Recognition: unknown
Instructions Shape Production of Language, not Processing
Pith reviewed 2026-05-14 20:58 UTC · model grok-4.3
The pith
Instructions primarily shape how language models produce outputs rather than how they process inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Instructions trigger a production-centered mechanism in language models. Through layer-wise probing of task-specific information across five binary judgment tasks, the information in sample tokens remains largely stable across prompting variations and correlates only weakly with behavior, whereas the information in output tokens varies substantially and correlates strongly with behavior. Attention-based interventions confirm this causally by showing that blocking instruction flow to all subsequent tokens reduces both behavior and information in output tokens, whereas blocking it only to sample tokens has minimal effect. The asymmetry generalizes across model families and tasks and becomes sh
What carries the argument
Layer-wise probing of task-specific information at sample versus output token positions, combined with attention-based blocking of instruction flow to isolate effects on production.
If this is right
- Task-specific information in output tokens predicts model behavior more reliably than the same information in input sample tokens.
- Blocking instruction signals from reaching output tokens reduces both information content and task performance.
- The production-centered asymmetry grows stronger in larger models and in models that have undergone instruction tuning.
- Assessing model capabilities requires measuring both internal representations and observable behavior while separating input processing from output production.
Where Pith is reading between the lines
- Prompt engineering may work mainly by steering the generation steps rather than by changing how inputs are understood.
- The same processing-production split could appear in other sequential tasks such as code generation or planning.
- Disrupting output pathways in isolation might reveal instruction sensitivity even when input encoding remains intact.
Load-bearing premise
The layer-wise probing isolates task-specific information at specific token positions without interference from other positions or model components, and the attention blocking cleanly separates instruction effects on sample versus output tokens.
What would settle it
If blocking instruction flow only to sample tokens were found to substantially alter model behavior or the task-specific information present in output tokens, that would falsify the claimed separation between processing and production effects.
Figures















read the original abstract
Instructions trigger a production-centered mechanism in language models. Through a cognitively inspired lens that separates language processing and production, we reveal this mechanism as an asymmetry between the two stages by probing task-specific information layer-wise across five binary judgment tasks. Specifically, we measure how instruction tokens shape information both when sample tokens, the input under evaluation, are processed and when output tokens are produced. Across prompting variations, task-specific information in sample tokens remains largely stable and correlates only weakly with behavior, whereas the same information in output tokens varies substantially and correlates strongly with behavior. Attention-based interventions confirm this pattern causally: blocking instruction flow to all subsequent tokens reduces both behavior and information in output tokens, whereas blocking it only to sample tokens has minimal effect on either. The asymmetry generalizes across model families and tasks, and becomes sharper with model scale and instruction-tuning, both of which disproportionately affect the production stage. Our findings suggest that understanding model capabilities requires jointly assessing internals and behavior, while decomposing the internal perspective by token position to distinguish the processing of input tokens from the production of output tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that instructions in language models primarily shape the production of output tokens rather than the processing of sample tokens. Layer-wise probing across five binary judgment tasks shows task-specific information in sample tokens remains largely stable with only weak behavioral correlation, while the same information in output tokens varies substantially and correlates strongly with behavior. Attention-based blocking interventions confirm the asymmetry causally: blocking instruction flow to all subsequent tokens reduces both behavior and output-token information, whereas blocking it only to sample tokens has minimal effect. The pattern generalizes across model families and sharpens with scale and instruction-tuning.
Significance. If the central asymmetry holds, the work offers a useful decomposition of LLM behavior into processing versus production stages, supported by both correlational probing and causal interventions. The cross-model generalization and the observation that effects strengthen with scale and tuning provide concrete, falsifiable predictions that could inform future analyses of instruction following. The empirical focus on token-position-specific information flow is a strength.
major comments (2)
- [Intervention results] Intervention description (likely §3.2): zeroing attention from instruction positions to sample tokens does not remove the instruction hidden states from the residual stream; residual connections and subsequent feed-forward layers can still propagate task-specific information to output positions. This undercuts the claim that minimal behavioral change demonstrates instructions bypass sample-token processing.
