Recognition: no theorem link
Sampling from Flow Language Models via Marginal-Conditioned Bridges
Pith reviewed 2026-05-14 19:03 UTC · model grok-4.3
The pith
Flow language models sample better by conditioning bridges on sampled one-hot endpoints from posterior marginals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Flow Language Models output posterior marginal distributions over clean tokens. Standard DDPM-style samplers collapse each marginal to its conditional mean and bridge toward that simplex point. The proposed sampler instead draws a full one-hot endpoint sequence from the factorized posterior at every reverse step and then draws the next continuous state from the analytic Ornstein-Uhlenbeck bridge conditioned on that endpoint. Under exact marginals the endpoint approximation error is exactly the conditional multi-information among positions. The induced one-step kernel preserves every token-wise posterior-predictive marginal while discarding only residual cross-position dependence. A Girsanov,
What carries the argument
marginal-conditioned Ornstein-Uhlenbeck bridge that samples a one-hot endpoint from the FLM posterior marginals and bridges the continuous state toward it
If this is right
- The sampler requires no retraining and performs the same number of model evaluations as standard DDPM sampling.
- Temperature scaling and nucleus truncation can be applied directly to the sampled token marginals before bridge construction.
- The one-step transition kernel exactly preserves all token-wise posterior-predictive marginals.
- The endpoint error is provably equal to the conditional multi-information among positions under exact marginals.
Where Pith is reading between the lines
- The same marginal-conditioning idea could be applied to any diffusion or flow model whose denoiser outputs factorized marginals.
- Incorporating learned cross-position dependence into the endpoint sampling step might recover some of the information currently discarded.
- The error reduction may become more pronounced on longer sequences where multi-information accumulates.
Load-bearing premise
The FLM denoisers supply exact posterior marginal distributions over clean tokens at each position.
What would settle it
An explicit path where the integrated denoising error of the marginal-conditioned bridge exceeds that of the conditional-mean bridge, or a controlled experiment showing no quality-diversity gain when the new sampler is substituted for the mean bridge.
Figures

read the original abstract
Flow Language Models (FLMs) are a recently introduced class of language models which adapt continuous flow matching for one-hot encoded token sequences. Their denoisers have a special structure absent from generic continuous diffusion models: each block of the denoising mean is a posterior marginal distribution over the clean token at that position. Standard DDPM-style samplers collapse these marginals to a single conditional-mean endpoint and bridge toward this simplex-valued point, which is generally not a valid one-hot sequence. We argue that the natural sampler for an FLM is instead posterior-predictive. At each reverse step, we sample a clean one-hot endpoint from the factorized posterior defined by the FLM token marginals, and then sample the next continuous state from the analytic Ornstein--Uhlenbeck bridge conditioned on that endpoint. The method is training-free, uses the same model evaluations as standard sampling, and gives a principled interface for token-level decoding controls such as temperature scaling and nucleus truncation. We show that, under exact posterior marginals, the endpoint approximation error is exactly the conditional multi-information among token positions. The induced one-step bridge kernel preserves all token-wise posterior-predictive marginals and loses only the residual cross-position dependence. Finally, we prove a Girsanov path-space comparison showing that the marginal-conditioned bridge has a no-larger denoising-error term than the frozen conditional-mean bridge, with strict improvement whenever intermediate coordinate-wise bridge observations reveal additional information about the clean token. Experiments with FLMs show that the sampler improves the quality--diversity tradeoff. Code is available at: github.com/imbirik/mcb.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a marginal-conditioned bridge (MCB) sampler for Flow Language Models (FLMs). Instead of bridging to a frozen conditional-mean endpoint, the method samples a one-hot clean token from the factorized posterior marginals supplied by the FLM denoiser and then draws the next state from the exact Ornstein-Uhlenbeck bridge conditioned on that endpoint. Under the assumption of exact posterior marginals, the authors derive that the endpoint approximation error equals the conditional multi-information among token positions, prove that the one-step kernel preserves all token-wise posterior-predictive marginals, and establish via Girsanov change of measure that the path-space denoising error of the MCB is at most that of the conditional-mean bridge, with strict improvement when intermediate observations carry additional information about the clean token. Experiments on FLMs report improved quality-diversity trade-offs while remaining training-free and using the same number of model evaluations.
