Slower Generalization, Faster Memorization: A Sweet Spot in Algorithmic Learning
Pith reviewed 2026-06-30 21:23 UTC · model grok-4.3
The pith
Small transformers reach high validation accuracy fastest at an intermediate dataset size, not the largest one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
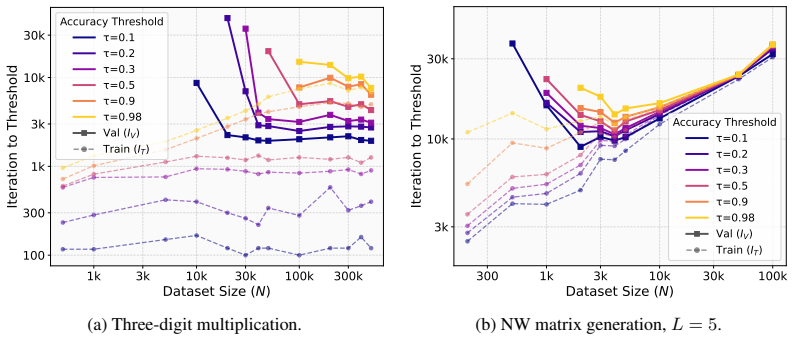
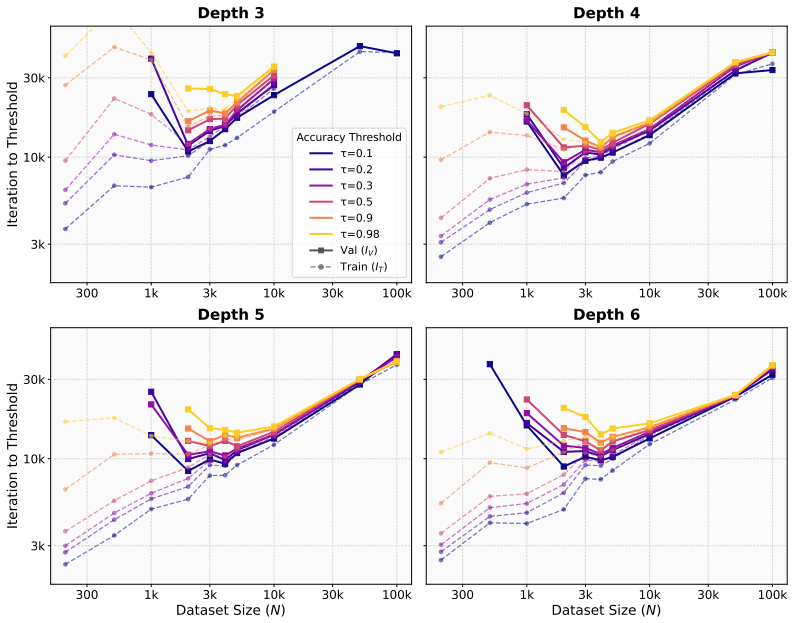
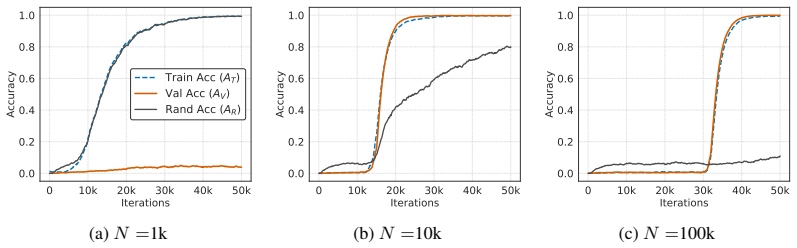
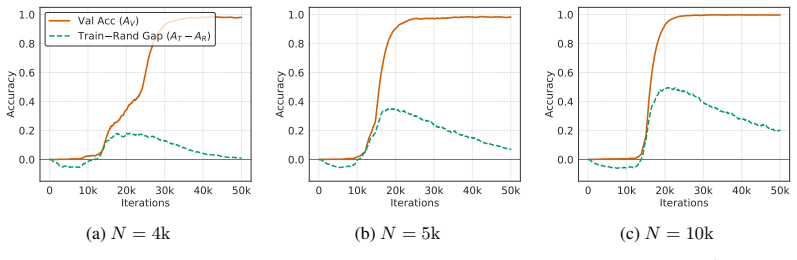
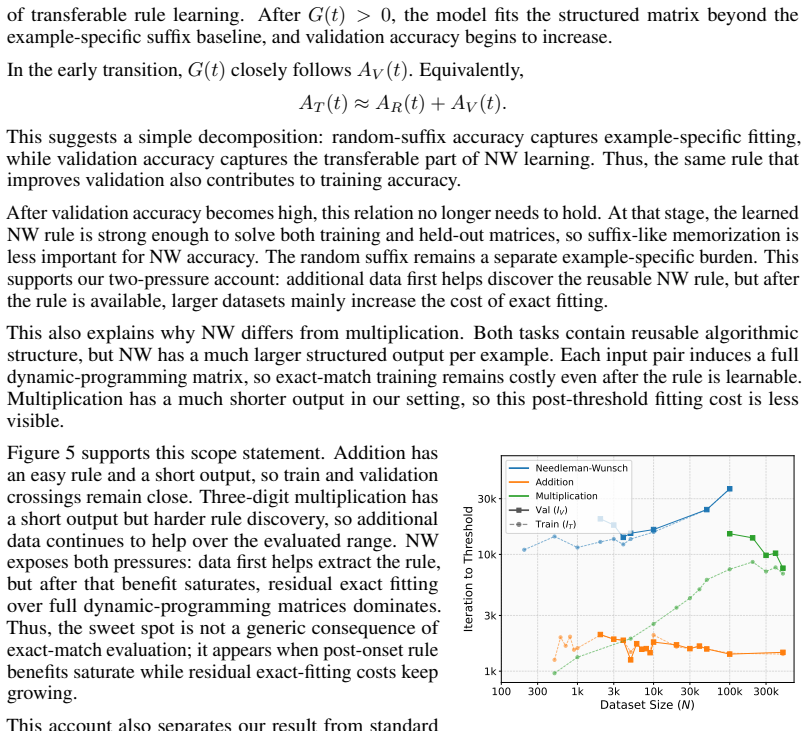
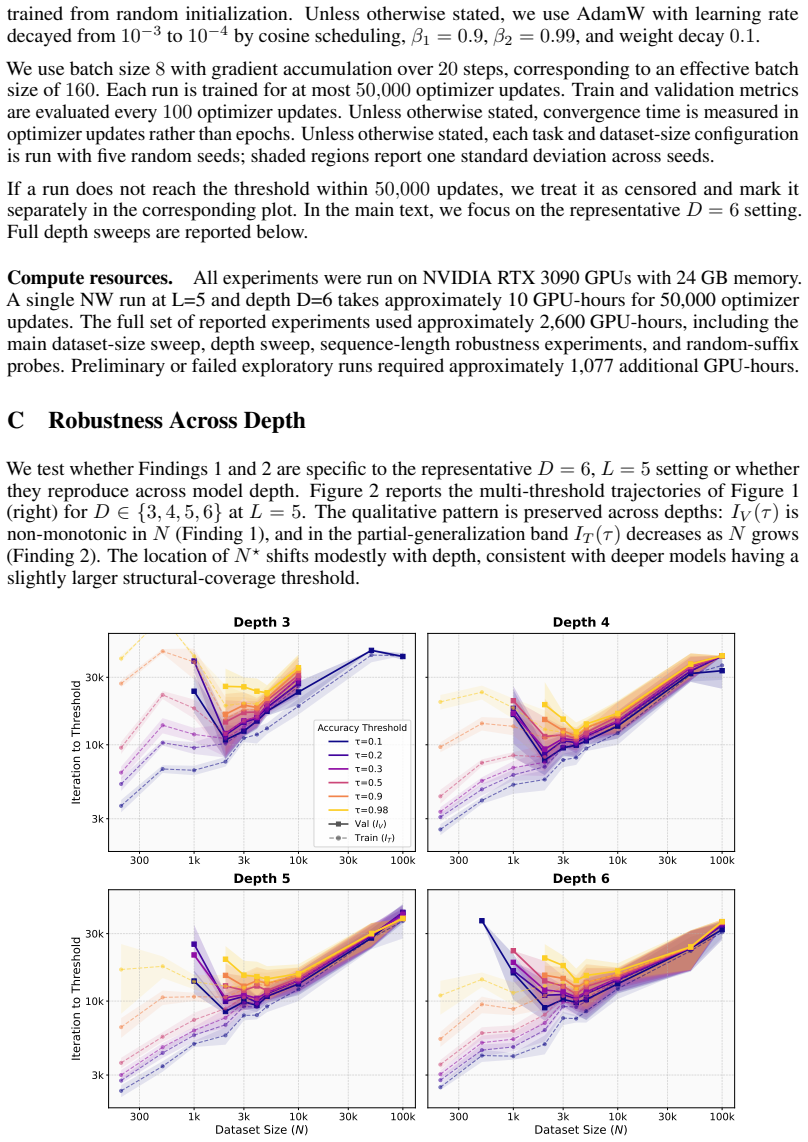
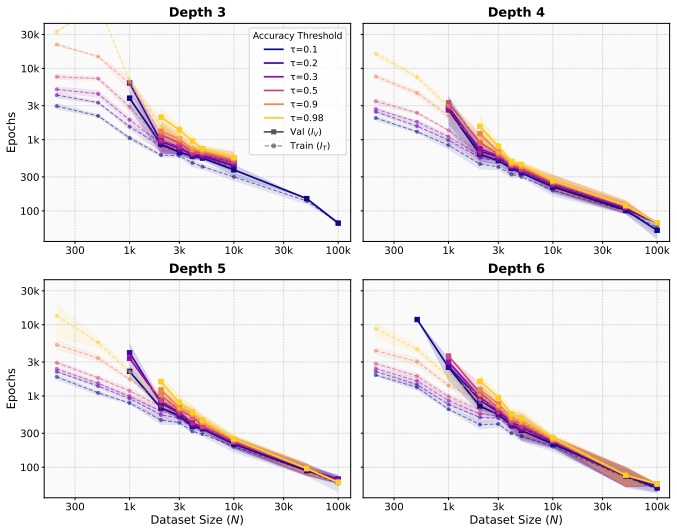
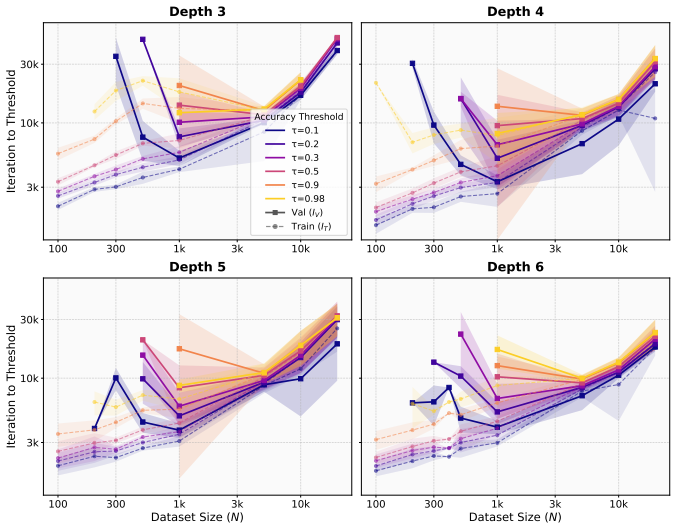
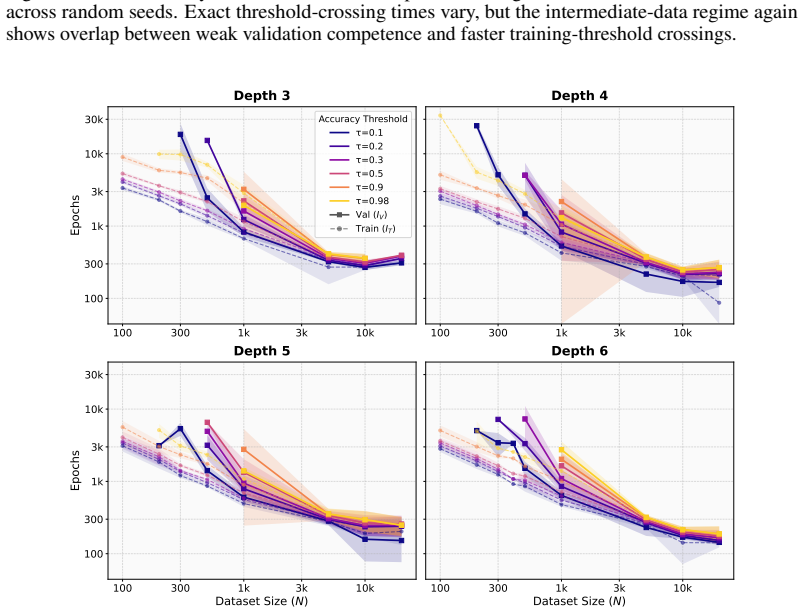
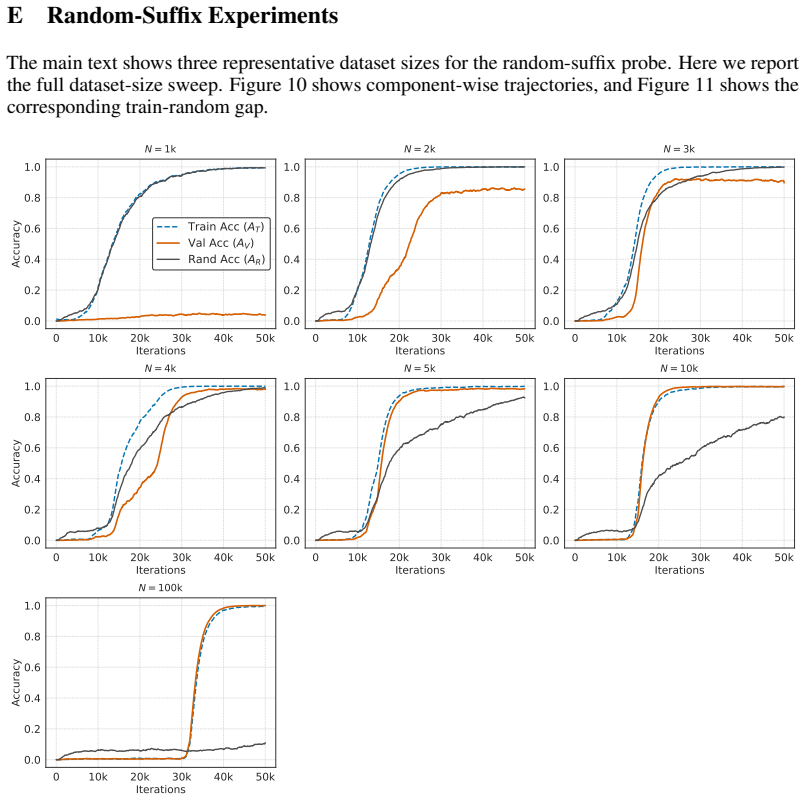
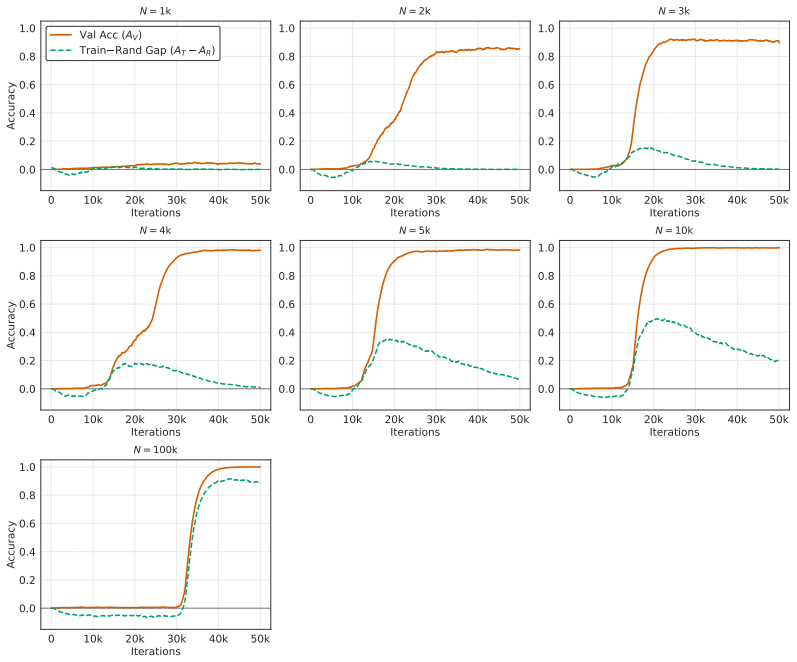
