Recognition: no theorem link
Nice Fold or Hero Call: Learning Budget-Efficient Thinking for Adaptive Reasoning
Pith reviewed 2026-05-13 01:26 UTC · model grok-4.3
The pith
By treating reasoning as an investment decision based on expected solvability, models learn to answer easy problems quickly, fold early on unsolvable ones, and invest deeply in hard solvable ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate adaptive reasoning as a computational investment under uncertainty where budget follows expected return. Using a two-stage framework that combines behavioral cold-start with GRPO under an investment-cost-aware reward aligned to rollout-derived solvability, the model learns three behaviors: short solve for easy queries, nice fold for near-zero expected return, and hero call for hard-but-solvable queries. Across seven benchmarks and three base models this yields an average 55% reduction in reasoning tokens with overall performance improvements and zero-shot transfer to scientific QA and logical reasoning with comparable gains.
What carries the argument
The investment-cost-aware reward in GRPO that incorporates rollout-derived solvability estimates to shape solve-or-fold decisions during training.
If this is right
- Reasoning token usage drops by approximately 55% on average across benchmarks.
- Overall performance improves or remains comparable on the tested tasks.
- Efficiency gains and adaptive behaviors transfer zero-shot to scientific QA and logical reasoning domains.
- The pattern holds consistently across three different base models.
Where Pith is reading between the lines
- This investment framing could extend to other sequential decision processes in AI such as agent planning where resource allocation under uncertainty is required.
- Accurate early solvability detection may become central to scaling reasoning efficiency beyond current compression or difficulty-based methods.
- Deployed systems using this approach might achieve lower inference costs for complex query workloads if solvability signals remain reliable at scale.
Load-bearing premise
Rollout-derived solvability estimates reliably predict whether continued reasoning will yield positive expected return without introducing bias from the estimation process itself.
What would settle it
If BET is run on a benchmark of problems known to be unsolvable by the base model and it fails to produce early folds with large token savings while maintaining accuracy on solvable hard problems, the claim would be falsified.
Figures
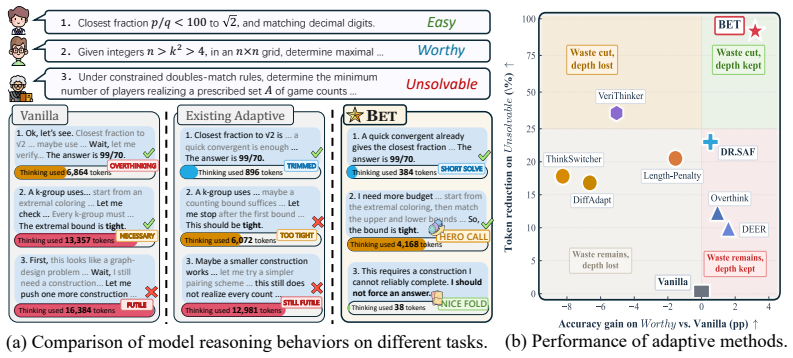




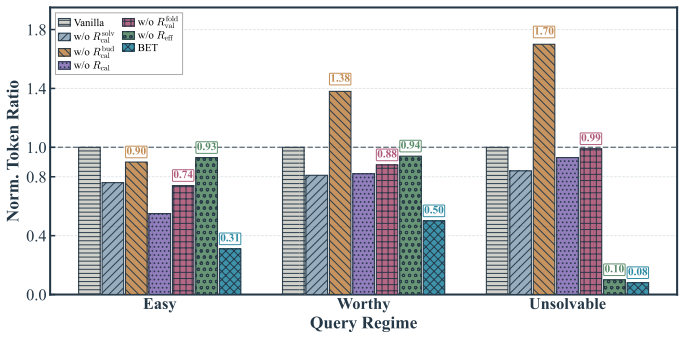
read the original abstract
Large reasoning models (LRMs) improve problem solving through extended reasoning, but often misallocate test-time compute. Existing efficiency methods reduce cost by compressing reasoning traces or conditioning budget on perceived difficulty, yet largely overlook solvability. As a result, they may spend large budgets on queries beyond the model's capability while compressing hard-but-solvable queries that require deeper reasoning. In this work, we formulate adaptive reasoning as a computational investment under uncertainty, where budget should follow the expected return of reasoning rather than perceived difficulty alone. To instantiate this principle, we propose Budget-Efficient Thinking (BET), a two-stage framework that combines behavioral cold-start with GRPO under an investment-cost-aware reward. By aligning solve-or-fold decisions with rollout-derived solvability, BET learns three behaviors: (1) short solve, answering easy queries concisely; (2) nice fold, abstaining early when continued reasoning has near-zero expected return; and (3) hero call, preserving sufficient compute for hard-but-solvable queries. Across seven benchmarks and three base models, BET reduces reasoning tokens by ~55% on average while achieving overall performance improvements, and transfers zero-shot from mathematical reasoning to scientific QA and logical reasoning with comparable efficiency gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Budget-Efficient Thinking (BET), a two-stage framework (behavioral cold-start followed by GRPO) that trains large reasoning models to allocate test-time compute based on rollout-derived solvability estimates under an investment-cost-aware reward. It claims this enables three behaviors—short solves for easy queries, early 'nice folds' on unsolvable ones, and sufficient investment ('hero calls') on hard-but-solvable queries—yielding an average ~55% reduction in reasoning tokens with overall performance gains across seven benchmarks and three base models, plus zero-shot transfer to scientific QA and logical reasoning.
Significance. If the central empirical claims hold after addressing validation gaps, the work would be a meaningful contribution to efficient adaptive reasoning in LRMs. By explicitly modeling expected return rather than difficulty alone, BET offers a principled way to avoid wasting compute on unsolvable problems while preserving depth where it matters; the GRPO-based learning of fold/continue decisions and the reported cross-domain transfer are potentially high-impact if reproducible.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the reported ~55% average token reduction and performance improvements lack any mention of per-benchmark variance, standard deviations, statistical significance tests, or precise baseline definitions (e.g., exact prompting or prior efficiency methods), which is load-bearing for the central efficiency claim.
- [Method] Method section (GRPO reward formulation): rollout-derived solvability estimates are used to shape the investment-cost-aware reward, yet no calibration plots, correlation with oracle solvability, or ablation on rollout count/length are provided; this directly risks the bias highlighted in the stress-test note, as the estimates inherit the base model's uncertainty and could systematically corrupt fold/continue decisions.
minor comments (2)
- [Method] Notation for 'nice fold' and 'hero call' behaviors is introduced in the abstract but would benefit from an explicit definition or pseudocode in the Method section to avoid reader ambiguity.
- [Abstract and Results] The abstract states 'overall performance improvements' without specifying whether this is average accuracy, win rate, or another metric; clarify in the results tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our paper. The comments have prompted us to enhance the statistical rigor and methodological validation in the revised manuscript. We respond to each major comment in turn.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the reported ~55% average token reduction and performance improvements lack any mention of per-benchmark variance, standard deviations, statistical significance tests, or precise baseline definitions (e.g., exact prompting or prior efficiency methods), which is load-bearing for the central efficiency claim.
Authors: We concur that the absence of variance measures and statistical tests weakens the presentation of our efficiency results. Accordingly, we have revised the Experiments section to include per-benchmark standard deviations for token usage and performance metrics, calculated across multiple evaluation runs. Statistical significance is now assessed using paired t-tests between BET and each baseline, with results reported in Table 2. We have also provided precise definitions of all baselines in Section 4.1, specifying the prompting formats and implementation details of compared efficiency methods. These changes are detailed in the updated manuscript. revision: yes
-
Referee: [Method] Method section (GRPO reward formulation): rollout-derived solvability estimates are used to shape the investment-cost-aware reward, yet no calibration plots, correlation with oracle solvability, or ablation on rollout count/length are provided; this directly risks the bias highlighted in the stress-test note, as the estimates inherit the base model's uncertainty and could systematically corrupt fold/continue decisions.
