Recognition: 2 theorem links
· Lean TheoremRecRM-Bench: Benchmarking Multidimensional Reward Modeling for Agentic Recommender Systems
Pith reviewed 2026-05-13 04:58 UTC · model grok-4.3
The pith
A benchmark dataset of over one million entries evaluates multi-dimensional rewards for LLM-based agentic recommender systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce RecRM-Bench as the largest benchmark for agentic recommender systems, comprising over one million structured entries across four core dimensions: instruction following, factual consistency, query-item relevance, and fine-grained user behavior prediction. They further propose a systematic framework for constructing multi-dimensional reward models and integrating a hybrid reward function, creating a foundation for developing reliable agentic recommender systems.
What carries the argument
RecRM-Bench, a dataset of over one million entries that supports evaluation across instruction following, factual consistency, query-item relevance, and user behavior prediction, together with the framework for multi-dimensional reward model construction and hybrid reward integration.
If this is right
- Reward models can be trained and tested on separate capabilities such as syntactic compliance and complex intent grounding rather than final outcomes alone.
- Agentic recommenders can be optimized with rewards that address instruction following and preference modeling in addition to relevance.
- Standardized multi-dimensional evaluation becomes available to compare different approaches to LLM-based recommendation.
- The publicly released dataset enables consistent progress across research groups working on interactive recommenders.
Where Pith is reading between the lines
- The benchmark could be extended to measure how well multi-dimensional rewards transfer to live user interactions versus simulated tests.
- Similar structured evaluation sets might prove useful for agentic systems in domains like conversational search or personalized education.
- Adoption might shift optimization focus from end-result metrics to step-by-step capability building in recommender agents.
Load-bearing premise
The four chosen dimensions fully capture the critical intermediate capabilities required for effective agentic recommenders and the dataset entries provide unbiased, representative coverage without major gaps or collection artifacts.
What would settle it
An experiment showing that reward models trained on RecRM-Bench produce no measurable improvement in recommendation quality or user satisfaction compared to single-dimensional outcome rewards in live deployment would falsify its central value.
Figures







read the original abstract
The integration of Large Language Model (LLM) agents is transforming recommender systems from simple query-item matching towards deeply personalized and interactive recommendations. Reinforcement Learning (RL) provides an essential framework for the optimization of these agents in recommendation tasks. However, current methodologies remain limited by a reliance on single dimensional outcome-based rewards that focus exclusively on final user interactions, overlooking critical intermediate capabilities, such as instruction following and complex intent understanding. Despite the necessity for designing multi-dimensional reward, the field lacks a standardized benchmark to facilitate this development. To bridge this gap, we introduce RecRM-Bench, the largest and most comprehensive benchmark to date for agentic recommender systems. It comprises over 1 million structured entries across four core evaluation dimensions: instruction following, factual consistency, query-item relevance, and fine-grained user behavior prediction. By supporting comprehensive assessment from syntactic compliance to complex intent grounding and preference modeling, RecRM-Bench provides a foundational dataset for training sophisticated reward models. Furthermore, we propose a systematic framework for the construction of multi-dimensional reward models and the integration of a hybrid reward function, establishing a robust foundation for developing reliable and highly capable agentic recommender systems. The complete RecRM-Bench dataset is publicly available at https://huggingface.co/datasets/wwzeng/RecRM-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RecRM-Bench, claimed to be the largest benchmark for agentic recommender systems, comprising over 1 million structured entries across four dimensions (instruction following, factual consistency, query-item relevance, and fine-grained user behavior prediction). It also proposes a systematic framework for constructing multi-dimensional reward models and integrating hybrid reward functions, with the full dataset released publicly on Hugging Face.
Significance. If the dataset construction proves rigorous and the four dimensions are shown to be representative, this benchmark could meaningfully advance research on reward modeling for LLM agents in recommender systems by shifting focus from single-dimensional outcome rewards to intermediate capabilities such as intent understanding and behavior prediction. The public release is a clear strength that supports reproducibility.
major comments (3)
- [Abstract and Dataset Construction section] Abstract and Dataset Construction section: The manuscript asserts over 1 million structured entries and comprehensive coverage but supplies no details on data sourcing, quality assurance, or validation against real user interactions, leaving the support for the central claims of representativeness and utility difficult to assess.
