Recognition: no theorem link
The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes
Pith reviewed 2026-05-13 02:13 UTC · model grok-4.3
The pith
On-policy distillation fails in LLMs due to distribution mismatch, biased gradients, and privileged information aggregation but targeted fixes restore effectiveness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On-policy distillation on mathematical reasoning is highly sensitive to teacher choice and loss formulation, whereas on-policy self-distillation fails due to the test-time absence of instance-specific privileged information. The three failure mechanisms are distribution mismatch between teacher and student caused by conditioning on student-generated prefixes, optimization instability from biased TopK reverse-KL gradients, and an OPSD-specific limitation where the student learns a PI-free policy that aggregates PI-conditioned teachers. In contrast, OPSD succeeds when PI represents a shared latent rule such as a system prompt. Stop-gradient TopK objectives, RLVR-adapted teachers, and SFT-stabl
What carries the argument
The three failure mechanisms in on-policy distillation—distribution mismatch from student-generated prefixes, biased TopK reverse-KL gradients, and PI-free policy aggregation in OPSD—together with the mitigations of stop-gradient TopK, RLVR teachers, and SFT stabilization.
If this is right
- OPD performance varies sharply with the choice of teacher and the exact loss formulation in reasoning tasks.
- OPSD succeeds for shared latent rules like system prompts or alignment preferences but cannot capture instance-specific PI.
- Stop-gradient applied to TopK objectives removes the source of optimization instability.
- RLVR-adapted teachers and SFT-stabilized students prevent the identified failure modes from appearing.
- The methods internalize shared information reliably but require additional handling when PI varies per instance.
Where Pith is reading between the lines
- The same mismatch and gradient issues may appear in other on-policy training loops that mix teacher and student outputs.
- Combining the fixes with existing post-training pipelines could reduce reliance on large supervised datasets for model improvement.
- Repeating the experiments at larger model scales would test whether the three mechanisms remain dominant or new interactions emerge.
- Training pipelines could adopt SFT stabilization as a default first step before attempting on-policy distillation steps.
Load-bearing premise
The tested settings of mathematical reasoning trajectories and system-prompt or alignment privileged information are representative enough that the three failure mechanisms and fixes will apply to other LLM tasks, model scales, and data distributions.
What would settle it
Apply the proposed fixes to a new task requiring instance-specific privileged information, such as personalized multi-turn dialogue, and measure whether performance still degrades relative to a teacher baseline or improves as predicted.
Figures















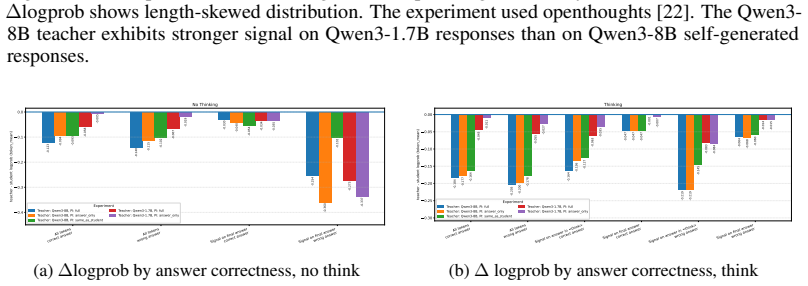


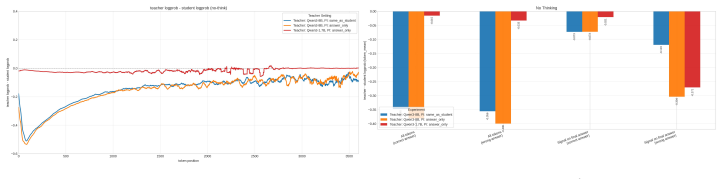



read the original abstract
On-policy distillation (OPD) and on-policy self-distillation (OPSD) have emerged as promising post-training methods for large language models, offering dense token-level supervision on trajectories sampled from the model's own policy. However, existing results on their effectiveness remain mixed: while OP(S)D has shown promise in system prompt and knowledge internalization, recent studies also report instability and degradation. In this work, we present a comprehensive empirical study of when OPD and OPSD work, when they fail, and why. We find that OPD on mathematical reasoning is highly sensitive to teacher choice and loss formulation, whereas OPSD fails in our tested settings due to test-time absence of instance-specific privileged information (PI). In contrast, OPSD is effective when PI represents a shared latent