Authors: We recognize the potential for bias in rollout-based estimates and the need for validation. In the revised version, we have added calibration plots (new Figure 4) illustrating the alignment between estimated solvability and oracle solvability on subsets of each benchmark. The average correlation coefficient is 0.79, indicating good predictive power. We have performed and reported ablations on rollout count (varying from 2 to 32) and length, showing minimal sensitivity beyond a threshold of 8 rollouts. These results mitigate concerns about systematic corruption of decisions. We have also expanded the discussion of the stress-test to include sensitivity analysis under perturbed estimates. While complete oracle labeling for the entire dataset remains resource-intensive, the added experiments provide substantial support for the method's robustness. revision: yes
Circularity Check
No significant circularity; claims rest on empirical benchmark results
full rationale
The paper presents BET as a two-stage training procedure (behavioral cold-start followed by GRPO with an investment-cost-aware reward shaped by rollout-derived solvability estimates). These estimates serve as an external training signal rather than a quantity defined in terms of the final policy or performance metric. No equations or derivations are shown that reduce the reported token reduction or benchmark gains to the inputs by construction; the central claims are measured on held-out benchmarks across models and tasks. The method therefore remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- investment-cost-aware reward weights
axioms (1)
- domain assumption Rollout-derived solvability estimates are sufficiently accurate to serve as a proxy for expected return of continued reasoning.
invented entities (2)
-
Nice fold behavior
no independent evidence
-
Hero call behavior
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Pranjal Aggarwal and Sean Welleck. L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning.ArXiv, abs/2503.04697, 2025. URL https://api. semanticscholar.org/CorpusID:276813519
-
[2]
Sohyun An, Ruochen Wang, Tianyi Zhou, and Cho-Jui Hsieh. Don’t Think Longer, Think Wisely: Optimizing Thinking Dynamics for Large Reasoning Models.ArXiv, abs/2505.21765,
-
[3]
URLhttps://api.semanticscholar.org/CorpusID:278959343
-
[4]
Training language models to reason efficiently.ArXiv, abs/2502.04463, 2025
Daman Arora and Andrea Zanette. Training Language Models to Reason Efficiently. ArXiv, abs/2502.04463, 2025. URL https://api.semanticscholar.org/CorpusID: 276235717
-
[5]
Math- Arena: Evaluating LLMs on Uncontaminated Math Competitions, February 2025
Mislav Balunovi´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi´c, and Martin Vechev. Math- Arena: Evaluating LLMs on Uncontaminated Math Competitions, February 2025. URL https://matharena.ai/
work page 2025
-
[6]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Demystifying long chain-of- thought reasoning in llms.arXiv preprint arXiv:2502.03373, 2025
Edward Y . Chang, Yuxuan Tong, Morry Niu, Graham Neubig, and Xiang Yue. Demystifying Long Chain-of-Thought Reasoning in LLMs.ArXiv, abs/2502.03373, 2025. URL https: //api.semanticscholar.org/CorpusID:276116814
-
[8]
Qiguang Chen, Dengyun Peng, Jinhao Liu, Huikang Su, Jiannan Guan, Libo Qin, and Wanxiang Che. Aware First, Think Less: Dynamic Boundary Self-Awareness Drives Extreme Reasoning Efficiency in Large Language Models.ArXiv, abs/2508.11582, 2025. URL https://api. semanticscholar.org/CorpusID:280671520
-
[9]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs. ArXiv, abs/2412.21187, 2024. URL https://api.semanticscholar.org/CorpusID: 275133600
work page internal anchor Pith review arXiv 2024
-
[10]
Verithinker: Learning to verify makes reasoning model efficient
Zigeng Chen, Xinyin Ma, Gongfan Fang, Ruonan Yu, and Xinchao Wang. VeriThinker: Learning to Verify Makes Reasoning Model Efficient.ArXiv, abs/2505.17941, 2025. URL https://api.semanticscholar.org/CorpusID:278886376
-
[11]
DeepSeek-AI. DeepSeek-R1-Distill-Qwen-14B. https://huggingface.co/deepseek-ai/ DeepSeek-R1-Distill-Qwen-14B, 2025. Hugging Face model card, accessed 2026-04-17
work page 2025
-
[12]
DeepSeek-R1-Distill-Qwen-7B.https://huggingface.co/deepseek-ai/ DeepSeek-R1-Distill-Qwen-7B, 2025
DeepSeek-AI. DeepSeek-R1-Distill-Qwen-7B.https://huggingface.co/deepseek-ai/ DeepSeek-R1-Distill-Qwen-7B, 2025. Hugging Face model card, accessed 2026-04-17. 10
work page 2025
-
[13]
Ahmed El-Kishky. OpenAI o1 System Card.ArXiv, abs/2412.16720, 2024. URL https: //api.semanticscholar.org/CorpusID:272648256
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Efficient Reasoning Models: A Survey.Trans
Sicheng Feng, Gongfan Fang, Xinyin Ma, and Xinchao Wang. Efficient Reasoning Models: A Survey.Trans. Mach. Learn. Res., 2025. URL https://api.semanticscholar.org/ CorpusID:277786677
work page 2025
-
[15]
Omni-math: A universal olympiad level mathematic benchmark for large language models
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang Tang, Benyou Wang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Yichang Zhang, Xuancheng Ren, Tianyu Liu, and Baobao Chang. Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Mod- els.ArXiv, abs/2410....
