OCH3R: Object-Centric Holistic 3D Reconstruction
Pith reviewed 2026-05-14 19:25 UTC · model grok-4.3
The pith
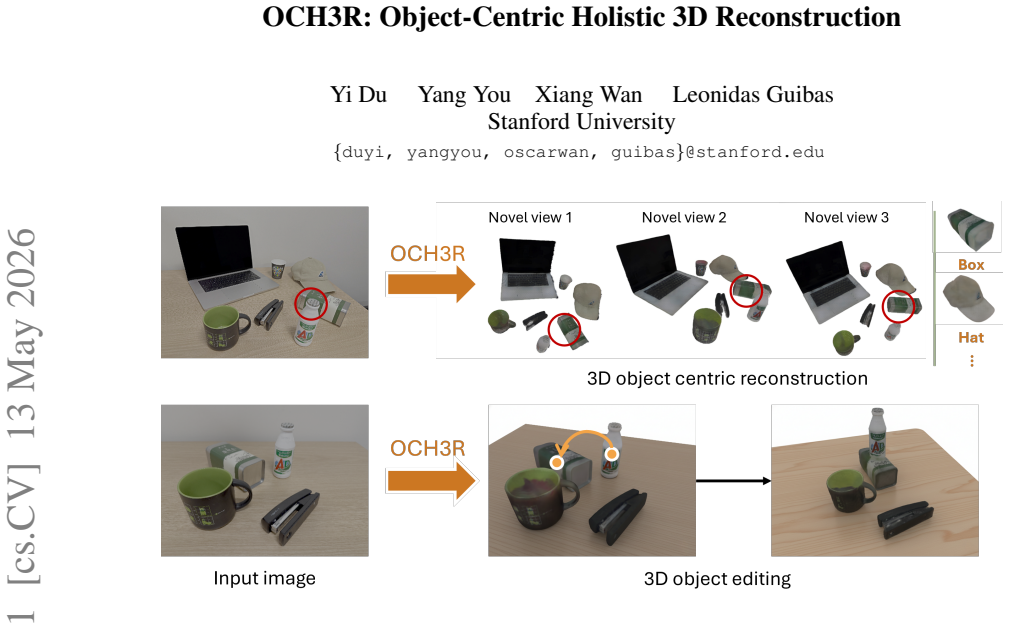
OCH3R reconstructs every object in a scene with its 6D pose and detailed 3D shape from a single RGB image in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OCH3R performs one forward pass to simultaneously predict all object instances with their 6D poses and detailed 3D reconstructions. A transformer predicts per-pixel CLIP-based category embeddings, metric depth, normalized object coordinates, and a fixed number of 3D Gaussians representing each object. The Gaussians are supervised by transforming them into canonical space with the predicted 6D poses and aligning them to pre-rendered canonical ground truth.
What carries the argument
Transformer that predicts per-pixel attributes including CLIP embeddings, metric depth, NOCS coordinates, and a fixed number of 3D Gaussians per object, supervised by canonical-space alignment using the predicted 6D poses.
If this is right
- Inference time stays constant regardless of how many objects appear in the scene.
- The method reaches state-of-the-art numbers on monocular depth estimation, open-vocabulary semantic segmentation, and RGB-only category-level 6D pose estimation.
- Per-object reconstructions remain editable because each object is represented by its own set of Gaussians.
- The single-pass design avoids error propagation that occurs when segmentation mistakes feed into later reconstruction stages.
Where Pith is reading between the lines
- Robotic systems could use the feed-forward output directly for grasp planning without waiting for separate segmentation or pose-refinement modules.
- The fixed-Gaussian representation may allow efficient transfer of object-level edits across different viewpoints of the same scene.
- Extending the same canonical-space supervision to video frames could yield temporally consistent object tracks without additional tracking losses.
Load-bearing premise
The predicted 6D poses must be accurate enough to transform the Gaussians into canonical space so that the alignment with ground truth provides reliable supervision.
