Recognition: 2 theorem links
· Lean TheoremAugmented Lagrangian Method for Last-Iterate Convergence for Constrained MDPs
Pith reviewed 2026-05-13 07:23 UTC · model grok-4.3
The pith
The inexact augmented Lagrangian method with projected Q-ascent achieves global last-iterate convergence for constrained MDPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We use the inexact augmented Lagrangian method to handle constraints in MDPs, solving the resulting sub-problems with projected Q-ascent to obtain global last-iterate convergence guarantees that extend from the tabular case to log-linear policies and scale to non-linear policies in practice.
What carries the argument
Inexact augmented Lagrangian (AL) method, with sub-problems solved by projected Q-ascent (PQA), which allows the standard AL convergence analysis to transfer to the CMDP setting.
If this is right
- Global last-iterate convergence for tabular CMDPs via PQA and AL analysis.
- Last-iterate convergence with comparable guarantees for log-linear policies.
- Scalability to complex non-linear policies demonstrated on continuous control tasks.
- Single last-iterate policy deployment becomes feasible, avoiding computational costs of mixtures.
Where Pith is reading between the lines
- The approach may generalize to other constrained RL problems like safety constraints in robotics.
- It could reduce the gap between theory and practice in deploying constrained policies.
- Future work might test the method on larger scale problems to verify the accuracy requirements for subproblem solving.
Load-bearing premise
Projected Q-ascent can solve the augmented Lagrangian sub-problems to the accuracy needed for the standard AL convergence proof to apply in the CMDP context.
What would settle it
Running the algorithm on a small tabular CMDP and observing that the last-iterate policy does not converge to the optimal value while mixture policies do would falsify the claim.
Figures












read the original abstract
We study policy optimization for infinite-horizon, discounted constrained Markov decision processes (CMDPs). While existing theoretical guarantees typically hold for the mixture policy, deploying such a policy is computationally and memory intensive. This leads to a practical mismatch where a single (last-iterate) policy must be deployed. Recent theoretical works have thus focused on proving last-iterate convergence, but are largely limited to the tabular setting or to algorithmic variants that are rarely used in practice. To address this, we use the classic inexact augmented Lagrangian ($\texttt{AL}$) method from constrained optimization, and propose a general framework with provable last-iterate convergence for CMDPs. We first focus on the tabular setting and propose to solve the $\texttt{AL}$ sub-problem with projected Q-ascent ($\texttt{PQA}$). Combining the theoretical guarantees of $\texttt{PQA}$ and the standard $\texttt{AL}$ analysis enables us to establish global last-iterate convergence. We generalize these results to handle log-linear policies, and demonstrate that an efficient, projected variant of $\texttt{PQA}$ can achieve last-iterate convergence with comparable guarantees as prior work. Finally, we demonstrate that our framework scales to complex non-linear policies, and evaluate it on continuous control tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an inexact augmented Lagrangian (AL) framework for policy optimization in infinite-horizon discounted constrained MDPs (CMDPs). It solves AL subproblems via projected Q-ascent (PQA) and claims that combining PQA guarantees with standard AL analysis yields global last-iterate convergence. The approach is first developed for tabular policies, then extended to log-linear policies via a projected PQA variant, and finally demonstrated on non-linear policies for continuous control tasks.
Significance. If the last-iterate guarantees are rigorously established, the work is significant for addressing the practical mismatch between mixture-policy theory and deployable single-policy algorithms in CMDPs. It offers a general, scalable framework that extends beyond tabular settings while leveraging classical constrained-optimization tools, which could influence both theory and practice in constrained RL.
