Recognition: no theorem link
Unsteady Metrics and Benchmarking Cultures of AI Model Builders
Pith reviewed 2026-05-15 04:51 UTC · model grok-4.3
The pith
AI builders select benchmarks to fit marketing narratives rather than enable consistent scientific comparison.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
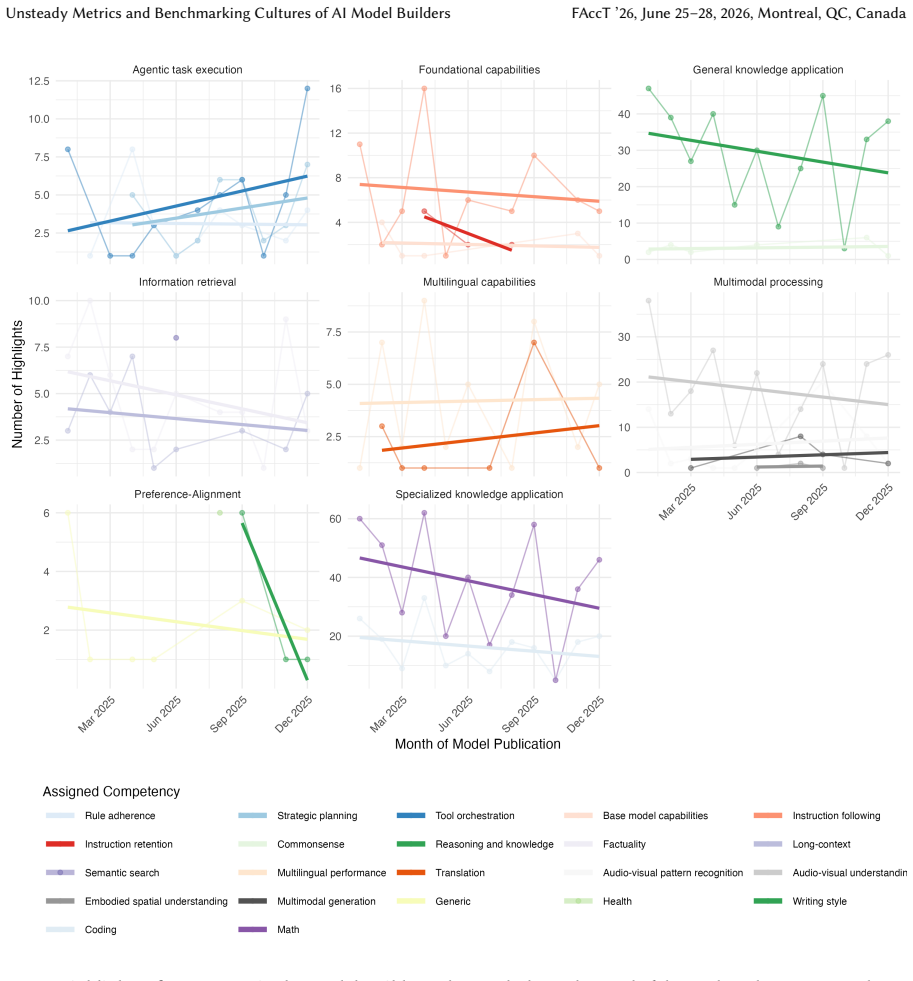
Highlighted benchmarks in 2025 model releases form a fragmented set where most tests are used by a single builder, the same test receives different competency attributions from different companies, and many results are framed as indicators of AGI progress even when the underlying tasks remain limited to specific STEM domains.
What carries the argument
The Benchmarking-Cultures-25 dataset of 231 highlighted benchmarks paired with a unified taxonomy that converts each builder's terminology into common categories of measured signals.
If this is right
- Direct head-to-head comparisons of model capabilities become unreliable because few benchmarks are shared.
- Progress claims toward general intelligence rest on loosely defined categories that mostly test math and science tasks.
- Reproducible scientific tracking of model improvement is hindered when selection favors narrative fit over standardization.
- Public understanding of state-of-the-art performance depends on whichever tests each company chooses to emphasize.
Where Pith is reading between the lines
- Regulators seeking standardized AI assessment may need to create independent benchmark suites outside company control.
- The same selection logic could appear in other fast-moving technical fields where public perception drives investment.
- Long-term research agendas may shift toward tasks that resist easy narrative framing if external pressure for comparability grows.
Load-bearing premise
The 139 releases and 231 highlighted benchmarks chosen by the 11 builders capture the main evaluation practices used across the AI industry in 2025.
