token dimensions, matrix specifications, or simulation parameters, which would help assess the validation of the theoretical scaling.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript and for acknowledging the potential significance of our results in connecting mean-field analysis of interacting systems to transformer dynamics. We note that the recommendation is listed as 'uncertain' but that no specific major comments were provided in the report. We are therefore responding at a high level and remain ready to supply further details if requested.
Circularity Check
No significant circularity detected
full rationale
The abstract outlines a proof strategy relying on Lyapunov-type estimates for the zero-temperature equation, identification of its long-time limit, Wasserstein stability estimates, and a quantitative Laplace principle to couple the finite-temperature mean-field continuity equation to its zero-temperature counterpart. These are standard external analytic tools from interacting particle systems and optimal transport, applied to the given mean-field model without any quoted reduction of the target Wasserstein scaling to a fitted parameter, self-definition, or load-bearing self-citation chain. No equations, ansatzes, or prior-author uniqueness theorems are exhibited in the available text that would force the claimed rate by construction. The derivation is therefore self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Token evolution in deep encoder-only transformers at inference is described in the large-token limit by a mean-field continuity equation.
- ad hoc to paper Lyapunov-type estimates exist for the zero-temperature equation and a stability estimate in Wasserstein space holds.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
W2(ρβt, Π♯ρ0) ≤ 2√[log(β+1)/β](eC1t − eC0t) + Vp(ρ0) exp(−pγ t / σmax(B))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Stochastic Scaling Limits and Synchronization by Noise in Deep Transformer Models
A. Agazzi, G. Bruno, E. M. García, S. Saviozzi, and M. Romito. Stochastic scaling limits and synchronization by noise in deep transformer models.arXiv preprint arXiv:2604.26898, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
A. Alcalde, B. Geshkovski, and D. Ruiz-Balet. Attention’s forward pass and Frank-Wolfe. arXiv preprint arXiv:2508.09628, 2025
- [4]
-
[5]
A. Álvarez-López, B. Geshkovski, and D. Ruiz-Balet. Perceptrons and localization of attention’s mean-field landscape.arXiv preprint arXiv:2601.21366, 2026
work page internal anchor Pith review arXiv 2026
-
[6]
L. Ambrosio, N. Gigli, and G. Savaré.Gradient flows in metric spaces and in the space of probability measures. Lectures in Mathematics ETH Zürich. Birkhäuser Verlag, Basel, second edition, 2008. 10
work page 2008
-
[7]
R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
D. Bahdanau, K. Cho, and Y . Bengio. Neural machine translation by jointly learning to align and translate. In Y . Bengio and Y . LeCun, editors,3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015
work page 2015
- [9]
-
[10]
K. Balasubramanian, S. Banerjee, and P. Rigollet. On the structure of stationary solu- tions to McKean-Vlasov equations with applications to noisy transformers.arXiv preprint arXiv:2510.20094, 2025
-
[11]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amo...
work page 2020
- [13]
- [14]
-
[15]
L. Bungert, T. Roith, and P. Wacker. Polarized consensus-based dynamics for optimization and sampling.Math. Program., 211(1-2):125–155, 2025
work page 2025
- [16]
-
[17]
A Unified Perspective on the Dynamics of Deep Transformers.arXiv preprint arXiv:2501.18322, 2025
V . Castin, P. Ablin, J. A. Carrillo, and G. Peyré. A unified perspective on the dynamics of deep transformers.arXiv preprint arXiv:2501.18322, 2025
- [18]
-
[19]
S. Chen, Z. Lin, Y . Polyanskiy, and P. Rigollet. Quantitative clustering in mean-field transformer models.arXiv preprint arXiv:2504.14697, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [20]
-
[21]
M. Dehghani, S. Gouws, O. Vinyals, J. Uszkoreit, and L. Kaiser. Universal transformers. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, 2019
work page 2019
-
[22]
A. Dembo and O. Zeitouni.Large deviations techniques and applications, volume 38 of Applications of Mathematics (New York). Springer-Verlag, New York, second edition, 1998. 11
work page 1998
-
[23]
J. Devlin, M. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In J. Burstein, C. Doran, and T. Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, ...
