The Rate-Distortion-Polysemanticity Tradeoff in SAEs
Pith reviewed 2026-06-30 21:10 UTC · model grok-4.3
The pith
Sparse autoencoders must trade higher rate and distortion for monosemantic features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
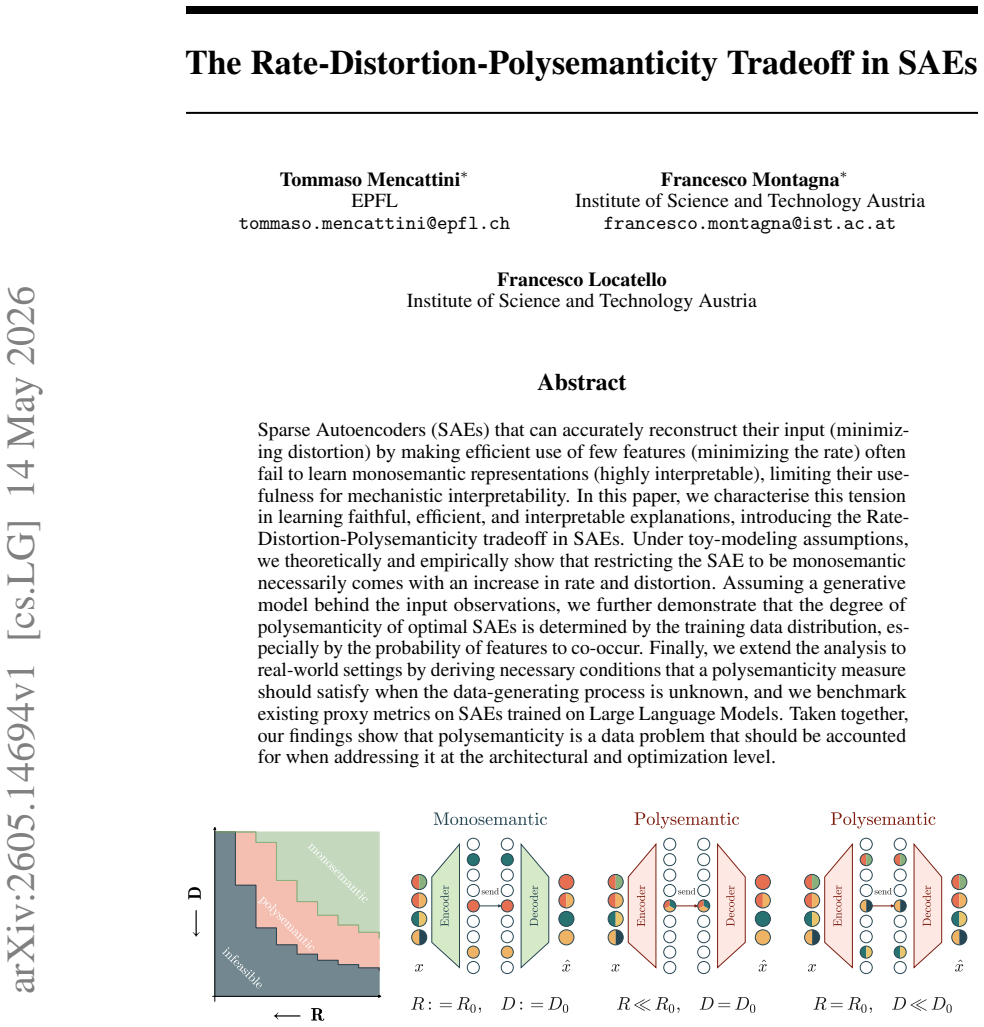
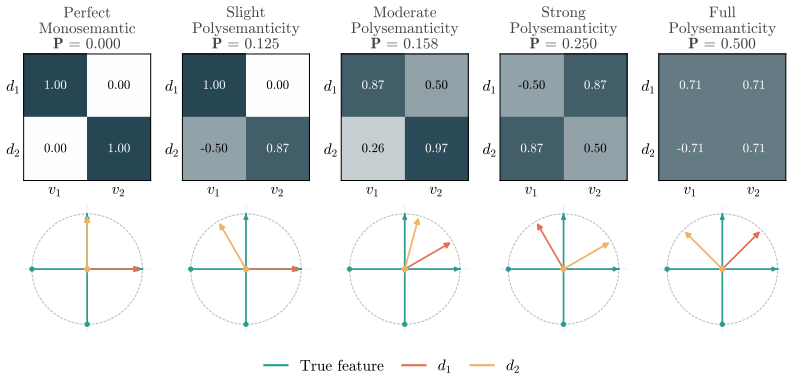
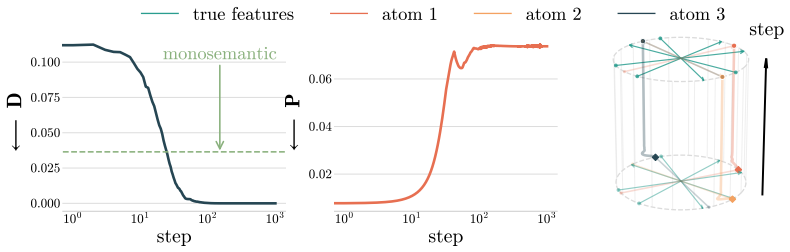
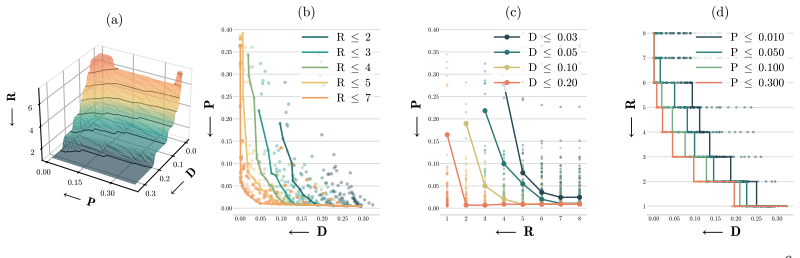
Under toy-modeling assumptions, restricting the SAE to be monosemantic necessarily comes with an increase in rate and distortion. Assuming a generative model behind the input observations, the degree of polysemanticity of optimal SAEs is determined by the training data distribution, especially by the probability of features to co-occur.
What carries the argument
The rate-distortion-polysemanticity tradeoff, which shows that monosemantic constraints on SAEs increase rate and distortion because optimal polysemanticity is set by feature co-occurrence probabilities in a generative model of the data.
Load-bearing premise
The analysis depends on toy-modeling assumptions and the existence of an underlying generative model that sets polysemanticity through feature co-occurrence probabilities.
What would settle it
Construct data in which every pair of features has zero co-occurrence probability, train both monosemantic and unrestricted SAEs, and check whether the monosemantic version can match the rate and distortion of the unrestricted version.
Figures
read the original abstract
