Recognition: unknown
When to Trust Confidence Thresholding: Calibration Diagnostics for Pseudo-Labelled Regression
Pith reviewed 2026-05-14 19:37 UTC · model grok-4.3
The pith
The attenuation bias from thresholding confidence scores can be predicted exactly from residual score variance on unlabeled data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Building on a recent identification result, we derive a closed-form expression for the attenuation bias that confidence thresholding induces in the downstream regression coefficient. The bias can be predicted from the residual score variance V^*=E[Var(p|X)] on the unlabelled set after partialling out the downstream controls X. We also obtain a sharp sensitivity bound under bounded calibration drift and identify the boundary V^*=0, which holds if and only if p is a deterministic function of X.
What carries the argument
The residual score variance V^* = E[Var(p | X)], which serves as a pre-inference diagnostic for the size of attenuation bias induced by thresholding.
If this is right
- The bias vanishes exactly when V^* = 0, i.e., when the score is fully determined by X.
- A (V^*, kappa) decision rule tells practitioners when thresholding is safe.
- The sensitivity bound quantifies how much calibration drift can be tolerated before the bias becomes large.
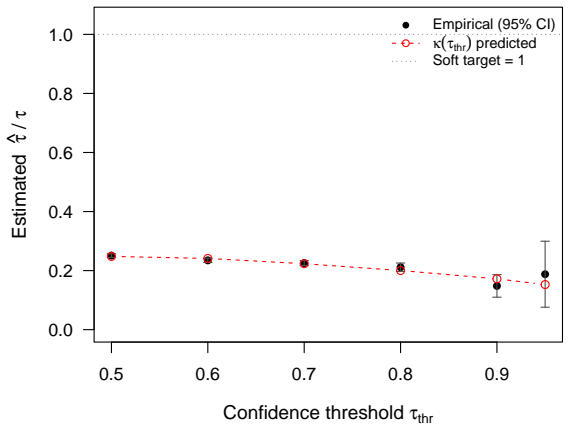
- Simulations and the UCI Adult example confirm that the formula predicts observed bias accurately.
Where Pith is reading between the lines
- Similar diagnostics could be developed for other pseudo-labeling strategies beyond simple thresholding.
- The framework suggests designing classifiers with explicit feature separation from downstream controls.
- Testing the diagnostic on streaming or online learning settings would reveal its robustness to distribution shift.
Load-bearing premise
The underlying moment equation is identified exactly and calibration drift remains bounded.
What would settle it
Run a controlled simulation with known true labels, apply thresholding at various cutoffs, and check if the difference between thresholded and oracle regression coefficients matches the predicted value from V^*.
Figures





read the original abstract
Calibrated probability outputs of trained classifiers are increasingly used as inputs to downstream regression estimands such as effects, prevalences, or disparities for a latent group observed only on a small labelled subset. A standard practice is to threshold the calibrated score at a confidence cutoff and treat the hard label as the truth. Building on a recent identification result for the underlying moment equation, we develop a calibration-aware diagnostic apparatus for pseudo-labelling pipelines. We derive a closed-form expression for the attenuation bias that confidence thresholding induces in the downstream regression coefficient, and show that the bias can be predicted, before any inference is run, from the residual score variance $V^{*}=\mathbb{E}[\operatorname{Var}(p\mid X)]$ on the unlabelled set after partialling out the downstream controls $X$. We further obtain a sharp sensitivity bound under bounded calibration drift, and identify the boundary $V^{*}=0$, which holds iff $p$ is a deterministic function of $X$; this motivates a structural separation between classifier features $W$ and downstream controls $X\subsetneq W$. Five controlled simulations and a UCI Adult illustration trace the predictions. The contribution is operational: a $(V^{*}, \kappa)$ decision rule that practitioners can compute from any classifier output to decide whether confidence thresholding is safe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to derive a closed-form expression for the attenuation bias that confidence thresholding induces in a downstream regression coefficient when using calibrated classifier scores as pseudo-labels. The bias is shown to be predictable before inference from the observable residual score variance V^*=E[Var(p|X)] on the unlabelled set after partialling out controls X. Building on an external identification result for the moment equation, the authors supply a sharp sensitivity bound under bounded calibration drift, identify the boundary V^*=0 (which holds iff p is deterministic in X), and motivate a structural separation X subset W. The contribution is operationalized as a (V^*, κ) decision rule, supported by five controlled simulations and a UCI Adult illustration.