work page 2019
-
[24]
M. Engel and A. Shalova. Random quadratic form on a sphere: Synchronization by common noise.arXiv preprint arXiv:2603.06187, 2026
-
[25]
M. Fornasier, H. Huang, L. Pareschi, and P. Sünnen. Consensus-based optimization on hyper- surfaces: Well-posedness and mean-field limit.Math. Models Methods Appl. Sci., 30(14):2725– 2751, 2020
work page 2020
-
[26]
M. Fornasier, T. Klock, and K. Riedl. Consensus-Based Optimization Methods Converge Globally.SIAM J. Optim., 34(3):2973–3004, 2024
work page 2024
-
[27]
Dynamic metastability in the self-attention model
B. Geshkovski, H. Koubbi, Y . Polyanskiy, and P. Rigollet. Dynamic metastability in the self-attention model.arXiv preprint arXiv:2410.06833, 2024
-
[28]
B. Geshkovski, C. Letrouit, Y . Polyanskiy, and P. Rigollet. The emergence of clusters in self- attention dynamics. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, Decemb...
work page 2023
-
[29]
B. Geshkovski, C. Letrouit, Y . Polyanskiy, and P. Rigollet. A mathematical perspective on transformers.Bull. Amer. Math. Soc. (N.S.), 62(3):427–479, 2025
work page 2025
-
[30]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
N. Karagodin, S. Ge, Y . Polyanskiy, and P. Rigollet. Normalization in attention dynamics.arXiv preprint arXiv:2510.22026, 2025
-
[32]
N. Karagodin, Y . Polyanskiy, and P. Rigollet. Clustering in causal attention masking. In A. Globersons, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. M. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15...
work page 2024
-
[33]
arXiv preprint arXiv:2604.01978 , year =
H. Koubbi, B. Geshkovski, and P. Rigollet. Homogenized transformers.arXiv preprint arXiv:2604.01978, 2026
-
[34]
Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut. ALBERT: A lite BERT for self-supervised learning of language representations. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020, 2020
work page 2020
- [35]
- [36]
-
[37]
Synchronization of mean-field models on the circle.arXiv preprint arXiv:2507.22857, 2025
Y . Polyanskiy, P. Rigollet, and A. Yao. Synchronization of mean-field models on the circle. arXiv preprint arXiv:2507.22857, 2025
-
[38]
K. Riedl. Leveraging memory effects and gradient information in consensus-based optimisation: onn global convergence in mean-field law.European J. Appl. Math., 35(4):483–514, 2024
work page 2024
-
[39]
Riedl.Mathematical Foundations of Interacting Multi-Particle Systems for Optimization
K. Riedl.Mathematical Foundations of Interacting Multi-Particle Systems for Optimization. PhD thesis, Technische Universität München, 2024. 12
work page 2024
-
[40]
The mean-field dynamics of transformers
P. Rigollet. The mean-field dynamics of transformers.arXiv preprint arXiv:2512.01868, 2025
-
[41]
M. E. Sander, P. Ablin, M. Blondel, and G. Peyré. Sinkformers: Transformers with doubly stochastic attention. InInternational Conference on Artificial Intelligence and Statistics, pages 3515–3530. PMLR, 2022
work page 2022
-
[42]
Shalova.Noisy gradient flows: with applications in machine learning
A. Shalova.Noisy gradient flows: with applications in machine learning. PhD thesis, Eindhoven University of Technology, 2025
work page 2025
-
[43]
A. Shalova and A. Schlichting. Solutions of stationary McKean–Vlasov equation on a high- dimensional sphere and other Riemannian manifolds.Adv. Nonlinear Anal., 15(1):20250141, 2026
work page 2026
-
[44]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. In I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V . N. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2...
work page 2017
-
[46]
J. V on Oswald, E. Niklasson, E. Randazzo, J. Sacramento, A. Mordvintsev, A. Zhmoginov, and M. Vladymyrov. Transformers learn in-context by gradient descent. InInternational Conference on Machine Learning, pages 35151–35174. PMLR, 2023
work page 2023
-
[47]
B. Zhang and R. Sennrich. Root mean square layer normalization. In H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. B. Fox, and R. Garnett, editors,Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 12360–1237...
work page 2019
-
[48]
B Heuristics supporting Conjecture 1 In this section, we provide heuristics supporting Conjecture 1
By choosing β large enough (in fact,β≳ 1 ε4 log 1 ε suffices) we havet 1 < t2 and the conclusion follows from Theorem 1. B Heuristics supporting Conjecture 1 In this section, we provide heuristics supporting Conjecture 1. Some of them can actually be found in the recent work [4], but we include them here for completeness. One-point dynamics.First, we cons...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.