Recognition: no theorem link
Approximation Theory of Laplacian-Based Neural Operators for Reaction-Diffusion System
Pith reviewed 2026-05-13 06:39 UTC · model grok-4.3
The pith
Laplacian eigenfunction neural operators approximate reaction-diffusion solution maps with only polynomial parameter growth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
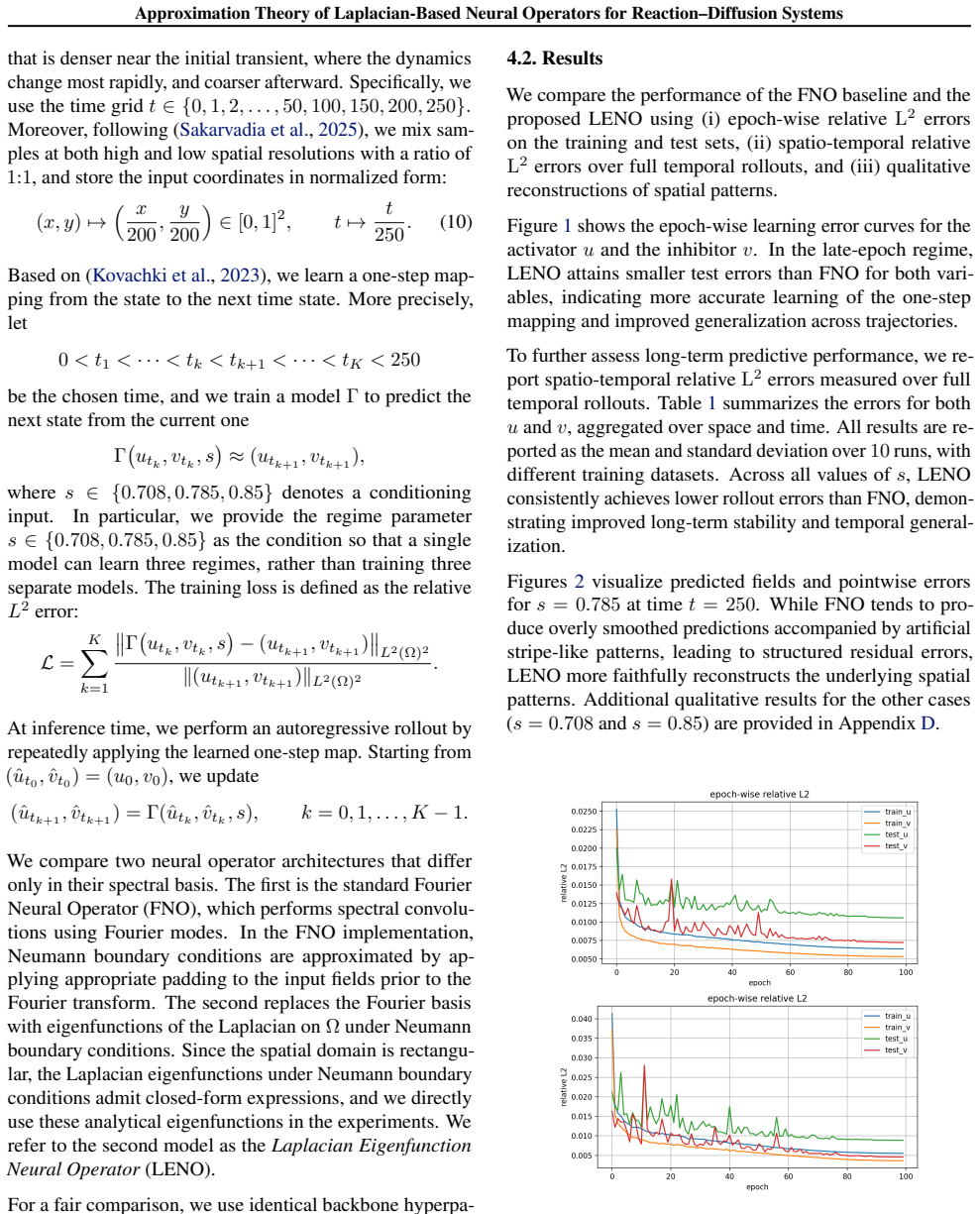
Our main results establish explicit approximation error bounds in terms of network depth, width, and spectral rank by exploiting the Laplacian spectral representation of the Green's function underlying the PDE. We show that the required parameter complexity grows at most polynomially with respect to the target accuracy, demonstrating that Laplacian eigenfunction-based neural operator architectures alleviate the curse of parametric complexity encountered in generic operator learning.