- [Probing analysis] Probing results (likely §4.1): the reported stability of task-specific information in sample tokens and its weak correlation with behavior rests on the assumption that layer-wise probes isolate position-specific signals without leakage from other token positions or residual components; no ablation of this assumption is described.
minor comments (2)
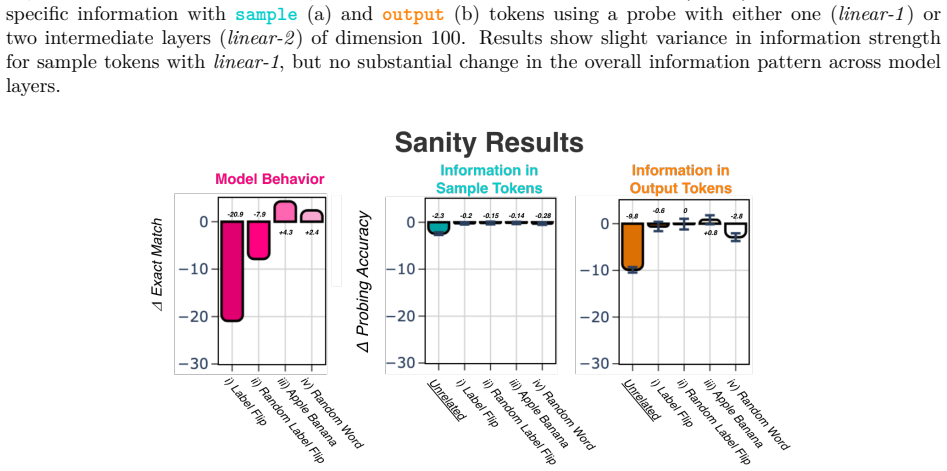
- [Figures] Include error bars or confidence intervals on all layer-wise probing and behavioral plots to allow assessment of the reported stability and correlations.
- [Results] Clarify the exact set of models and tasks in the generalization section; the abstract mentions five tasks and multiple families but the main text should list them explicitly with sample sizes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, providing our strongest honest defense of the manuscript while noting where clarifications or additions will improve the work.
read point-by-point responses
-
Referee: [Intervention results] Intervention description (likely §3.2): zeroing attention from instruction positions to sample tokens does not remove the instruction hidden states from the residual stream; residual connections and subsequent feed-forward layers can still propagate task-specific information to output positions. This undercuts the claim that minimal behavioral change demonstrates instructions bypass sample-token processing.
Authors: We appreciate the referee's careful analysis of the intervention mechanics. However, the design and results still support the production-centered interpretation. Zeroing attention from instruction positions specifically to sample tokens prevents direct attention-based incorporation of instruction signals into sample-token representations. The preserved instruction hidden states in the residual stream enable direct influence on output positions (via subsequent attention from output tokens to instruction tokens), which is precisely the bypass of sample-token processing that our claim describes. The key evidence is the asymmetry: blocking instruction flow only to sample tokens yields minimal change in behavior and output information, while blocking to all subsequent tokens (including output positions) produces large reductions. This pattern indicates that task-specific information need not be routed through sample processing. We will add a clarifying paragraph in the revised §3.2 explicitly discussing residual propagation and distinguishing direct versus indirect pathways. revision: partial
-
Referee: [Probing analysis] Probing results (likely §4.1): the reported stability of task-specific information in sample tokens and its weak correlation with behavior rests on the assumption that layer-wise probes isolate position-specific signals without leakage from other token positions or residual components; no ablation of this assumption is described.
Authors: We agree that an explicit check for position-specific isolation would strengthen the probing results. Although the probes are trained exclusively on activations extracted from designated sample or output token positions, residual-stream mixing could introduce some leakage. In the revision we will add an ablation subsection (new §4.2) that (i) trains control probes on randomly shuffled or masked position activations and (ii) reports cross-position probe accuracy and mutual information. These controls will quantify any leakage and confirm that the reported stability in sample tokens and strong correlation in output tokens are position-dependent. revision: yes
Circularity Check
No circularity: claims rest on direct empirical measurements and interventions
full rationale
The paper presents no mathematical derivation chain or fitted model whose outputs are forced by its own inputs. Its central claims follow from layer-wise probing of task-specific information (measured via classifiers on hidden states) and attention-masking interventions performed on five binary judgment tasks across model families. These are experimental observations of stability in sample-token representations versus variability in output-token representations, with causal tests via blocking. No equation reduces a prediction to a fitted parameter by construction, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled in. The work is self-contained against external benchmarks (multiple tasks, scales, and model families) and therefore receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task-specific information can be measured from layer-wise activations in a way that distinguishes processing from production stages.