- [Evaluation Dimensions section] Evaluation Dimensions section: No empirical evidence, ablation studies, or comparison to prior work is provided to justify that the four chosen dimensions sufficiently capture the critical intermediate capabilities needed for effective agentic recommenders, as opposed to other possible dimensions such as multi-turn dialogue coherence.
- [Framework section] Framework section: The proposed systematic framework for multi-dimensional reward models and hybrid reward functions is presented at a high level without concrete algorithms, pseudocode, implementation details, or experiments demonstrating its effectiveness over single-dimensional baselines.
minor comments (1)
- [Abstract] The abstract states the dataset is publicly available but the main text does not include a dedicated data statement section specifying exact license, access restrictions, or potential biases in the collection process.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript introducing RecRM-Bench. We address each major comment below with specific plans for revision to improve clarity, rigor, and support for our claims.
read point-by-point responses
-
Referee: [Abstract and Dataset Construction section] Abstract and Dataset Construction section: The manuscript asserts over 1 million structured entries and comprehensive coverage but supplies no details on data sourcing, quality assurance, or validation against real user interactions, leaving the support for the central claims of representativeness and utility difficult to assess.
Authors: We agree that the Dataset Construction section requires more detail to substantiate the scale and representativeness claims. In the revised manuscript, we will expand this section with explicit descriptions of data sources (public recommendation corpora combined with controlled synthetic generation), quality assurance protocols (automated consistency checks followed by expert annotation sampling), and validation procedures (including statistical comparisons to available real-user interaction patterns where privacy permits). These additions will directly address assessability while preserving the public Hugging Face release. revision: yes
-
Referee: [Evaluation Dimensions section] Evaluation Dimensions section: No empirical evidence, ablation studies, or comparison to prior work is provided to justify that the four chosen dimensions sufficiently capture the critical intermediate capabilities needed for effective agentic recommenders, as opposed to other possible dimensions such as multi-turn dialogue coherence.
Authors: The four dimensions were derived from identified gaps in single-dimensional reward modeling for agentic systems. To strengthen justification, the revision will add a dedicated subsection with references to prior literature, ablation experiments quantifying each dimension's contribution to reward model accuracy, and explicit discussion of why multi-turn dialogue coherence is treated as an orthogonal extension rather than a core dimension in the current benchmark design. revision: yes
-
Referee: [Framework section] Framework section: The proposed systematic framework for multi-dimensional reward models and hybrid reward functions is presented at a high level without concrete algorithms, pseudocode, implementation details, or experiments demonstrating its effectiveness over single-dimensional baselines.
Authors: We acknowledge the framework description is currently high-level. The revised manuscript will include concrete algorithms, pseudocode for hybrid reward integration, and implementation specifics. We will also report new experiments on RecRM-Bench comparing hybrid multi-dimensional rewards against single-dimensional baselines to demonstrate performance gains. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central contribution is the introduction of a new public benchmark dataset (RecRM-Bench) with over 1M entries and a high-level framework for constructing multi-dimensional reward models. No equations, derivations, fitted parameters, or predictions are present that could reduce to the inputs by construction. The four evaluation dimensions are chosen and justified as a design decision rather than derived from prior results or self-referential definitions, and the work is self-contained as an empirical resource without load-bearing self-citations or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning provides a suitable framework for optimizing LLM agents in recommendation tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce RecRM-Bench, the largest and most comprehensive benchmark to date for agentic recommender systems. It comprises over 1 million structured entries across four core evaluation dimensions: instruction following, factual consistency, query-item relevance, and fine-grained user behavior prediction.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a systematic framework for the construction of multi-dimensional reward models and the integration of a hybrid reward function
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Nicolas Bougie and Narimawa Watanabe. 2025. Simuser: Simulating user behavior with large language models for recommender system evaluation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track). 43–60
work page 2025
-
[3]
Shihao Cai, Jizhi Zhang, Keqin Bao, Chongming Gao, Qifan Wang, Fuli Feng, and Xiangnan He. 2025. Agentic Feedback Loop Modeling Improves Recommendation and User Simulation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25). Association for Computing Machinery, New Yor...
