Recognition: no theorem link
MindMirror: A Local-First Multimodal State-Aware Support System for Digital Workers
Pith reviewed 2026-05-13 05:48 UTC · model grok-4.3
The pith
MindMirror combines local facial expression detection with a fine-tuned model at 94.49 percent accuracy and structured reflection to support digital workers in managing fatigue and task blockage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a local-first multimodal system integrating camera-based facial expression recognition, user inputs, structured reflection, and a local LLM can form an effective closed workflow for state-aware support, demonstrated by a 34.83 percentage point accuracy gain in the emotion recognition module on a seven-class benchmark and positive user feedback on the prototype's design features.
What carries the argument
The closed workflow of state checking via multimodal inputs, manual correction, structured articulation of blockage, local LLM-based suggestion generation, and daily/weekly review reports, supported by a fine-tuned Hugging Face emotion model and Ollama-hosted Qwen LLM.
If this is right
- The local-first architecture keeps all processing on-device, reducing privacy risks compared to cloud-based alternatives.
- Manual correction gives users direct control to override automated detections before suggestions are generated.
- The structured reflection step helps users articulate vague feelings of blockage into concrete inputs for the LLM.
- Daily and weekly reports enable users to track patterns in their states over time without external data sharing.
Where Pith is reading between the lines
- Adding passive signals such as typing speed or application switches could strengthen state detection without extra user effort.
- The workflow might transfer to domains like student study sessions or remote team meetings where similar fatigue patterns occur.
- Over repeated use the reflection prompts could serve as a lightweight training mechanism for better self-awareness.
Load-bearing premise
That detected facial expressions and user-reported states accurately reflect internal experience in real work settings and that the local LLM suggestions will be perceived as helpful rather than intrusive or generic.
What would settle it
A longitudinal study measuring whether users show sustained changes in self-reported fatigue or task completion rates when using the full MindMirror workflow versus a control condition without the structured reflection and suggestions.
Figures



read the original abstract
Digital workers often experience fatigue, anxiety, reduced attention, and task blockage during prolonged computer-based work. Existing productivity tools mainly focus on task completion, while general-purpose AI chatbots require users to formulate clear prompts before receiving useful help. This paper presents MindMirror, a local-first multimodal state-aware support system for digital workers. MindMirror integrates camera-based facial expression cues, text input, optional speech interaction, structured blockage reflection, local large language model (LLM)-based response generation, and daily/weekly review reports. The system forms a closed workflow of state checking, manual correction, structured articulation, suggestion generation, and state review. The current prototype follows a local-first design, while optional speech services may rely on third-party APIs when enabled. It is implemented with a Web frontend, Flask backend, an emotion recognition model, an Ollama-hosted Qwen model, Chart.js visualization, and local JSON/LocalStorage records. We evaluate the emotion recognition module on an independent seven-class image-level facial expression benchmark containing 6,767 images. The fine-tuned Hugging Face model improves accuracy from 59.66% to 94.49% over a non-fine-tuned checkpoint baseline, an absolute gain of 34.83 percentage points. We further validate the prototype through endpoint-level reliability tests, voice-interaction latency tests, and a small formative user feedback study with six digital workers. Results suggest that users value the local-first design, manual correction mechanism, and structured reflection workflow. MindMirror is not intended for psychological diagnosis; instead, it serves as a lightweight, user-controllable tool for state reflection and supportive interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MindMirror, a local-first multimodal system designed to support digital workers by integrating camera-based facial expression recognition, text and optional speech inputs, structured reflection on task blockages, and local LLM-generated suggestions, culminating in daily/weekly review reports. It claims a substantial improvement in seven-class facial expression recognition accuracy from 59.66% to 94.49% on an independent benchmark of 6,767 images and reports positive qualitative feedback from a formative study involving six digital workers who valued the local-first design, manual correction, and reflection workflow.
Significance. If the system's effectiveness in reducing fatigue and improving productivity is confirmed, MindMirror could contribute meaningfully to the field of human-computer interaction by providing a privacy-preserving, user-controllable alternative to general-purpose AI tools for managing work-related mental states. The technical demonstration of fine-tuning for high-accuracy local emotion recognition and the closed workflow design are notable strengths.
major comments (2)
- [Evaluation section (user study)] The formative user study with only six participants reports that users 'valued' the local-first design, manual correction mechanism, and structured reflection workflow, but provides no quantitative pre/post measures of internal states (e.g., fatigue, anxiety), task performance metrics, or comparisons to baseline tools. This limits the ability to substantiate the central claim that MindMirror serves as an effective state-aware support system.
