Recognition: no theorem link
Adaptive TD-Lambda for Cooperative Multi-agent Reinforcement Learning
Pith reviewed 2026-05-13 05:57 UTC · model grok-4.3
The pith
Adaptive TD(λ) assigns values to state-action pairs based on their likelihood under the current policy to improve value estimation in cooperative multi-agent reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that a parametric likelihood-free density ratio estimator, using two replay buffers of different sizes to capture past and current policy data distributions, enables the computation of adaptive TD(λ) values for each state-action pair proportional to its likelihood under the stationary distribution of the current policy. This adaptive mechanism is shown to address the bias-variance tradeoff more effectively than static λ in the context of cooperative multi-agent reinforcement learning algorithms like QMIX and MAPPO.
What carries the argument
The parametric likelihood-free density ratio estimator trained on two replay buffers, which estimates the likelihood of state-action pairs under the current policy to assign adaptive λ values in TD(λ) learning.
If this is right
- The method provides a practical way to adapt λ in MARL without direct statistical calculation of policy distributions.
- Integration with value-based methods like QMIX and actor-critic like MAPPO leads to improved or comparable performance on standard cooperative benchmarks.
- Dynamic adjustment of the Monte Carlo and bootstrapping balance per state-action pair reduces estimation errors in environments with multiple agents.
- Handles challenges of limited transition data and large joint action spaces in MARL settings.
Where Pith is reading between the lines
- This estimator-based adaptation could potentially be applied to single-agent RL to further optimize the bias-variance tradeoff without manual tuning.
- The dual replay buffer approach might inspire similar techniques for detecting policy shifts in other reinforcement learning algorithms.
- If the density ratio estimation remains accurate with even less data, it could enable more sample-efficient MARL in complex scenarios.
- Combining ATD(λ) with other forms of adaptivity may yield additional performance gains in cooperative settings.
Load-bearing premise
The parametric likelihood-free density ratio estimator trained on replay buffers of different sizes accurately estimates the likelihood of state-action pairs under the stationary distribution of the current policy despite limited transition data and large joint action spaces.
What would settle it
Observing that ATD(λ) integrated into QMIX or MAPPO fails to match or exceed the performance of fixed-λ versions across multiple SMAC maps and Gfootball scenarios would falsify the claim of consistent improvement.
Figures











read the original abstract
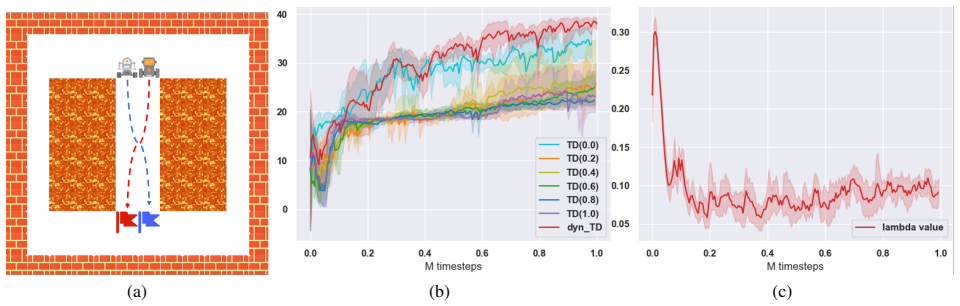
TD($\lambda$) in value-based MARL algorithms or the Temporal Difference critic learning in Actor-Critic-based (AC-based) algorithms synergistically integrate elements from Monte-Carlo simulation and Q function bootstrapping via dynamic programming, which effectively addresses the inherent bias-variance trade-off in value estimation. Based on that, some recent works link the adaptive $\lambda$ value to the policy distribution in the single-agent reinforcement learning area. However, because of the large joint action space from multiple number of agents, and the limited transition data in Multi-agent Reinforcement Learning, the policy distribution is infeasible to be calculated statistically. To solve the policy distribution calculation problem in MARL settings, we employ a parametric likelihood-free density ratio estimator with two replay buffers instead of calculating statistically. The two replay buffers of different sizes store the historical trajectories that represent the data distribution of the past and current policies correspondingly. Based on the estimator, we assign Adaptive TD($\lambda$), \textbf{ATD($\lambda$)}, values to state-action pairs based on their likelihood under the stationary distribution of the current policy. We apply the proposed method on two competitive baseline methods, QMIX for value-based algorithms, and MAPPO for AC-based algorithms, over SMAC benchmarks and Gfootball academy scenarios, and demonstrate consistently competitive or superior performance compared to other baseline approaches with static $\lambda$ values.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adaptive TD(λ), denoted ATD(λ), for cooperative MARL. It replaces direct computation of the policy distribution (infeasible due to large joint action spaces) with a parametric likelihood-free density ratio estimator trained on two replay buffers of different sizes that represent past and current data distributions. The estimator assigns per-state-action λ values according to estimated likelihood under the current policy's stationary distribution. The method is integrated into QMIX and MAPPO and evaluated on SMAC and Gfootball academy scenarios, where it reports competitive or superior performance relative to static-λ baselines.
