Uncovering latent consensus in heterogeneous populations: The Mixture Linear Ordering Problem
Pith reviewed 2026-06-30 20:38 UTC · model grok-4.3
The pith
An observed preference matrix can be decomposed into a mixture of several latent linear orders, each from a distinct subgroup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The observed preference matrix is produced by an unknown collection of K linear orders, each tied to a latent group of relative size given by a weight, and the task is to recover those orders and weights so their convex combination matches the matrix; this is achieved by mixed-integer programs that enforce the linear-order constraints for each group while matching the aggregate entries.
What carries the argument
The Mixture Linear Ordering Problem: recover K linear orders and nonnegative weights summing to one whose weighted sum equals the input preference matrix.
If this is right
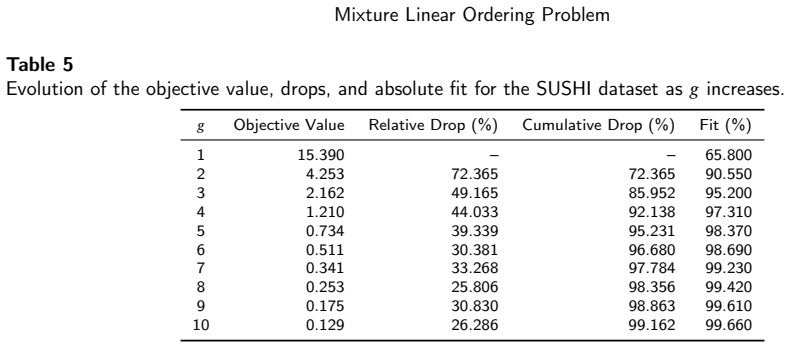
- Exact MIP formulations recover the underlying groups on synthetic instances whose size matches typical preference-aggregation problems.
- The compact reformulation admits a geometric interpretation inside the linear ordering polytope.
- The multi-start alternating-direction matheuristic returns high-quality solutions in far less time than the exact solver and sometimes improves the incumbent within the time limit.
- Both methods succeed when the number of groups K is supplied and the data are generated from the model.
Where Pith is reading between the lines
- The same decomposition could be tried on real ballot or survey matrices to surface voter blocs without assuming a single consensus ranking.
- A natural next step is an automatic procedure for choosing K that balances fit and parsimony.
- The approach may extend to other ranking polytopes such as the linear ordering polytope with additional constraints from domain knowledge.
Load-bearing premise
The observed matrix is produced exactly by a small number of distinct linear orders mixed by convex combination.
What would settle it
Generate a preference matrix from four or more linear orders with known weights, run the MIP or matheuristic with K set to three, and check whether the recovered orders and weights differ substantially from the planted ones.
Figures
read the original abstract
The classical linear ordering problem seeks a single ranking representing a given preference matrix. While suitable for homogeneous populations, it fails when observed preferences arise from several latent groups with distinct ranking patterns. To address this limitation, we introduce an extension partitioning the population into latent groups, each characterized by its own linear order, relative size, and preference structure. The observed matrix is then explained as the aggregate outcome of these group-specific preferences. We develop mixed-integer programming formulations, including a compact reformulation yielding a geometric interpretation within the linear ordering polytope. Because exact solutions become computationally demanding for larger instances, we propose a multi-start alternating-direction matheuristic iteratively updating group rankings and weights. Computational experiments on synthetically generated instances, matching sizes typical in preference aggregation scenarios, demonstrate the effectiveness of the exact approach in successfully recovering the underlying groups. Furthermore, the proposed heuristic delivers high-quality solutions in substantially shorter times, occasionally improving upon the exact method's best incumbent in difficult instances within the imposed time limit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Mixture Linear Ordering Problem (MLOP), which extends the classical linear ordering problem to heterogeneous populations by modeling the observed preference matrix as a convex combination of K latent linear orders, each with its own weight and preference structure. It develops mixed-integer programming formulations (including a compact reformulation with a geometric interpretation in the linear ordering polytope), proposes a multi-start alternating-direction matheuristic, and reports computational experiments on synthetic instances of typical preference-aggregation sizes showing that both the exact MIP and the heuristic recover the generating groups and weights.
Significance. If the recovery claims hold under identifiability conditions, the work provides a useful optimization-based framework for uncovering latent consensus structures in preference data, with direct relevance to social choice theory, marketing analytics, and multi-criteria decision making. The compact reformulation and matheuristic are practical strengths that address computational scalability; the synthetic recovery results are a positive but preliminary demonstration of the approach.
major comments (2)
- [§5] §5 (Computational Experiments): The synthetic instances are generated exactly from the model with known K and orders, and recovery is reported, but the section contains no experiments or analysis addressing non-uniqueness of the mixture decomposition. Distinct sets of orders and weights (or different K) can produce identical aggregate matrices within the linear ordering polytope; the MIPs and heuristic optimize fit without regularization or uniqueness constraints, so the reported recovery success depends on the solver returning the generating solution rather than an equivalent alternative. This is load-bearing for the central claim of "successfully recovering the underlying groups."
