Recognition: no theorem link
Cattle Trade: A Multi-Agent Benchmark for LLM Bluffing, Bidding, and Bargaining
Pith reviewed 2026-05-15 01:50 UTC · model grok-4.3
The pith
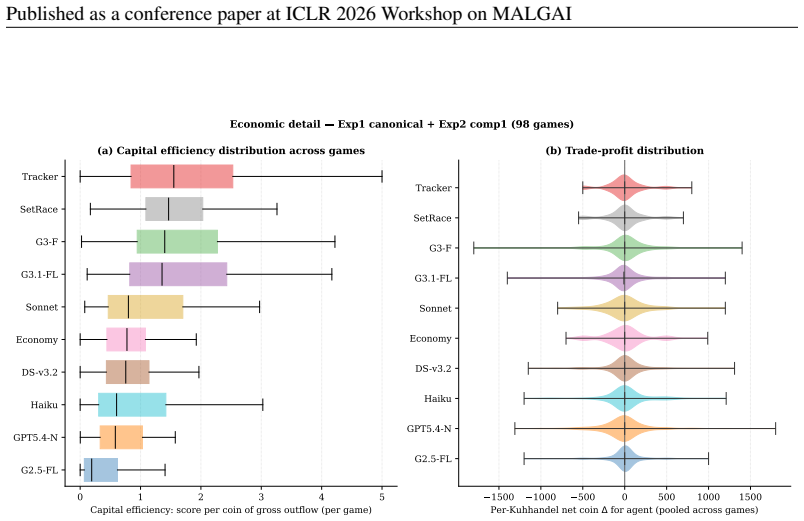
In the Cattle Trade benchmark, strategic coherence like spending efficiency and adaptive bidding predicts rank better than spending volume.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cattle Trade integrates auctions, trade challenges, bargaining, and bluffing into a single long-horizon multi-agent game with imperfect information and resource constraints. Evaluations across seven LLMs and three deterministic code agents in 242 games show that spending efficiency, resource discipline, and phase-adaptive bidding correlate more strongly with rank than spending volume or individual subskills. Two heuristic code agents rank higher than most LLMs, while behavioural analysis reveals LLM failure modes including overbidding, self-bidding, bankrupt trade challenge initiation, and limited opponent-state adaptation.
What carries the argument
The integrated Cattle Trade game mechanics that require agents to deploy bidding, bargaining, bluffing, and resource management jointly over many turns in an adversarial setting.
Load-bearing premise
The assumption that results from this specific Cattle Trade game design reflect broader agentic competence in strategic reasoning under imperfect information instead of being due to the particular game rules or turn structure.
What would settle it
Testing the same agents in a modified version of the game with different resource mechanics or fewer turns and observing whether the ranking by strategic coherence metrics stays the same.
Figures









read the original abstract
We introduce \textsc{Cattle Trade, a multi-agent benchmark for evaluating large language models (LLMs) as agents in strategic reasoning under imperfect information, adversarial interaction, and resource constraints. The benchmark combines auctions, hidden-offer trade challenges (TCs), bargaining, bluffing, opponent modeling, and resource allocation within a single long-horizon game lasting 50--60 turns. Unlike prior agent benchmarks that test these abilities in isolation, \textsc{Cattle Trade} evaluates whether agents integrate them across a competitive, multi-agent economic game with conflicting incentives. The benchmark logs every bid, TC offer, counteroffer, and card selection, enabling behavioural analysis beyond final scores or win rates. We evaluate seven cost-efficient language models and three deterministic code agents across 242 games. Strategic coherence, in particular spending efficiency, resource discipline, and phase-adaptive bidding, is associated with rank more strongly than spending volume or any single subskill. Two heuristic code agents outperform most tested LLMs, and behavioural traces surface recurring LLM failure modes including overbidding, self-bidding, bankrupt TC initiation, and weak opponent-state adaptation. Evaluating agentic competence requires benchmarks that test the joint deployment of multiple capabilities in multi-agent environments with conflicting incentives, uncertainty, and economic dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Cattle Trade, a multi-agent benchmark for evaluating LLMs in integrated strategic reasoning under imperfect information. The game combines auctions, hidden-offer trade challenges, bargaining, bluffing, and resource allocation over 50-60 turns. Across 242 games with seven LLMs and three deterministic code agents, the paper reports that metrics of strategic coherence (spending efficiency, resource discipline, phase-adaptive bidding) correlate more strongly with final rank than spending volume or isolated subskills, that two heuristic code agents outperform most LLMs, and that LLMs exhibit recurring failure modes such as overbidding and weak opponent adaptation.
Significance. If the central associations hold under additional statistical controls, the benchmark offers a valuable integrated testbed for multi-agent economic reasoning that goes beyond isolated capability evaluations. The provision of full behavioral logs (bids, offers, card selections) is a strength that enables post-hoc analysis of failure modes. The finding that simple heuristics can outperform current LLMs in this setting highlights a concrete gap in current agentic systems.
major comments (3)
- [Results] Results section (behavioral metrics analysis): the claim that spending efficiency, resource discipline, and phase-adaptive bidding are associated with rank more strongly than spending volume lacks reported correlation coefficients, p-values, confidence intervals, or controls for multiple comparisons and game-to-game variance, undermining the strength of the central empirical claim.