What would settle it
A complete census of 2025 model releases showing that most builders share and interpret the same small set of benchmarks in the same way would contradict the reported fragmentation and narrative flexibility.
Figures










read the original abstract
The primary way to establish and compare competencies in foundation and generative AI models has shifted from peer-reviewed literature to press releases and company blog posts, where model builders highlight results on selected benchmarks. These artifacts now largely define the state of the art for researchers and the public. Despite their prominence, which benchmarks model builders choose to highlight, and what they communicate through this selection, is underexamined. To investigate, we introduce and open-source Benchmarking-Cultures-25, a dataset of 231 benchmarks highlighted across 139 model releases in 2025 from 11 major AI builders, alongside an interactive tool to explore the data. Our analysis reveals a fragmented evaluation landscape with limited cross-model comparability: 63.2% of highlighted benchmarks are used by a single builder, and 38.5% appear in just one release. Few achieve widespread use (e.g., GPQA Diamond, LiveCodeBench, AIME 2025). Moreover, benchmarks are attributed different competencies by different builders, depending on their narrative. To disentangle these conflicting presentations, we develop a unified taxonomy mapping diverging terminology to a shared framework of measured signals based on what benchmark authors claim to measure. "General knowledge application" is the second most popular, yet vaguely defined, category. Qualitative analysis shows many such benchmarks deemphasize construct validity, instead framing results as indicators of progress toward AGI. Their authors claim to measure knowledge or reasoning broadly, yet mostly evaluate STEM subjects (especially math). We argue that highlighted benchmarks function less as standardized measurement tools and more as flexible narrative devices prioritizing market positioning over scientific evaluation. Data: https://hf.co/datasets/matybohacek/benchmarking-cultures-25; tool: https://bench-cultures.net.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the open Benchmarking-Cultures-25 dataset of 231 benchmarks highlighted across 139 model releases from 11 major AI builders in 2025. It reports quantitative patterns of fragmentation (63.2% single-builder benchmarks, 38.5% single-release usage) and inconsistent competency attributions, develops a unified taxonomy mapping author-stated signals, and qualitatively argues that highlighted benchmarks operate primarily as flexible narrative devices for market positioning rather than standardized scientific measurement tools, with many deemphasizing construct validity in favor of AGI-progress framing.
Significance. If the core observations hold, the work supplies a reproducible, open dataset and taxonomy that directly quantifies the lack of cross-model comparability in current AI evaluation practices. The direct counts from the assembled releases provide a solid descriptive foundation, and the interpretive framing offers a useful lens for metascience discussions of how benchmarks shape public and research perceptions of progress.
major comments (2)
- [§4] §4 (Qualitative analysis): The central claim that benchmarks function as narrative devices prioritizing market positioning rests on interpretive reading of author statements and framing; the manuscript does not report a systematic coding protocol, inter-rater reliability, or explicit decision rules for classifying 'AGI narrative' emphasis versus construct-validity focus, which weakens the load-bearing interpretive step from the quantitative fragmentation statistics.
- [§2] §2 (Data collection): The sample is restricted to 11 major builders and 139 releases; while the counts are internally consistent, the paper does not detail selection criteria or compare against a broader population of releases (e.g., smaller labs or open-source models), leaving the generalizability of the 'dominant evaluation practices' claim under-supported for the industry-wide conclusion.
minor comments (2)
- [Table 1] Table 1 or equivalent: the taxonomy categories (e.g., 'general knowledge application') would benefit from one or two concrete benchmark examples per category to illustrate how conflicting attributions were resolved.
- [Abstract / §3] The interactive tool at bench-cultures.net is referenced but the manuscript lacks a brief description of key exploratory features or example queries that readers can use to reproduce the reported statistics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below, indicating the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Qualitative analysis): The central claim that benchmarks function as narrative devices prioritizing market positioning rests on interpretive reading of author statements and framing; the manuscript does not report a systematic coding protocol, inter-rater reliability, or explicit decision rules for classifying 'AGI narrative' emphasis versus construct-validity focus, which weakens the load-bearing interpretive step from the quantitative fragmentation statistics.
