Recognition: 2 theorem links
· Lean TheoremSPIN: Structural LLM Planning via Iterative Navigation for Industrial Tasks
Pith reviewed 2026-05-15 05:15 UTC · model grok-4.3
The pith
SPIN wraps LLM planners with DAG validation and prefix execution control to produce shorter, more reliable industrial workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
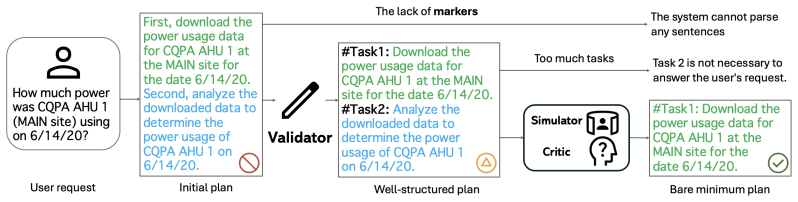
SPIN enforces a strict DAG contract through _validate_plan_text and repair prompting, producing executable plans before downstream execution, and then evaluates DAG prefixes incrementally to stop when the current prefix is sufficient to answer the query.
What carries the argument
Validated Directed Acyclic Graph (DAG) planning with prefix-based execution control, enforced by _validate_plan_text and repair prompting.
Load-bearing premise
That LLM-based validation and repair prompting will consistently produce executable DAG plans without introducing new structural errors or missing invalid cases, and that the LLM can accurately judge when a prefix is sufficient.
What would settle it
Running SPIN on a fresh collection of 261 industrial scenarios where the number of executed tasks stays above 623 or accomplishment falls below 0.706 would show the improvements do not hold.
Figures









read the original abstract
Industrial LLM agent systems often separate planning from execution, yet LLM planners frequently produce structurally invalid or unnecessarily long workflows, leading to brittle failures and avoidable tool and API cost. We propose \texttt{SPIN}, a planning wrapper that combines validated Directed Acyclic Graph (DAG) planning with prefix based execution control. \texttt{SPIN} enforces a strict DAG contract through \texttt{\_validate\_plan\_text} and repair prompting, producing executable plans before downstream execution, and then evaluates DAG prefixes incrementally to stop when the current prefix is sufficient to answer the query. On AssetOpsBench, across 261 scenarios, \texttt{SPIN} reduces executed tasks from 1061 to 623 and improves \emph{Accomplished} from 0.638 to 0.706, while reducing tool calls from 11.81 to 6.82 per run. On MCP Bench, the same wrapper improves planning, grounding, and dependency related scores for both GPT OSS1 and Llama 4 Maverick.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPIN, a planning wrapper for LLM agents in industrial tasks. It combines validated Directed Acyclic Graph (DAG) planning enforced via _validate_plan_text and repair prompting with prefix-based execution control that stops when the current prefix suffices to answer the query. On AssetOpsBench across 261 scenarios, SPIN reduces executed tasks from 1061 to 623, raises Accomplished from 0.638 to 0.706, and cuts tool calls from 11.81 to 6.82 per run. On MCP Bench it improves planning, grounding, and dependency scores for GPT OSS1 and Llama 4 Maverick.
Significance. If the empirical gains are reproducible and attributable to the DAG contract rather than downstream execution artifacts, SPIN would provide a lightweight, practical method for reducing invalid workflows and unnecessary tool invocations in industrial LLM agents. The concrete numerical improvements on named benchmarks constitute the primary evidence; the absence of open code, full prompts, and statistical tests limits how strongly the results can be generalized.
major comments (3)
- [Method description of validation and repair] The core mechanism (_validate_plan_text plus repair prompting) is described as enforcing a strict DAG contract, yet both steps are LLM calls with no deterministic checker for acyclicity, dependency closure, or type consistency. This is load-bearing for the claim that the observed reductions (1061→623 tasks, 11.81→6.82 tool calls) reflect genuine planning improvement rather than downstream failure handling; a modest rate of undetected invalid plans would undermine the interpretation of the AssetOpsBench metrics.
- [Prefix-based execution control] The prefix-sufficiency judgment is likewise an LLM decision with no stated verification or fallback. If this judgment is inaccurate, the reported Accomplished score (0.706) could be inflated by premature termination or by cases where the prefix is incorrectly deemed sufficient; the paper provides no ablation or error analysis on this component.
- [Experimental results] The AssetOpsBench and MCP Bench results report specific numerical deltas but omit baseline implementation details, number of independent runs, statistical significance tests, and the exact prompt templates used for validation/repair. Without these, it is impossible to determine whether the gains are robust or sensitive to prompt engineering.
minor comments (2)
- Define all acronyms (e.g., DAG, MCP) on first use in the abstract and main text.
