Recognition: no theorem link
Split the Differences, Pool the Rest: Provably Efficient Multi-Objective Imitation
Pith reviewed 2026-05-13 07:12 UTC · model grok-4.3
The pith
MA-BC partitions conflicting expert data and pools the rest to recover Pareto-optimal policies faster than separate learners in multi-objective imitation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MA-BC systematically partitions divergent expert trajectories while pooling non-conflicting state-action pairs, proving convergence to Pareto-optimal policies at a faster statistical rate than any learner handling each expert dataset independently and matching the minimax lower bound established for the multi-objective imitation setting.
What carries the argument
Multi-Output Augmented Behavioral Cloning (MA-BC), which identifies observable behavior conflicts in expert data and pools only the non-conflicting state-action pairs to produce a single policy on the Pareto front.
If this is right
- MA-BC reaches the same Pareto-front performance with fewer total samples than training a separate imitator on each expert dataset.
- The same partitioning-plus-pooling logic extends from discrete environments to continuous LQR control without changing the core guarantees.
- Policies trained by MA-BC avoid the dominated behavior that results from simply aggregating all expert trajectories.
- A matching lower bound confirms that no other algorithm can improve on the sample complexity MA-BC achieves.
Where Pith is reading between the lines
- The partitioning step could be replaced by any reliable disagreement detector, opening the method to larger or partially observed state spaces.
- In practice the approach may reduce total training cost when multiple competing objectives must be satisfied from limited expert data.
- Similar split-and-pool logic might apply to multi-task imitation where tasks share some but not all optimal actions.
Load-bearing premise
The demonstrations come from Pareto-optimal experts and observable conflicts in state-action pairs can be reliably partitioned without further structure on the dynamics or rewards.
What would settle it
An experiment or counterexample in a MOMDP where MA-BC's convergence rate to the Pareto front fails to beat independent per-expert learners, for instance when conflicts cannot be cleanly separated from the given trajectories.
Figures












read the original abstract
This work investigates multi-objective imitation learning: the problem of recovering policies that lie on the Pareto front given demonstrations from multiple Pareto-optimal experts in a Multi-Objective Markov Decision Process (MOMDP). Standard imitation approaches are ill-equipped for this regime, as naively aggregating conflicting expert trajectories can result in dominated policies. To address this, we introduce Multi-Output Augmented Behavioral Cloning (MA-BC), an algorithm that systematically partitions divergent expert data while pooling state-action pairs where no behavior conflict is observed. Theoretically, we prove that MA-BC converges to Pareto-optimal policies at a faster statistical rate than any learner that considers each expert dataset independently. Furthermore, we establish a novel lower bound for multi-objective imitation learning, demonstrating that MA-BC is minimax optimal. Finally, we empirically validate our algorithm across diverse discrete environments and, guided by our theoretical insights, extend and evaluate MA-BC on a continuous Linear Quadratic Regulator (LQR) control task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Multi-Output Augmented Behavioral Cloning (MA-BC) for multi-objective imitation learning in MOMDPs. Given demonstrations from multiple Pareto-optimal experts, the algorithm partitions state-action pairs exhibiting behavioral conflicts while pooling non-conflicting pairs. It claims to prove that MA-BC recovers Pareto-optimal policies at a faster statistical rate than any method treating expert datasets independently, establishes a matching lower bound showing minimax optimality, and validates the approach empirically on discrete environments plus a continuous LQR task.
Significance. If the central claims hold, the work is significant for providing the first algorithm with provably faster rates and minimax optimality for multi-objective imitation learning, directly addressing the problem of dominated policies from naive aggregation of conflicting experts. The combination of a novel lower-bound construction, explicit rate improvement over independent learners, and extension to continuous control constitutes a substantive contribution to imitation learning and multi-objective RL.
major comments (1)
- [Theoretical analysis (main convergence theorem and lower-bound construction)] The faster rate and minimax optimality rest on the claim that observable conflicts can be reliably partitioned from samples while safely pooling the remainder. In a general MOMDP, conflicts between Pareto-optimal experts at the same state can depend on the unknown vector reward and transition kernel in ways not recoverable from empirical frequencies alone; the manuscript provides no explicit high-probability guarantee or additional structural assumption ensuring the empirical partition matches the true one. This assumption is load-bearing for the central convergence claim.
minor comments (2)
- [Abstract] The abstract refers to 'diverse discrete environments' without naming them; listing the specific domains (e.g., grid-world variants) would improve reproducibility and context.