In Needleman-Wunsch matrix generation, small Transformers reach high validation exact-match accuracy fastest at an intermediate dataset size. Beyond this sweet spot, generalization stays achievable but demands more gradient updates. In the regime where partial validation competence first appears, larger datasets instead require fewer updates to reach high training accuracy. The same post-threshold slowdown for generalization does not occur on a multiplication baseline. These observations separate the critical data size for generalization onset from the dataset size that optimizes update-based convergence and show that learning the rule and completing exact fitting can diverge in structured-o
What carries the argument
The dataset-size sweet spot for update-efficient generalization in structured-output algorithmic tasks, where validation exact-match accuracy minimizes at intermediate rather than maximal data volume.
Load-bearing premise
The Needleman-Wunsch matrix generation task and chosen transformer scale form a representative controlled setting in which post-threshold effects from critical data size should hold without confounding factors.
What would settle it
Finding that validation exact-match accuracy in the Needleman-Wunsch task converges in progressively fewer updates as dataset size grows past the reported intermediate point would falsify the claimed sweet spot.
Figures
read the original abstract
Critical-data-size accounts of grokking suggest a natural post-threshold intuition: once training data is sufficient to identify the underlying rule, additional data should accelerate validation convergence. We show that this intuition can fail in a controlled structured-output task. In Needleman--Wunsch (NW) matrix generation, small Transformers reach high validation exact-match accuracy fastest at an intermediate dataset size, not at the largest one. Past this dataset-size sweet spot, generalization remains achievable but requires more gradient updates. Conversely, in the regime where partial validation competence first appears, larger datasets can require fewer updates to reach high training accuracy, suggesting that emerging rule structure can accelerate fitting beyond example-wise memorization. A multiplication baseline does not show the same post-threshold slowdown. These results separate the critical data size for the onset of generalization from the dataset size that optimizes update-based convergence, and identify structured-output tasks where learning the rule and completing exact-fitting can diverge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in the Needleman-Wunsch matrix generation task, small Transformers achieve high validation exact-match accuracy with the fewest gradient updates at an intermediate dataset size rather than the largest one, contrary to post-threshold expectations from critical-data-size accounts of grokking. It further claims that larger datasets can accelerate training accuracy (memorization) once partial validation competence emerges, while a multiplication baseline does not exhibit the same post-threshold slowdown in generalization.