Authors: We agree that greater methodological transparency would strengthen the qualitative section. The interpretations draw directly from quoted statements in the model releases, but we acknowledge the absence of a documented protocol. In the revised manuscript we will insert a new subsection in §4 that (a) lists the explicit decision rules used to flag AGI-progress framing versus construct-validity emphasis, (b) provides representative examples of each category and borderline cases, and (c) describes the author-led review process used to resolve disagreements. While we will not retroactively compute inter-rater reliability statistics, the added documentation will make the interpretive step reproducible and address the concern without changing the substantive claims. revision: yes
-
Referee: [§2] §2 (Data collection): The sample is restricted to 11 major builders and 139 releases; while the counts are internally consistent, the paper does not detail selection criteria or compare against a broader population of releases (e.g., smaller labs or open-source models), leaving the generalizability of the 'dominant evaluation practices' claim under-supported for the industry-wide conclusion.
Authors: The referee is correct that explicit selection criteria were not stated. We chose the 11 builders because they account for the releases that most directly shape public discourse and academic citations; however, this rationale should be documented. In revision we will (a) list the precise inclusion rule (builders that released at least one foundation or generative model in 2025 and issued public benchmark-highlighting materials), (b) name the 11 builders, and (c) add a limitations paragraph noting that practices among smaller labs or purely open-source projects may differ and that our conclusions apply specifically to the dominant industry actors. We will not expand the dataset to include those additional actors, as that would require a separate study. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's central claims derive from direct empirical counts (63.2% single-builder benchmarks, 38.5% single-release usage) and a taxonomy explicitly grounded in benchmark authors' own stated claims about measured signals. No equations, fitted parameters, predictions, or self-citations appear in the derivation chain that reduce findings to inputs by construction. The dataset Benchmarking-Cultures-25 is independently assembled from public releases, and the narrative-device interpretation follows from observable patterns without hidden reductions or load-bearing self-references.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Press releases and company blog posts constitute the primary artifacts that now define the state of the art for foundation-model evaluation.
- domain assumption The 139 releases from 11 major builders are representative of current benchmarking culture.
Reference graph
Works this paper leans on
-
[1]
Mohamed Abdalla and Moustafa Abdalla. 2021. The Grey Hoodie Project: Big Tobacco, Big Tech, and the Threat on Academic Integrity. InProceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society(2021-07-21). 287–297. arXiv:2009.13676 [cs] doi:10.1145/3461702.3462563
-
[2]
Norah Alzahrani, Hisham Alyahya, Yazeed Alnumay, Sultan Alrashed, Shaykhah Alsubaie, Yousef Almushayqih, Faisal Mirza, Nouf Alotaibi, Nora Al-Twairesh, Areeb Alowisheq, et al. 2024. When benchmarks are targets: Revealing the sensitivity of large language model leaderboards. InProceedings of the 62nd Annual Meeting of the Association for Computational Ling...
work page 2024
-
[3]
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. 2016. Concrete Problems in AI Safety. arXiv:1606.06565 [cs] doi:10.48550/arXiv.1606.06565
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1606.06565 2016
-
[4]
Anthropic. 2025. Claude 3.7 Sonnet System Card
work page 2025
-
[5]
Andrew M Bean, Ryan Othniel Kearns, Angelika Romanou, Franziska Sofia Hafner, Harry Mayne, Jan Batzner, Negar Foroutan, Chris Schmitz, Karolina Korgul, Hunar Batra, et al. 2025. Measuring what Matters: Construct Validity in Large Language Model Benchmarks. arXiv preprint arXiv:2511.04703(2025)
-
[6]
Borhane Blili-Hamelin, Christopher Graziul, Leif Hancox-Li, Hananel Hazan, El-Mahdi El-Mhamdi, Avijit Ghosh, Katherine A Heller, Jacob Metcalf, Fabricio Murai, Eryk Salvaggio, et al . [n. d.]. Position: Stop treating AGI as the north-star goal of AI research. In Forty-second International Conference on Machine Learning Position Paper Track
- [7]
-
[8]
Rishi Bommasani. 2021. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [9]
-
[10]
Rishi Bommasani, Percy Liang, and Tony Lee. 2023. Holistic evaluation of language models.Annals of the New York Academy of Sciences 1525, 1 (2023), 140–146