What carries the argument
Laplacian spectral representation of the Green's function, realized by eigenfunction-based neural operator layers that decompose the linear part of the reaction-diffusion dynamics.
Load-bearing premise
The solution operator of the generalized Gierer-Meinhardt system admits an effective approximation via the Laplacian spectral decomposition of its Green's function that the chosen neural operator architecture can realize without hidden constants that destroy the polynomial scaling.
What would settle it
A computation showing that the number of parameters needed to reach a given accuracy on the Gierer-Meinhardt system grows exponentially rather than polynomially with the inverse error would disprove the stated bounds.
Figures




read the original abstract
Neural operators provide a framework for learning solution operators of partial differential equations (PDEs), enabling efficient surrogate modeling for complex systems. While universal approximation results are now well understood, approximation analysis specific to nonlinear reaction-diffusion systems remains limited. In this paper, we study neural operators applied to the solution mapping from initial conditions to time-dependent solutions of a generalized Gierer-Meinhardt reaction-diffusion system, a prototypical model of nonlinear pattern formation. Our main results establish explicit approximation error bounds in terms of network depth, width, and spectral rank by exploiting the Laplacian spectral representation of the Green's function underlying the PDE. We show that the required parameter complexity grows at most polynomially with respect to the target accuracy, demonstrating that Laplacian eigenfunction-based neural operator architectures alleviate the curse of parametric complexity encountered in generic operator learning. Numerical experiments on the Gierer-Meinhardt system support the theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies Laplacian eigenfunction-based neural operators for learning the solution operator of a generalized Gierer-Meinhardt reaction-diffusion system, mapping initial conditions to time-dependent solutions. It derives explicit approximation error bounds expressed in terms of network depth, width, and spectral truncation rank, and claims that the total parameter complexity scales at most polynomially in the target accuracy 1/ε, thereby avoiding the curse of parametric complexity typical of generic operator learning.
Significance. If the polynomial scaling holds with constants independent of ε, the result would supply the first rigorous, architecture-specific approximation theory for spectral neural operators on nonlinear reaction-diffusion systems. This would strengthen the case for eigenfunction-based architectures in surrogate modeling of pattern-formation PDEs and provide a template for similar analyses on other semilinear parabolic systems.
major comments (2)
- [Section 4, Theorem 4.2] Main theorem (Section 4, Theorem 4.2): the stated error bound for the composed nonlinear operator absorbs the Lipschitz constant L of the reaction terms and the time horizon T into a multiplicative factor. The proof sketch does not demonstrate that this factor remains independent of the truncation rank N and of 1/ε; if it grows with N or 1/ε, the overall parameter count (depth × width × N) ceases to be polynomial in 1/ε. A concrete estimate showing the constant is O(1) with respect to ε is required.
- [Section 3.2] Section 3.2 (Duhamel formulation): the iterative application of the integral operator over [0,T] is bounded using the spectral decay of the Green's function. It is unclear whether the number of iterations or the Gronwall-type constant introduced by the nonlinearity is controlled uniformly in the spectral rank; this directly affects the claimed polynomial scaling.
minor comments (2)
- [Section 2] Notation for the spectral rank N and the network width m is used interchangeably in several places; a single consistent symbol would improve readability.
- [Figure 2] Figure 2 caption does not state the precise values of depth, width, and rank used in the numerical experiment; these should be listed explicitly.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important points regarding the uniformity of constants in our error bounds, which we address below by providing clarifications and committing to explicit revisions that strengthen the polynomial scaling claim without altering the main results.
read point-by-point responses
-
Referee: [Section 4, Theorem 4.2] Main theorem (Section 4, Theorem 4.2): the stated error bound for the composed nonlinear operator absorbs the Lipschitz constant L of the reaction terms and the time horizon T into a multiplicative factor. The proof sketch does not demonstrate that this factor remains independent of the truncation rank N and of 1/ε; if it grows with N or 1/ε, the overall parameter count (depth × width × N) ceases to be polynomial in 1/ε. A concrete estimate showing the constant is O(1) with respect to ε is required.