What would settle it
Small deliberate perturbations to the predicted 6D poses cause the transformed Gaussian reconstructions to diverge sharply from the canonical ground-truth shapes on held-out test images.
Figures








read the original abstract
Object-centric scene understanding is a fundamental challenge in computer vision. Existing approaches often rely on multi-stage pipelines that first apply pre-trained segmentors to extract individual objects, followed by per-object 3D reconstruction. Such methods are computationally expensive, fragile to segmentation errors, and scale poorly with scene complexity. We introduce OCH3R, a unified framework for Object-Centric Holistic 3D Reconstruction from a single RGB image. OCH3R performs one forward pass to simultaneously predict all object instances with their 6D poses and detailed 3D reconstructions. The key idea is a transformer architecture that predicts per-pixel attributes, including CLIP-based category embeddings, metric depth, normalized object coordinates (NOCS), and a fixed number of 3D Gaussians representing each object. To supervise these Gaussian reconstructions, we transform them into canonical space using the predicted 6D poses and align them with pre-rendered canonical ground truth, avoiding costly per-image Gaussian label generation. On standard indoor benchmarks, OCH3R achieves state-of-the-art performance across monocular depth estimation, open-vocabulary semantic segmentation, and RGB-only category-level 6D pose estimation, while producing high-fidelity, editable per-object reconstructions. Crucially, inference is fully feed-forward and scales independently of the number of objects, offering orders-of-magnitude speedups over conventional multi-stage pipelines in cluttered scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. OCH3R introduces a transformer-based framework that performs object-centric 3D reconstruction from a single RGB image in one forward pass. It jointly predicts per-object 6D poses, CLIP-based category embeddings, metric depth, NOCS coordinates, and a fixed number of 3D Gaussians per object. Gaussians are transformed into canonical space using the predicted poses and supervised against pre-rendered canonical ground truth, avoiding per-image Gaussian labels. The method claims state-of-the-art results on monocular depth estimation, open-vocabulary semantic segmentation, and RGB-only category-level 6D pose estimation on indoor benchmarks, with inference that scales independently of scene complexity.
Significance. If the joint optimization succeeds without the circular dependency undermining training, the work would offer a meaningful advance by unifying multiple scene-understanding tasks into a single feed-forward model. The canonical-space Gaussian supervision strategy and fixed-Gaussian representation are technically interesting and could enable editable per-object reconstructions at low inference cost. The paper would benefit from explicit credit for reproducible code or parameter-free derivations, but none are mentioned.
major comments (3)
- [§4.2] §4.2 (Gaussian supervision loss): the reconstruction objective transforms the predicted 3D Gaussians into canonical space using the simultaneously predicted 6D poses before comparing to pre-rendered ground truth. This couples the reconstruction gradient directly to pose accuracy; no stop-gradient, auxiliary GT-pose loss, or staged training schedule is described, leaving open whether reliable gradients exist from random initialization.
- [§5] §5 (Experiments and ablations): no quantitative analysis or ablation table examines how pose estimation error propagates into reconstruction fidelity (e.g., Chamfer distance or PSNR versus pose rotation/translation error). The central claim that one-pass holistic reconstruction is reliable therefore rests on unverified assumptions about pose accuracy during training.
- [Table 2] Table 2 (pose and reconstruction metrics): the reported SOTA numbers for category-level 6D pose and per-object reconstruction are presented without error bars or cross-validation on the effect of the fixed Gaussian count hyper-parameter, making it difficult to assess robustness of the claimed performance.
minor comments (2)
- [§3.1] §3.1: the notation for the fixed number of Gaussians per object (N_g) is introduced without an explicit statement of its value or sensitivity analysis.