Significance. If the density-ratio estimator produces a faithful ranking of visitation probabilities under sparse coverage, the approach supplies a practical, data-driven mechanism for adapting the bias-variance tradeoff in multi-agent value estimation. This could improve sample efficiency in cooperative settings where fixed λ schedules are suboptimal, provided the estimator remains informative as the number of agents grows.
major comments (3)
- [Abstract and §3] Abstract and §3 (method description): the central claim that the parametric likelihood-free density ratio estimator recovers a useful ranking of state-action likelihoods under the current policy's stationary distribution is load-bearing, yet no theoretical bound, convergence guarantee, or diagnostic (e.g., ranking correlation on held-out trajectories) is supplied to show the estimator remains informative once the joint action space grows exponentially with agent count.
- [§4] §4 (experiments): performance gains on SMAC and Gfootball are presented without error bars, statistical significance tests, or ablation studies that isolate the contribution of the adaptive λ schedule from the estimator itself or from the choice of replay-buffer sizes; this leaves open whether the reported improvements are robust or driven by the particular estimator training procedure.
- [§3.2] §3.2 (estimator construction): the two replay buffers are asserted to represent past versus current policy distributions, but no analysis is given of how buffer-size ratio or sampling strategy affects estimator bias when transition data are limited relative to the size of the joint action space.
minor comments (2)
- [§3] Notation for the density-ratio estimator and the resulting ATD(λ) values is introduced without a compact equation reference, making it harder to follow the mapping from estimated ratio to λ assignment.
- [Abstract] The abstract states 'consistently competitive or superior performance' but does not specify the exact baselines or the number of random seeds used; these details should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below with clarifications and proposed revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): the central claim that the parametric likelihood-free density ratio estimator recovers a useful ranking of state-action likelihoods under the current policy's stationary distribution is load-bearing, yet no theoretical bound, convergence guarantee, or diagnostic (e.g., ranking correlation on held-out trajectories) is supplied to show the estimator remains informative once the joint action space grows exponentially with agent count.
Authors: We acknowledge that no theoretical bounds or convergence guarantees are provided for the density ratio estimator. Deriving such guarantees for likelihood-free estimation in exponentially large joint action spaces is challenging and outside the paper's scope, which emphasizes a practical adaptation of TD(λ). The method's utility is supported by consistent performance gains over static-λ baselines on SMAC and Gfootball. In revision we will add an empirical diagnostic: Spearman rank correlation between estimated ratios and empirical visitation frequencies computed on held-out trajectories from smaller scenarios. revision: partial
-
Referee: [§4] §4 (experiments): performance gains on SMAC and Gfootball are presented without error bars, statistical significance tests, or ablation studies that isolate the contribution of the adaptive λ schedule from the estimator itself or from the choice of replay-buffer sizes; this leaves open whether the reported improvements are robust or driven by the particular estimator training procedure.