- [Emotion recognition evaluation] The accuracy of 94.49% is reported on a benchmark dataset of posed images; the manuscript does not include an evaluation on in-situ webcam feeds captured during actual prolonged work sessions, which may differ in expression naturalness, lighting, and head pose, potentially affecting real-world performance.
minor comments (2)
- [Abstract] The abstract mentions 'endpoint-level reliability tests' and 'voice-interaction latency tests' but provides no specific results or metrics for these tests, which would help assess the prototype's robustness.
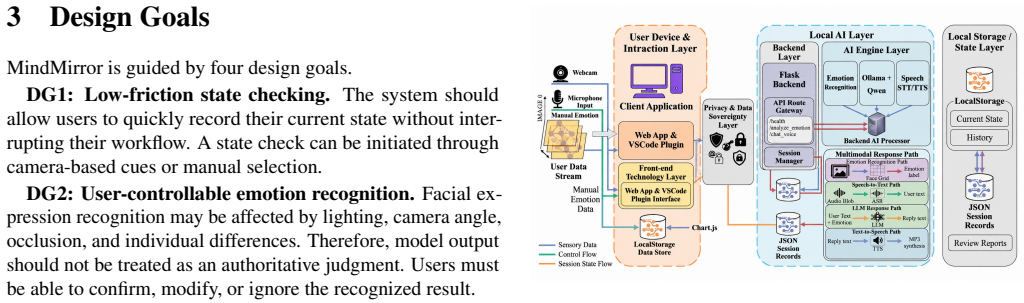
- [Implementation] The description of the system architecture (Web frontend, Flask backend, Ollama-hosted Qwen model) is high-level; including a diagram or more detailed component interactions would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation of MindMirror. The comments highlight important distinctions between formative exploration and efficacy validation, which we will address by clarifying scope and adding explicit limitations in the revised manuscript.
read point-by-point responses
-
Referee: [Evaluation section (user study)] The formative user study with only six participants reports that users 'valued' the local-first design, manual correction mechanism, and structured reflection workflow, but provides no quantitative pre/post measures of internal states (e.g., fatigue, anxiety), task performance metrics, or comparisons to baseline tools. This limits the ability to substantiate the central claim that MindMirror serves as an effective state-aware support system.
Authors: We agree that the study is formative and qualitative, with N=6 providing initial user feedback rather than quantitative evidence of effectiveness. The manuscript already describes the study as 'formative user feedback' and makes no claims of fatigue reduction or productivity gains; it only reports that participants valued the local-first design, manual correction, and reflection workflow. In revision we will expand the Evaluation section with additional protocol details (e.g., session structure, thematic analysis method) and insert a dedicated Limitations subsection that explicitly notes the absence of pre/post internal-state measures, task metrics, and baseline comparisons, while outlining plans for future controlled experiments. This directly incorporates the referee's concern by better bounding our claims. revision: yes
-
Referee: [Emotion recognition evaluation] The accuracy of 94.49% is reported on a benchmark dataset of posed images; the manuscript does not include an evaluation on in-situ webcam feeds captured during actual prolonged work sessions, which may differ in expression naturalness, lighting, and head pose, potentially affecting real-world performance.
Authors: The 94.49% figure is obtained on a standard independent seven-class benchmark of 6,767 images, chosen to enable direct comparison with published baselines and to demonstrate the benefit of fine-tuning. We concur that posed benchmark images differ from naturalistic webcam footage in lighting, pose, and expression subtlety. In the revised manuscript we will add a paragraph in the Evaluation and/or Discussion sections acknowledging this domain gap and stating that real-world performance remains to be validated. Because the current work focuses on prototype implementation and benchmark validation, we cannot retroactively supply in-situ results; such data collection would require a separate study. revision: partial
Circularity Check
No circularity; claims rest on external benchmark and direct user observations
full rationale
The paper evaluates its emotion recognition module on an independent external benchmark of 6,767 images, reporting a standard accuracy lift from fine-tuning (59.66% to 94.49%). User feedback comes from direct observation in a small formative study rather than any derived or fitted quantity. No equations, self-referential definitions, load-bearing self-citations, or renamed empirical patterns appear in the derivation chain. The workflow and results are self-contained against external data sources.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Facial expressions provide a usable proxy for internal emotional and attentional states during computer work.
- domain assumption Local LLMs can generate contextually appropriate supportive suggestions from structured user input.