-
[16]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645(8081):633–638, 2025
work page 2025
-
[17]
Token-Budget-Aware LLM Reasoning
Tingxu Han, Zhenting Wang, Chunrong Fang, Shiyun Zhao, Shiqing Ma, and Zhenyu Chen. Token-Budget-Aware LLM Reasoning. InAnnual Meeting of the Association for Computational Linguistics, 2024. URLhttps://api.semanticscholar.org/CorpusID:274992044
work page 2024
-
[18]
arXiv preprint arXiv:2504.11456 , year=
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning.ArXiv, abs/2504.11456, 2025. URL https://api.semantic...
-
[19]
LoRA: Low-Rank Adaptation of Large Language Models
J. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models.ArXiv, abs/2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
URLhttps://api.semanticscholar.org/CorpusID:235458009
- [21]
-
[22]
Yao Huang, Huanran Chen, Shouwei Ruan, Yichi Zhang, Xingxing Wei, and Yinpeng Dong. Mit- igating Overthinking in Large Reasoning Models via Manifold Steering.ArXiv, abs/2505.22411,
-
[23]
URLhttps://api.semanticscholar.org/CorpusID:278959734
-
[24]
ThinkSwitcher: When to Think Hard, When to Think Fast
Guosheng Liang, Longguang Zhong, Ziyi Yang, and Xiaojun Quan. ThinkSwitcher: When to Think Hard, When to Think Fast. InConference on Empirical Methods in Natural Language Processing, 2025. URLhttps://api.semanticscholar.org/CorpusID:278769768
work page 2025
-
[25]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s Verify Step by Step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
QFFT, Question-Free Fine-Tuning for Adaptive Reason- ing.ArXiv, abs/2506.12860, 2025
Wanlong Liu, Jun Xu, Fei Yu, Yukang Lin, Ke Ji, Wenyu Chen, Yan Xu, Yasheng Wang, Lifeng Shang, and Benyou Wang. QFFT, Question-Free Fine-Tuning for Adaptive Reason- ing.ArXiv, abs/2506.12860, 2025. URL https://api.semanticscholar.org/CorpusID: 279402374
-
[27]
DiffAdapt: Difficulty-Adaptive Reasoning for Token-Efficient LLM Inference
Xiang Liu, Xuming Hu, Xiaowen Chu, and Eunsol Choi. DiffAdapt: Difficulty-Adaptive Reasoning for Token-Efficient LLM Inference.ArXiv, abs/2510.19669, 2025. URL https: //api.semanticscholar.org/CorpusID:282272126
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning.ArXiv, abs/2501.12570, 2025
Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shiwei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, and Dacheng Tao. O1-Pruner: Length-Harmonizing Fine-Tuning for O1-Like Reason- ing Pruning.ArXiv, abs/2501.12570, 2025. URL https://api.semanticscholar.org/ CorpusID:275790112. 11
-
[29]
CoT-Valve: Length-Compressible Chain-of-Thought Tuning
Xinyin Ma, Guangnian Wan, Runpeng Yu, Gongfan Fang, and Xinchao Wang. CoT-Valve: Length-Compressible Chain-of-Thought Tuning. InAnnual Meeting of the Association for Computational Linguistics, 2025. URL https://api.semanticscholar.org/CorpusID: 276317564
work page 2025
-
[30]
math-ai. AMC-23. https://huggingface.co/datasets/math-ai/amc23, 2025. Hugging Face dataset. 40 problems from the 2023 AMC 12A/12B benchmark; accessed 2026-04-16
work page 2025
-
[31]
A survey of efficient reasoning for large reasoning models: Language, multimodality, and beyond
Xiaoye Qu, Yafu Li, Zhaoyu Su, Weigao Sun, Jianhao Yan, Dongrui Liu, Ganqu Cui, Daizong Liu, Shuxian Liang, Junxian He, Peng Li, Wei Wei, Jing Shao, Chaochao Lu, Yue Zhang, Xian-Sheng Hua, Bowen Zhou, and Yu Cheng. A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond.ArXiv, abs/2503.21614, 2025. URL https://api.s...