rule, such as a system prompt or alignment preference. We identify three failure mechanisms: (1) distribution mismatch between teacher and student caused by conditioning on student-generated prefixes, (2) optimization instability from biased TopK reverse-KL gradients, and (3) an OPSD-specific limitation where the student learns a PI-free policy that aggregates PI-conditioned teachers, which is insufficient when PI is instance-specific. We further show that stop-gradient TopK objectives, RLVR-adapted teachers, and SFT-stabilized students mitigate these failures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a comprehensive empirical study of on-policy distillation (OPD) and on-policy self-distillation (OPSD) for LLMs. It identifies three failure mechanisms—distribution mismatch from student-generated prefixes, optimization instability from biased TopK reverse-KL gradients, and OPSD-specific aggregation of PI-conditioned teachers into a PI-free policy when PI is instance-specific—and shows that these explain mixed prior results. The work focuses on mathematical reasoning trajectories and shared-latent PI (e.g., system prompts or alignment preferences), proposing and validating fixes via stop-gradient TopK objectives, RLVR-adapted teachers, and SFT-stabilized students, with ablations on teacher choice, loss formulation, and PI type.
Significance. If the mechanisms and fixes hold, this provides mechanistic insight into why OPD/OPSD results have been inconsistent, offering practical guidance for LLM post-training. The structured ablations and identification of specific pitfalls represent a useful contribution to understanding dense token-level supervision on self-generated trajectories. However, the restriction to math reasoning and shared PI settings means the work's broader impact depends on whether these failure modes generalize.
major comments (2)
- [Abstract and experimental results] Abstract and experimental results: The central claim that the three identified failure mechanisms explain mixed prior results on OPD/OPSD rests on the tested regimes (mathematical reasoning trajectories and system-prompt/alignment PI) being representative. No experiments are reported on other domains (e.g., general language modeling, code generation, or larger-scale models), leaving open the possibility that different token distributions or optimization landscapes produce distinct dominant failure modes.
- [Abstract] Abstract: The assertion that OPSD fails due to learning a PI-free policy that aggregates PI-conditioned teachers is load-bearing for the OPSD-specific limitation. However, the paper provides no quantitative measure (e.g., policy divergence or per-instance performance breakdown) of this aggregation effect, making it difficult to confirm that this is the primary cause rather than a symptom of other factors like data scale or conditioning.
minor comments (2)
- [Abstract] The abstract introduces OPD, OPSD, and PI without initial expansions or a brief definition, which reduces accessibility for readers outside the immediate subfield.
- [Abstract] The description of the fixes (stop-gradient TopK, RLVR teachers, SFT stabilization) would benefit from a short summary table comparing their effects across the ablations to improve clarity.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review of our manuscript. We address each major comment point by point below, indicating the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract and experimental results: The central claim that the three identified failure mechanisms explain mixed prior results on OPD/OPSD rests on the tested regimes (mathematical reasoning trajectories and system-prompt/alignment PI) being representative. No experiments are reported on other domains (e.g., general language modeling, code generation, or larger-scale models), leaving open the possibility that different token distributions or optimization landscapes produce distinct dominant failure modes.