work page 2023
-
[11]
Samuel Bowman and George Dahl. 2021. What will it take to fix benchmarking in natural language understanding?. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 4843–4855
work page 2021
-
[12]
Alexander Campolo. 2025. State-of-the-Art: The Temporal Order of Benchmarking Culture.Digital Society4, 2 (2025), 35
work page 2025
-
[13]
María Victoria Carro, Denise Alejandra Mester, Francisca Gauna Selasco, Luca Nicolás Forziati Gangi, Matheo Sandleris Musa, Lola Ramos Pereyra, Mario Leiva, Juan Gustavo Corvalan, María Vanina Martinez, and Gerardo Simari. 2025. A Conceptual Framework for AI Capability Evaluations.arXiv preprint arXiv:2506.18213(2025)
-
[14]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. 2024. A survey on evaluation of large language models.ACM transactions on intelligent systems and technology15, 3 (2024), 1–45
work page 2024
-
[15]
Simin Chen, Yiming Chen, Zexin Li, Yifan Jiang, Zhongwei Wan, Yixin He, Dezhi Ran, Tianle Gu, Haizhou Li, Tao Xie, et al . 2025. Benchmarking large language models under data contamination: A survey from static to dynamic evaluation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 10091–10109
work page 2025
- [16]
-
[17]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. 2024. Chatbot arena: An open platform for evaluating llms by human preference. InForty-first International Conference on Machine Learning
work page 2024
-
[18]
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, and Arman Cohan. 2024. Investigating data contamination in modern benchmarks for large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 8706–8719
work page 2024
-
[19]
Paul J. DiMaggio and Walter W. Powell. 1983. The Iron Cage Revisited: Institutional Isomorphism and Collective Rationality in Organizational Fields. 48, 2 (1983), 147–160. jstor:2095101 doi:10.2307/2095101
- [20]
-
[21]
Maria Eriksson, Erasmo Purificato, Arman Noroozian, Joao Vinagre, Guillaume Chaslot, Emilia Gomez, and David Fernandez-Llorca
- [22]
- [23]
- [24]
-
[25]
Aryo Pradipta Gema, Joshua Ong Jun Leang, Giwon Hong, Alessio Devoto, Alberto Carlo Maria Mancino, Rohit Saxena, Xuanli He, Yu Zhao, Xiaotang Du, Mohammad Reza Ghasemi Madani, et al. 2025. Are we done with mmlu?. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Tec...
work page 2025
-
[26]
Charles AE Goodhart. 1984. Problems of monetary management: the UK experience. InMonetary theory and practice: The UK experience. Springer, 91–121
work page 1984
- [27]
-
[28]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring Massive Multitask Language Understanding. arXiv:2009.03300 [cs] doi:10.48550/arXiv.2009.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.03300 2020
-
[29]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica
-
[30]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. doi:10.48550/ARXIV.2403.07974
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.07974
- [31]
-
[32]
Shaleen Khanal, Hongzhou Zhang, and Araz Taeihagh. 2025. Why and How Is the Power of Big Tech Increasing in the Policy Process? The Case of Generative AI. 44, 1 (2025), 52–69. doi:10.1093/polsoc/puae012
-
[33]
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, et al. 2021. Dynabench: Rethinking benchmarking in NLP. InProceedings of the 2021 conference of the North American chapter of the Association for Computational Linguistics: human language technologies. 4110–4124
work page 2021
- [34]
-
[35]
Md Tahmid Rahman Laskar, Sawsan Alqahtani, M Saiful Bari, Mizanur Rahman, Mohammad Abdullah Matin Khan, Haidar Khan, Israt Jahan, Amran Bhuiyan, Chee Wei Tan, Md Rizwan Parvez, et al. 2024. A systematic survey and critical review on evaluating large language models: Challenges, limitations, and recommendations.arXiv preprint arXiv:2407.04069(2024)
- [36]
-
[37]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. 2022. Holistic evaluation of language models.arXiv preprint arXiv:2211.09110(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Thomas Liao, Rohan Taori, Inioluwa Deborah Raji, and Ludwig Schmidt. 2021. Are we learning yet? a meta review of evaluation failures across machine learning. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
work page 2021
-
[39]
High Temperature Confinement in SU(N) Gauge Theories
João C. Magalhães and Rik Smit. 2026. Less Hype, More Drama: Open-Ended Technological Inevitability in Journalistic Discourses About AI in the US, The Netherlands, and Brazil. 14, 2 (2026), 323–340. doi:10.1080/21670811.2025.2522281
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/21670811.2025.2522281 2026
- [40]
-
[41]