Sparse Autoencoders (SAEs) that can accurately reconstruct their input (minimizing distortion) by making efficient use of few features (minimizing the rate) often fail to learn monosemantic representations (highly interpretable), limiting their usefulness for mechanistic interpretability. In this paper, we characterise this tension in learning faithful, efficient, and interpretable explanations, introducing the Rate-Distortion-Polysemanticity tradeoff in SAEs. Under toy-modeling assumptions, we theoretically and empirically show that restricting the SAE to be monosemantic necessarily comes with an increase in rate and distortion. Assuming a generative model behind the input observations, we further demonstrate that the degree of polysemanticity of optimal SAEs is determined by the training data distribution, especially by the probability of features to co-occur. Finally, we extend the analysis to real-world settings by deriving necessary conditions that a polysemanticity measure should satisfy when the data-generating process is unknown, and we benchmark existing proxy metrics on SAEs trained on Large Language Models. Taken together, our findings show that polysemanticity is a data problem that should be accounted for when addressing it at the architectural and optimization level.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Rate-Distortion-Polysemanticity tradeoff for Sparse Autoencoders. Under toy-modeling assumptions with an explicit generative model, it theoretically and empirically shows that restricting SAEs to monosemantic representations necessarily increases rate and distortion. It further shows that the polysemanticity of optimal SAEs is determined by the training data distribution, particularly feature co-occurrence probabilities. The work extends the analysis to real data by deriving necessary conditions that any polysemanticity measure must satisfy when the generative process is unknown, and benchmarks existing proxy metrics on SAEs trained on LLMs.