- [Introduction / Preliminaries] Notation for the vector-valued reward and the Pareto front could be introduced earlier with a small illustrative example to aid readers unfamiliar with MOMDPs.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the significance of our contribution and for the constructive comment on the theoretical analysis. We address the major comment below.
read point-by-point responses
-
Referee: [Theoretical analysis (main convergence theorem and lower-bound construction)] The faster rate and minimax optimality rest on the claim that observable conflicts can be reliably partitioned from samples while safely pooling the remainder. In a general MOMDP, conflicts between Pareto-optimal experts at the same state can depend on the unknown vector reward and transition kernel in ways not recoverable from empirical frequencies alone; the manuscript provides no explicit high-probability guarantee or additional structural assumption ensuring the empirical partition matches the true one. This assumption is load-bearing for the central convergence claim.
Authors: We thank the referee for identifying this important point. The current manuscript defines the partition based on observed empirical conflicts in the collected demonstrations and proceeds under the assumption that this empirical partition correctly identifies true behavioral conflicts. While standard concentration inequalities (e.g., Hoeffding bounds on empirical frequencies) imply that the partition is correct with high probability for sufficiently large sample sizes, we agree that the manuscript does not make this guarantee explicit in the statement or proof of the main convergence theorem. In the revised version, we will add a supporting lemma that provides an explicit high-probability bound (at least 1-δ) on the event that the empirical partition matches the true conflict set, using standard concentration arguments on the state-action visitation frequencies. This lemma will be integrated into the proof of the main theorem to ensure the faster statistical rate holds with high probability. No additional structural assumptions on the MOMDP are required beyond those already present in the paper. revision: yes
Circularity Check
No circularity: independent statistical rates and novel lower bound
full rationale
The paper defines the MA-BC algorithm explicitly as partitioning observed conflicts and pooling non-conflicting pairs, then derives convergence rates faster than independent learners plus a separate minimax lower bound. No quoted step reduces the claimed rates or optimality to a fitted parameter renamed as prediction, a self-definitional loop, or a load-bearing self-citation chain. The lower-bound construction is presented as novel and external to the algorithm definition. This is the normal case of a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Experts provide demonstrations from Pareto-optimal policies in a Multi-Objective Markov Decision Process
- standard math Standard concentration inequalities apply to the statistical rates of behavioral cloning
Reference graph
Works this paper leans on
- [1]
-
[2]
P. Abbeel and A. Y. Ng. Apprenticeship learning via inverse reinforcement learning. InInternational Conference on Machine Learning (ICML), 2004
work page 2004
-
[3]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
work page 2024
-
[4]
Shibbir Ahmed, Baijing Qiu, Chun-Wei Kong, Huang Xin, Fiaz Ahmad, and Jinlong Lin. A data-driven dynamic obstacle avoidance method for liquid-carrying plant protection uavs.Agronomy, 12(4), 2022
work page 2022
-
[5]
Learning all optimal policies with multiple criteria
Leon Barrett and Srini Narayanan. Learning all optimal policies with multiple criteria. InProceedings of the 25th International Conference on Machine Learning, ICML ’08, page 41–47, New York, NY, USA,
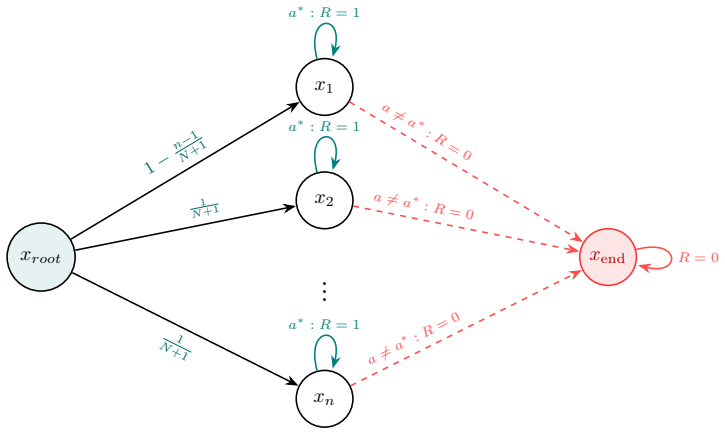
-
[6]
Association for Computing Machinery
-
[7]
Relative entropy inverse reinforcement learning
Abdeslam Boularias, Jens Kober, and Jan Peters. Relative entropy inverse reinforcement learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 182–189. JMLR Workshop and Conference Proceedings, 2011
work page 2011
-
[8]
Diffusion policy: Visuomotor policy learning via action diffusion, 2024
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion, 2024
work page 2024
-
[9]
Ultrafeedback: Boosting language models with scaled ai feedback.arXiv preprint arXiv:2310.01377,