- [Evaluation] Evaluation setup (242 games across 10 agents): no details are provided on how game parameters (card distributions, payoff matrices, turn limits) were selected, nor are sensitivity tests or ablations on rule variations reported; this leaves open the possibility that observed rank associations and code-agent superiority are artifacts of the specific 50-60 turn mechanics rather than generalizable strategic competence.
- [Abstract and Evaluation] Abstract and §4 (agent comparisons): the statement that two heuristic code agents outperform most tested LLMs is presented without per-agent win-rate tables, variance across repeated matches, or statistical tests comparing LLM vs. heuristic performance distributions.
minor comments (3)
- [Methods] Clarify the precise definitions and formulas used to compute spending efficiency and resource discipline in the methods or appendix.
- [Evaluation] Add a table summarizing the seven LLMs (model names, sizes, temperatures) and the three code agents' exact heuristics.
- [Results] Ensure all figures showing behavioral traces include axis labels, legends, and sample sizes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify areas where the empirical presentation can be strengthened with additional quantitative detail and robustness checks. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Results] Results section (behavioral metrics analysis): the claim that spending efficiency, resource discipline, and phase-adaptive bidding are associated with rank more strongly than spending volume lacks reported correlation coefficients, p-values, confidence intervals, or controls for multiple comparisons and game-to-game variance, undermining the strength of the central empirical claim.
Authors: We agree that the current presentation of the association between strategic coherence metrics and rank is qualitative and would benefit from explicit statistics. In the revised manuscript we will add Pearson and Spearman correlation coefficients (with 95% confidence intervals) between each behavioral metric and final rank, report p-values, apply Bonferroni or FDR correction for multiple comparisons, and include a mixed-effects regression controlling for game-to-game variance as a random effect. These additions will be placed in a new subsection of the Results. revision: yes
-
Referee: [Evaluation] Evaluation setup (242 games across 10 agents): no details are provided on how game parameters (card distributions, payoff matrices, turn limits) were selected, nor are sensitivity tests or ablations on rule variations reported; this leaves open the possibility that observed rank associations and code-agent superiority are artifacts of the specific 50-60 turn mechanics rather than generalizable strategic competence.
Authors: The game parameters were selected to create a balanced multi-stage economic environment that integrates auctions, bargaining, and resource constraints while remaining computationally tractable for LLM agents; card distributions follow a uniform random draw with fixed total value, payoff matrices are derived from standard Vickrey and Nash bargaining solutions, and the 50-60 turn horizon was chosen to allow multiple phases of play without excessive context length. In the revision we will add an explicit subsection detailing these choices with references to the underlying economic models. We will also report sensitivity results for two key variations (turn limit reduced to 30 and payoff scaling factor of 0.5) to demonstrate that the relative ordering of agents is robust. revision: yes
-
Referee: [Abstract and Evaluation] Abstract and §4 (agent comparisons): the statement that two heuristic code agents outperform most tested LLMs is presented without per-agent win-rate tables, variance across repeated matches, or statistical tests comparing LLM vs. heuristic performance distributions.
Authors: We acknowledge that the current text relies on aggregate statements without granular tables or inferential statistics. The revised version will include a new table in §4 showing per-agent mean rank, win rate, and standard deviation across the 242 games, broken down by LLM versus heuristic category. We will add Mann-Whitney U tests (with effect sizes) comparing the full performance distributions of the two best heuristics against the LLM group, together with a note on the number of repeated matches per agent pair. revision: yes
Circularity Check
No circularity: empirical benchmark with direct observational reporting
full rationale
The paper introduces a new multi-agent game benchmark and reports empirical results from running 242 games with 10 agents. No mathematical derivations, equations, parameter fitting, or predictive claims appear in the text. Behavioral metrics are computed directly from logged actions and correlated with observed ranks; these associations are presented as findings rather than as outputs of any model that was fitted to the same data. No self-citations are used to justify uniqueness theorems or ansatzes. The analysis is therefore self-contained and does not reduce any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-agent economic games with imperfect information can reveal integrated strategic capabilities in AI agents.