Significance. If the Girsanov comparison and exact error bound hold, the work supplies a principled, training-free improvement to sampling from FLMs together with a path-space optimality guarantee that is stronger than standard DDPM-style collapse. The explicit multi-information characterization of the approximation error and the marginal-preservation property are technically attractive and could generalize to other structured continuous generative models. The availability of reproducible code is a positive contribution.
major comments (2)
- [§4] §4 (Girsanov path-space comparison): The proof that the marginal-conditioned bridge has denoising-error term ≤ that of the frozen conditional-mean bridge relies on the existence of the Radon-Nikodym derivative between the two bridge measures. This requires the drift difference to satisfy a Novikov-type integrability condition. The manuscript states the result 'under exact posterior marginals' but provides no explicit verification that the moment condition holds uniformly, especially when marginals approach the uniform distribution or at early reverse times when the processes remain far from the endpoint. This integrability gap is load-bearing for the central comparison claim.
- [§3] §3 (endpoint approximation error): The claim that the error is exactly the conditional multi-information assumes the FLM denoiser supplies exact posterior marginals at every position and time. In practice these marginals are learned approximations; the manuscript does not quantify how the multi-information bound degrades under approximate marginals, which directly affects the practical significance of the theoretical guarantee.
minor comments (2)
- The notation for the Ornstein-Uhlenbeck bridge drift and the precise definition of the 'frozen conditional-mean bridge' could be stated more explicitly in the main text (currently referenced only via the appendix) to improve readability for readers unfamiliar with conditioned diffusions.
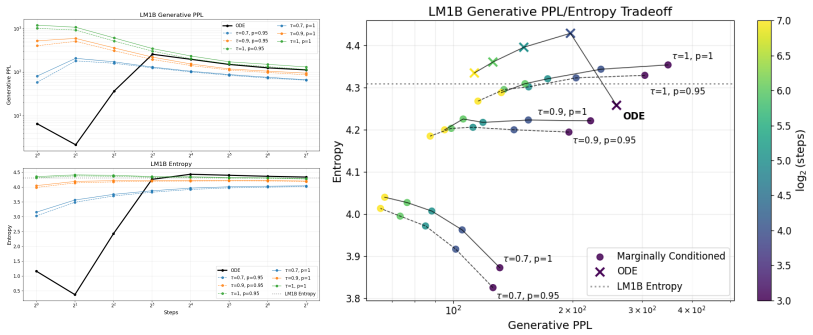
- Figure 2 (quality-diversity curves) would benefit from error bars or multiple random seeds to allow assessment of statistical significance of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. We address each major comment below and will incorporate the suggested clarifications into the revised version.
read point-by-point responses
-
Referee: [§4] §4 (Girsanov path-space comparison): The proof that the marginal-conditioned bridge has denoising-error term ≤ that of the frozen conditional-mean bridge relies on the existence of the Radon-Nikodym derivative between the two bridge measures. This requires the drift difference to satisfy a Novikov-type integrability condition. The manuscript states the result 'under exact posterior marginals' but provides no explicit verification that the moment condition holds uniformly, especially when marginals approach the uniform distribution or at early reverse times when the processes remain far from the endpoint. This integrability gap is load-bearing for the central comparison claim.
Authors: We agree that an explicit verification of the Novikov condition strengthens the presentation. In the revised manuscript we will add a short appendix showing that the condition holds uniformly. Because the Ornstein-Uhlenbeck drift is linear with bounded coefficients and the endpoint difference is confined to the probability simplex (hence bounded), the squared drift difference is uniformly integrable over the finite time horizon. This bound is independent of the particular marginal configuration, including near-uniform marginals and early reverse times. revision: yes
-
Referee: [§3] §3 (endpoint approximation error): The claim that the error is exactly the conditional multi-information assumes the FLM denoiser supplies exact posterior marginals at every position and time. In practice these marginals are learned approximations; the manuscript does not quantify how the multi-information bound degrades under approximate marginals, which directly affects the practical significance of the theoretical guarantee.
