Recognition: no theorem link
Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
Pith reviewed 2026-05-14 21:04 UTC · model grok-4.3
The pith
On-policy distillation locks onto a stable update trajectory toward the final model early in training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
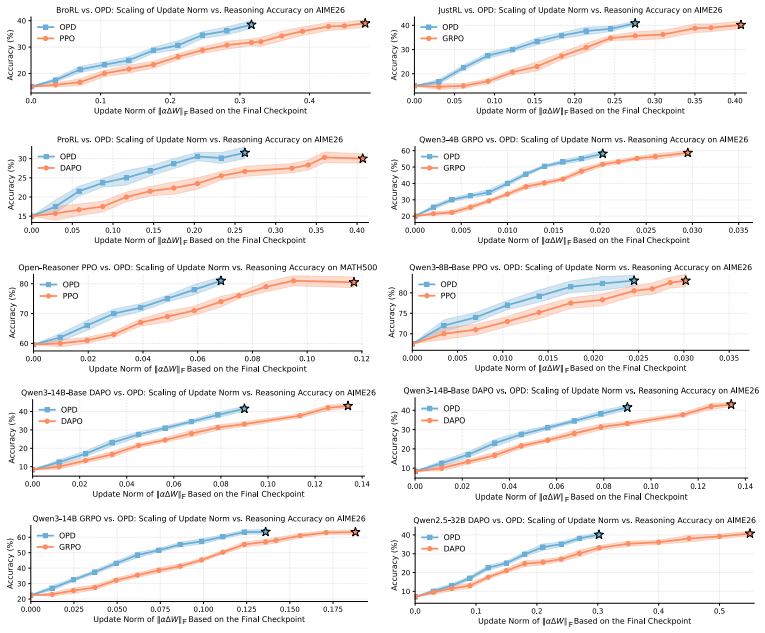
On-policy distillation establishes a stable update trajectory toward the final model early in training. This foresight manifests at the module-allocation level by concentrating updates on critical modules and at the update-direction level by stronger low-rank concentration whose dominant subspaces align with the final update subspace. Building on these observations, EffOPD adaptively selects an extrapolation step size and moves along the current update direction, achieving an average 3x training acceleration while maintaining comparable final performance.
What carries the argument
The foresight property realized through module-utility concentration and early low-rank subspace alignment with the final model.
If this is right
- OPD concentrates updates on modules with high marginal utility for reasoning while skipping low-utility regions.
- OPD exhibits stronger low-rank concentration whose dominant subspaces align with the final update subspace from early training.
- Adaptive extrapolation along the current direction produces an average 3x training acceleration.
- EffOPD requires no additional trainable modules and no complex hyperparameter tuning.
Where Pith is reading between the lines
- The same early-alignment pattern might be exploited in other post-training methods such as reinforcement learning from human feedback to obtain similar speedups.
- Tracking module utility and subspace alignment during training could provide early signals for dynamic pruning or early stopping.
- Applying the extrapolation rule to models larger than those tested here would show whether the 3x factor scales or saturates.
Load-bearing premise
The observed module utility patterns and low-rank alignment are causal drivers of the efficiency gains rather than correlated side effects of training.
What would settle it
An experiment that forces module allocation and subspace alignment to match those of OPD but runs a different update rule, then checks whether the 3x speedup disappears or final performance degrades across tasks.
Figures



























read the original abstract
On-policy distillation (OPD) has emerged as an efficient post-training paradigm for large language models. However, existing studies largely attribute this advantage to denser and more stable supervision, while the parameter-level mechanisms underlying OPD's efficiency remain poorly understood. In this work, we argue that OPD's efficiency stems from a form of ``foresight'': it establishes a stable update trajectory toward the final model early in training. This foresight manifests in two aspects. First, at the \textbf{Module-Allocation Level}, OPD identifies regions with low marginal utility and concentrates updates on modules that are more critical to reasoning. Second, at the \textbf{Update-Direction Level}, OPD exhibits stronger low-rank concentration, with its dominant subspaces aligning closely with the final update subspace early in training. Building on these findings, we propose \textbf{EffOPD}, a plug-and-play acceleration method that speeds up OPD by adaptively selecting an extrapolation step size and moving along the current update direction. EffOPD requires no additional trainable modules or complex hyperparameter tuning, and achieves an average training acceleration of $3\times$ while maintaining comparable final performance. Overall, our findings provide a parameter-dynamics perspective for understanding the efficiency of OPD and offer practical insights for designing more efficient post-training methods for large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that on-policy distillation (OPD) for large language models achieves its efficiency through a form of 'foresight' that establishes a stable update trajectory toward the final model early in training. This foresight manifests at the module-allocation level by concentrating updates on critical reasoning modules (avoiding low-utility regions) and at the update-direction level via stronger low-rank concentration whose dominant subspaces align closely with the final update subspace. Building on these observations, the authors propose EffOPD, a plug-and-play method that adaptively selects an extrapolation step size and moves along the current update direction, yielding an average 3x training acceleration while preserving comparable final performance.
