Recognition: unknown
Early Data Exposure Improves Robustness to Subsequent Fine-Tuning
Pith reviewed 2026-05-14 20:40 UTC · model grok-4.3
The pith
Mixing some target data into pretraining improves retention of that capability after later fine-tuning on new tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
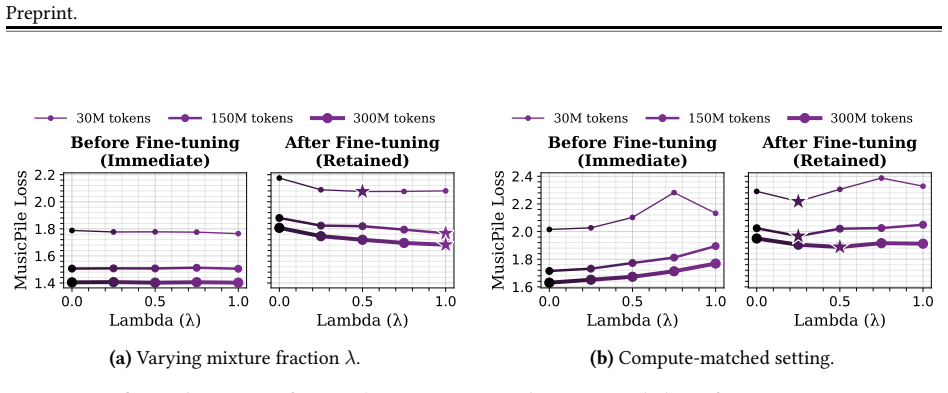
Early exposure, by mixing post-training data into pretraining, improves the frontier between retained upstream performance and downstream performance across 135M and 1B models, two post-training domains, and two downstream tasks. In compute-matched allocations of target data, the optimum lies neither at full pretraining exposure nor at full post-training specialization. Post-training drives immediate specialization while early exposure builds robustness to later forgetting; replay and dropout applied during post-training provide additional gains on top of early exposure.
What carries the argument
Early exposure: the inclusion of a portion of the post-training target data directly in the pretraining corpus, which alters how the capability is initially acquired and thereby affects its resistance to overwriting during later fine-tuning.
Load-bearing premise
The controlled three-stage pipeline and the specific model sizes and tasks used here reflect the forgetting dynamics that arise in larger-scale training with more complex and overlapping data distributions.
What would settle it
Train a larger model or a model on more naturalistic overlapping data mixtures and check whether the retention advantage of early exposure over pure post-training disappears or reverses after the downstream fine-tuning stage.
Figures











read the original abstract
How can we train models whose post-trained capabilities survive subsequent fine-tuning? Rather than focusing on downstream interventions to mitigate forgetting of upstream capabilities, we study how upstream training choices - that is, the manner in which a capability is acquired - shape how robustly that capability is retained. We investigate this question in a controlled three-stage language-model pipeline: pretraining, post-training to acquire a target capability, and downstream fine-tuning on a new objective. Across 135M and 1B models, two post-training domains, and two downstream fine-tuning tasks, we find that immediate post-training performance does not reliably predict retention after subsequent fine-tuning: training recipes that look equivalent immediately after post-training can retain the target capability very differently after subsequent fine-tuning. In particular, early exposure - mixing post-training data into pretraining - consistently improves the frontier between retained upstream performance and downstream performance. In compute-matched experiments, where the target data must be allocated between pretraining and post-training, we find that the optimum lies at neither extreme. Together with our other empirical and theoretical findings, this supports the view that post-training drives immediate specialization while early exposure improves robustness to later forgetting. Replay and dropout, typically used to mitigate forgetting as it occurs during fine-tuning, provide complementary gains to early exposure when applied during post-training. Our findings suggest that robustness to subsequent fine-tuning should be treated as a first-class objective of upstream training, addressed preventatively through choices like early exposure rather than reactively during fine-tuning itself.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in a controlled three-stage language model pipeline (pretraining, post-training to acquire a target capability, and downstream fine-tuning), mixing post-training data into pretraining ('early exposure') improves robustness to subsequent fine-tuning. This is shown empirically across 135M and 1B models, two post-training domains, and two fine-tuning tasks: immediate post-training performance does not predict retention after fine-tuning, early exposure improves the retained-upstream vs. downstream performance frontier, and in compute-matched data allocation the optimum lies at neither extreme (all data in pretraining or all in post-training). Replay and dropout during post-training provide complementary gains.
Significance. If the result holds, the work is significant for shifting emphasis from reactive forgetting mitigation during fine-tuning to preventative upstream training choices such as data mixing. It offers consistent empirical patterns across model scales, domains, and tasks in a controlled setting, with credit for the compute-matched allocation experiments that directly compare allocation strategies. This could influence practical training pipelines by treating robustness as a first-class upstream objective.
major comments (2)
- [Experiments] Experiments section: The robustness benefit of early exposure is demonstrated only for 135M and 1B models; no scaling experiments, scaling-law analysis, or discussion of how forgetting dynamics or loss landscape curvature might change at larger scales (e.g., 7B+) is provided, which is load-bearing for the claim that early exposure 'consistently improves' the frontier in general.