Authors: We appreciate this observation on the proof of Theorem 4.2. The Lipschitz constant L is determined solely by the fixed reaction terms of the generalized Gierer-Meinhardt system and is therefore independent of the spectral truncation rank N. The time horizon T is a fixed parameter of the problem. The multiplicative factor arises from a standard application of Gronwall's inequality to the Duhamel integral formulation after spectral expansion; this yields a bound of the form exp(C L T) where C is an absolute constant from the spectral decay estimates and does not depend on N or ε. While the original proof sketch was concise, we agree that an explicit derivation of this independence is needed to rigorously confirm the polynomial parameter scaling. We will add this detailed estimate (including the explicit form of the constant) to the revised version of Section 4. revision: yes
-
Referee: [Section 3.2] Section 3.2 (Duhamel formulation): the iterative application of the integral operator over [0,T] is bounded using the spectral decay of the Green's function. It is unclear whether the number of iterations or the Gronwall-type constant introduced by the nonlinearity is controlled uniformly in the spectral rank; this directly affects the claimed polynomial scaling.
Authors: Thank you for raising this point on Section 3.2. The Duhamel formulation is applied directly via the spectral representation of the Green's function, without a fixed number of discrete iterations; the integral is handled by expanding in the Laplacian eigenbasis and bounding the resulting series using the known decay rates of the eigenvalues. The Gronwall-type constant is controlled by the Lipschitz constant of the nonlinearity, which is independent of the truncation rank N because the reaction terms act pointwise and the eigenfunctions form a complete orthonormal basis. The spectral decay ensures that the remainder terms after truncation do not introduce N-dependent growth in the constant. We acknowledge that the original presentation could be clearer on this uniformity. We will revise Section 3.2 to include an explicit lemma bounding the Gronwall factor uniformly in N, thereby confirming that it does not affect the polynomial dependence on 1/ε. revision: yes
Circularity Check
No circularity: derivation relies on external spectral theory of Laplacian and Green's functions
full rationale
The paper establishes approximation bounds for Laplacian eigenfunction-based neural operators applied to the generalized Gierer-Meinhardt system by expanding the Green's function in Laplacian eigenfunctions and composing with the nonlinear reaction terms. This construction draws directly from standard PDE spectral theory (external mathematical facts) rather than any self-definition, fitted input renamed as prediction, or load-bearing self-citation chain. The claimed polynomial parameter scaling in target accuracy follows from explicit truncation and network approximation estimates whose constants are controlled by the problem data and time horizon, without reduction to the paper's own inputs or prior author results. No step in the provided abstract or described derivation collapses by construction to a tautology or fitted parameter.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Green's function of the generalized Gierer-Meinhardt system admits a Laplacian eigenfunction expansion that can be truncated for operator approximation.
Reference graph
Works this paper leans on
-
[1]
Neural operator: Graph kernel network for partial differential equations
Anandkumar, A., Azizzadenesheli, K., Bhattacharya, K., Kovachki, N., Li, Z., Liu, B., and Stuart, A. Neural operator: Graph kernel network for partial differential equations. InICLR 2020 Workshop on Integration of Deep Neural Models and Differential Equations,
work page 2020
-
[2]
Learning neural operators on Riemannian manifolds
Chen, G., Liu, X., Meng, Q., Chen, L., Liu, C., and Li, 8 Approximation Theory of Laplacian-Based Neural Operators for Reaction–Diffusion Systems Y . Learning neural operators on Riemannian manifolds. arXiv preprint arXiv:2302.08166, 2023a. Chen, K., Wang, C., and Yang, H. Deep operator learning lessens the curse of dimensionality for PDEs.Trans- actions ...