-
[32]
Qwen Team. Qwen3-4B-Thinking-2507. https://huggingface.co/Qwen/ Qwen3-4B-Thinking-2507, 2025. Hugging Face model card, accessed 2026-04-17
work page 2025
-
[33]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A Graduate-Level Google-Proof Q&A Benchmark.ArXiv, abs/2311.12022, 2023. URL https://api.semanticscholar.org/ CorpusID:265295009
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Jun-Mei Song, Mingchuan Zhang, Y . K. Li, Yu Wu, and Daya Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.ArXiv, abs/2402.03300, 2024. URL https://api.semanticscholar. org/CorpusID:267412607
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Efficient Reinforcement Finetuning via Adaptive Curriculum Learning.ArXiv, abs/2504.05520, 2025
Taiwei Shi, Yiyang Wu, Linxin Song, Tianyi Zhou, and Jieyu Zhao. Efficient Reinforcement Finetuning via Adaptive Curriculum Learning.ArXiv, abs/2504.05520, 2025. URL https: //api.semanticscholar.org/CorpusID:277628042
-
[36]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Musr: Testing the limits of chain-of-thought with multistep soft reasoning.arXiv:2310.16049,
Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning.ArXiv, abs/2310.16049, 2023. URL https://api.semanticscholar.org/CorpusID:264439655
-
[38]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models.Trans
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Hanjie Chen, and Xia Hu. Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models.Trans. Mach. Learn. Res., 2025. URL https://api.semanticscholar.org/CorpusID:277150783
work page 2025
-
[39]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1.5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Songjun Tu, Jiahao Lin, Qichao Zhang, Xiangyu Tian, Linjing Li, Xiangyuan Lan, and Dongbin Zhao. Learning When to Think: Shaping Adaptive Reasoning in R1-Style Models via Multi- Stage RL.ArXiv, abs/2505.10832, 2025. URL https://api.semanticscholar.org/ CorpusID:278714618
-
[41]
TRL: Transformers Rein- forcement Learning, 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: Transformers Rein- forcement Learning, 2020. URLhttps://github.com/huggingface/trl
work page 2020
-
[42]
Siyuan Wang, Zhongkun Liu, Wanjun Zhong, Ming Zhou, Zhongyu Wei, Zhumin Chen, and Nan Duan. From LSAT: The progress and challenges of complex reasoning.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:2201–2216, 2022
work page 2022
-
[43]
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. Openclaw-RL: Train any agent simply by talking.arXiv preprint arXiv:2603.10165, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Miku Watanabe, Hao Li, Yutaro Kashiwa, Brittany Reid, Hajimu Iida, and Ahmed E. Hassan. On the Use of Agentic Coding: An Empirical Study of Pull Requests on GitHub.ACM Transactions on Software Engineering and Methodology, 2025. URL https://api.semanticscholar. org/CorpusID:281394787
work page 2025
-
[45]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, F. Xia, Quoc Le, and Denny Zhou. Chain of Thought Prompting Elicits Reasoning in Large Language Mod- els.ArXiv, abs/2201.11903, 2022. URL https://api.semanticscholar.org/CorpusID: 246411621
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[46]
BudgetThinker: Empowering Budget-aware LLM Reasoning with Control Tokens.ArXiv, abs/2508.17196, 2025