- [Methods and Results] Methods and Results: Exact data mixing proportions, precise definitions of upstream/downstream metrics, and statistical controls (number of runs, variance reporting, significance tests) are not fully explicit, which limits assessment of the strength and reproducibility of the reported patterns across the three-stage pipeline.
minor comments (2)
- [Abstract] Abstract: The reference to 'other empirical and theoretical findings' should be clarified with a brief pointer to the specific sections or results that constitute the theoretical component.
- [Figures] Figures: Ensure legends and axis labels explicitly indicate mixing ratios and the two performance axes for all frontier plots to improve readability.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work and recommendation for minor revision. We address each major comment below and will update the manuscript accordingly to improve clarity and acknowledge limitations.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The robustness benefit of early exposure is demonstrated only for 135M and 1B models; no scaling experiments, scaling-law analysis, or discussion of how forgetting dynamics or loss landscape curvature might change at larger scales (e.g., 7B+) is provided, which is load-bearing for the claim that early exposure 'consistently improves' the frontier in general.
Authors: We thank the referee for this important observation. Our experiments are deliberately limited to 135M and 1B models to enable a fully controlled three-stage pipeline with compute-matched allocations. We agree that the absence of scaling experiments and analysis limits the strength of general claims. In the revised manuscript we will add a paragraph in the Discussion section that (i) explicitly qualifies the scope of our results to the studied scales, (ii) references existing literature on how forgetting and loss-landscape properties evolve with model size, and (iii) outlines why we expect the qualitative benefit of early exposure to persist while noting that quantitative scaling behavior remains an open question. We do not have the resources to run new 7B+ experiments in this revision. revision: partial
-
Referee: [Methods and Results] Methods and Results: Exact data mixing proportions, precise definitions of upstream/downstream metrics, and statistical controls (number of runs, variance reporting, significance tests) are not fully explicit, which limits assessment of the strength and reproducibility of the reported patterns across the three-stage pipeline.
Authors: We agree that greater explicitness is required. The revised manuscript will (i) state the exact mixing proportions used in every experiment (e.g., the percentage of post-training data introduced during pretraining), (ii) provide formal definitions of the upstream retention metric and downstream performance metric, and (iii) report the number of independent runs (typically three random seeds), standard deviations, and any statistical significance tests performed. These details will be placed in a new subsection of Methods and referenced in Results. revision: yes
- Absence of scaling experiments and scaling-law analysis for models larger than 1B parameters due to computational constraints.
Circularity Check
No circularity: purely empirical comparisons with no derivation chain
full rationale
The paper is an empirical study reporting direct experimental outcomes from controlled three-stage training pipelines (pretraining, post-training, downstream fine-tuning) on 135M and 1B models. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text or abstract. Claims rest on observed performance differences across data-mixing recipes and compute-matched allocations, which are measured independently rather than reduced to inputs by construction. This is the standard non-circular outcome for purely experimental work.
Axiom & Free-Parameter Ledger
free parameters (1)
- mixing proportion of post-training data into pretraining
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2502.02737. Christina Baek, Ricardo Pio Monti, David Schwab, Amro Abbas, Rishabh Adiga, Cody Blakeney, Maximilian Böther, Paul Burstein, Aldo Gael Carranza, Alvin Deng, Parth Doshi, Vineeth Dorna, Alex Fang, Tony Jiang, Siddharth Joshi, Brett W. Larsen, Jason Chan Lee, Katherine L. Mentzer, Luke Merrick, Haakon Mongstad, Fan Pan,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Louis Bethune, David Grangier, Dan Busbridge, Eleonora Gualdoni, Marco Cuturi, and Pierre Ablin
URL https://arxiv.org/abs/2603.16177. Louis Bethune, David Grangier, Dan Busbridge, Eleonora Gualdoni, Marco Cuturi, and Pierre Ablin. Scaling laws for forgetting during finetuning with pretraining data injection,
- [3]
-
[4]
Yangyi Chen, Binxuan Huang, Yifan Gao, Zhengyang Wang, Jingfeng Yang, and Heng Ji
URLhttps://arxiv.org/abs/2405.09673. Yangyi Chen, Binxuan Huang, Yifan Gao, Zhengyang Wang, Jingfeng Yang, and Heng Ji. Scaling laws for predicting downstream performance in llms,
-
[5]
arXiv preprint arXiv:2410.08527 , year=
URLhttps://arxiv.org/abs/2410.08527. Zhengxiao Du, Aohan Zeng, Yuxiao Dong, and Jie Tang. Understanding emergent abilities of language models from the loss perspective. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
- [6]
-
[7]
LoRA: Low-Rank Adaptation of Large Language Models
URL https://arxiv.org/ abs/2106.09685. James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks. Proceedings of the Nat...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
ISSN 1091-6490. doi: 10.1073/pnas.1611835114. URLhttp://dx.doi.org/10.1073/pnas.1611835114. Suhas Kotha and Percy Liang. Replaying pre-training data improves fine-tuning,
-
[9]
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C
URL https: //arxiv.org/abs/2603.04964. Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C. Lipton, and J. Zico Kolter. Tofu: A task of fictitious unlearning for llms,
-
[10]
arXiv preprint arXiv:2401.06121 , year=
URLhttps://arxiv.org/abs/2401.06121. 12 Preprint. Pratyush Maini, Sachin Goyal, Dylan Sam, Alex Robey, Yash Savani, Yiding Jiang, Andy Zou, Matt Fredrikson, Zacharcy C. Lipton, and J. Zico Kolter. Safety pretraining: Toward the next generation of safe ai,
-
[11]
Michael McCloskey and Neal J Cohen
URLhttps://arxiv.org/abs/2504.16980. Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation, volume 24, pp. 109–165. Elsevier,
-
[12]
URL https://arxiv.org/abs/2410.17194. Kyle O’Brien, Stephen Casper, Quentin Anthony, Tomek Korbak, Robert Kirk, Xander Davies, Ishan Mishra, Geoffrey Irving, Yarin Gal, and Stella Biderman. Deep ignorance: Filtering pretraining data builds tamper-resistant safeguards into open-weight llms,
-
[13]
URLhttps://arxiv.org/abs/2508.06601. Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saum...