Significance. If the derivation is exact, the result supplies a practical, pre-inference diagnostic that lets practitioners decide whether thresholding is safe using only classifier outputs and observable quantities. The closed-form prediction, the explicit sensitivity bound, and the structural separation between classifier features W and downstream controls X are clear strengths. The simulations and real-data example provide direct traceability of the predicted bias. This could affect practice in semi-supervised regression and pseudo-labelling pipelines in statistics and machine learning.
major comments (1)
- [Derivation of closed-form bias expression] The closed-form bias expression (abstract and derivation section) treats the thresholding operator 1{p>κ} as preserving the moment identification exactly once V^* is conditioned on X. This requires that any selection-induced covariance between the thresholded pseudo-label and the downstream regression error (conditional on X) is fully absorbed into the residual variance term. The supplied sensitivity bound addresses only calibration drift; an explicit bound or verification for the additional covariance term is needed, as its presence would make the closed-form understate the bias even when V^* is observed perfectly.
minor comments (1)
- [Abstract] The abstract states that five simulations 'trace the predictions' but does not report the specific ranges of V^* and κ examined or the design of the data-generating processes; adding a short table or sentence would improve reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the potential practical utility of the (V^*, κ) rule. We address the single major comment below and will strengthen the derivation section accordingly.
read point-by-point responses
-
Referee: The closed-form bias expression (abstract and derivation section) treats the thresholding operator 1{p>κ} as preserving the moment identification exactly once V^* is conditioned on X. This requires that any selection-induced covariance between the thresholded pseudo-label and the downstream regression error (conditional on X) is fully absorbed into the residual variance term. The supplied sensitivity bound addresses only calibration drift; an explicit bound or verification for the additional covariance term is needed, as its presence would make the closed-form understate the bias even when V^* is observed perfectly.
Authors: We appreciate the referee drawing attention to this covariance term. Under the structural separation X ⊂ W that we introduce, the downstream regression error is conditionally independent of the classifier features W (and hence of p and the thresholded pseudo-label) given X. The identification result we build upon therefore implies that E[thresholded pseudo-label × regression error | X] = 0, so the covariance vanishes and is absorbed into the residual variance V^* without further bias. The calibration-drift sensitivity bound is stated separately because drift can induce finite-sample dependence even when the population conditional independence holds. To make the argument fully explicit, we will insert a short lemma in the derivation section proving the covariance term is zero under our maintained assumptions and will note how the existing sensitivity bound extends if conditional independence is relaxed by a small amount. This clarification does not change the closed-form result or the (V^*, κ) rule. revision: yes
Circularity Check
No circularity: derivation relies on external identification result and direct definition of V*
full rationale
The paper states it builds on a recent external identification result for the underlying moment equation rather than deriving that condition from its own quantities. V* is introduced as the observable E[Var(p|X)] computed directly from classifier outputs after partialling out controls X; the closed-form attenuation bias is expressed as a function of this quantity without fitting V* to the target coefficient or renaming a fitted input as a prediction. No self-citation is load-bearing for the central claim, no ansatz is smuggled, and the structural separation X subset W is maintained as an explicit assumption. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Recent identification result for the underlying moment equation holds
- domain assumption Calibration drift is bounded
Reference graph
Works this paper leans on
- [1]
-
[2]
D.-H. Lee, Pseudo-label: The simple and efficient semi-supervised learn- ing method for deep neural networks, in: Workshop on challenges in representation learning, ICML, Vol. 3, Atlanta, 2013, p. 896
work page 2013
-
[3]