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Workshop Track Proceedings . OpenReview.net, 2017. URL https://openreview.net/forum?id=HJ4-rAVtl
2017
-
[2]
The mighty torr: A benchmark for table reasoning and robustness
Shir Ashury-Tahan, Yifan Mai, Ariel Gera, Yotam Perlitz, Asaf Yehudai, Elron Bandel, Leshem Choshen, Eyal Shnarch, Percy Liang, Michal Shmueli-Scheuer, et al. The mighty torr: A benchmark for table reasoning and robustness. arXiv preprint arXiv:2502.19412, 2025
-
[3]
Robustness as an emergent property of task performance
Shir Ashury-Tahan, Ariel Gera, Elron Bandel, Michal Shmueli-Scheuer, and Leshem Choshen. Robustness as an emergent property of task performance. arXiv preprint arXiv:2602.03344, 2026
-
[4]
The internal state of an LLM knows when it ' s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it ' s lying. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 967--976, Singapore, December 2023. Association for Computational Linguistics. doi:10.18653/v1/2023.findings-emnlp.68. URL https://aclanthology....
-
[5]
Computational Linguistics , year =
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics, 48 0 (1): 0 207--219, March 2022. doi:10.1162/coli_a_00422. URL https://aclanthology.org/2022.cl-1.7/
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[6]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia: A suite for analyzing large language models across training and scaling. In Andreas Krause, Emma Brunskill, Kyung...
2023
-
[8]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. In International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=ETKGuby0hcs
work page 2023
-
[10]
Aspects of the Theory of Syntax
Noam Chomsky. Aspects of the Theory of Syntax. The MIT Press, Cambridge, 1965. URL http://www.amazon.com/Aspects-Theory-Syntax-Noam-Chomsky/dp/0262530074
-
[11]
What you can cram into a single \ &!\#* vector:
Alexis Conneau, German Kruszewski, Guillaume Lample, Lo \"i c Barrault, and Marco Baroni. What you can cram into a single \ & ! \# * vector: Probing sentence embeddings for linguistic properties. In Iryna Gurevych and Yusuke Miyao (eds.), Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ ...
-
[13]
Cours de linguistique g \'e n \'e rale
Ferdinand de Saussure. Cours de linguistique g \'e n \'e rale . Payot, Paris, 1916. URL https://books.google.ch/books?id=B38KAQAAMAAJ
work page 1916
-
[14]
A spreading-activation theory of retrieval in sentence production
Gary Dell. A spreading-activation theory of retrieval in sentence production. Psychological Review, 93: 0 283--321, 07 1986. doi:10.1037/0033-295X.93.3.283
-
[15]
Robert Desimone and John S. Duncan. Neural mechanisms of selective visual attention. Annual review of neuroscience, 18: 0 193--222, 1995. URL https://api.semanticscholar.org/CorpusID:14290580
work page 1995
-
[16]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al - Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aur \' e lien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Rozi \` e...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[17]
Monitoring latent world states in language models with propositional probes
Jiahai Feng, Stuart Russell, and Jacob Steinhardt. Monitoring latent world states in language models with propositional probes. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=0yvZm2AjUr
work page 2025
-
[18]
Clémentine Fourrier, Nathan Habib, Alina Lozovskaya, Konrad Szafer, and Thomas Wolf. Open llm leaderboard v2. https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard, 2024
work page 2024
-
[19]
Inside-out: Hidden factual knowledge in LLM s
Zorik Gekhman, Eyal Ben-David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpektor, Jonathan Herzig, and Roi Reichart. Inside-out: Hidden factual knowledge in LLM s. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=f7GG1MbsSM
work page 2025
-
[20]
Estimating knowledge in large language models without generating a single token
Daniela Gottesman and Mor Geva. Estimating knowledge in large language models without generating a single token. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 3994--4019, Miami, Florida, USA, November 2024. Association for Computational Linguistics....