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, et al. Ultrafeedback: Boosting language models with scaled ai feedback.arXiv preprint arXiv:2310.01377, 2023
-
[10]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
work page 2019
-
[11]
Dylan J Foster, Adam Block, and Dipendra Misra. Is behavior cloning all you need? understanding horizon in imitation learning.arXiv preprint arXiv:2407.15007, 2024
-
[12]
Tim Franzmeyer, Edith Elkind, Philip Torr, Jakob Foerster, and Joao Henriques. Select to perfect: Imitating desired behavior from large multi-agent data.arXiv preprint arXiv:2405.03735, 2024
-
[13]
Learning equilibria from data: Provably efficient multi-agent imitation learning, 2025
Till Freihaut, Luca Viano, Volkan Cevher, Matthieu Geist, and Giorgia Ramponi. Learning equilibria from data: Provably efficient multi-agent imitation learning, 2025
work page 2025
-
[14]
Rate optimal learning of equilibria from data.arXiv preprint arXiv:2510.09325, 2025
Till Freihaut, Luca Viano, Emanuele Nevali, Volkan Cevher, Matthieu Geist, and Giorgia Ramponi. Rate optimal learning of equilibria from data.arXiv preprint arXiv:2510.09325, 2025
-
[15]
Characterization of optimal policies in vector-valued markovian decision processes
Nagata Furukawa. Characterization of optimal policies in vector-valued markovian decision processes. Mathematics of operations research, 5(2):271–279, 1980
work page 1980
- [16]
-
[17]
J. Ho, J. K. Gupta, and S. Ermon. Model-free imitation learning with policy optimization. InInternational Conference on Machine Learning (ICML), 2016
work page 2016
-
[18]
Multi-objective lqr with linear scalarization.arXiv preprint arXiv:2408.04488, 2024
Ali Jadbabaie, Devavrat Shah, and Sean R Sinclair. Multi-objective lqr with linear scalarization.arXiv preprint arXiv:2408.04488, 2024
-
[19]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karam- cheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
OpenVLA: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An open-source vision-language-action model. In8th Annual Conference on Robot Learning, 2024
work page 2024
-
[21]
Woo Kyung Kim, Minjong Yoo, and Honguk Woo. Pareto inverse reinforcement learning for diverse expert policy generation.arXiv preprint arXiv:2408.12110, 2024
-
[22]
Pretraining language models with human preferences
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Vinayak Bhalerao, Christopher Buckley, Jason Phang, Samuel R Bowman, and Ethan Perez. Pretraining language models with human preferences. In International conference on machine learning, pages 17506–17533. PMLR, 2023
work page 2023
-
[23]
Coordinated multi-agent imitation learning
Hoang M Le, Yisong Yue, Peter Carr, and Patrick Lucey. Coordinated multi-agent imitation learning. InInternational Conference on Machine Learning, pages 1995–2003. PMLR, 2017
work page 1995
-
[24]
Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H. Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Behavior generation with latent actions. InMulti-modal Foundation Model meets Embodied AI Workshop @ ICML2024, 2024
work page 2024
-
[25]
Learning strategy representation for imitation learning in multi-agent games
Shiqi Lei, Kanghoon Lee, Linjing Li, and Jinkyoo Park. Learning strategy representation for imitation learning in multi-agent games. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 18163–18171, 2025
work page 2025
-
[26]
How to find the exact pareto front for multi-objective mdps? arXiv preprint arXiv:2410.15557, 2024
Yining Li, Peizhong Ju, and Ness B Shroff. How to find the exact pareto front for multi-objective mdps? arXiv preprint arXiv:2410.15557, 2024
-
[27]
Multi-objective reinforcement learning: Convexity, stationarity and pareto optimality
Haoye Lu, Daniel Herman, and Yaoliang Yu. Multi-objective reinforcement learning: Convexity, stationarity and pareto optimality. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[28]
Molter.Classic graph problems made temporal – a parameterized complexity analysis
H. Molter.Classic graph problems made temporal – a parameterized complexity analysis. Foundations of Computing. Universitätsverlag der TU Berlin, 2020
work page 2020
-
[29]
Inverse q-learning done right: Offline imitation learning inq π-realizable mdps, 2025
Antoine Moulin, Gergely Neu, and Luca Viano. Inverse q-learning done right: Offline imitation learning inq π-realizable mdps, 2025
work page 2025
-
[30]
Antoine Moulin, Gergely Neu, and Luca Viano. Optimistically optimistic exploration for provably efficient infinite-horizon reinforcement and imitation learning.arXiv preprint arXiv:2502.13900, 2025