Reference graph
Works this paper leans on
-
[1]
R. W. Picard.Affective Computing. MIT Press, 1997
work page 1997
-
[2]
R. A. Calvo and S. D’Mello. Affect detection: An interdisciplinary review of models, methods, and their applications.IEEE Transactions on Affective Computing, 1(1):18–37, 2010
work page 2010
-
[3]
World Health Organization. Mental health at work. WHO Fact Sheet, 2024. Available at: https://www.who.int/news-room/ fact-sheets/detail/mental-health-at-work
work page 2024
-
[4]
I. J. Goodfellow, D. Erhan, P. L. Carrier, A. Courville, M. Mirza, B. Ham- ner, W. Cukierski, Y . Tang, D. Thaler, D.-H. Lee, and others. Challenges in representation learning: A report on three machine learning contests. arXiv preprint arXiv:1307.0414, 2013
work page Pith review arXiv 2013
-
[5]
P. Lucey, J. F. Cohn, T. Kanade, J. Saragih, Z. Ambadar, and I. Matthews. The extended Cohn-Kanade dataset (CK+): A complete dataset for action unit and emotion-specified expression. In2010 IEEE Computer Society 8 Conference on Computer Vision and Pattern Recognition Workshops, pp. 94–101, 2010
work page 2010
- [6]
-
[7]
F. Xue, Q. Wang, and G. Guo. TransFER: Learning relation-aware facial expression representations with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3601– 3610, 2021
work page 2021
- [8]
-
[9]
H. Lian, C. Lu, S. Li, Y . Zhao, C. Tang, and Y . Zong. A survey of deep learning-based multimodal emotion recognition: Speech, text, and face. Entropy, 25(10):1440, 2023
work page 2023
-
[10]
A. Zadeh, P. P. Liang, S. Poria, E. Cambria, and L.-P. Morency. Mul- timodal language analysis in the wild: CMU-MOSEI dataset and in- terpretable dynamic fusion graph. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pp. 2236–2246, 2018
work page 2018
-
[11]
Z. Guo, A. Lai, J. H. Thygesen, J. Farrington, T. Keen, and K. Li. Large language models for mental health applications: Systematic review.JMIR Mental Health, 11:e57400, 2024
work page 2024
-
[12]
K. K. Fitzpatrick, A. Darcy, and M. Vierhile. Delivering cognitive behavior therapy to young adults with symptoms of depression and anxiety using a fully automated conversational agent: A randomized controlled trial.JMIR Mental Health, 4(2):e19, 2017
work page 2017
-
[13]
I. Li, A. K. Dey, and J. Forlizzi. A stage-based model of personal informatics systems. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp. 557–566, 2010
work page 2010
-
[14]
E. P. S. Baumer. Reflective informatics: Conceptual dimensions for designing technologies of reflection. InProceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, pp. 585–594, 2015
work page 2015
-
[15]
S. Amershi, D. Weld, M. V orvoreanu, A. Fourney, B. Nushi, P. Collisson, J. Suh, S. Iqbal, P. N. Bennett, K. Inkpen, and others. Guidelines for human-AI interaction. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems, pp. 1–13, 2019
work page 2019
-
[16]
M. Kleppmann, A. Wiggins, P. van Hardenberg, and M. McGranaghan. Local-first software: You own your data, in spite of the cloud. InPro- ceedings of the 2019 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software, pp. 154–178, 2019
work page 2019
-
[17]
S. Kaufman, S. Rosset, C. Perlich, and O. Stitelman. Leakage in data mining: Formulation, detection, and avoidance.ACM Transactions on Knowledge Discovery from Data, 6(4):1–21, 2012
work page 2012
-
[18]
vit-Facial-Expression-Recognition
mo-thecreator. vit-Facial-Expression-Recognition. Hugging Face model card. Available at: https://huggingface.co/mo-thecreator/ vit-Facial-Expression-Recognition
-
[19]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Ollama. Ollama documentation. Available at: https://ollama. com. 9 A Detailed Per-Class Results Table 12 reports the detailed per-class accuracy comparison on the 6,767-image independent image-level benchmark. This appendix preserves class-level evidence without interrupting the main evaluation narrative. Table 12:Detailed per-class accuracy comparison on...
-
[21]
Base the response on the user’s confirmed state and reflection content
-
[22]
Provide specific and actionable suggestions
-
[23]
Use warm and supportive language
-
[24]
Do not diagnose mental disorders
-
[25]
Do not provide medical or therapeutic treatment
-
[26]
If the user expresses severe or persistent distress, recommend professional help. Output format: Step 1: Immediate action - Action: <one concrete action> - Explanation: <short explanation> Step 2: Short-term strategy - Action: <one short-term work strategy> - Explanation: <short explanation> Step 3: Longer-term reminder - Action: <one reflection or planni...
-
[27]
The state-check workflow was easy to understand
-
[28]
Manual correction made the system feel more controllable
-
[29]
The three-question reflection helped me articulate my blockage
-
[30]
The generated suggestions were specific enough to be actionable
-
[31]
The local-first/no-account design increased my trust in the system. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.