- [Figure 4] Figure 4: the qualitative reconstructions would benefit from side-by-side comparison with ground-truth meshes or point clouds to illustrate fidelity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and have revised the paper to improve clarity and provide additional analysis where needed.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Gaussian supervision loss): the reconstruction objective transforms the predicted 3D Gaussians into canonical space using the simultaneously predicted 6D poses before comparing to pre-rendered ground truth. This couples the reconstruction gradient directly to pose accuracy; no stop-gradient, auxiliary GT-pose loss, or staged training schedule is described, leaving open whether reliable gradients exist from random initialization.
Authors: We acknowledge the coupling between pose prediction and Gaussian reconstruction in the joint loss. Direct supervision on poses is provided independently via the NOCS and metric depth terms, which supply stable gradients from initialization. The Gaussian alignment loss then contributes once poses are sufficiently accurate. We have revised §4.2 to describe the loss weighting schedule and initialization strategy that prevent the circular dependency from undermining training. revision: yes
-
Referee: [§5] §5 (Experiments and ablations): no quantitative analysis or ablation table examines how pose estimation error propagates into reconstruction fidelity (e.g., Chamfer distance or PSNR versus pose rotation/translation error). The central claim that one-pass holistic reconstruction is reliable therefore rests on unverified assumptions about pose accuracy during training.
Authors: We agree that explicit quantification of error propagation strengthens the central claim. We have added a new ablation study in the revised §5 that injects controlled pose perturbations and reports the resulting changes in reconstruction metrics (Chamfer distance and PSNR). The results show graceful degradation and support the reliability of the one-pass approach. revision: yes
-
Referee: [Table 2] Table 2 (pose and reconstruction metrics): the reported SOTA numbers for category-level 6D pose and per-object reconstruction are presented without error bars or cross-validation on the effect of the fixed Gaussian count hyper-parameter, making it difficult to assess robustness of the claimed performance.
Authors: We have updated Table 2 to include error bars from multiple independent runs. We also conducted a sensitivity analysis over the fixed Gaussian count hyper-parameter and report the outcomes in the supplementary material, confirming that performance is robust within the operating range used in the main experiments. revision: yes
Circularity Check
No significant circularity; supervision relies on external canonical ground truth
full rationale
The OCH3R method predicts per-pixel attributes (CLIP embeddings, depth, NOCS, and fixed 3D Gaussians) plus 6D poses in one transformer forward pass. Supervision then transforms the predicted Gaussians into canonical space using those poses and aligns them to pre-rendered canonical ground truth. This is a joint optimization against an independent external signal, not a self-definition, fitted-input renaming, or self-citation chain. No load-bearing self-citations, uniqueness theorems, or ansatzes from prior author work appear in the derivation. The reported metrics (depth, segmentation, pose) are evaluated on standard benchmarks outside the fitted values, keeping the chain self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- fixed number of 3D Gaussians per object
axioms (1)
- domain assumption Pre-rendered canonical ground-truth shapes exist and are accurate for supervision alignment
Reference graph
Works this paper leans on
-
[1]
Zoedepth: Zero-shot transfer by com- bining relative and metric depth, 2023
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias M ¨uller. Zoedepth: Zero-shot transfer by com- bining relative and metric depth, 2023. 6
work page 2023
-
[2]
Aleksei Bochkovskii, Ama ¨el Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second, 2025. 6
work page 2025
-
[3]
Secondpose: Se(3)- consistent dual-stream feature fusion for category-level pose estimation