-
[24]
Juyeon Heo, Christina Heinze-Deml, Oussama Elachqar, Kwan Ho Ryan Chan, Shirley You Ren, Andrew Miller, Udhyakumar Nallasamy, and Jaya Narain. Do LLM s ``know'' internally when they follow instructions? In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=qIN5VDdEOr
work page 2025
-
[25]
Designing and Interpreting Probes with Control Tasks
John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp.\ 2733--2743, Hong Kong, Chin...
-
[26]
John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pp.\ 4129--413...
-
[27]
Surface form competition: Why the highest probability answer isn ' t always right
Ari Holtzman, Peter West, Vered Shwartz, Yejin Choi, and Luke Zettlemoyer. Surface form competition: Why the highest probability answer isn ' t always right. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp.\ 7038--7051, Online an...
-
[28]
Auxiliary task demands mask the capabilities of smaller language models
Jennifer Hu and Michael Frank. Auxiliary task demands mask the capabilities of smaller language models. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=U5BUzSn4tD
work page 2024
-
[30]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, L \' e lio Renard Lavaud, Lucile Saulnier, Marie - Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.04088 2024
-
[31]
Discourse probing of pretrained language models
Fajri Koto, Jey Han Lau, and Timothy Baldwin. Discourse probing of pretrained language models. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou (eds.), Proceedings of the 2021 Conference of the North American Chapter of the Association for Computatio...
-
[32]
Revisiting the evaluation of theory of mind through question answering
Matthew Le, Y-Lan Boureau, and Maximilian Nickel. Revisiting the evaluation of theory of mind through question answering. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJ...
-
[33]
Language Models Struggle to Use Representations Learned In-Context
Michael A. Lepori, Tal Linzen, Ann Yuan, and Katja Filippova. Language models struggle to use representations learned in-context. 2026. URL https://arxiv.org/abs/2602.04212
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Juncai Li, Ru Li, Xiaoli Li, Qinghua Chai, and Jeff Z. Pan. Inference helps PLM s' conceptual understanding: Improving the abstract inference ability with hierarchical conceptual entailment graphs. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 22088...
-
[37]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT . In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, Novem...
work page 2022
-
[38]
Earl K. Miller and Jonathan D. Cohen. An integrative theory of prefrontal cortex function. Annual review of neuroscience, 24: 0 167--202, 2001. URL https://api.semanticscholar.org/CorpusID:7301474
work page 2001
-
[40]
State of what art? a call for multi-prompt LLM evaluation
Moran Mizrahi, Guy Kaplan, Dan Malkin, Rotem Dror, Dafna Shahaf, and Gabriel Stanovsky. State of what art? a call for multi-prompt LLM evaluation. Transactions of the Association for Computational Linguistics, 12: 0 933--949, 2024. doi:10.1162/tacl_a_00681. URL https://aclanthology.org/2024.tacl-1.52/
-
[42]
S tereo S et: Measuring stereotypical bias in pretrained language models
Moin Nadeem, Anna Bethke, and Siva Reddy. S tereo S et: Measuring stereotypical bias in pretrained language models. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: ...
-
[43]
Large language diffusion models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, JUN ZHOU, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=KnqiC0znVF
work page 2026
-
[45]
LLM s know more than they show: On the intrinsic representation of LLM hallucinations
Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. LLM s know more than they show: On the intrinsic representation of LLM hallucinations. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=KRnsX5Em3W
work page 2025
-
[46]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human fee...
work page 2022
-
[47]
Improving language understanding by generative pre-training
Alec Radford and Karthik Narasimhan. Improving language understanding by generative pre-training. 2018. URL https://api.semanticscholar.org/CorpusID:49313245
work page 2018
-
[48]
Recognition memory for syntactic and semantic aspects of connected discourse
Jacqueline Strunk Sachs. Recognition memory for syntactic and semantic aspects of connected discourse. Perception & Psychophysics, 2 0 (9): 0 437--442, 1967
work page 1967
-
[49]
Carson T. Schütze. The empirical base of linguistics . Number 2 in Classics in Linguistics. Language Science Press, Berlin, 2016. doi:10.17169/langsci.b89.100
-
[50]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models' sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt formatting. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024. URL https://openreview...
work page 2024
-
[51]
Aviv Slobodkin, Omer Goldman, Avi Caciularu, Ido Dagan, and Shauli Ravfogel. The curious case of hallucinatory (un)answerability: Finding truths in the hidden states of over-confident large language models. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 3607...