Meredith Ringel Morris, Jascha Sohl-dickstein, Noah Fiedel, Tris Warkentin, Allan Dafoe, Aleksandra Faust, Clement Farabet, and Shane Legg. 2024. Levels of AGI for Operationalizing Progress on the Path to AGI. arXiv:2311.02462 [cs] doi:10.48550/arXiv.2311.02462
-
[42]
Shiwen Ni, Xiangtao Kong, Chengming Li, Xiping Hu, Ruifeng Xu, Jia Zhu, and Min Yang. 2025. Training on the benchmark is not all you need. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 24948–24956
work page 2025
-
[43]
2024.How News Coverage, Often Uncritical, Helps Build up the AI Hype
Rasmus Kleis Nielsen. 2024.How News Coverage, Often Uncritical, Helps Build up the AI Hype. http://reutersinstitute.politics.ox.ac.uk/ news/how-news-coverage-often-uncritical-helps-build-ai-hype
work page 2024
-
[44]
OpenAI. 2023. GPT-4 Research Preview: Capabilities and Limitations
work page 2023
-
[45]
OpenAI. 2023. GPT-4 System Card. (2023)
work page 2023
-
[46]
OpenAI. 2024. OpenAI o1 System Card
work page 2024
-
[47]
Yonatan Oren, Nicole Meister, Niladri S Chatterji, Faisal Ladhak, and Tatsunori Hashimoto. 2023. Proving test set contamination in black-box language models. InThe Twelfth International Conference on Learning Representations
work page 2023
-
[48]
Simon Ott, Adriano Barbosa-Silva, Kathrin Blagec, Jan Brauner, and Matthias Samwald. 2022. Mapping global dynamics of benchmark creation and saturation in artificial intelligence.Nature Communications13, 1 (2022), 6793
work page 2022
-
[49]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, Michael Choi, Anish Agrawal, Arnav Chopra, Adam Khoja, Ryan Kim, Richard Ren, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, Dmitry Dodonov, Tung Nguyen, Jaeho Lee, Daron Anderson, Mikhail Doroshenko, Alun Cennyth Stokes, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.14249 2026
- [50]
-
[51]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2023. GPQA: A Graduate-Level Google-Proof Q&A Benchmark. arXiv:2311.12022 [cs] doi:10.48550/arXiv.2311.12022
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.12022 2023
-
[52]
Kevin Roose. 2025. When A.I. Passes This Test, Look Out. https://www.nytimes.com/2025/01/23/technology/ai-test-humanitys-last- exam.html
work page 2025
- [53]
-
[54]
David Sculley, Jasper Snoek, Alex Wiltschko, and Ali Rahimi. 2018. Winner’s curse? On pace, progress, and empirical rigor. (2018). https://openreview.net/forum?id=rJWF0Fywf
work page 2018
-
[55]
Harald Semmelrock, Tony Ross-Hellauer, Simone Kopeinik, Dieter Theiler, Armin Haberl, Stefan Thalmann, and Dominik Kowald. 2025. Reproducibility in machine-learning-based research: Overview, barriers, and drivers.AI Magazine46, 2 (2025), e70002
work page 2025
-
[56]
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.Transactions on machine learning research(2023)
work page 2023
-
[57]
Marilyn Strathern. 1997. ‘Improving ratings’: audit in the British University system.European review5, 3 (1997), 305–321
work page 1997
-
[58]
Savannah Thais. 2024. Misrepresented technological solutions in imagined futures: The origins and dangers of ai hype in the research community. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 7. 1455–1465
work page 2024
- [59]
-
[60]
Angelina Wang, Aaron Hertzmann, and Olga Russakovsky. 2024. Benchmark suites instead of leaderboards for evaluating AI fairness. Patterns5, 11 (2024)
work page 2024
-
[61]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. 2024. MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark. arXiv:2406.01574 [cs] doi:10.48550/arXiv.2406.01574
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.01574 2024
- [62]
-
[63]
Andrew White. 2025. About 30% of Humanity’s Last Exam chemistry/biology answers are likely wrong. https://www.futurehouse.org/ research-announcements/hle-exam
work page 2025
- [64]
- [65]
-
[66]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. 2024. MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark f...
work page internal anchor Pith review doi:10.48550/arxiv.2311.16502 2024
-
[67]
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, William Song, Tiffany Zhao, Pranav Raja, Charlotte Zhuang, Dylan Slack, et al. 2024. A careful examination of large language model performance on grade school arithmetic.Advances in Neural Information Processing Systems37 (2024), 46819–46836
work page 2024
- [68]
-
[69]
Kyrie Zhixuan Zhou, Justin Eric Chen, Xiang Zheng, Yaoyao Qian, Yunpeng Xiao, and Kai Shu. 2025. "Everyone Else Does It": The Rise of Preprinting Culture in Computing Disciplines.arXiv preprint arXiv:2511.04081(2025). Unsteady Metrics and Benchmarking Cultures of AI Model Builders FAccT ’26, June 25–28, 2026, Montreal, QC, Canada ABenchmarking-Cultures-25...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.