major comments (2)
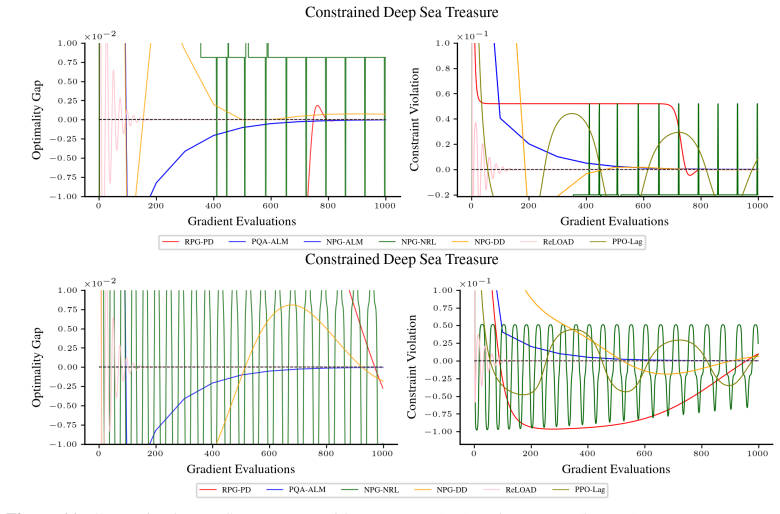
- [§3, Theorem 1] §3 (tabular case) and the proof of Theorem 1: Standard inexact AL last-iterate results require that the primal optimality gap or residual of each subproblem decay at a controlled rate (typically summable or O(1/k^{1+ε})). The manuscript invokes PQA convergence but does not supply an explicit joint schedule or error-propagation lemma showing that the sublinear rate of PQA, which depends on the current penalty parameter and constraint violation, remains inside the basin needed for the outer AL iteration to preserve last-iterate convergence.
- [§4] §4 (log-linear extension): The projected PQA variant is asserted to deliver comparable last-iterate guarantees, yet the argument again relies on transferring the same AL analysis without deriving a bound on how the projection and function-approximation error interact with the increasing penalty sequence. This step is load-bearing for the claim that the framework generalizes beyond tabular policies.
minor comments (2)
- Notation for the augmented Lagrangian and the projection operator in PQA is introduced without a consolidated table of symbols; readers must hunt across sections for definitions.
- [Experiments] The experimental section reports performance on continuous-control tasks but does not include ablation on the inner-solver tolerance schedule, which would help verify the practical relevance of the theoretical error requirements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We have carefully considered the points raised regarding the analysis in Sections 3 and 4, and we provide detailed responses below. Where appropriate, we have revised the manuscript to include additional lemmas and clarifications.
read point-by-point responses
-
Referee: [§3, Theorem 1] §3 (tabular case) and the proof of Theorem 1: Standard inexact AL last-iterate results require that the primal optimality gap or residual of each subproblem decay at a controlled rate (typically summable or O(1/k^{1+ε})). The manuscript invokes PQA convergence but does not supply an explicit joint schedule or error-propagation lemma showing that the sublinear rate of PQA, which depends on the current penalty parameter and constraint violation, remains inside the basin needed for the outer AL iteration to preserve last-iterate convergence.
Authors: We appreciate the referee pointing out the need for an explicit joint schedule and error-propagation analysis. In our framework, the PQA subproblem solver achieves a sublinear convergence rate that scales with the current augmented Lagrangian penalty parameter. By choosing the number of PQA iterations to increase appropriately with the penalty parameter (as detailed in the proof of Theorem 1), the subproblem residuals become summable, satisfying the conditions for last-iterate convergence of the inexact AL method. To make this transparent, we have added an error-propagation lemma in the revised appendix that explicitly bounds the interaction between the PQA rate, the penalty sequence, and the constraint violation, confirming that the errors remain within the required basin. revision: yes
-
Referee: [§4] §4 (log-linear extension): The projected PQA variant is asserted to deliver comparable last-iterate guarantees, yet the argument again relies on transferring the same AL analysis without deriving a bound on how the projection and function-approximation error interact with the increasing penalty sequence. This step is load-bearing for the claim that the framework generalizes beyond tabular policies.