Significance. If the results hold, the framing of polysemanticity as a data-distribution phenomenon (via co-occurrence) rather than purely an architectural failure would be a useful conceptual contribution to mechanistic interpretability. The derivation of necessary conditions for polysemanticity measures provides a concrete criterion that future metrics can be checked against. The paper receives credit for explicitly stating its toy-model assumptions and for attempting a bridge from the generative-model analysis to practical LLM SAEs.
major comments (2)
- [Abstract and theoretical analysis] Abstract and theoretical analysis: the central claim that monosemantic restriction 'necessarily' increases rate and distortion is derived only under toy generative assumptions with known feature co-occurrence probabilities. No argument is supplied showing that the necessity survives when the data-generating process is unknown (the realistic case), which is load-bearing for the claimed tradeoff applying to deployed SAEs.
- [Empirical extension section] Empirical extension section: the benchmarking of proxy metrics on real LLM SAEs is presented at high level without reported error bars, baseline comparisons, or quantitative tables, so it is impossible to evaluate whether the necessary conditions are satisfied or whether the proxies behave as predicted by the toy analysis.
minor comments (1)
- [Toy-model experiments] Clarify the precise definitions of rate, distortion, and the polysemanticity measure used in the toy experiments so that the reported increases can be reproduced from the stated generative model.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for acknowledging the paper's contributions in framing polysemanticity as a data-distribution phenomenon and providing necessary conditions for polysemanticity measures. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract and theoretical analysis] Abstract and theoretical analysis: the central claim that monosemantic restriction 'necessarily' increases rate and distortion is derived only under toy generative assumptions with known feature co-occurrence probabilities. No argument is supplied showing that the necessity survives when the data-generating process is unknown (the realistic case), which is load-bearing for the claimed tradeoff applying to deployed SAEs.
Authors: We agree that the necessity claim for increased rate and distortion under monosemantic restriction is established only under the specified toy generative model assumptions, including known feature co-occurrence probabilities. The manuscript does not supply an argument demonstrating that this necessity holds in the general case where the data-generating process is unknown. The extension section instead focuses on deriving necessary conditions for any polysemanticity measure to be valid when the generative process is unknown. We will revise the manuscript to more explicitly state the scope of the necessity result and clarify that it does not directly apply to deployed SAEs without the toy assumptions. revision: partial
-
Referee: [Empirical extension section] Empirical extension section: the benchmarking of proxy metrics on real LLM SAEs is presented at high level without reported error bars, baseline comparisons, or quantitative tables, so it is impossible to evaluate whether the necessary conditions are satisfied or whether the proxies behave as predicted by the toy analysis.
Authors: We acknowledge that the presentation of the benchmarking results for proxy metrics on SAEs trained on LLMs is at a high level and lacks error bars, baseline comparisons, and quantitative tables. This limits the ability to assess whether the necessary conditions are met or how the proxies align with the toy model predictions. In the revised version, we will expand this section to include error bars, relevant baseline comparisons, detailed quantitative tables, and explicit checks against the necessary conditions derived in the paper. revision: yes
Circularity Check
No circularity: derivation proceeds from explicit generative-model assumptions without reducing to fitted inputs or self-citations.