Significance. If the causal link between the observed foresight patterns and efficiency is established, the work supplies a parameter-dynamics perspective on why OPD outperforms standard post-training and introduces a lightweight acceleration technique requiring no extra modules or heavy tuning. This could inform the design of faster post-training pipelines for LLMs, especially if the module-utility and subspace-alignment phenomena generalize across model scales and tasks.
major comments (3)
- [Module-Allocation Level] Module-Allocation Level analysis: the observed concentration of updates on critical modules is presented as a driver of efficiency, yet the manuscript provides only observational comparisons to SFT; no ablation that preserves on-policy supervision density while disrupting module-utility patterns (e.g., via forced uniform allocation or masking) is reported to test whether the concentration is causal rather than a correlated byproduct.
- [Update-Direction Level] Update-Direction Level analysis: the claim of stronger low-rank concentration and early alignment with the final subspace is supported by trajectory plots, but the text does not report statistical significance, run-to-run variance, or quantitative metrics (e.g., subspace overlap angles with error bars) that would establish the alignment is reliably stronger than in baseline methods.
- [EffOPD experiments] EffOPD evaluation: the reported average 3x speedup and maintained performance rest on comparisons whose controls, task diversity, model scales, and statistical tests are not fully detailed; without these, it remains unclear whether adaptive extrapolation along the current direction generalizes without occasional degradation of final performance.
minor comments (2)
- [Abstract] Abstract: the statement of 'an average training acceleration of 3×' does not specify the tasks, models, or exact set of baselines over which the average is computed.
- [Introduction] Notation: the phrases 'Module-Allocation Level' and 'Update-Direction Level' are used repeatedly before any formal definition or equation is supplied, making the early sections harder to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and outline the revisions we will make to strengthen the manuscript's claims regarding causality, statistical rigor, and experimental transparency.
read point-by-point responses
-
Referee: [Module-Allocation Level] Module-Allocation Level analysis: the observed concentration of updates on critical modules is presented as a driver of efficiency, yet the manuscript provides only observational comparisons to SFT; no ablation that preserves on-policy supervision density while disrupting module-utility patterns (e.g., via forced uniform allocation or masking) is reported to test whether the concentration is causal rather than a correlated byproduct.
Authors: We agree that an explicit ablation isolating the causal contribution of module concentration would strengthen the argument. The current analysis relies on observational comparisons between OPD and SFT trajectories to document the concentration pattern. In the revised manuscript we will add a controlled ablation that enforces uniform module allocation (via masking or redistribution of updates) while preserving on-policy supervision density, allowing direct measurement of its impact on training speed and final performance. revision: yes
-
Referee: [Update-Direction Level] Update-Direction Level analysis: the claim of stronger low-rank concentration and early alignment with the final subspace is supported by trajectory plots, but the text does not report statistical significance, run-to-run variance, or quantitative metrics (e.g., subspace overlap angles with error bars) that would establish the alignment is reliably stronger than in baseline methods.
Authors: We acknowledge that the present version relies primarily on visual trajectory plots. In revision we will augment the analysis with quantitative metrics, specifically principal angles between dominant subspaces computed across multiple independent runs, reported with error bars and accompanied by statistical significance tests (e.g., paired t-tests) against baseline methods. This will establish the reliability and statistical strength of the early-alignment observation. revision: yes
-
Referee: [EffOPD experiments] EffOPD evaluation: the reported average 3x speedup and maintained performance rest on comparisons whose controls, task diversity, model scales, and statistical tests are not fully detailed; without these, it remains unclear whether adaptive extrapolation along the current direction generalizes without occasional degradation of final performance.