Authors: We agree that a detailed bound on the projection and approximation errors is necessary for the log-linear case. The projected PQA introduces an additional error term arising from the projection onto the parameterized policy class. Using the smoothness properties of the log-linear parameterization and the fact that the penalty parameter increases at a controlled rate, we derive that this error term decreases sufficiently fast to not disrupt the summability condition. In the revised manuscript, we have included a new proposition in Section 4 that provides this bound and shows how it integrates with the AL analysis, thereby establishing the last-iterate guarantees with rates comparable to the tabular setting. revision: yes
Circularity Check
No significant circularity detected in the derivation chain.
full rationale
The paper's central argument combines the (presumably independently derived) convergence guarantees of projected Q-ascent for solving AL subproblems with the standard inexact augmented Lagrangian convergence analysis to obtain last-iterate guarantees for CMDPs. The abstract and description present this as a transfer of existing AL results to the CMDP setting rather than a self-referential construction. No quoted equations, self-definitions, fitted inputs renamed as predictions, or load-bearing self-citations that reduce the claimed result to its own inputs are present. The derivation is therefore treated as self-contained against external benchmarks (standard AL theory and separate PQA analysis).
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (J-uniqueness, washburn_uniqueness_aczel)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use the classic inexact augmented Lagrangian (AL) method... solve the AL sub-problem with projected Q-ascent (PQA)... global last-iterate convergence... O(1/ε^6) policy gradient evaluations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
th soft labels enabling efficient optimization even in large state–action spaces [Asad et al., 2024]. Minimizing this surrogate carries out the forward-KL projection, yielding the projected PQA update ( PPQA). The corresponding pseudo-code (Algorithm
work page 2024
-
[2]
is provided in Section E. Following Agarwal et al. [2021], Asad et al. [2024], in order to control the projection error induced by approximate minimization ofℓk(θ), we make the following assumptions: Assumption 4(Bias).For allk≥1,min θℓk(θ)≤ϵbias Assumption 5(Optimization Error).Supposeθk+1 is obtained by approximately minimizingℓk(θ), then,|ℓk(θk+1)−minθ...
work page 2021
-
[3]
Assumption 5 accounts for the optimization error arising from minimizing the surrogate using a finite number of gradient steps. This assumption is common in the analysis of PG methods with function approximation [Asad et al., 2024, Agarwal et al., 2021, Yuan et al., 2022b, Ding et al., 2023]. In particular, ifn steps of gradient descent are used to minimi...
work page 2024
-
[4]
However, their analysis relies on several restrictive structural assumptions
analyze a regularized NPG primal-dual method for log-linear policies (Lin-RPG-PD) and establish a last-iterateO(1/ε6) rate. However, their analysis relies on several restrictive structural assumptions. First, the policy is required to be projected on to a restricted simplex (a non-standard impractical modification). As further noted by M¨uller et al. [202...
work page 2024
-
[5]
Dissecting Discrete Soft Actor-Critic: Limitations and Principled Alternatives
Reza Asad, Reza Babanezhad, and Sharan Vaswani. Revisiting actor-critic methods in discrete action off-policy reinforcement learning.arXiv preprint arXiv:2509.09838,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
The augmented lagrangian methods: Overview and recent advances.arXiv preprint arXiv:2510.16827,
Kangkang Deng, Rui Wang, Zhenyuan Zhu, Junyu Zhang, and Zaiwen Wen. The augmented lagrangian methods: Overview and recent advances.arXiv preprint arXiv:2510.16827,
-
[7]
Policy gradient for reinforcement learning with general utilities
Navdeep Kumar, Kaixin Wang, Utkarsh Pratiush, Kfir Yehuda Levy, and Shie Mannor. Policy gradient for reinforcement learning with general utilities. InThe Second Tiny Papers Track at ICLR 2024,
work page 2024
-
[8]
Smoothness of the augmented lagrangian dual in convex optimization
Jingwang Li and Vincent Lau. Smoothness of the augmented lagrangian dual in convex optimization. arXiv preprint arXiv:2505.01824,
-
[9]
Jiacai Liu, Wenye Li, Dachao Lin, Ke Wei, and Zhihua Zhang. On the convergence of projected policy gradient for any constant step sizes.Journal of Machine Learning Research, 26(193):1–35, 2025a. Xingtu Liu, Lin F Yang, and Sharan Vaswani. Sample complexity bounds for linear constrained mdps with a generative model.arXiv preprint arXiv:2507.02089, 2025b. Y...