- [Section 2 and Section 3] Model formulation (Section 2) and compact reformulation (Section 3): The weakest assumption is that the data-generating process is exactly a modest number of linear orders whose convex combination reproduces the matrix and that K is known. No discussion or sensitivity analysis is provided for model misspecification or for how K should be selected when it is unknown; the experiments therefore do not stress-test the method outside the correctly-specified, known-K regime.
minor comments (2)
- [Abstract] Abstract: The claim that the heuristic "occasionally improving upon the exact method's best incumbent" is stated without accompanying metrics, time-limit details, or instance characteristics that would allow readers to assess the improvement.
- [§5] The manuscript would benefit from explicit baseline comparisons (e.g., single linear ordering or non-mixture clustering methods) on the same synthetic instances, as well as reporting of variability (error bars or multiple random seeds) in the recovery metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, agreeing where the concerns are valid and outlining targeted revisions to the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (Computational Experiments): The synthetic instances are generated exactly from the model with known K and orders, and recovery is reported, but the section contains no experiments or analysis addressing non-uniqueness of the mixture decomposition. Distinct sets of orders and weights (or different K) can produce identical aggregate matrices within the linear ordering polytope; the MIPs and heuristic optimize fit without regularization or uniqueness constraints, so the reported recovery success depends on the solver returning the generating solution rather than an equivalent alternative. This is load-bearing for the central claim of "successfully recovering the underlying groups."
Authors: We agree that non-uniqueness of the mixture decomposition is a substantive issue that affects interpretation of the recovery results. Our synthetic experiments demonstrate that the MIP and heuristic recover the generating orders and weights when data are generated exactly from the model, but we acknowledge that the formulation admits multiple solutions with identical objective values. In the revised manuscript we will add a dedicated paragraph in §5 discussing identifiability, drawing on the geometric view of the linear ordering polytope introduced in Section 3, and stating the conditions (e.g., sufficient angular separation between orders) under which the decomposition is expected to be unique. We will also clarify that reported success holds when the solver returns the generating solution among possibly equivalent alternatives. This revision directly addresses the load-bearing claim without adding new computational experiments. revision: partial
-
Referee: [Section 2 and Section 3] Model formulation (Section 2) and compact reformulation (Section 3): The weakest assumption is that the data-generating process is exactly a modest number of linear orders whose convex combination reproduces the matrix and that K is known. No discussion or sensitivity analysis is provided for model misspecification or for how K should be selected when it is unknown; the experiments therefore do not stress-test the method outside the correctly-specified, known-K regime.
Authors: The current work is scoped to the correctly specified, known-K setting to establish the core MIP formulations and matheuristic. We will revise Sections 2 and 3 to include an explicit discussion of this modeling assumption and its implications for misspecification. We will also add guidance on selecting K when unknown, proposing the use of information criteria (AIC/BIC) applied to the mixture likelihood or cross-validation on held-out preference entries. While we will not expand the experimental section with new misspecification tests (which would go beyond the paper’s stated scope), the added text will clearly delineate the regime in which the reported results apply and flag these issues as important directions for follow-up work. revision: yes
Circularity Check
No circularity: model is an independent optimization formulation tested against external synthetic ground truth
full rationale
The paper defines the mixture linear ordering problem as a decomposition task solved via MIP formulations and a matheuristic. Recovery is evaluated on synthetics generated from the model, with success measured by match to known generating parameters. No equation reduces the output groups/weights to the input matrix by construction, no fitted parameter is relabeled as a prediction, and no load-bearing self-citation or imported uniqueness theorem appears. The derivation chain is self-contained as an inverse optimization problem against independently generated benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- K (number of latent groups)
axioms (2)
- domain assumption The observed preference matrix is exactly a convex combination of K linear-order matrices.
- standard math Standard MIP solvers can handle the resulting formulations for the tested instance sizes.