- Add a short reproducibility statement indicating whether code, prompts, and benchmark splits will be released.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, clarifying the mechanisms, committing to additional analyses and details, and outlining the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: The core mechanism (_validate_plan_text plus repair prompting) is described as enforcing a strict DAG contract, yet both steps are LLM calls with no deterministic checker for acyclicity, dependency closure, or type consistency. This is load-bearing for the claim that the observed reductions (1061→623 tasks, 11.81→6.82 tool calls) reflect genuine planning improvement rather than downstream failure handling; a modest rate of undetected invalid plans would undermine the interpretation of the AssetOpsBench metrics.
Authors: We acknowledge that validation and repair rely on LLM calls guided by structured prompts rather than an external deterministic checker. The prompts explicitly require output in a format that encodes a topological order and closed dependencies, which we use to detect and repair violations. To strengthen the claim, we will add the full validation prompt template, report the observed repair rate across runs (currently ~12% of plans), and include a limitations paragraph discussing residual risk of undetected cycles. These changes will make the interpretation of the task and tool-call reductions more robust. revision: yes
-
Referee: The prefix-sufficiency judgment is likewise an LLM decision with no stated verification or fallback. If this judgment is inaccurate, the reported Accomplished score (0.706) could be inflated by premature termination or by cases where the prefix is incorrectly deemed sufficient; the paper provides no ablation or error analysis on this component.
Authors: We agree that prefix sufficiency is an LLM judgment without explicit verification. In the revision we will add an ablation that compares prefix-based stopping against full-plan execution on the same 261 scenarios, report the frequency of early-stop decisions, and provide a manual error analysis of 50 sampled cases where the judgment was borderline. We will also describe the fallback rule (continue execution on low-confidence sufficiency scores) that is already implemented but was omitted from the original text. revision: yes
-
Referee: The AssetOpsBench and MCP Bench results report specific numerical deltas but omit baseline implementation details, number of independent runs, statistical significance tests, and the exact prompt templates used for validation/repair. Without these, it is impossible to determine whether the gains are robust or sensitive to prompt engineering.
Authors: We will expand the experimental section to include: (i) precise baseline code references and hyper-parameters, (ii) results averaged over five independent runs with standard deviations, (iii) paired t-test p-values confirming statistical significance of the reported deltas, and (iv) all prompt templates in a new appendix. We further commit to releasing the full codebase and prompts publicly upon acceptance, directly addressing the reproducibility concern. revision: yes
Circularity Check
No circularity: empirical results on external benchmarks
full rationale
The paper describes SPIN as an LLM wrapper enforcing DAG plans via _validate_plan_text and repair prompting, then reports direct empirical measurements of reduced task executions (1061 to 623), improved Accomplished scores (0.638 to 0.706), and lower tool calls (11.81 to 6.82) on AssetOpsBench across 261 scenarios plus MCP Bench scores. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the provided text that would reduce any claimed result to its own inputs by construction. The derivation chain consists of a proposed method followed by independent benchmark evaluation, making the findings self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can be prompted to validate and repair plans into valid DAGs without introducing new errors
- domain assumption LLMs can accurately determine when a plan prefix is sufficient to answer the query
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean (distinction-to-reality forcing)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
simulator S predicts the candidate outcome ... critic C returns ... can_answer_now flag
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Automating thought of search: A journey towards soundness and completeness, 2024
Daniel Cao, Michael Katz, Harsha Kokel, Kavitha Srinivas, and Shirin Sohrabi. Automating thought of search: A journey towards soundness and completeness, 2024. URL https:// arxiv.org/abs/2408.11326
-
[2]
Edward Y . Chang and Longling Geng. Sagallm: Context management, validation, and transac- tion guarantees for multi-agent llm planning.Proceedings of the VLDB Endowment, 18(12): 4874–4886, 2025. doi: 10.14778/3750601.3750611. URL https://www.vldb.org/pvldb/ vol18/p4874-chang.pdf
-
[3]
Assetopsbench – codabench competition
CodaBench. Assetopsbench – codabench competition. https://www.codabench.org/ competitions/10206/, 2025. Accessed: 2026-01-04
work page 2025
-
[4]
Grammar-constrained decoding for structured NLP tasks without finetuning
Saibo Geng, Martin Josifoski, Maxime Peyrard, and Robert West. Grammar-constrained decoding for structured NLP tasks without finetuning. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10932–10952. Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.emnlp-main.674. URL https: //aclantholog...
