Recognition: 1 theorem link
· Lean TheoremVoxCor: Training-Free Volumetric Features for Multimodal Voxel Correspondence
Pith reviewed 2026-05-14 19:30 UTC · model grok-4.3
The pith
A training-free fit-transform method creates reusable volumetric features from frozen 2D vision transformers for cross-modal voxel correspondence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
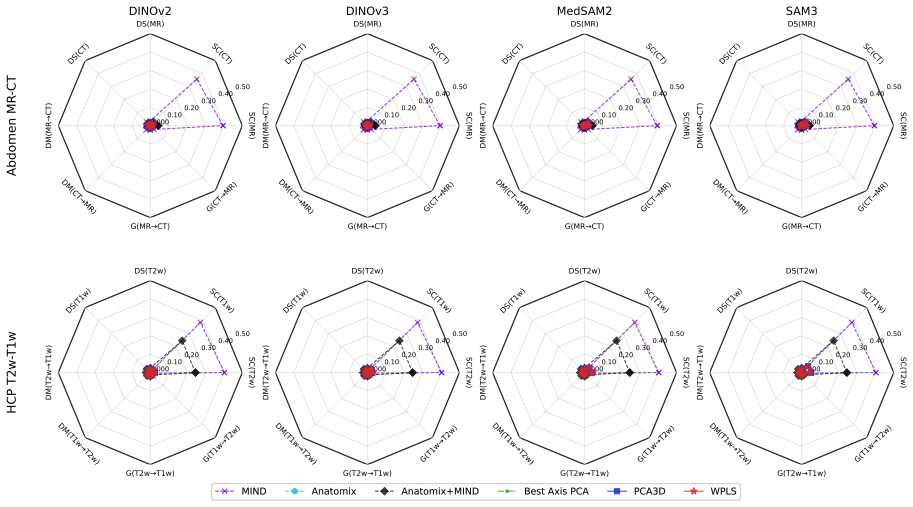
VoxCor is a training-free fit-transform method that combines triplanar ViT inference with a closed-form weighted partial least squares projection fitted on correspondences to select modality-stable anatomical directions; at transform time new volumes receive the same triplanar features followed by the fixed projection, after which correspondences are obtained by nearest-neighbor search, yielding improved performance in the hardest cross-subject cross-modality settings and registration results competitive with handcrafted descriptors and learned 3D features.
What carries the argument
The closed-form weighted partial least squares (WPLS) projection on triplanar ViT features, which uses fitting-time correspondences to identify modality-stable anatomical directions.
If this is right
- Voxel correspondences on new volumes can be obtained directly by nearest-neighbor search without any registration step.
- Registration performance becomes competitive with handcrafted descriptors and learned 3D features.
- Encoder sensitivity decreases for dense correspondence transfer across modalities.
- The same features support downstream tasks such as voxelwise k-nearest-neighbor segmentation and segmentation-center landmark localization.
- The resulting representations serve as a reusable feature layer for multimodal analysis beyond single-pair registration.
Where Pith is reading between the lines
- The same fitting procedure could be repeated on other 2D foundation models to produce modality-stable 3D features without redesigning the projection step.
- Fitting correspondences from a wider range of anatomical sites might allow the method to handle previously unseen body regions with minimal extra data.
- Because no per-volume optimization occurs at test time, the approach could be inserted into real-time clinical pipelines that currently avoid learned features due to compute cost.
- Combining the projected features with classical intensity-based registration as a coarse-to-fine step might further reduce residual errors in difficult cross-subject cases.
Load-bearing premise
The modality-stable anatomical directions identified by the WPLS projection on fitting-time correspondences generalize to new volumes and unseen modality combinations without further adaptation.
What would settle it
A clear drop in nearest-neighbor correspondence accuracy or deformable registration Dice scores when the fitted projection is applied to a new cross-modality volume pair absent from the fitting correspondences.