Authors: The statements in §3 are derived under the exact-marginal assumption, as explicitly stated in the manuscript. When the supplied marginals are approximate, the endpoint error is the conditional multi-information plus a non-negative term controlled by the total variation distance between the approximate and true marginals. We will add a clarifying paragraph in the revised version to make this decomposition explicit. A quantitative bound on the degradation is model-specific and would require a separate analysis of the denoiser’s approximation error; we therefore leave such a study for future work while noting that the reported experiments already show practical improvement with the learned marginals. revision: partial
Circularity Check
No circularity: derivations are self-contained under stated assumptions
full rationale
The paper's load-bearing steps—the endpoint error equaling conditional multi-information, the one-step kernel preserving token-wise marginals, and the Girsanov path-space comparison—are presented as direct consequences of the Ornstein-Uhlenbeck bridge construction and the exact-posterior-marginals assumption. No equation reduces by construction to a fitted parameter, renamed empirical pattern, or self-citation chain. The Girsanov argument is introduced as a new comparison between the marginal-conditioned and frozen bridges; it does not invoke prior results by the same authors as a uniqueness theorem or ansatz. The derivation therefore remains independent of its inputs once the modeling assumptions are granted.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption FLM denoisers provide exact posterior marginal distributions over clean tokens
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Michael Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209):1– 80, 2025
work page 2025
-
[3]
Building Normalizing Flows with Stochastic Interpolants
Michael S Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants.arXiv preprint arXiv:2209.15571, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [4]
-
[5]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces, 2023
work page 2023
-
[6]
A continuous time framework for discrete denoising models, 2022
Andrew Campbell, Joe Benton, Valentin De Bortoli, Tom Rainforth, George Deligiannidis, and Arnaud Doucet. A continuous time framework for discrete denoising models, 2022
work page 2022
-
[7]
One billion word benchmark for measuring progress in statistical language modeling, 2014
Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. One billion word benchmark for measuring progress in statistical language modeling, 2014
work page 2014
-
[8]
LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling
Yuxin Chen, Chumeng Liang, Hangke Sui, Ruihan Guo, Chaoran Cheng, Jiaxuan You, and Ge Liu. Langflow: Continuous diffusion rivals discrete in language modeling.arXiv preprint arXiv:2604.11748, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Itai Gat, Tal Remez, Neta Shaul, Felix Kreuk, Ricky T. Q. Chen, Gabriel Synnaeve, Yossi Adi, and Yaron Lipman. Discrete flow matching, 2024
work page 2024
-
[10]
Openwebtext corpus.HTTP://SKYLION007.GITHUB.IO/O PENWEBTEXTCORPUS, 2019
Aaron Gokaslan and Vanya Cohen. Openwebtext corpus.HTTP://SKYLION007.GITHUB.IO/O PENWEBTEXTCORPUS, 2019
work page 2019
-
[11]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[12]
The curious case of neural text degeneration, 2020
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration, 2020
work page 2020
-
[13]
Flow Map Language Models: One-step Language Modeling via Continuous Denoising
Chanhyuk Lee, Jaehoon Yoo, Manan Agarwal, Sheel Shah, Jerry Huang, Aditi Raghunathan, Seunghoon Hong, Nicholas M Boffi, and Jinwoo Kim. Flow map language models: One-step language modeling via continuous denoising.arXiv preprint arXiv:2602.16813, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Discrete diffusion modeling by estimating the ratios of the data distribution, 2024
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution, 2024
work page 2024
-
[16]
Ornstein–uhlenbeck processes and exten- sions.Handbook of financial time series, pages 421–437, 2009
Ross A Maller, Gernot Müller, and Alex Szimayer. Ornstein–uhlenbeck processes and exten- sions.Handbook of financial time series, pages 421–437, 2009. 10
work page 2009
-
[17]
Constraint ornstein-uhlenbeck bridges.Journal of Mathematical Physics, 58(9), 2017
Alain Mazzolo. Constraint ornstein-uhlenbeck bridges.Journal of Mathematical Physics, 58(9), 2017
work page 2017
-
[18]
Linear convergence of diffusion models under the manifold hypothesis, 2025
Peter Potaptchik, Iskander Azangulov, and George Deligiannidis. Linear convergence of diffusion models under the manifold hypothesis, 2025
work page 2025
-
[19]
Peter Potaptchik, Jason Yim, Adhi Saravanan, Peter Holderrieth, Eric Vanden-Eijnden, and Michael S Albergo. Discrete flow maps.arXiv preprint arXiv:2604.09784, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
work page 2019
-
[21]
Categorical flow maps.arXiv preprint arXiv:2602.12233, 2026
Daan Roos, Oscar Davis, Floor Eijkelboom, Michael Bronstein, Max Welling, ˙Ismail ˙Ilkan Ceylan, Luca Ambrogioni, and Jan-Willem van de Meent. Categorical flow maps.arXiv preprint arXiv:2602.12233, 2026
-
[22]
Simple and effective masked diffusion language models, 2024
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models, 2024
work page 2024
-
[23]
Logit-kl flow matching: Non-autoregressive text generation via sampling-hybrid inference
Egor Sevriugov, Nikita Dragunov, Anton Razzhigaev, Andrey Kuznetsov, and Ivan Oseledets. Logit-kl flow matching: Non-autoregressive text generation via sampling-hybrid inference. In The Fourteenth International Conference on Learning Representations
-
[24]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
work page 2015
-
[25]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[26]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 11 A Pseudo-Code Algorithm 5Marginal-conditioned OU bridge sampler Require:Reverse grid0 =t 0 < t 1 <· · ·...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.