Authors: We agree that the representativeness of our tested regimes is central to the broader claims. Mathematical reasoning was selected as the primary domain because it permits clean isolation of instance-specific versus shared privileged information, enabling precise diagnosis of the three failure mechanisms. We acknowledge that the absence of experiments on domains such as code generation or general language modeling leaves open the possibility of different dominant failure modes. In the revision we will expand the Limitations and Future Work section to explicitly discuss this scope limitation, qualify the central claim accordingly, and outline why the identified mechanisms (prefix mismatch, biased TopK gradients, and PI aggregation) are expected to be relevant beyond math while calling for targeted follow-up studies. revision: partial
-
Referee: [Abstract] Abstract: The assertion that OPSD fails due to learning a PI-free policy that aggregates PI-conditioned teachers is load-bearing for the OPSD-specific limitation. However, the paper provides no quantitative measure (e.g., policy divergence or per-instance performance breakdown) of this aggregation effect, making it difficult to confirm that this is the primary cause rather than a symptom of other factors like data scale or conditioning.
Authors: We thank the referee for this observation. The current manuscript supports the aggregation claim through comparative performance results and qualitative policy analysis in Section 4.3, but we agree that direct quantitative evidence would strengthen the argument. In the revised version we will add explicit metrics, including estimates of policy divergence (e.g., token-level KL between the student policy and each PI-conditioned teacher) and per-instance performance breakdowns that contrast shared-PI versus instance-specific-PI settings. These additions will help isolate the aggregation effect from confounding factors such as data scale. revision: yes
Circularity Check
No circularity: purely empirical identification of failure modes
full rationale
The paper presents a comprehensive empirical study of on-policy distillation and self-distillation, identifying three failure mechanisms and mitigation strategies through direct experiments on mathematical reasoning trajectories and system-prompt/alignment settings. No derivation chain, first-principles prediction, or mathematical reduction is claimed; all central claims rest on observed experimental comparisons (e.g., sensitivity to teacher choice, loss formulation, and presence/absence of instance-specific PI). No self-citations, fitted parameters renamed as predictions, or ansatzes are load-bearing. The analysis is self-contained against the reported benchmarks and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in supervised fine-tuning, reinforcement learning with verifiable rewards, and KL-regularized distillation hold for the loss formulations and sampling procedures used.
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self- generated mistakes, 2024
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self- generated mistakes, 2024
work page 2024
-
[2]
Minillm: On-policy distillation of large language models, 2026
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: On-policy distillation of large language models, 2026
work page 2026
-
[3]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
work page 2026
-
[4]
Mimo-v2-flash technical report, 2026
Core Team, Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, Gang Xie, Hailin Zhang, Hanglong Lv, Hanyu Li, Heyu Chen, Hongshen Xu, Houbin Zhang, Huaqiu Liu, Jiangshan Duo, Jianyu Wei, Jiebao Xiao, Jinhao Dong, Jun Shi, Junhao Hu, Kainan Bao, Kang Zhou, Lei Li, Liang Zhao, Linghao Zhang,...