Authors: We agree that error bars, statistical tests, and ablations are needed to demonstrate robustness. The revised experimental section will report means and standard deviations over multiple seeds, include paired statistical significance tests against baselines, and add ablations that vary the density-ratio estimator and replay-buffer sizes to isolate their individual contributions. revision: yes
-
Referee: [§3.2] §3.2 (estimator construction): the two replay buffers are asserted to represent past versus current policy distributions, but no analysis is given of how buffer-size ratio or sampling strategy affects estimator bias when transition data are limited relative to the size of the joint action space.
Authors: Buffer sizes follow standard replay-buffer practices for balancing recency and stability in off-policy MARL. We will add a sensitivity analysis in the revision, presenting experiments that vary the buffer-size ratio and sampling strategy, together with their effects on estimator bias and final performance under limited data. revision: yes
- Formal theoretical bounds or convergence guarantees for the parametric likelihood-free density ratio estimator under exponentially growing joint action spaces.
Circularity Check
No circularity: adaptive λ assignment relies on independent density-ratio estimator
full rationale
The derivation proceeds from the standard TD(λ) bias-variance motivation, cites prior single-agent adaptive-λ work, then introduces a separate parametric likelihood-free density-ratio estimator trained on two replay buffers of different sizes to approximate the current policy's stationary distribution. The resulting per-state-action λ values are defined directly from the estimator output rather than from any performance metric or fitted target; the final empirical claim is an external benchmark comparison on SMAC and GFootball. No equation reduces the claimed improvement to a self-referential fit, no uniqueness theorem is invoked, and the estimator is not defined in terms of the downstream return. The construction therefore remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- density ratio estimator parameters
axioms (1)
- domain assumption Two replay buffers of different sizes faithfully represent the data distributions of past and current policies.
invented entities (1)
-
ATD(λ) value assigned per state-action pair
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
work page 2015
-
[2]
Mastering the game of go without human knowledge , author=. nature , volume=. 2017 , publisher=
work page 2017
-
[3]
IEEE Transactions on Industrial informatics , volume=
An overview of recent progress in the study of distributed multi-agent coordination , author=. IEEE Transactions on Industrial informatics , volume=. 2012 , publisher=
work page 2012
-
[4]
Twenty-Fifth AAAI Conference on Artificial Intelligence , year=
Coordinated multi-agent reinforcement learning in networked distributed POMDPs , author=. Twenty-Fifth AAAI Conference on Artificial Intelligence , year=
-
[5]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Value-decomposition networks for cooperative multi-agent learning , author=. arXiv preprint arXiv:1706.05296 , year=
-
[6]
International Conference on Machine Learning , pages=
QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning , author=. International Conference on Machine Learning , pages=
-
[7]
Advances in neural information processing systems , volume=
Weighted qmix: Expanding monotonic value function factorisation for deep multi-agent reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[8]
arXiv preprint arXiv:2008.01062 , year=
Qplex: Duplex dueling multi-agent q-learning , author=. arXiv preprint arXiv:2008.01062 , year=
-
[9]
International Conference on Machine Learning , pages=
Multi-agent determinantal q-learning , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[10]
Advances in Neural Information Processing Systems , volume=
Maven: Multi-agent variational exploration , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2003.08039 , year=
Roma: Multi-agent reinforcement learning with emergent roles , author=. arXiv preprint arXiv:2003.08039 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
The surprising effectiveness of ppo in cooperative multi-agent games , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
International Conference on Learning Representations (ICLR) , year=
More Centralized Training, Still Decentralized Execution: Multi-Agent Conditional Policy Factorization , author=. International Conference on Learning Representations (ICLR) , year=
-
[14]
Proceedings of the AAAI conference on artificial intelligence , volume=
Counterfactual multi-agent policy gradients , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[15]
Mikayel Samvelyan and Tabish Rashid and Christian Schroeder de Witt and Gregory Farquhar and Nantas Nardelli and Tim G. J. Rudner and Chia-Man Hung and Philiph H. S. Torr and Jakob Foerster and Shimon Whiteson , journal =
-
[16]
Proceedings of the AAAI conference on artificial intelligence , volume=
Google research football: A novel reinforcement learning environment , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[17]