-
[3]
Furuya, T., Taniguchi, K., and Okuda, S
ISSN 0893-6080. Furuya, T., Taniguchi, K., and Okuda, S. Quantitative ap- proximation for neural operators in nonlinear parabolic equations.arXiv preprint arXiv:2410.02151,
-
[4]
Hao, W. and Wang, J. Laplacian eigenfunction-based neural operator for learning nonlinear partial differential equa- tions.arXiv preprint arXiv:2502.05571,
-
[5]
Kratsios, A., Furuya, T., Lassas, M., de Hoop, M., et al. Mixture of experts soften the curse of dimensionality in operator learning.arXiv preprint arXiv:2404.09101,
-
[6]
Lanthaler, S. and Stuart, A. M. The curse of dimensionality in operator learning.arXiv preprint arXiv:2306.15924,
- [7]
-
[8]
Fourier Neural Operator for Parametric Partial Differential Equations
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhat- tacharya, K., Stuart, A., and Anandkumar, A. Fourier neural operator for parametric partial differential equa- tions.arXiv preprint arXiv:2010.08895, 2020a. Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhat- tacharya, K., Stuart, A., and Anandkumar, A. Neural operator: Graph kernel network f...
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [9]
-
[10]
doi: https://doi.org/10.1016/j.apm.2017.01.081
ISSN 0307- 904X. doi: https://doi.org/10.1016/j.apm.2017.01.081. 9 Approximation Theory of Laplacian-Based Neural Operators for Reaction–Diffusion Systems Takamoto, M., Praditia, T., Leiteritz, R., MacKinlay, D., Alesiani, F., Pfl ¨uger, D., and Niepert, M. Pdebench: An extensive benchmark for scientific machine learning. Advances in Neural Information Pr...
-
[11]
Proof of Proposition 2 We follow the idea described in (Rothe, 2006, Part II)
10 Approximation Theory of Laplacian-Based Neural Operators for Reaction–Diffusion Systems A. Proof of Proposition 2 We follow the idea described in (Rothe, 2006, Part II). LetU 0 ∈ X. We choose a constantC 1 >0such that C0 := Z Ω Φ(·, y,·)U 0(y)dy L∞([0,∞);L∞(Ω)2) ≤C
work page 2006
-
[12]
We define the set B:= ¯Ω×[0, C 1]×[0, C 1]. Then ˜G:B →R 2 + is well-defined, and there exists a constantB >0such that | ˜G(x, U)| ≤Bfor all(x, U)∈ B,(11) and | ˜G(x, U)− ˜G(x, V)| ≤B|U−V|for all(x, U),(x, V)∈ B.(12) We now chooseT 0 ∈(0,1)such that C0 +e BT0 −1< C 1.(13) Fork∈N, we define ηk(t) :=∥U (k+1)(·, t)−U (k)(·, t)∥L∞(Ω)2 . Under assumptions (11)...
work page 2006
-
[13]
Proof of Theorem 4 Let ϵ∈(0,1) , and let U0 ∈ X
B. Proof of Theorem 4 Let ϵ∈(0,1) , and let U0 ∈ X . In what follows, we use the notation ≲ to denote an inequality up to a multiplicative constant independent ofϵ. Step 1.We define the operators ΘU0 , bΘU0 :L ∞([0, T0];L ∞(Ω)2)→L ∞([0, T0];L ∞(Ω)2) by ΘU0[U](x, t) := Z Ω Φ(x, y, t)U0(y)dy+ Z t 0 Z Ω Φ(x, y, t−s) ˜G(y, U(y, s))dy ds, 11 Approximation Theo...
work page 1987
-
[14]
For the second term, (15) yields |(2)| ≤ ∥ ˜G∥W 1,∞ Z t 0 Z Ω |Φ(x, y, t−s)−Φ N(x, y, t−s)|dy ds≲ϵ
or (Masuda, 1983, Lemma 7), we have |(1)|≲ Z T0 0 e− s 2 N 2/n (s/2)− n 4 ds≲N n−4 2n ≲ϵ. For the second term, (15) yields |(2)| ≤ ∥ ˜G∥W 1,∞ Z t 0 Z Ω |Φ(x, y, t−s)−Φ N(x, y, t−s)|dy ds≲ϵ. This completes the proof. Step 2.We choose a large compact set ˜Ω⊂R n+2. On ˜Ω, the map ˜G: ˜Ω→R 2 satisfies ˜G∈W 1,∞(˜Ω;R 2). Applying the approximation result of (Ya...
work page 1983
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.