Reference graph
Works this paper leans on
-
[1]
European Journal of Operational Research 270, 982–998
Approaching rank aggregation problems by using evolution strategies: The case of the optimal bucket order problem. European Journal of Operational Research 270, 982–998. doi:10.1016/j.ejor.2018.04.031. Aledo, J.A., Gámez, J.A., Rosete, A.,
-
[2]
Information Fusion 124, 103353
A consensus set for the aggregation of partial rankings: The case of the Optimal Set of Bucket Orders Problem. Information Fusion 124, 103353. doi:10.1016/j.inffus.2025.103353. Anderson,P.E.,Chartier,T.P.,Langville,A.N.,Pedings-Behling,K.E.,2022.Fairnessandthesetofoptimalrankingsforthelinearorderingproblem. Optimization and Engineering 23, 1289–1317. doi:...
-
[3]
European Journal of Operational Research 331, 351–364
Multiple linear ordering problem. European Journal of Operational Research 331, 351–364. doi:10.1016/j.ejor.2025.10.040. Cameron, T.R., Charmot, S., Pulaj, J.,
-
[4]
Foundations of Data Science 3, 133–149
On the linear ordering problem and the rankability of data. Foundations of Data Science 3, 133–149. doi:10.3934/fods.2021010. Carathéodory,C.,1911. Überdenvariabilitätsbereichderfourier’schenkonstantenvonpositivenharmonischenfunktionen. RendicontidelCircolo Matematico di Palermo (1884-1940) 32, 193–217. doi:10.1007/BF03014795. Cattaruzza, D., Labbé, M., P...
-
[5]
INFORMS Journal on Computing 36, 1084–1107
Exact and Heuristic Solution Techniques for Mixed-Integer Quantile Minimization Problems. INFORMS Journal on Computing 36, 1084–1107. doi:10.1287/ijoc.2022.0105. Ceberio, J., Mendiburu, A., Lozano, J.A.,
-
[6]
European Journal of Operational Research 241, 686–696
The linear ordering problem revisited. European Journal of Operational Research 241, 686–696. doi:10.1016/j.ejor.2014.09.041. Celis, L.E., Straszak, D., Vishnoi, N.K.,
-
[7]
Ranking with Fairness Constraints, in: Chatzigiannakis, I., Kaklamanis, C., Marx, D., Sannella, D. (Eds.), 45th International Colloquium on Automata, Languages, and Programming (ICALP 2018), Schloss Dagstuhl – Leibniz-Zentrum für Informatik, Dagstuhl, Germany. pp. 28:1–28:15. doi:10.4230/LIPIcs.ICALP.2018.28. Chakraborty,D.,Das,S.,Khan,A.,Subramanian,A.,2...
-
[8]
Algorithms for discovering bucket orders from data, in: Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Association for Computing Machinery, New York, NY, USA. pp. 561–566. doi:10.1145/1150402.1150468. Kamishima, T.,
-
[9]
Nantonac collaborative filtering: Recommendation based on order responses, in: Proceedings of the Ninth ACM SIGKDD InternationalConferenceonKnowledgeDiscoveryandDataMining,AssociationforComputingMachinery,NewYork,NY,USA.pp.583–588. doi:10.1145/956750.956823. Labbé,M.,Landete,M.,Monge,J.F.,2023. Bilevelintegerlinearmodelsforrankingitemsandsets. OperationsR...
-
[10]
The Review of Economics and Statistics 18, 105–125
Quantitative Input and Output Relations in the Economic Systems of the United States. The Review of Economics and Statistics 18, 105–125. doi:10.2307/1927837,arXiv:1927837. Lu, T., Boutilier, C.,
-
[11]
volume 175 ofApplied Mathematical Sciences
Exact and Heuristic Methods in Combinatorial Optimization: A Study on the Linear Ordering and the Maximum Diversity Problem. volume 175 ofApplied Mathematical Sciences. Springer, Berlin, Heidelberg. doi:10.1007/978-3-662-64877-3. Murphy, T.B., Martin, D.,
-
[12]
Computational Statistics & Data Analysis 41, 645–655
Mixtures of distance-based models for ranking data. Computational Statistics & Data Analysis 41, 645–655. doi:10.1016/S0167-9473(02)00165-2. Pitoura, E., Stefanidis, K., Koutrika, G.,
-
[13]
Fairness in rankings and recommendations: an overview. The VLDB Journal 31, 431–458. doi:10.1007/s00778-021-00697-y. Rockafellar, R.T.,
-
[14]
Princeton University Press, Princeton
Convex Analysis. Princeton University Press, Princeton. doi:doi:10.1515/9781400873173. Singh,A.,Joachims,T.,2018.FairnessofExposureinRankings,in:Proceedingsofthe24thACMSIGKDDInternationalConferenceonKnowledge Discovery & Data Mining, Association for Computing Machinery, New York, NY, USA. pp. 2219–2228. doi:10.1145/3219819.3220088. Vitelli, V., Sørensen, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.