full rationale
The paper states its central tradeoff result under toy-modeling assumptions with an explicit generative model whose features have defined co-occurrence probabilities; the claimed determination of optimal polysemanticity follows directly from those probabilities inside the model. The real-world extension derives necessary conditions on any polysemanticity measure when the data-generating process is unknown, without fitting parameters or renaming prior results. No equations or steps in the abstract reduce a prediction to its own inputs by construction, and no self-citation chains or uniqueness theorems are invoked as load-bearing. The analysis is therefore self-contained against external benchmarks once the modeling assumptions are granted.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Toy-modeling assumptions suffice to demonstrate the rate-distortion-polysemanticity tradeoff
- domain assumption Input observations are generated by an underlying generative model whose feature co-occurrence probabilities determine optimal SAE polysemanticity
Reference graph
Works this paper leans on
-
[1]
Kola Ayonrinde, Michael T. Pearce, and Lee Sharkey. Interpretability as compression: Reconsidering sae explanations of neural activations with mdl-saes.arXiv preprint arXiv:2410.11179,
-
[2]
Christopher P
https://transformer-circuits.pub/2023/monosemantic-features/index.html. Christopher P. Burgess, Irina Higgins, Arka Pal, Loic Matthey, Nick Watters, Guillaume Desjardins, and Alexander Lerchner. Understanding disentangling in β-vae,
2023
-
[3]
Understanding disentangling in $\beta$-VAE
URL https://arxiv. org/abs/1804.03599. Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Batchtopk sparse autoencoders.arXiv preprint arXiv:2412.06410,
URL https://arxiv.org/abs/2412.06410. Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. Learning multi-level features with matryoshka sparse autoencoders,
-
[5]
David Chanin and Adrià Garriga-Alonso
URLhttps://arxiv.org/abs/2503.17547. David Chanin and Adrià Garriga-Alonso. Sparse but wrong: Incorrect L0 leads to incorrect features in sparse autoencoders.arXiv preprint arXiv:2508.16560,
-
[6]
David Chanin and Adrià Garriga-Alonso. SynthSAEBench: Evaluating sparse autoencoders on scalable realistic synthetic data.arXiv preprint arXiv:2602.14687,
-
[7]
arXiv preprint arXiv:2409.14507 , year=
David Chanin, James Wilken-Smith, Tomáš Dulka, Hardik Bhatnagar, and Joseph Bloom. A is for absorption: Studying feature splitting and absorption in sparse autoencoders.arXiv preprint arXiv:2409.14507,
-
[8]
David Chanin, Tomáš Dulka, and Adria Garriga-Alonso. Feature hedging: Correlated features break narrow sparse autoencoders.arXiv preprint arXiv:2505.11756,
-
[9]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
ISBN 0471241954. Hoagy Cunningham, Aidan Ewart, Logan Riggs Smith, Robert Huben, and Lee Sharkey. Sparse au- toencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
https://transformer-circuits.pub/2022/toy_ model/index.html, arXiv:2209.10652. 10 Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
URL https://arxiv. org/abs/2503.01822. Adam Karvonen, Can Rager, Johnny Lin, Curt Tigges, Joseph Bloom, David Chanin, Yeu-Tong Lau, Eoin Farrell, Callum McDougall, Kola Ayonrinde, et al. Saebench: A comprehensive benchmark for sparse autoencoders in language model interpretability.arXiv preprint arXiv:2503.09532,
-
[12]
Gouki Minegishi, Hiroki Furuta, Yusuke Iwasawa, and Yutaka Matsuo. Rethinking evalua- tion of sparse autoencoders through the representation of polysemous words.arXiv preprint arXiv:2501.06254,
-
[13]
URLhttps://distill.pub/ 2020/circuits/zoom-in
doi: 10.23915/distill.00024.001. https://distill.pub/2020/circuits/zoom-in. Charles O’Neill, Alim Gumran, and David Klindt. Compute optimal inference and provable amorti- sation gap in sparse autoencoders,
-
[14]
Kiho Park, Yo Joong Choe, and Victor Veitch
URLhttps://arxiv.org/abs/2411.13117. Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InProceedings of the 41st International Conference on Machine Learning,
-
[15]
URLhttps://arxiv.org/abs/2410.13928. Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, and Neel Nanda. Improving dictionary learning with gated sparse autoen- coders, 2024a. URLhttps://arxiv.org/abs/2404.16014. Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, J...