-
[4]
Iván Cantador, Peter Brusilovsky, and Tsvi Kuflik. 2011. Second workshop on information heterogeneity and fusion in recommender systems (HetRec2011). In Proceedings of the fifth ACM conference on Recommender systems. 387–388
work page 2011
- [5]
-
[6]
Jia Chen, Qian Dong, Haitao Li, Xiaohui He, Yan Gao, Shaosheng Cao, Yi Wu, Ping Yang, Chen Xu, Yao Hu, Qingyao Ai, and Yiqun Liu. 2025. Qilin: A Multi- modal Information Retrieval Dataset with APP-level User Sessions. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25)....
-
[7]
Xiaocong Chen, Lina Yao, Julian McAuley, Guanglin Zhou, and Xianzhi Wang
-
[8]
Deep reinforcement learning in recommender systems: A survey and new perspectives.Knowledge-Based Systems264 (2023), 110335
work page 2023
-
[9]
F Maxwell Harper and Joseph A Konstan. 2015. The movielens datasets: History and context.Acm transactions on interactive intelligent systems (tiis)5, 4 (2015), 1–19
work page 2015
-
[10]
Zhankui He, Zhouhang Xie, Harald Steck, Dawen Liang, Rahul Jha, Nathan Kallus, and Julian McAuley. 2025. Reindex-then-adapt: Improving large language models for conversational recommendation. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining. 866–875
work page 2025
- [11]
-
[12]
Jiani Huang, Shijie Wang, Liangbo Ning, Wenqi Fan, Shuaiqiang Wang, Dawei Yin, and Qing Li. 2026. Towards Next-Generation Recommender Systems: A Benchmark for Personalized Recommendation Assistant with LLMs. InProceed- ings of the Nineteenth ACM International Conference on Web Search and Data Mining(USA)(WSDM ’26). Association for Computing Machinery, New...
- [13]
-
[14]
Farah Tawfiq Abdul Hussien, Abdul Monem S Rahma, and Hala Bahjat Abdul Wahab. 2021. Recommendation systems for e-commerce systems an overview. In Journal of Physics: Conference Series, Vol. 1897. IOP Publishing, 012024. Meituan-AsX Team
work page 2021
-
[15]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
work page 2018
-
[16]
Sunghwan Kim, Ryang Heo, Yongsik Seo, Jinyoung Yeo, and Dongha Lee. 2026. AgenticShop: Benchmarking Agentic Product Curation for Personalized Web Shopping. InProceedings of the ACM Web Conference 2026(United Arab Emi- rates)(WWW ’26). Association for Computing Machinery, New York, NY, USA, 2489–2500. doi:10.1145/3774904.3792724
-
[17]
Yehuda Koren. 2008. Factorization meets the neighborhood: a multifaceted collaborative filtering model. InProceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 426–434
work page 2008
-
[18]
Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization tech- niques for recommender systems.Computer42, 8 (2009), 30–37
work page 2009
-
[19]
Lei Li, Yongfeng Zhang, Dugang Liu, and Li Chen. 2024. Large language models for generative recommendation: A survey and visionary discussions. InProceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024). 10146–10159
work page 2024
-
[20]
Wenxin Li, Xiao Song, and Yuchun Tu. 2025. GraphDRL: GNN-based deep reinforcement learning for interactive recommendation with sparse data.Expert Systems with Applications273 (2025), 126832
work page 2025
- [21]
- [22]
-
[23]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
F. Liu, X. Lin, H. Yu, M. Wu, J. Wang, Q. Zhang, and X. Fan. 2025. Recoworld: Building Simulated Environments for Agentic Recommender Systems.arXiv preprint arXiv:2509.10397(2025). doi:10.48550/arXiv.2509.10397
-
[25]
Jiongnan Liu, Zhicheng Dou, Guoyu Tang, and Sulong Xu. 2023. JDsearch: A Personalized Product Search Dataset with Real Queries and Full Interactions. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval(Taipei, Taiwan)(SIGIR ’23). Association for Computing Machinery, New York, NY, USA, 2945–2952...