Hao Wen, Xinrui Wu, Yi Sun, Feifei Zhang, Liye Chen, Jie Wang, Yunxin Liu, Yunhao Liu, Ya-Qin Zhang, and Yuanchun Li. BudgetThinker: Empowering Budget-aware LLM Reasoning with Control Tokens.ArXiv, abs/2508.17196, 2025. URL https://api.semanticscholar. org/CorpusID:280711841
-
[47]
CODA: Difficulty-Aware Compute Allocation for Adaptive Reasoning
Siye Wu, Jian Xie, Yikai Zhang, and Yanghua Xiao. CODA: Difficulty-Aware Compute Allocation for Adaptive Reasoning, 2026. URLhttps://arxiv.org/abs/2603.08659
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Yuyang Wu, Yifei Wang, Tianqi Du, Stefanie Jegelka, and Yisen Wang. When More is Less: Understanding Chain-of-Thought Length in LLMs.ArXiv, abs/2502.07266, 2025. URL https://api.semanticscholar.org/CorpusID:276259519
-
[49]
Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He
Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He. Chain of Draft: Thinking Faster by Writing Less.ArXiv, abs/2502.18600, 2025. URL https://api.semanticscholar.org/ CorpusID:276618268
-
[50]
arXiv preprint arXiv:2504.15895 , year=
Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Zheng Lin, Li Cao, and Weiping Wang. Dynamic Early Exit in Reasoning Models.ArXiv, abs/2504.15895, 2025. URL https://api.semanticscholar.org/CorpusID:277994255
-
[51]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Qiyuan Zhang, Fuyuan Lyu, Zexu Sun, Lei Wang, Weixu Zhang, Wenyue Hua, Haolun Wu, Zhihan Guo, Yufei Wang, Niklas Muennighoff, et al. A survey on test-time scaling in large language models: What, how, where, and how well?arXiv preprint arXiv:2503.24235, 2025
work page internal anchor Pith review arXiv 2025
-
[52]
Xiaoyun Zhang, Jingqing Ruan, Xing Ma, Yawen Zhu, Haodong Zhao, Hao Li, Jiansong Chen, Ke Zeng, and Xunliang Cai. When to continue thinking: Adaptive thinking mode switching for efficient reasoning.arXiv preprint arXiv:2505.15400, 2025
-
[53]
Let LRMs Break Free from Overthinking via Self-Braking Tuning.arXiv preprint arXiv:2505.14604, 2025
Haoran Zhao, Yuchen Yan, Yongliang Shen, Haolei Xu, Wenqi Zhang, Kaitao Song, Jian Shao, Weiming Lu, Jun Xiao, and Yueting Zhuang. Let LRMs Break Free from Overthinking via Self-Braking Tuning.arXiv preprint arXiv:2505.14604, 2025
-
[54]
SABER: Switchable and Balanced Training for Efficient LLM Reasoning
Kai Zhao, Yanjun Zhao, Jiaming Song, Shien He, Lusheng Zhang, Qiang Zhang, and Tianjiao Li. SABER: Switchable and Balanced Training for Efficient LLM Reasoning. ArXiv, abs/2508.10026, 2025. URL https://api.semanticscholar.org/CorpusID: 280649722
-
[55]
Zhaomeng Zhou, Lan Zhang, Junyang Wang, and Mu Yuan. IoT-Brain: Grounding LLMs for Semantic-Spatial Sensor Scheduling.Proceedings of the 2025 ACM Workshop on Access Networks with Artificial Intelligence, 2025. URL https://api.semanticscholar.org/ CorpusID:283459628
work page 2025
-
[56]
how many s= 0.05 queries does fold miss
Yubo Zhu, Dongrui Liu, Zecheng Lin, Wei Tong, Sheng Zhong, and Jing Shao. The LLM Already Knows: Estimating LLM-Perceived Question Difficulty via Hidden Representations. InConference on Empirical Methods in Natural Language Processing, 2025. URL https: //api.semanticscholar.org/CorpusID:281325426. 13 A Training Pipeline and Implementation Details A.1 Over...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.