K. Sohn, D. Berthelot, C.-L. Li, Z. Zhang, N. Carlini, E. D. Cubuk, A.Kurakin, H.Zhang, C.Raffel, FixMatch: Simplifyingsemi-supervised learning with consistency and confidence, in: Advances in Neural Infor- mation Processing Systems (NeurIPS), 2020
work page 2020
- [4]
-
[5]
Y. Wang, H. Chen, Q. Heng, W. Hou, Y. Fan, Z. Wu, J. Wang, M. Sav- vides, T. Shinozaki, B. Raj, B. Schiele, X. Xie, FreeMatch: Self-adaptive thresholding for semi-supervised learning, International Conference on Learning Representations (ICLR) (2023)
work page 2023
-
[6]
A. Tarvainen, H. Valpola, Mean teachers are better role models: Weight- averaged consistency targets improve semi-supervised deep learning results, in: Advances in Neural Information Processing Systems (NeurIPS), 2017. 21
work page 2017
- [7]
-
[8]
M. T. Kurbucz, Identification of latent group effects under conditional calibration (2026)
work page 2026
-
[9]
R. Kohavi, Scaling up the accuracy of naive-Bayes classifiers: a decision- tree hybrid, in: ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1996, pp. 202–207
work page 1996
-
[10]
J. Li, C. Xiong, S. C. Hoi, CoMatch: Semi-supervised learning with contrastive graph regularization, in: Proceedings of the IEEE/CVF in- ternational conference on computer vision, 2021, pp. 9475–9484
work page 2021
-
[11]
M. N. Rizve, K. Duarte, Y. S. Rawat, M. Shah, In defense of pseudo- labeling: An uncertainty-aware pseudo-label selection framework for semi-supervised learning, in: International Conference on Learning Rep- resentations (ICLR), 2021
work page 2021
-
[12]
X. Wang, Z. Wu, L. Lian, S. X. Yu, Debiased learning from naturally imbalanced pseudo-labels, IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
work page 2022
-
[13]
J. E. Van Engelen, H. H. Hoos, A survey on semi-supervised learning, Machine learning 109 (2) (2020) 373–440
work page 2020
-
[14]
J. C. Platt, Probabilistic outputs for support vector machines and com- parisons to regularized likelihood methods, in: Advances in Large Mar- gin Classifiers, 1999
work page 1999
-
[15]
B.Zadrozny, C.Elkan, Transformingclassifierscoresintoaccuratemulti- classprobabilityestimates, in: ProceedingsoftheEighthACMSIGKDD International Conference on Knowledge Discovery and Data Mining, 2002, pp. 694–699
work page 2002
-
[16]
A. Niculescu-Mizil, R. Caruana, Predicting good probabilities with su- pervised learning, in: Proceedings of the 22nd International Conference on Machine Learning, 2005, pp. 625–632. 22
work page 2005
-
[17]
C. Guo, G. Pleiss, Y. Sun, K. Q. Weinberger, On calibration of modern neural networks, in: Proceedings of the 34th International Conference on Machine Learning, PMLR, 2017, pp. 1321–1330
work page 2017
-
[18]
M.Minderer, J.Djolonga, R.Romijnders, F.Hubis, X.Zhai, N.Houlsby, D. Tran, M. Lucic, Revisiting the calibration of modern neural networks, Advances in Neural Information Processing Systems 34 (2021) 15682– 15694
work page 2021
- [19]
-
[20]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, J. Dean, Distilling the knowledge in a neural network, arXiv preprint arXiv:1503.02531 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[21]
R.Müller, S.Kornblith, G.E.Hinton, Whendoeslabelsmoothinghelp?, Advances in Neural Information Processing Systems 32 (2019)
work page 2019
-
[22]
A. Lewbel, Estimation of average treatment effects with misclassifica- tion, Econometrica 75 (2) (2007) 537–551
work page 2007
-
[23]
A. Mahajan, Identification and estimation of regression models with misclassification, Econometrica 74 (3) (2006) 631–665
work page 2006
-
[24]
P. M. Robinson, Root-N-consistent semiparametric regression, Econo- metrica 56 (4) (1988) 931–954
work page 1988
-
[25]
V. Chernozhukov, D. Chetverikov, M. Demirer, E. Duflo, C. Hansen, W. Newey, J. Robins, Double/debiased machine learning for treatment and structural parameters, The Econometrics Journal 21 (1) (2018) C1– C68
work page 2018
-
[26]
B. Lakshminarayanan, A. Pritzel, C. Blundell, Simple and scalable pre- dictive uncertainty estimation using deep ensembles, Advances in Neural Information Processing Systems 30 (2017)
work page 2017
-
[27]
Y. Gal, Z. Ghahramani, Dropout as a Bayesian approximation: Repre- senting model uncertainty in deep learning, in: Proceedings of the 33rd International Conference on Machine Learning, 2016, pp. 1050–1059. 23
work page 2016
-
[28]
Breiman, Random forests, Machine Learning 45 (2001) 5–32
L. Breiman, Random forests, Machine Learning 45 (2001) 5–32
work page 2001
-
[29]
M. N. Wright, A. Ziegler, ranger: A fast implementation of random forests for high dimensional data in C++ and R, Journal of Statistical Software 77 (1) (2017) 1–17. 24
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.