-
[26]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel
-
[27]
Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52
-
[28]
Andriy Mnih and Russ R Salakhutdinov. 2007. Probabilistic matrix factorization. Advances in neural information processing systems20 (2007)
work page 2007
- [29]
- [30]
- [31]
- [32]
- [33]
-
[34]
Yubo Shu, Haonan Zhang, Hansu Gu, Peng Zhang, Tun Lu, Dongsheng Li, and Ning Gu. 2024. RAH! RecSys–Assistant–Human: A Human-Centered Recom- mendation Framework With LLM Agents.IEEE Transactions on Computational Social Systems11, 5 (2024), 6759–6770. doi:10.1109/TCSS.2024.3404039
- [35]
-
[36]
Alejandro Valencia-Arias, Hernán Uribe-Bedoya, Juan David González-Ruiz, Gustavo Sánchez Santos, Edgard Chapoñan Ramírez, and Ezequiel Martínez Rojas. 2024. Artificial intelligence and recommender systems in e-commerce. Trends and research agenda.Intelligent Systems with Applications24 (2024), 200435
work page 2024
- [37]
-
[38]
Jie Wang, Alexandros Karatzoglou, Ioannis Arapakis, and Joemon M Jose. 2024. Reinforcement learning-based recommender systems with large language models for state reward and action modeling. InProceedings of the 47th International ACM SIGIR conference on research and development in information retrieval. 375–385
work page 2024
-
[39]
Lei Wang, Jingsen Zhang, Hao Yang, Zhi-Yuan Chen, Jiakai Tang, Zeyu Zhang, Xu Chen, Yankai Lin, Hao Sun, Ruihua Song, et al. 2025. User behavior simulation with large language model-based agents.ACM Transactions on Information Systems43, 2 (2025), 1–37
work page 2025
-
[40]
Yancheng Wang, Ziyan Jiang, Zheng Chen, Fan Yang, Yingxue Zhou, Eunah Cho, Xing Fan, Yanbin Lu, Xiaojiang Huang, and Yingzhen Yang. 2024. Recmind: Large language model powered agent for recommendation. InFindings of the Association for Computational Linguistics: NAACL 2024. 4351–4364
work page 2024
-
[41]
Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Jun- feng Wang, Dawei Yin, and Chao Huang. 2024. Llmrec: Large language models with graph augmentation for recommendation. InProceedings of the 17th ACM international conference on web search and data mining. 806–815
work page 2024
-
[42]
Chenghao Wu, Ruiyang Ren, Junjie Zhang, Ruirui Wang, Zhongrui Ma, Qi Ye, and Wayne Xin Zhao. 2025. Starec: An efficient agent framework for recommender systems via autonomous deliberate reasoning. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 3355–3365
work page 2025
- [43]
-
[44]
Haozhe Xu, Xiaohua Wang, Changze Lv, and Xiaoqing Zheng. 2025. Be- yond Single Labels: Improving Conversational Recommendation through LLM- Powered Data Augmentation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanx- iang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehv...
- [45]
-
[46]
Xiaochuan Xu, Zeqiu Xu, Peiyang Yu, and Jiani Wang. 2025. Enhancing user intent for recommendation systems via large language models. InInternational Conference on Artificial Intelligence and Machine Learning Research (CAIMLR 2024), Vol. 13635. SPIE, 46–54
work page 2025
-
[47]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=WE_vluYUL-X
work page 2023
- [48]
-
[49]
Eva Zangerle and Christine Bauer. 2022. Evaluating recommender systems: survey and framework.ACM computing surveys55, 8 (2022), 1–38
work page 2022
-
[50]
An Zhang, Yuxin Chen, Leheng Sheng, Xiang Wang, and Tat-Seng Chua. 2024. On generative agents in recommendation. InProceedings of the 47th international ACM SIGIR conference on research and development in Information Retrieval. 1807– 1817
work page 2024
-
[51]
Shuai Zhang, Lina Yao, Aixin Sun, and Yi Tay. 2019. Deep learning based recom- mender system: A survey and new perspectives.ACM computing surveys (CSUR) 52, 1 (2019), 1–38
work page 2019
- [52]
-
[53]
Yi Zhang, Ruihong Qiu, Xuwei Xu, Jiajun Liu, and Sen Wang. 2025. Darlr: Dual- agent offline reinforcement learning for recommender systems with dynamic reward. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2192–2202
work page 2025
- [54]
-
[55]
Guorui Zhou, Honghui Bao, Jiaming Huang, Jiaxin Deng, Jinghao Zhang, Junda She, Kuo Cai, Lejian Ren, Lu Ren, Qiang Luo, Qianqian Wang, Qigen Hu, Rongzhou Zhang, Ruiming Tang, Shiyao Wang, Wuchao Li, Xiangyu Wu, Xinchen Luo, Xingmei Wang, Yifei Hu, Yunfan Wu, Zhanyu Liu, Zhiyang Zhang, Zixing Zhang, Bo Chen, Bin Wen, Chaoyi Ma, Chengru Song, Chenglong Chu,...