-
[5]
Saibo Geng, Hudson Cooper, Michał Moskal, Samuel Jenkins, Julian Berman, Nathan Ranchin, Robert West, Eric Horvitz, and Harsha Nori. Jsonschemabench: A rigorous benchmark of structured outputs for language models, 2025. URLhttps://arxiv.org/abs/2501.10868
-
[6]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large language models can self-correct with tool-interactive critiquing, 2024. URLhttps://arxiv.org/abs/2305.11738. ICLR 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Siegel, Nitya Nadgir, and Arvind Narayanan
Sayash Kapoor, Benedikt Ströbl, Zachary S. Siegel, Nitya Nadgir, and Arvind Narayanan. Ai agents that matter, 2024. URLhttps://arxiv.org/abs/2407.01502
-
[8]
Thought of search: Planning with language models through the lens of efficiency
Michael Katz, Harsha Kokel, Kavitha Srinivas, and Shirin Sohrabi. Thought of search: Planning with language models through the lens of efficiency. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2024. URL https://proceedings.neurips.cc/paper_files/ paper/2024/hash/fa080fe0f218871faec1d8ba20e491d5-Abstract-Conference.html
work page 2024
-
[9]
Liping Liu, Chunhong Zhang, Likang Wu, Chuang Zhao, Zheng Hu, Ming He, and Jianping Fan. Instruct-of-reflection: Enhancing large language models iterative reflection capabili- ties via dynamic-meta instruction. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Asso- ciatio...
-
[10]
Learning to generate structured output with schema reinforcement learning
Yaxi Lu, Haolun Li, Xin Cong, Zhong Zhang, Yesai Wu, Yankai Lin, Zhiyuan Liu, Fangming Liu, and Maosong Sun. Learning to generate structured output with schema reinforcement learning. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguis- ...
-
[11]
Introducing structured outputs in the api, August 2024
OpenAI. Introducing structured outputs in the api, August 2024. URL https://openai.com/ index/introducing-structured-outputs-in-the-api/. Accessed: 2025-12-28
work page 2024
-
[12]
Dhaval Patel, Shuxin Lin, James Rayfield, Nianjun Zhou, Roman Vaculin, Natalia Martinez, Fearghal O’donncha, and Jayant Kalagnanam. Assetopsbench: Benchmarking ai agents for task automation in industrial asset operations and maintenance, 2025. URL https://arxiv.org/ abs/2506.03828. 10
-
[13]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R. Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. InAdvances in Neural In- formation Processing Systems (NeurIPS), 2023. URL https://openreview.net/forum?id= vAElhFcKW6
work page 2023
-
[14]
Joykirat Singh, Raghav Magazine, Yash Pandya, and Akshay Nambi. Agentic reasoning and tool integration for llms via reinforcement learning, 2025. URL https://arxiv.org/abs/ 2505.01441. MSR-TR-042025-V1
-
[15]
On the self-verification limitations of large language models on reasoning and planning tasks
Kaya Stechly, Karthik Valmeekam, and Subbarao Kambhampati. On the self-verification limitations of large language models on reasoning and planning tasks. InInternational Con- ference on Learning Representations (ICLR), 2025. doi: 10.48550/arXiv.2402.08115. URL https://openreview.net/forum?id=4O0v4s3IzY. Poster
-
[16]
MCP-bench: Benchmarking tool-using LLM agents with complex real-world tasks via MCP servers
Zhenting Wang, Qi Chang, Hemani Patel, Shashank Biju, Cheng-En Wu, Quan Liu, Aolin Ding, Alireza Rezazadeh, Ankit Shah, Yujia Bao, and Eugene Siow. MCP-bench: Benchmarking tool-using LLM agents with complex real-world tasks via MCP servers. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=fe8mzHwMxN
work page 2026
-
[17]
Rewoo: Decoupling reasoning from observations for efficient augmented language models,
Binfeng Xu, Zhiyuan Peng, Bowen Lei, Subhabrata Mukherjee, Yuchen Liu, and Dongkuan Xu. Rewoo: Decoupling reasoning from observations for efficient augmented language models,
- [18]
-
[19]
Zhe Yang, Yichang Zhang, Yudong Wang, Ziyao Xu, Junyang Lin, and Zhifang Sui. Confidence v.s. critique: A decomposition of self-correction capability for LLMs. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
-
[20]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023. URL https://openreview.net/forum?id=WE_ vluYUL-X
work page 2023
-
[21]
/benchmark/cods_track1/track1_result/trajectory
Yifan Zhang, Giridhar Ganapavarapu, Srideepika Jayaraman, Bhavna Agrawal, Dhaval Patel, and Achille Fokoue. Spiral: Symbolic llm planning via grounded and reflective search, 2025. URLhttps://arxiv.org/abs/2512.23167. A Reproducibility Details A.1 Experiment Regeneration Deterministic table recomputation from saved run artifacts.All tables reported in this...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.