-
[52]
o LM pics-on what language model pre-training captures
Alon Talmor, Yanai Elazar, Yoav Goldberg, and Jonathan Berant. o LM pics-on what language model pre-training captures. Transactions of the Association for Computational Linguistics, 8: 0 743--758, 2020. doi:10.1162/tacl_a_00342. URL https://aclanthology.org/2020.tacl-1.48/
-
[53]
BERT Rediscovers the Classical NLP Pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. BERT rediscovers the classical NLP pipeline. In Anna Korhonen, David Traum, and Llu \'i s M \`a rquez (eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp.\ 4593--4601, Florence, Italy, July 2019 a . Association for Computational Linguistics. doi:10.18653/v1/P19-14...
-
[54]
Thomas McCoy, Najoung Kim, Benjamin Van Durme, Samuel R
Ian Tenney, Patrick Xia, Berlin Chen, Alex Wang, Adam Poliak, R. Thomas McCoy, Najoung Kim, Benjamin Van Durme, Samuel R. Bowman, Dipanjan Das, and Ellie Pavlick. What do you learn from context? probing for sentence structure in contextualized word representations. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, US...
work page 2019
-
[55]
Function vectors in large language models
Eric Todd, Millicent Li, Arnab Sen Sharma, Aaron Mueller, Byron C Wallace, and David Bau. Function vectors in large language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=AwyxtyMwaG
work page 2024
-
[58]
The curve of learning with and without instructions
Leendert Van Maanen, Yuyao Zhang, Maarten De Schryver, and Baptist Liefooghe. The curve of learning with and without instructions. Journal of Cognition, 7 0 (1): 0 48, 2024
work page 2024
-
[59]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 30: Annual Conference o...
work page 2017
-
[60]
Information-Theoretic Probing with Minimum Description Length
Elena Voita and Ivan Titov. Information-theoretic probing with minimum description length. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 183--196, Online, November 2020. Association for Computational Linguistics. doi:10.18653/v1/2020.emnlp-...
-
[63]
Smith, and Hannaneh Hajishirzi
Evan Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Allyson Ettinger, Michal Guerquin, David Heineman, Hamish Ivison, Pang Wei Koh, Jiacheng...
work page 2025
-
[64]
Alex Warstadt, Alicia Parrish, Haokun Liu, Anhad Mohananey, Wei Peng, Sheng-Fu Wang, and Samuel R. Bowman. BL i MP : The benchmark of linguistic minimal pairs for E nglish. Transactions of the Association for Computational Linguistics, 8: 0 377--392, 2020. doi:10.1162/tacl_a_00321. URL https://aclanthology.org/2020.tacl-1.25/
-
[65]
Albert Webson and Ellie Pavlick. Do prompt-based models really understand the meaning of their prompts? In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz (eds.), Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp.\ 2300--2344, Seattle,...
-
[66]
Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M
Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. Finetuned language models are zero-shot learners. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net, 2022. URL https://openreview.net/forum?id=gEZrGCozdqR
work page 2022
-
[68]
Calibrate before use: Improving few-shot performance of language models
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate before use: Improving few-shot performance of language models. In Proceedings of the 38th International Conference on Machine Learning, 2021. URL https://proceedings.mlr.press/v139/zhao21c.html
work page 2021
-
[69]
LIMA : Less is more for alignment
Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, LILI YU, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. LIMA : Less is more for alignment. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=KBMOKmX2he
work page 2023
-
[70]
P ro SA : Assessing and understanding the prompt sensitivity of LLM s
Jingming Zhuo, Songyang Zhang, Xinyu Fang, Haodong Duan, Dahua Lin, and Kai Chen. P ro SA : Assessing and understanding the prompt sensitivity of LLM s. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 1950--1976, Miami, Florida, USA, November 2024. Association for Com...