-
[10]
Last-Iterate Convergence of General Parameterized Policies in Constrained MDPs
11 Washim U Mondal and Vaneet Aggarwal. Sample-efficient constrained reinforcement learning with general parameterization.Advances in Neural Information Processing Systems, 37:68380–68405, 2024a. Washim Uddin Mondal and Vaneet Aggarwal. Last-iterate convergence of general parameterized policies in constrained mdps.arXiv preprint arXiv:2408.11513, 2024b. A...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Adrian M¨uller, Pragnya Alatur, Giorgia Ramponi, and Niao He. Cancellation-free regret bounds for lagrangian approaches in constrained markov decision processes.arXiv preprint arXiv:2306.07001,
-
[12]
Behaviour suite for reinforce- ment learning.arXiv preprint arXiv:1908.03568,
Ian Osband, Yotam Doron, Matteo Hessel, John Aslanides, Eren Sezener, Andre Saraiva, Katrina McKinney, Tor Lattimore, Csaba Szepesvari, Satinder Singh, et al. Behaviour suite for reinforce- ment learning.arXiv preprint arXiv:1908.03568,
-
[13]
Benchmarking safe exploration in deep reinforcement learning,
Alex Ray, Joshua Achiam, and Dario Amodei. Benchmarking safe exploration in deep reinforcement learning.arXiv preprint arXiv:1910.01708, 7(1):2,
-
[14]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U Balis, Gianluca De Cola, Tristan Deleu, Manuel Goul˜ao, Andreas Kallinteris, Markus Krimmel, Arjun KG, et al. Gymnasium: A standard interface for reinforcement learning environments.arXiv preprint arXiv:2407.17032,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Sharan Vaswani, Olivier Bachem, Simone Totaro, Robert M ¨u ller, Shivam Garg, Matthieu Geist, Marlos C Machado, Pablo Samuel Castro, and Nicolas Le Roux. A general class of surrogate functions for stable and efficient reinforcement learning.arXiv preprint arXiv:2108.05828,
-
[17]
A dual approach to constrained markov decision processes with entropy regularization
Donghao Ying, Yuhao Ding, and Javad Lavaei. A dual approach to constrained markov decision processes with entropy regularization. InInternational Conference on Artificial Intelligence and Statistics, pages 1887–1909. PMLR,
work page 1909
-
[18]
Rui Yuan, Simon S Du, Robert M Gower, Alessandro Lazaric, and Lin Xiao. Linear convergence of natural policy gradient methods with log-linear policies.arXiv preprint arXiv:2210.01400, 2022a. Rui Yuan, Robert M. Gower, and Alessandro Lazaric. A general sample complexity analysis of vanilla policy gradient, 2022b. Wenhao Zhan, Shicong Cen, Baihe Huang, Yuxi...
-
[19]
Proof. To prove this result, we reduce finding an approximate solution to Problem 1 to an equivalent linear program (LP) (refer to Section C.1 for additional details) . Using the standard occupancy measure formulation of CMDPs [Altman, 2021], we have max µπ∈K, z∈Rm + ⟨µπ,r⟩s.t.⟨µπ,ci⟩−zi =b i ∀i∈[m](9) wherez∈Rm + are non-negative slack variables. and K:=...
work page 2021
-
[20]
=O( 1/ϵ6). 17 C Proof of Technical Tools C.1 Reduction from Inequality to Equality Constraints The objective is to solve the following CMDP Problem 1.max πVπ r (ρ) s.t. Vπ ci (ρ)≥bi ∀i∈[m]. Using the standard linear programming (LP) formulation of CMDPs [Altman, 2021], solving Prob- lem 1 with respect to a policyπis equivalent to solving the following LP ...
