Recognition: unknown
Three-Stage Learning Unlocks Strong Performance in Simple Models for Long-Term Time Series Forecasting
Pith reviewed 2026-05-14 19:08 UTC · model grok-4.3
The pith
A three-stage training process lets simple MLP models match complex architectures on long-term time series forecasting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
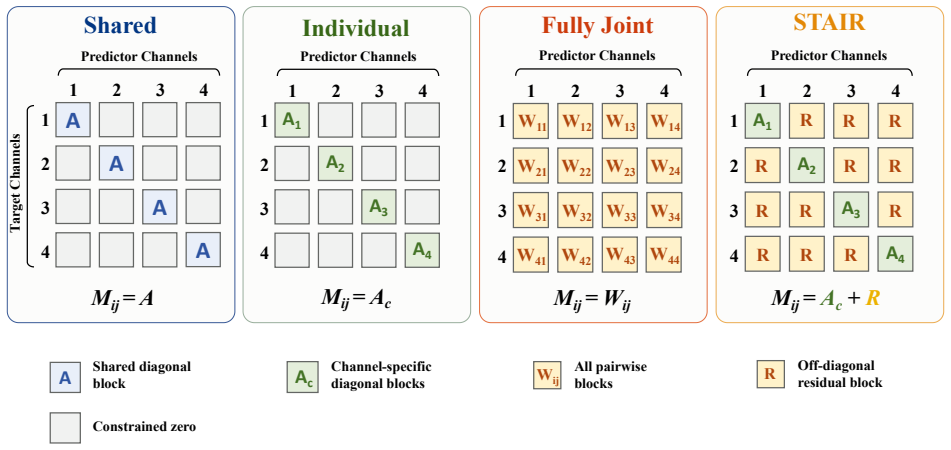
STAIR decomposes forecasting ability into three stages on a shallow MLP: shared temporal mapping to capture common dynamics across variables, channel-wise fine-tuning for variable-specific patterns, and residual learning to incorporate cross-variable information. Combined with Shared-to-Individual Fine-tuning and alpha-RevIN to address strict channel independence and strong normalization priors, the method matches or outperforms recent strong baselines on nine long-term forecasting benchmarks while keeping the core temporal predictor simple.
What carries the argument
STAIR (Stagewise Temporal Adaptation via Individualization and Residual Learning), a sequential three-stage training process that starts with shared mapping, moves to per-variable adaptation, and ends with residual cross-variable addition on a basic temporal backbone.
If this is right
- Simple linear and MLP models can reach competitive accuracy on long-term forecasting benchmarks through staged training alone.
- Gradual increase in modeling flexibility avoids the need for complex architectural priors such as frequency-domain or multi-scale modules.
- Alpha-RevIN offers a tunable normalization that mitigates the overly strong prior of standard RevIN while retaining more original signal.
- Channel-wise fine-tuning effectively captures variable-specific temporal patterns without requiring full cross-variable mixing from the start.
Where Pith is reading between the lines
- The staged specialization might transfer to other sequence tasks where end-to-end training leaves shared and specific patterns entangled.
- Testing whether reversing the stage order or adding a fourth stage for higher-order interactions produces further gains would be a direct next experiment.
- The approach could be combined with minimal linear layers or attention on top of the residual stage to explore the performance-efficiency frontier with still-simple backbones.
Load-bearing premise
The three stages can be trained sequentially on a shallow MLP without later stages overwriting useful shared patterns learned earlier.
What would settle it
If applying the three stages to the same shallow MLP yields no improvement over standard end-to-end training across the nine benchmarks, the value of the staged organization would be falsified.
Figures


read the original abstract
Recent studies on long-term time series forecasting have shown that simple linear models and MLP-based predictors can achieve strong performance without increasingly complex architectures. However, many competitive baselines still rely on structural priors such as frequency-domain modeling, explicit decomposition, multi-scale mixing, or sophisticated cross-variable interaction modules, while paying less attention to how simple temporal mappings should be trained and organized. In this paper, we propose STAIR, short for Stagewise Temporal Adaptation via Individualization and Residual Learning, a training paradigm for long-term time series forecasting that aims to unlock the capacity of simple temporal mapping models without introducing complex architectural modules. STAIR decomposes forecasting ability into three progressive stages: it first learns common temporal dynamics across variables through a shared temporal mapping, then adapts the shared model to each variable via channel-wise fine-tuning to capture variable-specific patterns, and finally complements the backbone with cross-variable information through residual learning. We further introduce Shared-to-Individual Fine-tuning and alpha-RevIN to mitigate the limitations of strict channel independence and the overly strong normalization prior induced by standard RevIN. This design gradually increases modeling flexibility while keeping the core temporal predictor as a shallow MLP in the main experiments, with linear variants analyzed separately. Experiments on nine long-term forecasting benchmarks show that STAIR matches or outperforms recent strong baselines while preserving a simple temporal backbone, providing a concise and effective modeling perspective for long-term time series forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STAIR, a three-stage training paradigm for simple temporal models such as shallow MLPs in long-term time series forecasting. Stage 1 learns shared temporal dynamics across variables, Stage 2 performs channel-wise fine-tuning for variable-specific patterns, and Stage 3 adds residual cross-variable information. The method introduces Shared-to-Individual Fine-tuning and alpha-RevIN to address channel independence and normalization issues, claiming to match or outperform recent strong baselines on nine long-term forecasting benchmarks while preserving a simple backbone.