work page 2026
-
[5]
On-policy distillation.Thinking Machines Lab: Connec- tionism, 2025
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Connec- tionism, 2025. https://thinkingmachines.ai/blog/on-policy-distillation
work page 2025
-
[6]
Self-distillation enables continual learning, 2026
Idan Shenfeld, Mehul Damani, Jonas H¨ubotter, and Pulkit Agrawal. Self-distillation enables continual learning, 2026
work page 2026
-
[7]
Self-distilled reasoner: On-policy self-distillation for large language models, 2026
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models, 2026
work page 2026
-
[8]
On-policy self-distillation for reasoning compression, 2026
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. On-policy self-distillation for reasoning compression, 2026
work page 2026
-
[9]
On-policy context distillation for language models, 2026
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models, 2026
work page 2026
-
[10]
Revisiting on-policy distillation: Empirical failure modes and simple fixes, 2026
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on-policy distillation: Empirical failure modes and simple fixes, 2026
work page 2026
-
[11]
Why does self-distillation (sometimes) degrade the reasoning capability of llms?, 2026
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of llms?, 2026
work page 2026
-
[12]
Learning by distilling context, 2022
Charlie Snell, Dan Klein, and Ruiqi Zhong. Learning by distilling context, 2022
work page 2022
-
[13]
Andrew Bagnell, Aarti Singh, and Andrea Zanette
Yuda Song, Lili Chen, Fahim Tajwar, Remi Munos, Deepak Pathak, J. Andrew Bagnell, Aarti Singh, and Andrea Zanette. Expanding the capabilities of reinforcement learning via text feedback, 2026
work page 2026
-
[14]
Pope: Learning to reason on hard problems via privileged on-policy exploration, 2026
Yuxiao Qu, Amrith Setlur, Virginia Smith, Ruslan Salakhutdinov, and Aviral Kumar. Pope: Learning to reason on hard problems via privileged on-policy exploration, 2026. 11
work page 2026
-
[15]
Rupam Mahmood, and Martha White
Alan Chan, Hugo Silva, Sungsu Lim, Tadashi Kozuno, A. Rupam Mahmood, and Martha White. Greedification operators for policy optimization: Investigating forward and reverse kl divergences, 2022
work page 2022
-
[16]
Characterbench: Benchmarking character customization of large language models, 2024
Jinfeng Zhou, Yongkang Huang, Bosi Wen, Guanqun Bi, Yuxuan Chen, Pei Ke, Zhuang Chen, Xiyao Xiao, Libiao Peng, Kuntian Tang, Rongsheng Zhang, Le Zhang, Tangjie Lv, Zhipeng Hu, Hongning Wang, and Minlie Huang. Characterbench: Benchmarking character customization of large language models, 2024
work page 2024
-
[17]
Jen tse Huang, Man Ho Lam, Eric John Li, Shujie Ren, Wenxuan Wang, Wenxiang Jiao, Zhaopeng Tu, and Michael R. Lyu. Emotionally numb or empathetic? evaluating how llms feel using emotionbench, 2024
work page 2024
-
[18]
Crisp: Compressed reasoning via iterative self-policy distillation, 2026
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. Crisp: Compressed reasoning via iterative self-policy distillation, 2026
work page 2026
-
[19]
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms, 2024
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms, 2024
work page 2024
-
[20]
Dapo: An open-source llm reinforcement learning system at scale, 2025
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page 2025
-
[21]
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe, 2026
work page 2026
-
[22]
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, Liangyu Chen, Zaid Khan, Eric Frankel, Sachin Grover, Caroline Choi, Niklas Muennighoff, Shiye Su, Wanjia Zhao, John Yang, Shreyas Pimpalgaonkar, Kartik Sharma, Charlie Cheng-Jie Ji, ...
work page 2025
-
[23]
Demystifying OPD: Length Inflation and Stabilization Strategies for Large Language Models
Feng Luo, Yu-Neng Chuang, Guanchu Wang, Zicheng Xu, Xiaotian Han, Tianyi Zhang, and Vladimir Braverman. Demystifying opd: Length inflation and stabilization strategies for large language models.arXiv preprint arXiv:2604.08527, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Reinforcement learning via self-distillation, 2026
Jonas H ¨ubotter, Frederike L ¨ubeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation, 2026
work page 2026
-
[25]
Openclaw-rl: Train any agent simply by talking, 2026
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. Openclaw-rl: Train any agent simply by talking, 2026
work page 2026
-
[26]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
work page 2017
-
[27]
Persuasion for good: Towards a personalized persuasive dialogue system for social good
Xuewei Wang, Weiyan Shi, Richard Kim, Yoojung Oh, Sijia Yang, Jingwen Zhang, and Zhou Yu. Persuasion for good: Towards a personalized persuasive dialogue system for social good. arXiv preprint arXiv:1906.06725, 2019
-
[28]
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models, 2026. 12 A Appendix A.1 Experiment Setup We use a maximum response length of16384, temperature1.0, and top-p0.95for evaluation. Table 1 summarizes the main hyperparameters for OPD,...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.