-
[14]
URLhttps://arxiv.org/abs/2512.13961. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to fol...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Training language models to follow instructions with human feedback
URL https://arxiv.org/abs/ 2203.02155. Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine- tuning aligned language models compromises safety, even when users do not intend to!,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
URL https://arxiv.org/abs/2310.03693. David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy P. Lillicrap, and Greg Wayne. Experience replay for continual learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Dylan Sam, Sachin Goyal, Pratyush Maini, Alexander Robey, and J
URLhttps://arxiv.org/abs/1811.11682. Dylan Sam, Sachin Goyal, Pratyush Maini, Alexander Robey, and J. Zico Kolter. When should we introduce safety interventions during pretraining?,
-
[18]
URLhttps://arxiv.org/abs/2601.07087. Jacob Mitchell Springer, Sachin Goyal, Kaiyue Wen, Tanishq Kumar, Xiang Yue, Sadhika Malladi, Graham Neubig, and Aditi Raghunathan. Overtrained language models are harder to fine-tune,
-
[19]
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov
URL https://arxiv.org/abs/2503.19206. Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting.J. Mach. Learn. Res., 15(1):1929–1958, January
-
[20]
ISSN 1532-4435. Mitchell Wortsman, Gabriel Ilharco, Samir Yitzhak Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S. Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time, 2022a. URLhttps://arxiv.org/abs/2...
-
[21]
URLhttps://arxiv.org/abs/2505.09388. Xianjun Yang, Xiao Wang, Qi Zhang, Linda Petzold, William Yang Wang, Xun Zhao, and Dahua Lin. Shadow alignment: The ease of subverting safely-aligned language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Pet- zold, William Yang Wang, Xun Zhao, and Dahua Lin
URL https://arxiv.org/abs/ 2310.02949. 14 Preprint. Contributions Lawrence Feng led the project and conducted all the main experiments. Gaurav R. Ghosal, Ziqian Zhong, Jacob Mitchell Springer, and Aditi Raghunathan were involved throughout the project, including project direction, experimental design, analysis, and paper writing. Acknowledgments We gratef...
-
[23]
22 Preprint. 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0 Retained Post-training Loss 2.2 2.3 2.4 2.5Fine-tuning Loss 1.4 1.5 1.6 1.7 1.8 1.9 2.0 2.1 Retained Post-training Loss 2.1 2.2 2.3 2.4Fine-tuning Loss C4 MusicPile FLAN Unmixed pretraining Mixed pretraining With dropout With replay Figure 12: Dropout and replay applied without pretraining-time mixing (1B).Comp...
2025
-
[24]
Following (Springer et al., 2025), we have the following initialization: Assumption C.8(Pretrained Initialization Scale).Let (W1(0),W 2(0)) be the parameters at initialization
Next, we will characterize the initialization scale of model before pretraining. Following (Springer et al., 2025), we have the following initialization: Assumption C.8(Pretrained Initialization Scale).Let (W1(0),W 2(0)) be the parameters at initialization. Then we have thatW 1(0) =W 2(0) = exp(−T)Id. Essentially, Assumption C.8 requires that the model pa...
2025
-
[25]
Next,we will study the dynamics of the non-zero singular values (Lemma A.11 Springer et al
=σi(t)−2ησi(t)(σi(t)2−(σspec,i)2) + 2ηλ(σi(t)2−σi(0)2)(2) As a result, note that whenσ(un)mixed i (0) = 0,σ(un)mixed i (t) = 0for allt. Next,we will study the dynamics of the non-zero singular values (Lemma A.11 Springer et al. (2025)). We will assume that post-training is performed for a sufficient number of steps. Assumption C.13(Sufficient Post-Trainin...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.