Significance. If the empirical results hold under scrutiny, the work is significant because it shows that competitive long-term forecasting performance can be achieved through staged training of simple models rather than architectural elaboration, offering a concise alternative perspective to the prevailing emphasis on complex modules like frequency decomposition or multi-scale mixing. The benchmark results provide concrete evidence that basic temporal predictors can be unlocked via progressive adaptation.
major comments (2)
- [Method description of the three progressive stages] The central claim that the three stages build cumulatively without interference is load-bearing but unverified: in a shallow MLP backbone, Stage 2 channel-wise fine-tuning risks overwriting the shared temporal mappings learned in Stage 1, and Stage 3 residuals may compensate for degraded representations rather than complement them. No ablation freezes the shared weights or measures representation retention across stages.
- [Experiments section] Table of benchmark results: performance claims lack error bars, standard deviations across runs, or statistical significance tests, and exact hyperparameter settings (learning rates per stage, fine-tuning epochs) are not reported, undermining reproducibility and the assertion of consistent outperformance over baselines.
minor comments (2)
- [Method] The definition of alpha-RevIN should include an explicit equation showing how the scaling parameter modifies standard RevIN to avoid overly strong normalization.
- [Experiments] Figure captions and the experimental setup would benefit from clearer notation distinguishing the linear variant from the MLP backbone used in main results.
Circularity Check
No circularity: empirical staged training validated on external benchmarks
full rationale
The paper presents STAIR as a three-stage empirical training procedure (shared temporal mapping, channel-wise fine-tuning, residual cross-variable learning) applied to a shallow MLP backbone, augmented by Shared-to-Individual Fine-tuning and alpha-RevIN. All performance claims are supported by direct experiments on nine independent long-term forecasting benchmarks, with no equations, predictions, or first-principles derivations that reduce to quantities defined solely by fitted parameters or self-citations within the paper. The central results are measured against external baselines and test sets, preserving independent content in the evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha in alpha-RevIN
axioms (1)
- domain assumption Simple MLP or linear models possess sufficient capacity for long-term forecasting when trained with progressive adaptation.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[2]
Advances in Neural Information Processing Systems , year=
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting , author=. Advances in Neural Information Processing Systems , year=
-
[3]
International Conference on Machine Learning , year=
FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting , author=. International Conference on Machine Learning , year=
-
[4]
International Conference on Learning Representations , year=
Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift , author=. International Conference on Learning Representations , year=
-
[5]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Are Transformers Effective for Time Series Forecasting? , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[6]
International Conference on Learning Representations , year=
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers , author=. International Conference on Learning Representations , year=
-
[7]
International Conference on Learning Representations , year=
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis , author=. International Conference on Learning Representations , year=
-
[8]
International Conference on Learning Representations , year=
Crossformer: Transformer Utilizing Cross-Dimension Dependency for Multivariate Time Series Forecasting , author=. International Conference on Learning Representations , year=
-
[9]
arXiv preprint arXiv:2303.06053 , year=
TSMixer: An All-MLP Architecture for Time Series Forecasting , author=. arXiv preprint arXiv:2303.06053 , year=
-
[10]
International Conference on Learning Representations , year=
FITS: Modeling Time Series with 10k Parameters , author=. International Conference on Learning Representations , year=
-
[11]
International Conference on Machine Learning , year=
SparseTSF: Modeling Long-term Time Series Forecasting with 1k Parameters , author=. International Conference on Machine Learning , year=
-
[12]
International Conference on Learning Representations , year=
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting , author=. International Conference on Learning Representations , year=
-
[13]
International Conference on Learning Representations , year=
TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting , author=. International Conference on Learning Representations , year=
-
[14]
International Conference on Learning Representations , year=
ModernTCN: A Modern Pure Convolution Structure for General Time Series Analysis , author=. International Conference on Learning Representations , year=
-
[15]
Long- term forecasting with tide: Time-series dense encoder,
Long-term Forecasting with TiDE: Time-series Dense Encoder , author=. arXiv preprint arXiv:2304.08424 , year=
-
[16]
Advances in Neural Information Processing Systems , year=
Non-stationary Transformers: Rethinking the Stationarity in Time Series Forecasting , author=. Advances in Neural Information Processing Systems , year=
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Dish-TS: A General Paradigm for Alleviating Distribution Shift in Time Series Forecasting , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.