Figures








read the original abstract
Cross-modal 3D medical image analysis requires voxelwise representations that remain anatomically consistent across imaging contrasts, scanners, and acquisition protocols. Recent work has shown that frozen 2D Vision Transformer (ViT) foundation models can support such representations, but typical pipelines extract features along a single anatomical axis and adapt those features inside a registration solver for one image pair at a time, leaving complementary viewing directions unused and producing representations that do not transfer to new volumes. We introduce VoxCor, a training-free fit--transform method for reusable volumetric feature representations from frozen 2D ViT foundation models. During an offline fitting phase, VoxCor combines triplanar ViT inference with a compact closed-form weighted partial least squares (WPLS) projection that uses fitting-time voxel correspondences to select modality-stable anatomical directions in the triplanar feature space. At transform time, new volumes are mapped by triplanar ViT inference and linear projection alone, without fine-tuning or registration. Voxel correspondences can then be queried directly by nearest-neighbor search. We evaluate VoxCor on intra-subject Abdomen MR--CT and inter-subject HCP T2w--T1w tasks using deformable registration, voxelwise k-nearest-neighbor segmentation, and segmentation-center landmark localization. VoxCor improves the hardest cross-subject, cross-modality transfer settings, reduces encoder sensitivity for dense correspondence transfer, and yields registration performance competitive with handcrafted descriptors and learned 3D features. This positions VoxCor as a reusable feature layer for downstream multimodal analysis beyond pairwise registration. Code, configuration files, and implementation details are publicly available on GitHub at \href{https://github.com/guneytombak/VoxCor}{guneytombak/VoxCor}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VoxCor, a training-free fit-transform method that extracts reusable volumetric features from frozen 2D ViT foundation models via triplanar inference followed by a closed-form weighted partial least squares (WPLS) projection fitted once on voxel correspondences. These features support direct nearest-neighbor voxel correspondence across modalities and subjects without per-pair adaptation or fine-tuning, and are evaluated on intra-subject Abdomen MR-CT and inter-subject HCP T2w-T1w tasks for deformable registration, kNN segmentation, and landmark localization, claiming gains in the hardest cross-subject cross-modality settings, reduced encoder sensitivity, and competitive performance versus handcrafted and learned 3D descriptors.
Significance. If the WPLS-derived directions prove to generalize beyond the fitting distribution, VoxCor would supply a practical, reusable feature layer for multimodal 3D medical imaging that avoids task-specific training or per-pair solvers, simplifying pipelines for registration and dense correspondence. The training-free design and public code release are notable strengths for reproducibility.
major comments (3)
- [Abstract] Abstract: the claims of performance improvements, reduced encoder sensitivity, and competitive registration results are stated without any quantitative numbers, error bars, data-split details, baseline specifications, or subject counts for fitting versus test phases, making it impossible to verify whether the data support the central claims.
- [Abstract] Abstract and evaluation description: the manuscript does not state whether the fitting set used to learn the WPLS projection is disjoint from the test volumes or how many subjects are used for fitting, which is load-bearing for the claim that modality-stable directions generalize to new volumes and unseen modality combinations.
- [Method (WPLS)] Method section on WPLS projection: because the projection is fitted using external voxel correspondences from a fitting set, the selected directions may encode dataset-specific anatomical or acquisition biases rather than truly invariant features; without explicit held-out validation this risks circularity in the 'training-free reusable feature' positioning.
minor comments (1)
- [Abstract] The GitHub link is given but the main text could include a brief reproducibility checklist (exact ViT backbone, triplanar axis choices, and WPLS hyperparameters) to aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to improve clarity and support for the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of performance improvements, reduced encoder sensitivity, and competitive registration results are stated without any quantitative numbers, error bars, data-split details, baseline specifications, or subject counts for fitting versus test phases, making it impossible to verify whether the data support the central claims.
Authors: We agree that the abstract lacks the necessary quantitative support. In the revised manuscript we will insert specific performance metrics (e.g., Dice scores, landmark errors), standard deviations or error bars, baseline specifications, and explicit subject counts for the fitting versus test phases so that readers can directly assess the strength of the reported improvements. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: the manuscript does not state whether the fitting set used to learn the WPLS projection is disjoint from the test volumes or how many subjects are used for fitting, which is load-bearing for the claim that modality-stable directions generalize to new volumes and unseen modality combinations.