-
[31]
A. Y. Ng and S. J. Russell. Algorithms for inverse reinforcement learning. InInternational Conference on Machine Learning (ICML), 2000
work page 2000
-
[32]
An algorithmic perspective on imitation learning.Foundations and Trends in Robotics, 2018
T Osa, J Pajarinen, G Neumann, JA Bagnell, P Abbeel, and J Peters. An algorithmic perspective on imitation learning.Foundations and Trends in Robotics, 2018
work page 2018
-
[33]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
work page 2022
-
[34]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
work page 2024
-
[35]
D. A. Pomerleau. Efficient training of artificial neural networks for autonomous navigation.Neural Computation, 3(1):88–97, 1991
work page 1991
-
[36]
Puterman.Markov Decision Processes: Discrete Stochastic Dynamic Programming
Martin L. Puterman.Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons, Inc., USA, 1st edition, 1994. 12
work page 1994
-
[37]
Improving language under- standing by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language under- standing by generative pre-training. 2018
work page 2018
-
[38]
Nived Rajaraman, Yanjun Han, Lin Yang, Jingbo Liu, Jiantao Jiao, and Kannan Ramchandran. On the value of interaction and function approximation in imitation learning.Advances in Neural Information Processing Systems, 34:1325–1336, 2021
work page 2021
-
[39]
Nived Rajaraman, Lin Yang, Jiantao Jiao, and Kannan Ramchandran. Toward the fundamental limits of imitation learning.Advances in Neural Information Processing Systems, 33:2914–2924, 2020
work page 2020
-
[40]
Diederik M Roijers, Peter Vamplew, Shimon Whiteson, and Richard Dazeley. A survey of multi-objective sequential decision-making.Journal of Artificial Intelligence Research, 48:67–113, 2013
work page 2013
-
[41]
PhD thesis, University of Amsterdam, 2016
Diederik Marijn Roijers.Multi-Objective Decision-Theoretic Planning. PhD thesis, University of Amsterdam, 2016
work page 2016
-
[42]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2011
work page 2011
-
[43]
Efficient reductions for imitation learning
Stéphane Ross and Drew Bagnell. Efficient reductions for imitation learning. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2010
work page 2010
-
[44]
Learning agents for uncertain environments (extended abstract)
Stuart Russell. Learning agents for uncertain environments (extended abstract). InAnnual Conference on Computational Learning Theory (COLT), 1998
work page 1998
-
[45]
Maarten Sap, Saadia Gabriel, Lianhui Qin, Dan Jurafsky, Noah A. Smith, and Yejin Choi. Social bias frames: Reasoning about social and power implications of language. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5477–5490, Online, July 2020. Association for Computational Linguistics
work page 2020
-
[46]
Online apprenticeship learning.arXiv:2102.06924, 2021
Lior Shani, Tom Zahavy, and Shie Mannor. Online apprenticeship learning.arXiv:2102.06924, 2021
-
[47]
Stochastic games.Proceedings of the national academy of sciences, 39(10):1095–1100, 1953
Lloyd S Shapley. Stochastic games.Proceedings of the national academy of sciences, 39(10):1095–1100, 1953
work page 1953
-
[48]
Quantization-free autoregressive action transformer
Ziyad Sheebaelhamd, Michael Tschannen, Michael Muehlebach, and Claire Vernade. Quantization-free autoregressive action transformer. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[49]
Jiaming Song, Hongyu Ren, Dorsa Sadigh, and Stefano Ermon. Multi-agent generative adversarial imitation learning.Advances in neural information processing systems, 31, 2018
work page 2018
-
[50]
Of moments and matching: A game-theoretic framework for closing the imitation gap
Gokul Swamy, Sanjiban Choudhury, J Andrew Bagnell, and Steven Wu. Of moments and matching: A game-theoretic framework for closing the imitation gap. InInternational Conference on Machine Learning, pages 10022–10032. PMLR, 2021
work page 2021
-
[51]
U. Syed, M. Bowling, and R.E. Schapire. Apprenticeship learning using linear programming. In International Conference on Machine Learning (ICML), 2008
work page 2008
-
[52]
U. Syed and R. E. Schapire. A game-theoretic approach to apprenticeship learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2007
work page 2007
-
[53]
Multi-agent imitation learning: Value is easy, regret is hard
Jingwu Tang, Gokul Swamy, Fei Fang, and Zhiwei Steven Wu. Multi-agent imitation learning: Value is easy, regret is hard. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 27790–27816. Curran Associates, Inc., 2024