Significance. If the empirical observation holds under controlled conditions, the result would separate the critical data size required for the onset of generalization from the dataset size that minimizes the number of updates needed for convergence. This distinction could refine understanding of when rule structure accelerates fitting versus when additional data impedes update-efficient generalization in structured-output algorithmic tasks.
major comments (1)
- The provided abstract and reader's assessment indicate that experimental details (dataset size ranges, NW task generation procedure, Transformer hyperparameters, number of runs, and error bars) are not available for verification; without these, the robustness of the reported sweet spot cannot be assessed and the central empirical claim remains unverified.
Simulated Author's Rebuttal
We thank the referee for their assessment and the opportunity to clarify the experimental details supporting our central claims. We address the major comment below.
read point-by-point responses
-
Referee: The provided abstract and reader's assessment indicate that experimental details (dataset size ranges, NW task generation procedure, Transformer hyperparameters, number of runs, and error bars) are not available for verification; without these, the robustness of the reported sweet spot cannot be assessed and the central empirical claim remains unverified.
Authors: The referee correctly notes that the abstract omits these specifics, which is standard for abstracts. The full manuscript contains a dedicated Experimental Setup section (Section 3) and Appendix that specify: dataset sizes spanning multiple orders of magnitude with the intermediate sweet spot identified; the NW matrix generation procedure via the standard dynamic-programming recurrence on random input sequences; the small Transformer architecture and training hyperparameters; the number of independent runs; and error bars on all reported curves. These elements are also referenced in the figure captions and results section. We believe this information suffices for verification and reproduction of the reported sweet spot and the contrast with the multiplication baseline. If any aspect remains unclear, we are happy to expand or clarify further in revision. revision: no
Circularity Check
No significant circularity
full rationale
The paper is an empirical report on dataset-size effects in Transformer training for a structured-output task. The abstract describes observational results on validation accuracy convergence rates at different data scales, with no equations, derivations, fitted parameters presented as predictions, or self-citations invoked as load-bearing uniqueness theorems. No steps reduce by construction to inputs; the central claim is a direct experimental finding on a specific algorithmic task and baseline comparison, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md. Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Yufei Huang, Shengding Hu, Xu Han, Zhiyuan Liu, and Maosong Sun. Unified view of grokking, double descent and emergent abilities: A perspective from circuits competition.arXiv preprint arXiv:2402.15175,
-
[4]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[5]
Teaching arithmetic to small transformers.arXiv preprint arXiv:2307.03381, 2023
Nayoung Lee, Kartik Sreenivasan, Jason D Lee, Kangwook Lee, and Dimitris Papailiopoulos. Teaching arithmetic to small transformers.arXiv preprint arXiv:2307.03381,
-
[6]
Kaifeng Lyu, Jikai Jin, Zhiyuan Li, Simon S Du, Jason D Lee, and Wei Hu. Dichotomy of early and late phase implicit biases can provably induce grokking.arXiv preprint arXiv:2311.18817,
-
[7]
How much do language models memorize? arXiv preprint arXiv:2505.24832, 2025
John X Morris, Chawin Sitawarin, Chuan Guo, Narine Kokhlikyan, G Edward Suh, Alexander M Rush, Kamalika Chaudhuri, and Saeed Mahloujifar. How much do language models memorize? arXiv preprint arXiv:2505.24832,
-
[8]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Gen- eralization beyond overfitting on small algorithmic datasets.arXiv preprint arXiv:2201.02177,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2309.02390 , year=
Vikrant Varma, Rohin Shah, Zachary Kenton, János Kramár, and Ramana Kumar. Explaining grokking through circuit efficiency.arXiv preprint arXiv:2309.02390,
-
[10]
Critical data size of language models from a grokking perspective.arXiv preprint arXiv:2401.10463,
Xuekai Zhu, Yao Fu, Bowen Zhou, and Zhouhan Lin. Critical data size of language models from a grokking perspective.arXiv preprint arXiv:2401.10463,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.