Authors: The fitting set is disjoint from all test volumes; the WPLS projection is learned once on a separate cohort (10 subjects for Abdomen, 20 subjects for HCP) and then applied without further adaptation. We will add these exact subject counts and an explicit statement of disjointness to both the abstract and the evaluation section to make the generalization claim verifiable. revision: yes
-
Referee: [Method (WPLS)] Method section on WPLS projection: because the projection is fitted using external voxel correspondences from a fitting set, the selected directions may encode dataset-specific anatomical or acquisition biases rather than truly invariant features; without explicit held-out validation this risks circularity in the 'training-free reusable feature' positioning.
Authors: We acknowledge the risk of dataset-specific bias. To address it we will add a new held-out validation experiment in the revised manuscript that applies the fitted WPLS directions to completely unseen subjects and modality pairs (including cross-dataset transfer) and reports the resulting correspondence accuracy, thereby demonstrating that the selected directions capture modality-stable anatomical structure rather than fitting-set idiosyncrasies. revision: yes
Circularity Check
No circularity: closed-form WPLS fit on external correspondences yields independent transform-time features
full rationale
The derivation consists of an offline closed-form WPLS projection computed from externally supplied fitting-time voxel correspondences, followed by a linear transform applied unchanged to new volumes. No equation reduces the output to a redefinition of its own fitted parameters, no self-citation chain is load-bearing for the central claim, and no ansatz or uniqueness result is smuggled in. The reusability claim is therefore an empirical generalization statement rather than a definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- WPLS projection weights
axioms (1)
- domain assumption Triplanar features from a frozen 2D ViT capture complementary anatomical information that can be linearly combined into modality-stable volumetric descriptors
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean; IndisputableMonolith/Foundation/AlexanderDuality.leanreality_from_one_distinction; Jcost uniqueness unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VoxCor combines triplanar ViT inference with a compact closed-form weighted partial least squares (WPLS) projection that uses fitting-time voxel correspondences to select modality-stable anatomical directions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A survey of medical image registration.Medical image analysis, 2(1):1–36, 1998
JB Antoine Maintz and Max A Viergever. A survey of medical image registration.Medical image analysis, 2(1):1–36, 1998
1998
-
[2]
Deformable medical image registration: A survey.IEEE transactions on medical imaging, 32(7):1153–1190, 2013
Aristeidis Sotiras, Christos Davatzikos, and Nikos Paragios. Deformable medical image registration: A survey.IEEE transactions on medical imaging, 32(7):1153–1190, 2013
2013
-
[3]
A review of atlas-based segmentation for magnetic resonance brain images.Computer methods and programs in biomedicine, 104(3):e158–e177, 2011
Mariano Cabezas, Arnau Oliver, Xavier Lladó, Jordi Freixenet, and Meritxell Bach Cuadra. A review of atlas-based segmentation for magnetic resonance brain images.Computer methods and programs in biomedicine, 104(3):e158–e177, 2011
2011
-
[4]
Symmetric diffeomorphic image registration with cross-correlation: evaluating automated labeling of elderly and neurodegenerative brain.Medical image analysis, 12(1):26–41, 2008
Brian B Avants, Charles L Epstein, Murray Grossman, and James C Gee. Symmetric diffeomorphic image registration with cross-correlation: evaluating automated labeling of elderly and neurodegenerative brain.Medical image analysis, 12(1):26–41, 2008
2008
-
[5]
Elastix: a toolbox for intensity-based medical image registration.IEEE transactions on medical imaging, 29(1):196–205, 2009
Stefan Klein, Marius Staring, Keelin Murphy, Max A Viergever, and Josien PW Pluim. Elastix: a toolbox for intensity-based medical image registration.IEEE transactions on medical imaging, 29(1):196–205, 2009
2009
-
[6]
Diffeomorphic demons: Efficient non-parametric image registration.NeuroImage, 45(1):S61–S72, 2009
Tom Vercauteren, Xavier Pennec, Aymeric Perchant, and Nicholas Ayache. Diffeomorphic demons: Efficient non-parametric image registration.NeuroImage, 45(1):S61–S72, 2009
2009
-
[7]
A fast diffeomorphic image registration algorithm.Neuroimage, 38(1): 95–113, 2007
John Ashburner. A fast diffeomorphic image registration algorithm.Neuroimage, 38(1): 95–113, 2007
2007
-
[8]
Voxel- morph: a learning framework for deformable medical image registration.IEEE transactions on medical imaging, 38(8):1788–1800, 2019
Guha Balakrishnan, Amy Zhao, Mert R Sabuncu, John Guttag, and Adrian V Dalca. Voxel- morph: a learning framework for deformable medical image registration.IEEE transactions on medical imaging, 38(8):1788–1800, 2019
2019
-
[9]
End-to-end unsupervised deformable image registration with a convolutional neural net- work
Bob D De Vos, Floris F Berendsen, Max A Viergever, Marius Staring, and Ivana Išgum. End-to-end unsupervised deformable image registration with a convolutional neural net- work. InDeep Learning in Medical Image Analysis and Multimodal Learning for Clini- cal Decision Support: Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS ...