work page 2021
-
[21]
) + 4 max { maxµπ,z ¯Fβ,λ∗(π,z)−maxµπ,z ¯Fβ,λ1(π,z),4 κ } . To relate Eq. (15) to an individual constrainti∈[m], bi−⟨µπT+1,ci⟩=−(⟨µπT+1,ci⟩−bi) =−(⟨µπT+1,ci⟩−bi−[zT+1 ]i + [zT+1 ]i)(Add/Subtract[z T+1 ]i) ≤−(⟨µπt+1,ci⟩−bi−[zT+1 ]i)(Since[z T+1 ]i≥0) ≤|⟨µπT+1,ci⟩−bi−[zT+1 ]i| ≤max i∈[m] |⟨µπT+1,ci⟩−bi−[zT+1 ]i| ≤ m∑ i=1 ⟨µπt+1,ci⟩−[zt+1]i−bi (S...
work page 2014
-
[22]
We will follow the proof in Liu et al
) + 4 max { δ1, 4 κ } .(36) Proof. We will follow the proof in Liu et al. [2019, Theorem 4.3] and do the proof by induction. Clearly, the inequality (36) holds fort= 1 . Next, we assume that (36) holds for somet≥1, and show it is also true fort+ 1 . We use the contrapositive argument. Assume that (36) does not hold for t+ 1, i.e., δt+1 > C t+ 1,(37) In th...
work page 2019
-
[23]
Lemma 12(Lemma 4.2 in Liu et al
2≤4t2 for all t≥1, we get ≤ω(ωκσ+ 1)σ t2 −κC 4t2z∗+ κ 2t2 (z∗)2 + 1 t2z∗ = Q(z∗) t2 , which, together with (39) yieldsP(z ∗)≤0.This completes the proof. Lemma 12(Lemma 4.2 in Liu et al. [2019]).Suppose the nonnegative sequence{δt}satisfies E 2δ2 t+1 +δt+1≤δt, t= 1,2,...,(42) whereE >0is a constant. Then, we have δt≤max { δ1, 4 E } t , t= 1,2,....(43) Proo...
work page 2019
-
[24]
In fact, we have δt+1≤−1 +√1 + 2Eδt E ≤−1 + √ 1 + 2E max{δ1, 4 E} t E = 2 max { δ1, 4 E } t+ √ t2 + 2Emax { δ1, 4 E } t ≤max { δ1, 4 E } t+ 1 , where the first inequality is due to the inequality (42), and the second inequality is due to the assumption that (43) holds fort. Lemma 13(Theorem 1 in Li and Lau [2025]).Assuming f is closed proper convex, the d...
work page 2025
-
[25]
yields [∇πG(π)](s,a) = dπ(s)Qπ Γ(π)(s,a) 1−γ . Therefore, the projected Q-Ascent (PQA) [Xiao, 2022, Liu et al., 2025a] update for the step-sizeη >0can be written as: for anyk≥1, πk+1 = arg max π∈Π [ ∑ s∈S dπk(s) 1−γ ⣨ Qπk Γ(πk)(s,·),π(·|s)−πk(·|s) ⟩ −1 2η ∑ s∈S dπk(s) 1−γ∥π(·|s)−πk(·|s)∥2 2 ] . (45) Theorem 4.Suppose Assumptions 1 to 3 holds. Let π∗denote...
work page 2022
-
[26]
Let η=ρmin L and under this choice, L 2 = ρmin 2η
This further implies the following inequalities: G(π)≥G(π′) +⟨∇πG(π′),π−π′⟩−L 2∥π−π′∥2 2 (47) G(π′) +⟨∇πG(π′),π−π′⟩≥G(π)−L 2∥π−π′∥2 2.(48) Under Assumption 1, for all s∈S,ρ(s) =ρmin. Let η=ρmin L and under this choice, L 2 = ρmin 2η. Using Eq. (47) withπ=πk+1 andπ′=πk, we have that G(πk+1)≥G(πk) +⟨∇πG(πk),πk+1−πk⟩−ρmin 2η∥πk+1−πk∥2 2 =G(πk) +⟨∇πG(πk),πk+1...