-
[71]
International Conference on Learning Representations , year =
Collin Burns and Haotian Ye and Dan Klein and Jacob Steinhardt , title =. International Conference on Learning Representations , year =
-
[72]
Jianhao Jiang and Yaoru Dong and Junqi Zhou and Zhiqiang Zhu , title =. 2025 , url =
work page 2025
-
[73]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
work page 2023
-
[74]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Large Language Diffusion Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
- [75]
-
[76]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov , editor =. Locating and Editing Factual Associations in. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022 , year =
work page 2022
-
[77]
In-Context Learning Creates Task Vectors
Hendel, Roee and Geva, Mor and Globerson, Amir. In-Context Learning Creates Task Vectors. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.624
-
[78]
In-context Learning and Induction Heads
Catherine Olsson and Nelson Elhage and Neel Nanda and Nicholas Joseph and Nova DasSarma and Tom Henighan and Ben Mann and Amanda Askell and Yuntao Bai and Anna Chen and Tom Conerly and Dawn Drain and Deep Ganguli and Zac Hatfield. In-context Learning and Induction Heads , journal =. 2022 , url =. doi:10.48550/ARXIV.2209.11895 , eprinttype =. 2209.11895 , ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.11895 2022
-
[79]
The Twelfth International Conference on Learning Representations , year =
Bill Yuchen Lin and Abhilasha Ravichander and Xi Lu and Nouha Dziri and Melanie Sclar and Khyathi Chandu and Chandra Bhagavatula and Yejin Choi , title =. The Twelfth International Conference on Learning Representations , year =
-
[80]
The Twelfth International Conference on Learning Representations , year =
Nikhil Prakash and Tamar Rott Shaham and Tal Haklay and Yonatan Belinkov and David Bau , title =. The Twelfth International Conference on Learning Representations , year =
-
[81]
Proceedings of the 38th International Conference on Machine Learning , year =
Zihao Zhao and Eric Wallace and Shi Feng and Dan Klein and Sameer Singh , title =. Proceedings of the 38th International Conference on Machine Learning , year =
-
[82]
International Conference on Learning Representations , year=
Finetuned Language Models are Zero-Shot Learners , author=. International Conference on Learning Representations , year=
-
[83]
Chunting Zhou and Pengfei Liu and Puxin Xu and Srini Iyer and Jiao Sun and Yuning Mao and Xuezhe Ma and Avia Efrat and Ping Yu and LILI YU and Susan Zhang and Gargi Ghosh and Mike Lewis and Luke Zettlemoyer and Omer Levy , booktitle=. 2023 , url=
work page 2023
-
[84]
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
Min, Sewon and Lyu, Xinxi and Holtzman, Ari and Artetxe, Mikel and Lewis, Mike and Hajishirzi, Hannaneh and Zettlemoyer, Luke. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.759
-
[85]
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus. Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.556
-
[86]
arXiv preprint arXiv:2404.03028 , year =
Instruction Inference: Understanding How Language Models Interpret Instructions , author =. arXiv preprint arXiv:2404.03028 , year =
-
[87]
Juyeon Heo and Christina Heinze-Deml and Oussama Elachqar and Kwan Ho Ryan Chan and Shirley You Ren and Andrew Miller and Udhyakumar Nallasamy and Jaya Narain , booktitle=. Do. 2025 , url=
work page 2025
-
[88]
A Pipeline to Assess Merging Methods via Behavior and Internals , author =. CoRR , volume =. 2025 , url =
work page 2025
-
[89]
Efficient Estimation of Word Representations in Vector Space , booktitle =
Tomas Mikolov and Kai Chen and Greg Corrado and Jeffrey Dean , editor =. Efficient Estimation of Word Representations in Vector Space , booktitle =. 2013 , url =
work page 2013
- [90]
-
[91]
The Neuroscience of Language: On Brain Circuits of Words and Serial Order , author=. 2002 , publisher=
work page 2002
-
[92]
arXiv preprint arXiv:2310.10348 , year=
Aaquib Syed and Can Rager and Arthur Conmy , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.10348 , eprinttype =. 2310.10348 , timestamp =
-
[93]
Forty-first International Conference on Machine Learning,
Reduan Achtibat and Sayed Mohammad Vakilzadeh Hatefi and Maximilian Dreyer and Aakriti Jain and Thomas Wiegand and Sebastian Lapuschkin and Wojciech Samek , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
work page 2024
- [94]
- [95]
- [96]
-
[97]
The History and Theory of Rhetoric: An Introduction (Subscription) , author=. 2015 , publisher=
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.