Yamei Chen, Yan Di, Guangyao Zhai, Fabian Manhardt, Chenyangguang Zhang, Ruida Zhang, Federico Tombari, Nassir Navab, and Benjamin Busam. Secondpose: Se(3)- consistent dual-stream feature fusion for category-level pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9959–9969, 2024. 2
work page 2024
-
[4]
Cheng Chi and Shuran Song. Garmentnets: Category-level pose estimation for garments via canonical space shape com- pletion, 2021. 1
work page 2021
-
[5]
Laura Downs, Anthony Francis, Nate Koenig, Brandon Kin- man, Ryan Hickman, Krista Reymann, Thomas B. McHugh, and Vincent Vanhoucke. Google scanned objects: A high- quality dataset of 3d scanned household items, 2022. 3
work page 2022
-
[6]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geomet- ric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10579–10596, 2024. 6
work page 2024
-
[7]
Multi-task learning using uncertainty to weigh losses for scene geome- try and semantics, 2018
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geome- try and semantics, 2018. 3
work page 2018
-
[8]
An analysis of svd for deep rotation estimation,
Jake Levinson, Carlos Esteves, Kefan Chen, Noah Snavely, Angjoo Kanazawa, Afshin Rostamizadeh, and Ameesh Makadia. An analysis of svd for deep rotation estimation,
-
[9]
Chi Li, Jin Bai, and Gregory D. Hager. A unified framework for multi-view multi-class object pose estimation, 2018. 1
work page 2018
-
[10]
Instance-adaptive and geometric-aware keypoint learning for category-level 6d object pose estimation
Xiao Lin, Wenfei Yang, Yuan Gao, and Tianzhu Zhang. Instance-adaptive and geometric-aware keypoint learning for category-level 6d object pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21040–21049, 2024. 2
work page 2024
-
[11]
Monodiff9d: Monocular category-level 9d object pose estimation via diffusion model
Jian Liu, Wei Sun, Hui Yang, Jin Zheng, Zichen Geng, Hos- sein Rahmani, and Ajmal Mian. Monodiff9d: Monocular category-level 9d object pose estimation via diffusion model. InIEEE International Conference on Robotics and Automa- tion (ICRA), 2025. 2
work page 2025
-
[12]
Dinov2: Learning robust visual features with- out supervision, 2024
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Je- gou, Julien Mairal, ...
work page 2024
-
[13]
Unidepthv2: Universal monocular metric depth estimation made simpler, 2025
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mat- tia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler, 2025. 6
work page 2025
-
[14]
Vi- sion transformers for dense prediction, 2021
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction, 2021. 1
work page 2021
- [15]
-
[16]
Normalized object coordinate space for category-level 6d object pose and size estimation
He Wang, Srinath Sridhar, Jingwei Huang, Julien Valentin, Shuran Song, and Leonidas J Guibas. Normalized object coordinate space for category-level 6d object pose and size estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2642–2651,
-
[17]
Vggt: Vi- sual geometry grounded transformer, 2025
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer, 2025. 1, 6
work page 2025
-
[18]
Garmenttracking: Category-level garment pose tracking, 2025
Han Xue, Wenqiang Xu, Jieyi Zhang, Tutian Tang, Yutong Li, Wenxin Du, Ruolin Ye, and Cewu Lu. Garmenttracking: Category-level garment pose tracking, 2025. 1
work page 2025
-
[19]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2, 2024. 6
work page 2024
-
[20]
Harley, Leonidas Guibas, and Cewu Lu
Yang You, Kai Xiong, Zhening Yang, Zhengxiang Huang, Junwei Zhou, Ruoxi Shi, Zhou Fang, Adam W. Harley, Leonidas Guibas, and Cewu Lu. Pace: A large-scale dataset with pose annotations in cluttered environments, 2024. 3
work page 2024
-
[21]
New crfs: Neural window fully-connected crfs for monocular depth estimation, 2022
Weihao Yuan, Xiaodong Gu, Zuozhuo Dai, Siyu Zhu, and Ping Tan. New crfs: Neural window fully-connected crfs for monocular depth estimation, 2022. 6
work page 2022
-
[22]
Omni6dpose: A benchmark and model for universal 6d object pose estima- tion and tracking, 2024
Jiyao Zhang, Weiyao Huang, Bo Peng, Mingdong Wu, Fei Hu, Zijian Chen, Bo Zhao, and Hao Dong. Omni6dpose: A benchmark and model for universal 6d object pose estima- tion and tracking, 2024. 3
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.