work page 2024
-
[54]
Luca Viano, Till Freihaut, Emanuele Nevali, Volkan Cevher, Matthieu Geist, and Giorgia Ramponi. Multi-agent imitation learning with function approximation: Linear markov games and beyond.arXiv preprint arXiv:2602.22810, 2026. 13
-
[55]
Luca Viano, Angeliki Kamoutsi, Gergely Neu, Igor Krawczuk, and Volkan Cevher. Proximal point imitation learning.Advances in Neural Information Processing Systems, 35:24309–24326, 2022
work page 2022
-
[56]
Imitation learning in discounted linear MDPs without exploration assumptions
Luca Viano, Stratis Skoulakis, and Volkan Cevher. Imitation learning in discounted linear MDPs without exploration assumptions. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[57]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–1736. PMLR, 2023
work page 2023
-
[58]
Joe Watson, Sandy H. Huang, and Nicolas Heess. Coherent soft imitation learning, 2023
work page 2023
-
[59]
D.J. White. Multi-objective infinite-horizon discounted markov decision processes.Journal of mathemat- ical analysis and applications, 89(2):639–647, 1982
work page 1982
-
[60]
A broad-coverage challenge corpus for sentence understanding through inference
Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122. Association for Computational Linguistics, 2018
work page 2018
-
[61]
Markus Wulfmeier, Michael Bloesch, Nino Vieillard, Arun Ahuja, Jörg Bornschein, Sandy Huang, Artem Sokolov, Matt Barnes, Guillaume Desjardins, Alex Bewley, et al. Imitating language via scalable inverse reinforcement learning.Advances in Neural Information Processing Systems, 37:90714–90735, 2024
work page 2024
-
[62]
Tian Xu, Ziniu Li, Yang Yu, and Zhi-Quan Luo. Provably efficient adversarial imitation learning with unknown transitions.arXiv preprint arXiv:2306.06563, 2023
-
[63]
A generalized algorithm for multi-objective reinforcement learning and policy adaptation
Runzhe Yang, Xingyuan Sun, and Karthik Narasimhan. A generalized algorithm for multi-objective reinforcement learning and policy adaptation. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché- Buc, E. Fox, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[64]
Multi-agent adversarial inverse reinforcement learning
Lantao Yu, Jiaming Song, and Stefano Ermon. Multi-agent adversarial inverse reinforcement learning. InInternational conference on machine learning, pages 7194–7201. PMLR, 2019
work page 2019
-
[65]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric. P Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023
work page 2023
-
[66]
B. D. Ziebart, A. Maas, J. A. Bagnell, and A. K. Dey. Maximum entropy inverse reinforcement learning. InNational Conference on Artificial Intelligence (AAAI), 2008. 14 Contents of Appendix A Related Work 16 B Omitted Proofs 18 B.1 Proof of Theorem 2.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 B.2 Proof of Theorem...
work page 2008
-
[67]
for a complete overview of the classics. Recent theoretical developmentsThe first solid sample complexity investigation in imitation learning is by [38], which also introduced the lower bound construction on which we build on for ours to show that behavioral cloning is actually optimal across offline algorithms. Beyond the tabular setting, [10] proved tha...
-
[68]
Aliasing:Multiple distinct deterministic policies collapse into the exact same geometric vertex of the return polytope
-
[69]
Edge-bound Policies:Deterministic policies may map to the flat edge connecting two vertices, rather than forming new extreme points. Because of these phenomena, the strict "distance-1" property between adjacent vertices breaks down. Our result in Theorem 2.1 holds in general, and is agnostic to the existence ofaliasedoredge-boundpolicies. B.2 Proof of The...
-
[70]
Then, switching the attention back to(3), taking the maximum over both sides and defining asJM,i(π)as the ith entry of the performance vector for policyπ in the environment M, we have that max M∈{M 1,M2,M3,M4} E[J M,i(π⋆)−J M,i(ˆπ1)]≥ 1 8(1−γ) X x∈X \Xcommon ν0(x)P[π 1(x)̸= ˆπ1(x)] = 1 8(1−γ) X x∈X \Xcommon ν0(x)P[x /∈ D1] = 1 8(1−γ) X x∈X \Xcommon ν0(x)(...
-
[71]
in the graph, which is an NP-hard problem. Thus, we restrict our setting to pair-wise distinct actions, and leave the extension to arbitrary experts for future work. Cluster 1 (Expert 1 Actions) Cluster 2 (Expert 2 Actions) (x1, a1) (x2, a2) (x3, a3) (x4, a4) τA τB (x1, a′ 1) (x2, a′ 2) (x3, a′ 3) (x4, a′ 4) τC No Linking Trajectories (Mutually Exclusive)...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.