2017
-
[10]
Cross-modal attention for multi-modal image registration.Medical Image Analysis, 82:102612, 2022
Xinrui Song, Hanqing Chao, Xuanang Xu, Hengtao Guo, Sheng Xu, Baris Turkbey, Brad- ford J Wood, Thomas Sanford, Ge Wang, and Pingkun Yan. Cross-modal attention for multi-modal image registration.Medical Image Analysis, 82:102612, 2022
2022
-
[11]
Junyu Chen, Yihao Liu, Shuwen Wei, Zhangxing Bian, Shalini Subramanian, Aaron Carass, Jerry L. Prince, and Yong Du. A survey on deep learning in medical image registration: New technologies, uncertainty, evaluation metrics, and beyond.Medical Image Analysis, 100:103385, 2025. ISSN 1361-8415. doi: 10.1016/j.media.2024.103385. URLhttps://www. sciencedirect....
-
[12]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021. URL https:...
2021
-
[13]
Emerging properties in self-supervised vision transformers
MathildeCaron, HugoTouvron, IshanMisra, HervéJégou, JulienMairal, PiotrBojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InPro- ceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021. 27
2021
-
[14]
DINOv2: Learning Robust Visual Features without Supervision
MaximeOquab, TimothéeDarcet, ThéoMoutakanni, HuyVo, MarcSzafraniec, VasilKhali- dov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. DINOv3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Segment anything
AlexanderKirillov, EricMintun, NikhilaRavi, HanziMao, ChloeRolland, LauraGustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015– 4026, 2023
2023
-
[17]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. SAM 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Segment anything in medical images.Nature Communications, 15:654, 2024
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images.Nature Communications, 15:654, 2024
2024
-
[20]
Medsam2: Segment anything in 3d medical images and videos.arXiv preprint arXiv:2504.03600, 2025
Jun Ma, Zongxin Yang, Sumin Kim, Bihui Chen, Mohammed Baharoon, Adibvafa Fallah- pour, Reza Asakereh, Hongwei Lyu, and Bo Wang. MedSAM2: Segment anything in 3d medical images and videos.arXiv preprint arXiv:2504.03600, 2025
-
[21]
Mohammed Baharoon, Waseem Qureshi, Jiahong Ouyang, Yanwu Xu, Kilian Phol, Ab- dulrhman Aljouie, and Wei Peng. Towards general purpose vision foundation models for medical image analysis: An experimental study of dinov2 on radiology benchmarks.arXiv preprint arXiv:2312.02366, 2023
-
[22]
Kerem Cekmeceli, Meva Himmetoglu, Guney I Tombak, Anna Susmelj, Ertunc Erdil, and Ender Konukoglu. Do vision foundation models enhance domain generalization in medical image segmentation?arXiv preprint arXiv:2409.07960, 2024
-
[23]
DINO-Reg: General purpose image encoder for training-free multi-modal deformable medical image registration
Xinrui Song, Xuanang Xu, and Pingkun Yan. DINO-Reg: General purpose image encoder for training-free multi-modal deformable medical image registration. InInternational Con- ference on Medical Image Computing and Computer-Assisted Intervention, pages 608–617. Springer, 2024
2024
-
[24]
Wong, Clinton J
Neel Dey, Benjamin Billot, Hallee E. Wong, Clinton J. Wang, Mengwei Ren, P. Ellen Grant, Adrian V. Dalca, and Polina Golland. Learning general-purpose biomedical vol- ume representations using randomized synthesis. InInternational Conference on Learning Representations, 2025
2025
-
[25]
Totalsegmentator: robust segmentation of 104 anatomic structures in ct images.Radiology: Artificial Intelligence, 5(5), 2023