2021 IEEE 33rd International Conference on Tools with Artificial Intelligence (ICTAI) , pages=
Awd3: Dynamic reduction of the estimation bias , author=. 2021 IEEE 33rd International Conference on Tools with Artificial Intelligence (ICTAI) , pages=. 2021 , organization=
work page 2021
-
[18]
Reinforcement learning: An introduction , author=. 2018 , publisher=
work page 2018
-
[19]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
High-dimensional continuous control using generalized advantage estimation , author=. arXiv preprint arXiv:1506.02438 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Learning for Dynamics and Control Conference , pages=
Experience replay with likelihood-free importance weights , author=. Learning for Dynamics and Control Conference , pages=. 2022 , organization=
work page 2022
-
[21]
Advances in neural information processing systems , volume=
Bias correction of learned generative models using likelihood-free importance weighting , author=. Advances in neural information processing systems , volume=
-
[22]
International conference on machine learning , pages=
Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[23]
Advances in neural information processing systems , volume=
Multi-agent actor-critic for mixed cooperative-competitive environments , author=. Advances in neural information processing systems , volume=
-
[24]
International Conference on Machine Learning , pages=
Fop: Factorizing optimal joint policy of maximum-entropy multi-agent reinforcement learning , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[25]
IEEE Transactions on Neural Networks and Learning Systems , year=
Smix ( ): Enhancing centralized value functions for cooperative multiagent reinforcement learning , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[26]
Machine Learning Proceedings 1994 , pages=
Incremental multi-step Q-learning , author=. Machine Learning Proceedings 1994 , pages=. 1994 , publisher=
work page 1994
-
[27]
International Conference on Machine Learning , pages=
Emphatic algorithms for deep reinforcement learning , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[28]
International conference on learning representations , year=
Dop: Off-policy multi-agent decomposed policy gradients , author=. International conference on learning representations , year=
-
[29]
arXiv preprint arXiv:2102.03479 , year=
Rethinking the implementation tricks and monotonicity constraint in cooperative multi-agent reinforcement learning , author=. arXiv preprint arXiv:2102.03479 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Reconciling -returns with experience replay , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
A concise introduction to decentralized POMDPs , author=. 2016 , publisher=
work page 2016
-
[32]
Advances in neural information processing systems , volume=
An equivalence between loss functions and non-uniform sampling in experience replay , author=. Advances in neural information processing systems , volume=
-
[33]
IEEE Transactions on Information Theory , volume=
Estimating divergence functionals and the likelihood ratio by convex risk minimization , author=. IEEE Transactions on Information Theory , volume=. 2010 , publisher=
work page 2010
-
[34]
Proceedings of the AAAI conference on artificial intelligence , volume=
Rainbow: Combining improvements in deep reinforcement learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
- [35]
-
[36]
Prioritized experience replay , author=. arXiv preprint arXiv:1511.05952 , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
Pettingzoo: Gym for multi-agent reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Computer Science Department Faculty Publication Series , pages=
Eligibility traces for off-policy policy evaluation , author=. Computer Science Department Faculty Publication Series , pages=
- [39]
-
[40]
International Conference on Algorithmic Learning Theory , pages=
Q ( ) with off-policy corrections , author=. International Conference on Algorithmic Learning Theory , pages=. 2016 , organization=
work page 2016
-
[41]
Advances in neural information processing systems , volume=
Safe and efficient off-policy reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[42]
Advances in Neural Information Processing Systems , volume=
Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
International Conference on Machine Learning , pages=
True online TD (lambda) , author=. International Conference on Machine Learning , pages=. 2014 , organization=
work page 2014
-
[44]
Learning to predict by the methods of temporal differences , author=. Machine learning , volume=. 1988 , publisher=
work page 1988
-
[45]
Journal of Machine Learning Research , volume=
An emphatic approach to the problem of off-policy temporal-difference learning , author=. Journal of Machine Learning Research , volume=
-
[46]
Advances in Neural Information Processing Systems , volume=
Predictive-state decoders: Encoding the future into recurrent networks , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Forty-second International Conference on Machine Learning,
Yueheng Li and Guangming Xie and Zongqing Lu , title =. Forty-second International Conference on Machine Learning,. 2025 , url =
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.