Reference graph
Works this paper leans on
-
[1]
Herbrich, Ralf and Minka, Tom and Graepel, Thore , booktitle=. TrueSkill: A. 2006 , publisher=
work page 2006
-
[2]
Silver, David and Schrittwieser, Julian and Simonyan, Karen and Antonoglou, Ioannis and Huang, Aja and Guez, Arthur and Hubert, Thomas and Baker, Lucas and Lai, Matthew and Bolton, Adrian and others , journal=. Mastering the Game of. 2017 , publisher=
work page 2017
-
[3]
Brown, Noam and Sandholm, Tuomas , journal=. Superhuman. 2019 , publisher=
work page 2019
-
[4]
Human-Level Play in the Game of
Bakhtin, Anton and Brown, Noam and Dinan, Emily and Farina, Gabriele and Flaherty, Colin and Fried, Daniel and Goff, Andrew and Gray, Jonathan and Hu, Hengyuan and Jacob, Athul Paul and others , journal=. Human-Level Play in the Game of. 2022 , publisher=
work page 2022
-
[5]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[6]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Transactions on Machine Learning Research , year=
Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models , author=. Transactions on Machine Learning Research , year=
-
[9]
Suzgun, Mirac and Scales, Nathan and Sch. Challenging. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
work page 2023
-
[10]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and others , booktitle=
-
[11]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P and others , booktitle=. Judging
-
[12]
Duan, Jinhao and Zhang, Renming and Diffenderfer, James and Kailkhura, Bhavya and Sun, Lichao and Stinis, Elias and Stamoulis, Dimitrios , journal=
-
[13]
From Text to Tactic: Evaluating
Light, Jonathan and Cai, Min and Shen, Sheng and Hu, Ziniu , journal=. From Text to Tactic: Evaluating
-
[14]
Exploring Large Language Models for Communication Games: An Empirical Study on
Xu, Yuzhuang and Wang, Shuo and Li, Peng and Luo, Fuwen and Wang, Xiaolong and Liu, Weidong and Liu, Yang , journal=. Exploring Large Language Models for Communication Games: An Empirical Study on
-
[15]
Do the Rewards Justify the Means?
Pan, Alexander and Chan, Jun Shern and Zou, Andy and Li, Nathaniel and Basart, Steven and Woodside, Thomas and Zhang, Hanlin and Emmons, Scott and Hendrycks, Dan , booktitle=. Do the Rewards Justify the Means?
-
[16]
Suspicion-Agent: Playing Imperfect Information Games with Theory of Mind Aware
Guo, Jiaxian and Yang, Bo and Yoo, Paul and Lin, Bill Yuchen and Iwasawa, Yusuke and Matsuo, Yutaka , journal=. Suspicion-Agent: Playing Imperfect Information Games with Theory of Mind Aware
-
[17]
Costarelli, Anthony and Allen, Mat and Hauksson, Roman and Sodunke, Grace and Hariharan, Suhas and Cheng, Carlson and Li, Wenjie and Clymer, Joshua and Yadav, Arjun , journal=
-
[18]
Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages=
Deal or No Deal? End-to-End Learning for Negotiation Dialogues , author=. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2017
-
[19]
arXiv preprint arXiv:2305.19165 , year=
Strategic Reasoning with Language Models , author=. arXiv preprint arXiv:2305.19165 , year=
-
[20]
Proceedings of the National Academy of Sciences , volume=
Deception Abilities Emerge in Large Language Models , author=. Proceedings of the National Academy of Sciences , volume=
-
[21]
Hong, Sirui and Zhuge, Mingchen and Chen, Jonathan and Zheng, Xiawu and Cheng, Yuheng and Zhang, Ceyao and Wang, Jinlin and Wang, Zili and Yau, Steven Ka Shing and Lin, Zijuan and others , booktitle=
-
[22]
Advances in Neural Information Processing Systems , volume=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Gut Feelings: The Intelligence of the Unconscious , author=. 2007 , publisher=
work page 2007
-
[24]
Jia, Jingru and Yuan, Zehua and Pan, Junhao and McNamara, Paul E. and Chen, Deming , booktitle=
-
[25]
Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI) , pages=
Game Theory Meets Large Language Models: A Systematic Survey , author=. Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI) , pages=
-
[26]
Lin, Wenye and Roberts, Jonathan and Yang, Yunhan and Albanie, Samuel and Lu, Zongqing and Han, Kai , booktitle=
-
[27]
Learning Strategic Language Agents in the
Xu, Zelai and Gu, Wanjun and Yu, Chao and Wu, Yi and Wang, Yu , booktitle=. Learning Strategic Language Agents in the
-
[28]
Nature Human Behaviour , volume=
Playing Repeated Games with Large Language Models , author=. Nature Human Behaviour , volume=. 2025 , publisher=
work page 2025
-
[29]
Mao, Shaoguang and Cai, Yuzhe and Xia, Yan and Wu, Wenshan and Wang, Xun and Wang, Fengyi and Guan, Qiang and Ge, Tao and Wei, Furu , booktitle=
-
[30]
and Stoica, Ion and Rosing, Tajana and Jin, Haojian and Zhang, Hao , booktitle=
Hu, Lanxiang and Huo, Mingjia and Zhang, Yuxuan and Yu, Haoyang and Xing, Eric P. and Stoica, Ion and Rosing, Tajana and Jin, Haojian and Zhang, Hao , booktitle=. lmgame-Bench: How Good are
-
[31]
Game of Thoughts: Iterative Reasoning in Game-Theoretic Domains with Large Language Models , author=. Proceedings of the International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , pages=
-
[32]
Artificial Analysis Intelligence Index v4.0 , author =. 2026 , howpublished =
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.