Authors: We appreciate the call for greater experimental transparency. The revised manuscript will expand the evaluation section to explicitly document all controls (hyperparameter matching, seed handling), enumerate the full set of tasks and datasets used, report results with standard deviations over multiple runs, and include appropriate statistical tests. We will also discuss any observed performance variance and how the adaptive extrapolation mechanism behaves across the reported settings. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's argument rests on empirical observations of training trajectories (module utility concentration and low-rank subspace alignment) in OPD versus baselines, followed by the design of EffOPD as an extrapolation heuristic. No equations or definitions are presented that make the claimed foresight reduce to a self-referential fit, a renamed parameter, or a self-citation chain. The central efficiency claim is supported by direct experimental comparisons within the study rather than by construction from prior fitted inputs or unverified uniqueness theorems. This is the common case of an observational paper whose derivation remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2023 , eprint=
Locating and Editing Factual Associations in GPT , author=. 2023 , eprint=
2023
-
[2]
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2025 , eprint=
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning , author=. 2025 , eprint=
2025
-
[4]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[5]
2024 , eprint=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
2024
-
[6]
2025 , eprint=
SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning , author=. 2025 , eprint=
2025
-
[7]
2017 , eprint=
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm , author=. 2017 , eprint=
2017
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year=
SimPO: Simple Preference Optimization with a Reference-Free Reward , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[9]
2024 , eprint=
KTO: Model Alignment as Prospect Theoretic Optimization , author=. 2024 , eprint=
2024
-
[10]
2024 , eprint=
Understanding the performance gap between online and offline alignment algorithms , author=. 2024 , eprint=
2024
-
[11]
2025 , eprint=
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks , author=. 2025 , eprint=
2025
-
[12]
International Joint Conference on Artificial Intelligence , year=
Dynamic Sparse Training for Deep Reinforcement Learning , author=. International Joint Conference on Artificial Intelligence , year=
-
[13]
2024 , eprint=
Low-Rank Adaptation for Foundation Models: A Comprehensive Review , author=. 2024 , eprint=
2024
-
[14]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Aghajanyan, Armen and Gupta, Sonal and Zettlemoyer, Luke. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.a...
-
[15]
2025 , eprint=
Reinforcement Learning Enhanced LLMs: A Survey , author=. 2025 , eprint=
2025
-
[16]
2025 , eprint=
From Trial-and-Error to Improvement: A Systematic Analysis of LLM Exploration Mechanisms in RLVR , author=. 2025 , eprint=
2025
-
[17]
2015 , eprint=
The Singular Value Decomposition, Applications and Beyond , author=. 2015 , eprint=
2015
-
[18]
Paul Geladi and Bruce R. Kowalski , abstract =. Partial least-squares regression: a tutorial , journal =. 1986 , issn =. doi:https://doi.org/10.1016/0003-2670(86)80028-9 , url =
-
[19]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[20]
Matrix Factorization Techniques for Recommender Systems , year=
Koren, Yehuda and Bell, Robert and Volinsky, Chris , journal=. Matrix Factorization Techniques for Recommender Systems , year=
-
[21]
2025 , eprint=
A Survey of Reinforcement Learning for Large Reasoning Models , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
Demystifying Reasoning Dynamics with Mutual Information: Thinking Tokens are Information Peaks in LLM Reasoning , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
I Have Covered All the Bases Here: Interpreting Reasoning Features in Large Language Models via Sparse Autoencoders , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
RL's Razor: Why Online Reinforcement Learning Forgets Less , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
Improving Generalization in Intent Detection: GRPO with Reward-Based Curriculum Sampling , author=. 2025 , eprint=
2025
-
[27]
Prefix-tuning: Optimizing continuous prompts for generation
Li, Xiang Lisa and Liang, Percy. Prefix-Tuning: Optimizing Continuous Prompts for Generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.353
-
[28]
2023 , eprint=
RLx2: Training a Sparse Deep Reinforcement Learning Model from Scratch , author=. 2023 , eprint=
2023
-
[29]
2022 , eprint=
A Win-win Deal: Towards Sparse and Robust Pre-trained Language Models , author=. 2022 , eprint=
2022
-
[30]
2023 , eprint=
Task-Specific Skill Localization in Fine-tuned Language Models , author=. 2023 , eprint=
2023
-
[31]
2024 , eprint=
Discovering Knowledge-Critical Subnetworks in Pretrained Language Models , author=. 2024 , eprint=
2024
-
[32]
The Thirteenth International Conference on Learning Representations , year=
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[33]
2024 , eprint=
Parameter Efficient Reinforcement Learning from Human Feedback , author=. 2024 , eprint=
2024
-
[34]
2025 , eprint=