Jakob Wasserthal, Hanns-Christian Breit, Manfred T Meyer, Maurice Pradella, Daniel Hinck, Alexander W Sauter, Tobias Heye, Daniel T Boll, Joshy Cyriac, Shan Yang, et al. Totalsegmentator: robust segmentation of 104 anatomic structures in ct images.Radiology: Artificial Intelligence, 5(5), 2023
2023
-
[26]
Hanxue Gu, Yaqian Chen, Nicholas Konz, Qihang Li, and Maciej A Mazurowski. Are vision foundation models ready for out-of-the-box medical image registration?arXiv preprint arXiv:2507.11569, 2025. 28
-
[27]
VISTA3D: A unified segmentation foundation model for 3d medical imaging
Yufan He, Pengfei Guo, Yucheng Tang, Andriy Myronenko, Vishwesh Nath, Ziyue Xu, Dong Yang, Can Zhao, Benjamin Simon, Mason Belue, Stephanie Harmon, Baris Turkbey, Daguang Xu, and Wenqi Li. VISTA3D: A unified segmentation foundation model for 3d medical imaging. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[28]
SegVol: Universal and interactive volu- metric medical image segmentation
Yuxin Du, Fan Bai, Tiejun Huang, and Bo Zhao. SegVol: Universal and interactive volu- metric medical image segmentation. InAdvances in Neural Information Processing Systems, 2024
2024
-
[29]
Alessa Hering, Lasse Hansen, Tony C. W. Mok, et al. Learn2reg: Comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning. IEEE Transactions on Medical Imaging, 42(3):697–712, 2023
2023
-
[30]
Van Essen, Stephen M
David C. Van Essen, Stephen M. Smith, Deanna M. Barch, Timothy E. J. Behrens, Essa Yacoub, Kamil Ugurbil, and WU-Minn HCP Consortium. The wu-minn human connectome project: an overview.Neuroimage, 80:62–79, 2013
2013
-
[31]
Jacob A. Wegelin. A survey of Partial Least Squares (PLS) methods, with emphasis on the two-blockcase. TechnicalReportTechnicalReport371, DepartmentofStatistics, University of Washington, 2000
2000
-
[32]
Takoua Jendoubi and Korbinian Strimmer. A whitening approach to probabilistic canonical correlation analysis for omics data integration.BMC Bioinformatics, 20(1):15, 2019. doi: 10.1186/s12859-018-2572-9
-
[33]
Heinrich, Mark Jenkinson, Bartłomiej W
Mattias P. Heinrich, Mark Jenkinson, Bartłomiej W. Papież, Michael Brady, and Julia A. Schnabel. Towards realtime multimodal fusion for image-guided interventions using self- similarities. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2013, volume 8151 ofLecture Notes in Computer Science, pages 187–194. Springer, 2013. doi: 10.1007...
-
[34]
Convex- adam: Self-configuring dual-optimisation-based 3d multitask medical image registration
Hanna Siebert, Christoph Großbröhmer, Lasse Hansen, and Mattias P Heinrich. Convex- adam: Self-configuring dual-optimisation-based 3d multitask medical image registration. IEEE Transactions on Medical Imaging, 2024
2024
-
[35]
Freesurfer.NeuroImage, 62(2):774–781, 2012
Bruce Fischl. Freesurfer.NeuroImage, 62(2):774–781, 2012
2012
-
[36]
xformers: A modu- lar and hackable transformer modelling library.https://github.com/facebookresearch/ xformers, 2022
Benjamin Lefaudeux, Francisco Massa, Diana Liskovich, Wenhan Xiong, Vittorio Caggiano, Sean Naren, Min Xu, Jieru Hu, Marta Tintore, Susan Zhang, Patrick Labatut, Daniel Haziza, Luca Wehrstedt, Jeremy Reizenstein, and Grigory Sizov. xformers: A modu- lar and hackable transformer modelling library.https://github.com/facebookresearch/ xformers, 2022. 29 A Me...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.