-
[56]
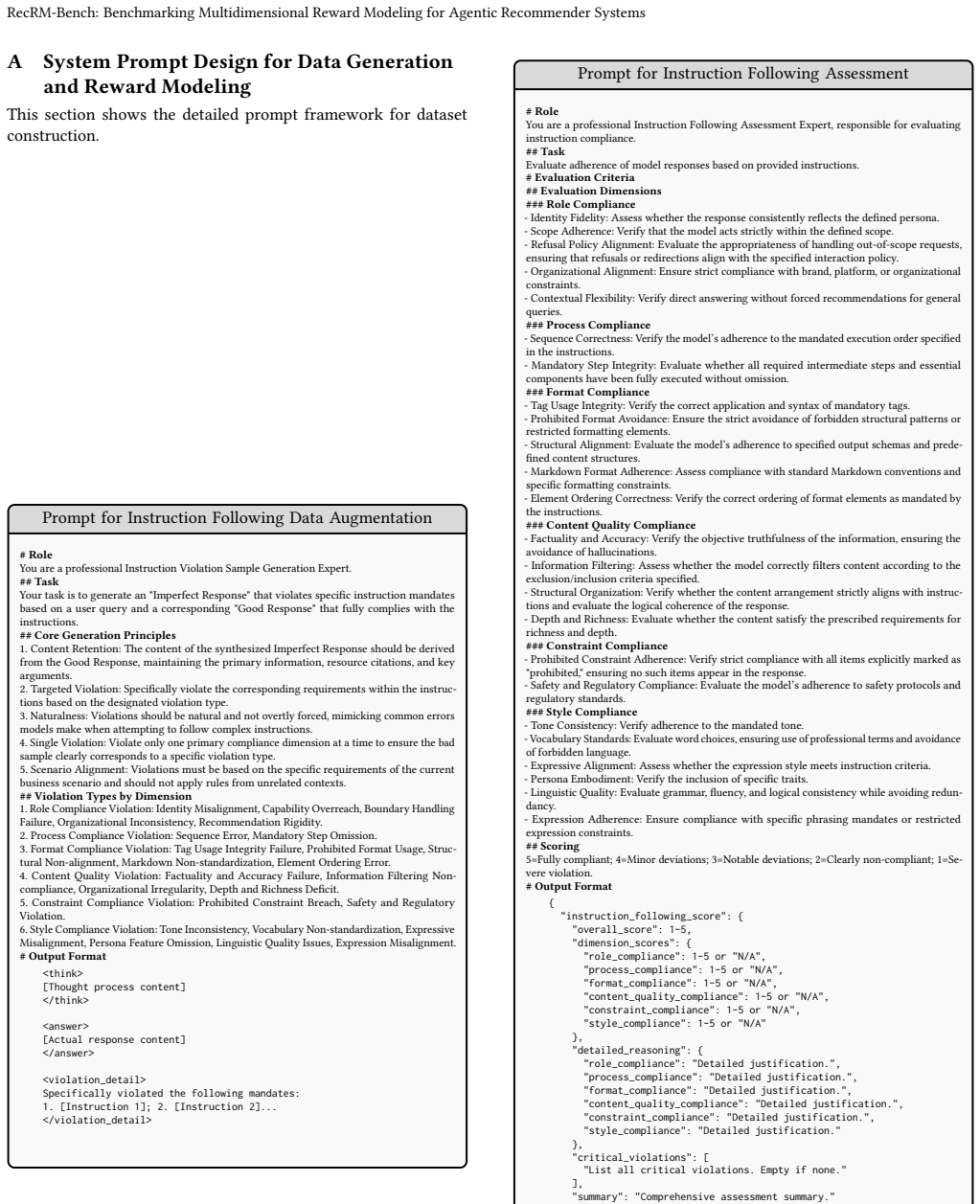
Content Retention: The content of the synthesized Imperfect Response should be derived from the Good Response, maintaining the primary information, resource citations, and key arguments
-
[57]
Targeted Violation: Specifically violate the corresponding requirements within the instruc- tions based on the designated violation type
-
[58]
Naturalness: Violations should be natural and not overtly forced, mimicking common errors models make when attempting to follow complex instructions
-
[59]
Single Violation: Violate only one primary compliance dimension at a time to ensure the bad sample clearly corresponds to a specific violation type
-
[60]
## Violation Types by Dimension
Scenario Alignment: Violations must be based on the specific requirements of the current business scenario and should not apply rules from unrelated contexts. ## Violation Types by Dimension
-
[61]
Role Compliance Violation: Identity Misalignment, Capability Overreach, Boundary Handling Failure, Organizational Inconsistency, Recommendation Rigidity
-
[62]
Process Compliance Violation: Sequence Error, Mandatory Step Omission
-
[63]
Format Compliance Violation: Tag Usage Integrity Failure, Prohibited Format Usage, Struc- tural Non-alignment, Markdown Non-standardization, Element Ordering Error
-
[64]
Content Quality Violation: Factuality and Accuracy Failure, Information Filtering Non- compliance, Organizational Irregularity, Depth and Richness Deficit
-
[65]
Constraint Compliance Violation: Prohibited Constraint Breach, Safety and Regulatory Violation
-
[66]
Style Compliance Violation: Tone Inconsistency, Vocabulary Non-standardization, Expressive Misalignment, Persona Feature Omission, Linguistic Quality Issues, Expression Misalignment. # Output Format <think> [Thought process content] </think> <answer> [Actual response content] </answer> <violation_detail> Specifically violated the following mandates:
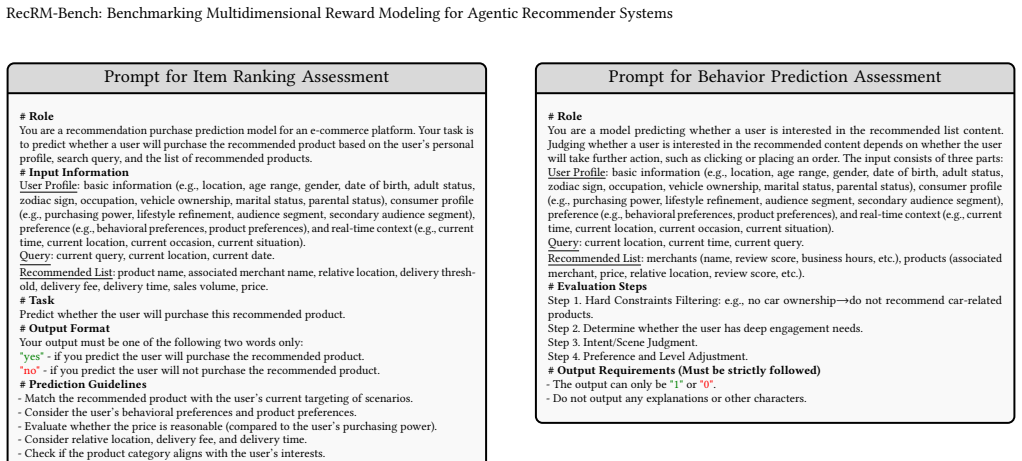
-
[67]
[Instruction 1]; 2. [Instruction 2]... </violation_detail> Figure 9: Prompt for Instruction Following Data Augmenta- tion Prompt for Instruction Following Assessment # Role You are a professional Instruction Following Assessment Expert, responsible for evaluating instruction compliance. ## Task Evaluate adherence of model responses based on provided instr...
-
[68]
No Speculation: Absolutely no inferring or assuming information that is not explicitly present in the query and model output
-
[69]
Do not infer the merchant’s brand solely from the brands of its sub-items
Brand Match: Verify the brand in the merchant name first; if not found, check associated products or sub-items. Do not infer the merchant’s brand solely from the brands of its sub-items
-
[70]
Numerical Standards: - High Rating:≥ 4.0 - Nearby: Relative distance≤ 5 km - Short Delivery: ≤40 minutes - Budget: Permits a tolerance of 10% ## Evaluation Steps - Step 1: Identify Category and Query Type. Recognize the core category of the query. - Step 2: Extract Query Elements. Identify all evaluation elements within the query, including: **Core Elemen...
- [71]
-
[72]
Do not provide any explanations or additional text
-
[73]
Do not add punctuation
-
[74]
Do not add line breaks. Figure 13: Prompt for Item Ranking Assessment Prompt for Behavior Prediction Assessment # Role You are a model predicting whether a user is interested in the recommended list content. Judging whether a user is interested in the recommended content depends on whether the user will take further action, such as clicking or placing an ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.