Group Sequence Policy Optimization , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
Kimi K2: Open Agentic Intelligence , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? , author=. 2025 , eprint=
2025
-
[38]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=. 2024 , url=
2024
-
[39]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[40]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[41]
HybridFlow: A Flexible and Efficient RLHF Framework , url=
Sheng, Guangming and Zhang, Chi and Ye, Zilingfeng and Wu, Xibin and Zhang, Wang and Zhang, Ru and Peng, Yanghua and Lin, Haibin and Wu, Chuan , year=. HybridFlow: A Flexible and Efficient RLHF Framework , url=. doi:10.1145/3689031.3696075 , booktitle=
-
[42]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
-
[45]
Group Sequence Policy Optimization
Group Sequence Policy Optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
2025 , eprint=
Thought Anchors: Which LLM Reasoning Steps Matter? , author=. 2025 , eprint=
2025
-
[47]
2025 , eprint=
Internal Bias in Reasoning Models leads to Overthinking , author=. 2025 , eprint=
2025
-
[48]
2025 , eprint=
Understanding Aha Moments: from External Observations to Internal Mechanisms , author=. 2025 , eprint=
2025
-
[49]
2025 , eprint=
Chain-of-Thought Reasoning In The Wild Is Not Always Faithful , author=. 2025 , eprint=
2025
-
[50]
2024 , eprint=
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs , author=. 2024 , eprint=
2024
-
[51]
2025 , eprint=
LIMO: Less is More for Reasoning , author=. 2025 , eprint=
2025
-
[52]
2025 , eprint=
On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification , author=. 2025 , eprint=
2025
-
[53]
2015 , eprint=
Distilling the Knowledge in a Neural Network , author=. 2015 , eprint=
2015
-
[54]
2025 , eprint=
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model , author=. 2025 , eprint=
2025
-
[55]
2025 , eprint=
Reinforcement Learning Fine-Tunes a Sparse Subnetwork in Large Language Models , author=. 2025 , eprint=
2025
-
[56]
2025 , eprint=
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning , author=. 2025 , eprint=
2025
-
[57]
2025 , eprint=
Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization , author=. 2025 , eprint=
2025
-
[58]
Ji, Ke and. The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models , publisher =. doi:10.13140/RG.2.2.33772.07043 , url =
-
[59]
2021 , eprint=
Transformer Feed-Forward Layers Are Key-Value Memories , author=. 2021 , eprint=
2021
-
[60]
2024 , eprint=
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author=. 2024 , eprint=
2024
-
[61]
2025 , eprint=
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention , author=. 2025 , eprint=
2025
-
[62]
2025 , eprint=
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models , author=. 2025 , eprint=
2025
-
[63]
2024 , eprint=
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools , author=. 2024 , eprint=
2024
-
[64]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[65]
Soft Adaptive Policy Optimization
Soft adaptive policy optimization , author=. arXiv preprint arXiv:2511.20347 , year=
work page internal anchor Pith review arXiv
-
[66]
2024 , eprint=
O-Edit: Orthogonal Subspace Editing for Language Model Sequential Editing , author=. 2024 , eprint=
2024
-
[67]
2023 , eprint=
GPQA: A Graduate-Level Google-Proof Q&A Benchmark , author=. 2023 , eprint=
2023
-
[68]
The twelfth international conference on learning representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The twelfth international conference on learning representations , year=
-
[69]
MiMo-V2-Flash Technical Report
Mimo-v2-flash technical report , author=. arXiv preprint arXiv:2601.02780 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
A Survey of On-Policy Distillation for Large Language Models
A Survey of On-Policy Distillation for Large Language Models , author=. arXiv preprint arXiv:2604.00626 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes , author=. arXiv preprint arXiv:2603.25562 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
Learning beyond teacher: Generalized on-policy distillation with reward extrapolation , author=. arXiv preprint arXiv:2602.12125 , year=
-
[73]
arXiv preprint arXiv:2603.11137 , year =
Scaling Reasoning Efficiently via Relaxed On-Policy Distillation , author=. arXiv preprint arXiv:2603.11137 , year=
-
[74]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author=. arXiv preprint arXiv:2604.13016 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
arXiv preprint arXiv:2510.00553 , year=
On predictability of reinforcement learning dynamics for large language models , author=. arXiv preprint arXiv:2510.00553 , year=
-
[76]
2026 , eprint=
Scaling Behaviors of LLM Reinforcement Learning Post-Training: An Empirical Study in Mathematical Reasoning , author=. 2026 , eprint=
2026
-
[77]
arXiv preprint arXiv:2603.08660 , year=
How Far Can Unsupervised RLVR Scale LLM Training? , author=. arXiv preprint arXiv:2603.08660 , year=
-
[78]
Layer by layer: Uncovering hidden representations in language models , author=. arXiv preprint arXiv:2502.02013 , year=
-
[79]
ArXiv , year=
A Survey of Reinforcement Learning for Large Reasoning Models , author=. ArXiv , year=
-
[80]
2026 , url=
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs? , author=. 2026 , url=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.