work page 2020
-
[27]
= max αk∈[0,1] F(παk)−C1∥παk−πk∥2 2 ≥max αk∈[0,1] αkF(µπ∗ ) + (1−αk)F(µπk))−C1∥παk−πk∥2 2 (SinceFis concave) = max αk∈[0,1] αkG(π∗) + (1−αk)G(πk)−C1∥παk−πk∥2 2 Multiplying both sides by−1and addingG(π∗), =⇒G(π∗)−G(πk+1)≤G(π∗)−max αk∈[0,1] { αkG(π∗) + (1−αk)G(πk)−C1∥παk−πk∥2 2 } =G(π∗) + min αk∈[0,1] { −αkG(π∗)−(1−αk)G(πk) +C 1∥παk−πk∥2 2 } = min αk∈[0,1] ...
work page 2020
-
[28]
As a result, we consider the following policy class Πθ:={π|∃θs.tπ=πθ} where the model parameterizing the policy is implicit in the definition. In this setting, to update the policy, we consider the following projected PQA (PPQA) update using the forward KL-divergence. For allk≥1, using a fixed step-sizeη >0, the PPQA consists of two steps: πk+1/2 = arg ma...
work page 2021
-
[29]
Finally, we have that ∥∇πG(π)∥2≤U √ A (1−γ)2. E.4 Additional Lemmas for the Augmented Lagrangian General Utility Proposition 1.For each iterationt∈[T], the policy gradient of the AL in Eq.(2)is given by ∇θFβ,λ(π(θ)) =∑ s dπ(s) 1−γ ∑ a Qπ Γ(π)(s,a) dπθ(a|s) dθ Γ(π) =r−β∑m i=1ci min { Vπ ci (ρ)−bi−λi β,0 } ,(62) andQπ Γ(π)is the state-action value function ...
work page 2021
-
[30]
≤1 +β∥b∥1 +√m √ M2 + βσπ2 3 +∥M∥1 (Using Eq. (13)) 42 F Large-Scale Experiments on Continious Control Tasks F.1 Key Results We evaluate our framework on three MuJCo tasks (each with a single constraint) from Safety- Gymnasium [Ji et al., 2023] and compare against standard on-policy PG methods in the constrained setting:PPOLag[Ray et al., 2019] andCPO[Achi...
work page 2023
-
[31]
Overall, SPMA-ALM achieves the most consistent constraint satisfaction across environments, with lower mean and tail violations. Figure 5:Box plot of constraint violations of the final policy, evaluated over 10 rollouts per seed across 10 seeds. The green triangle denotes the mean, and the orange line indicates the median. Table 3:Constraint violation sta...
work page 2018
-
[32]
Overall,PQA-ALMperform well in practice
We report results using the configuration that achieved the smallest optimality gap subject to the final policy satisfying the constraint violation b−VπT+1 c (ρ)≤εwhereε∈{0.001,0.01}. Overall,PQA-ALMperform well in practice. Table 4:Grid search ranges for the tabular experiments. n denotes the number of iterates used to update the corresponding surrogate....
work page 2019
-
[33]
we use tile-code features [Sutton and Barto, 2018]. Tilde-coded features require three parameters to be set: (i) hash table size (feature dimensiond), (ii) number of tilesN, and (iii) size of tiless. IncreasingN increases the express ability of the features Increasings controls how “spread out” the features are. For both environments, we consider the foll...
work page 2018
-
[34]
n denotes the number of iterates used to update the corresponding surrogate
Table 5:Grid search ranges for each method. n denotes the number of iterates used to update the corresponding surrogate. Method Fixed Params. Search Space PPQA-ALMT= 10,K= 100, Primal step-size{0.0001,0.001,0.1,1.0,10} n= 250,β= 10Surrogate step-size{0.0001,0.001,0.1,1.0,10} PPO-Lag[Ray et al., 2019]T= 1000,n= 250, Primal step-size:{0.01,0.1,1,10,100} Dua...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.