-
[16]
doi: 10.52202/079017-3211. URL https://proceedings.neurips.cc/paper_files/paper/ 2024/file/b76a9959151d377ddd2c77a275a97475-Paper-Conference.pdf. Adam Scherlis, Kshitij Sachan, Adam S. Jermyn, Joe Benton, and Buck Shlegeris. Polysemanticity and capacity in neural networks.arXiv preprint arXiv:2210.01892,
-
[17]
Recent Advances in Autoencoder-Based Representation Learning
ISBN 978- 0956372857. Michael Tschannen, Olivier Bachem, and Mario Lucic. Recent advances in autoencoder-based representation learning.arXiv preprint arXiv:1812.05069,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
ReLU or TopK θ= (W enc, Wdec,b enc,b dec)parameter tuple of an SAE Θclass of SAEs under consideration Data generating process V= (v 1,
11 A Notation Symbol Meaning Dimensions ddimension of the ambient activation space mSAE width (number of latent coordinates) nnumber of ground-truth concepts in the DGP KTopK sparsity budget, when applicable Sparse autoencoder x∈R d input activation ˆx∈R d SAE reconstruction ofx a(x)∈R m preactivation z(x)∈R m latent code (message) Wenc, Wdec ∈R m×d encod...
2006
-
[19]
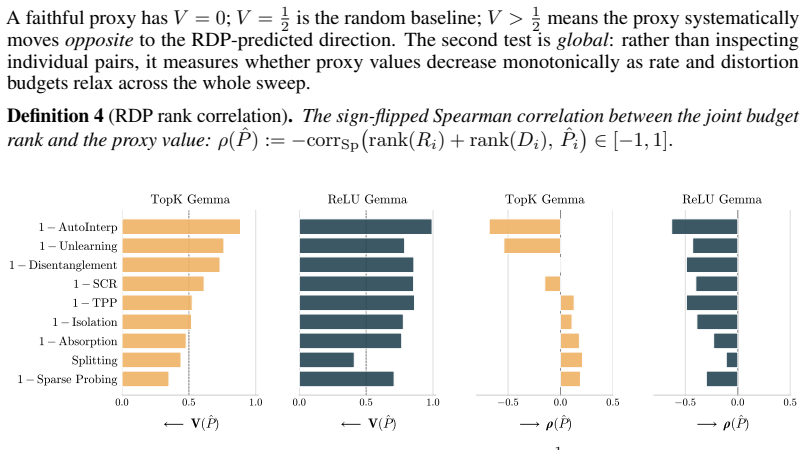
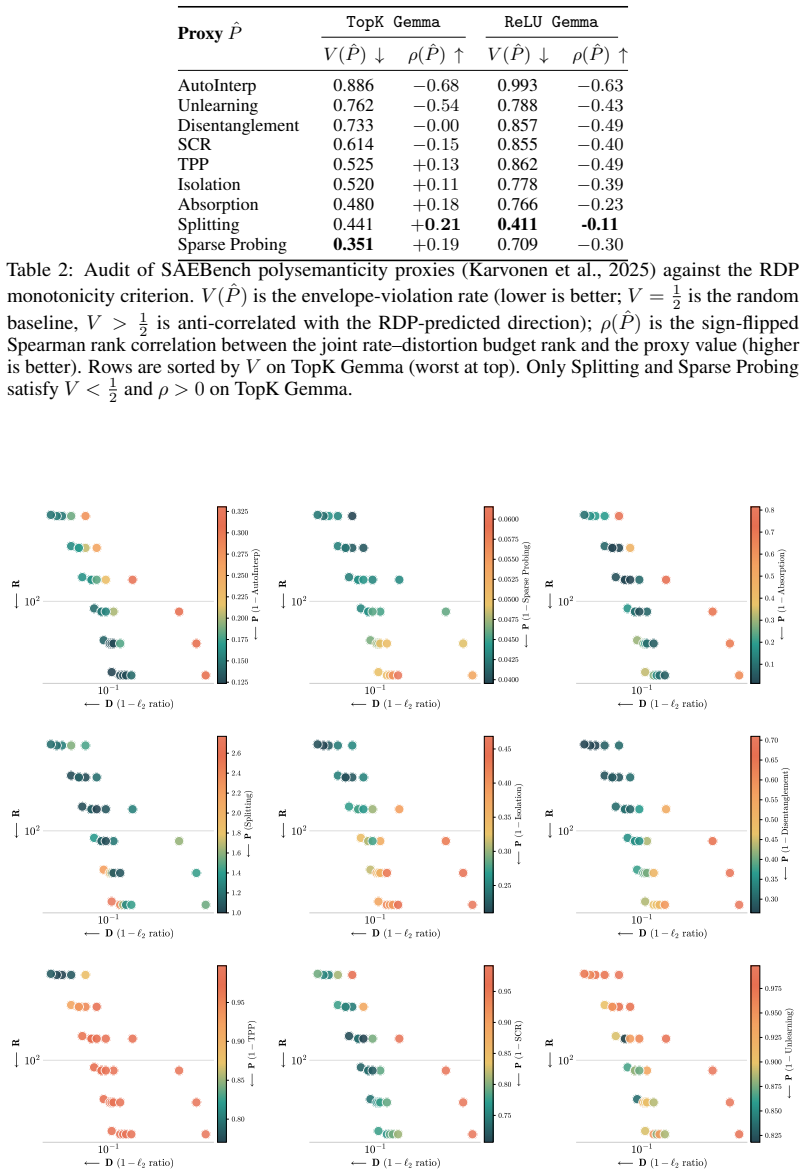
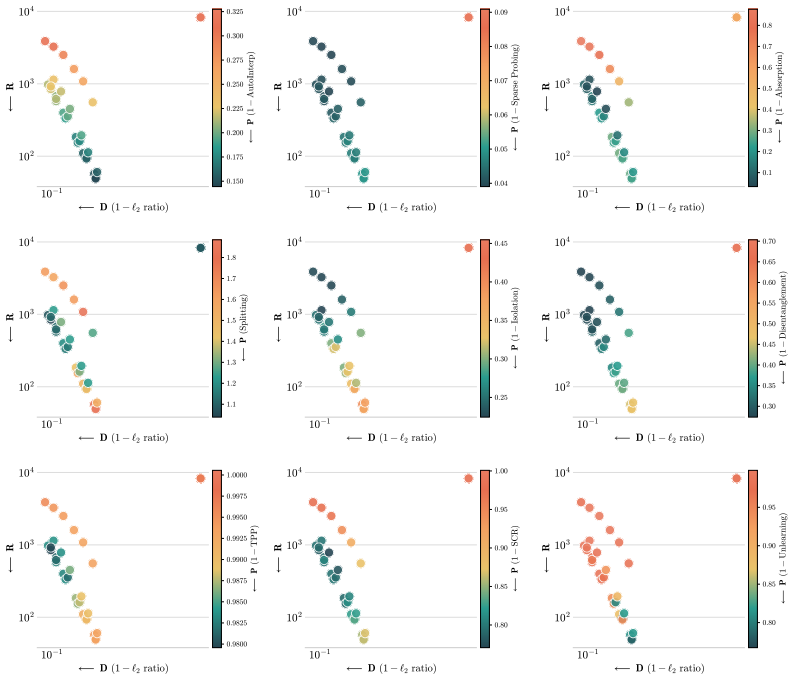
against the RDP monotonicity criterion. V( ˆP) is the envelope-violation rate (lower is better; V= 1 2 is the random baseline, V > 1 2 is anti-correlated with the RDP-predicted direction); ρ( ˆP) is the sign-flipped Spearman rank correlation between the joint rate–distortion budget rank and the proxy value (higher is better). Rows are sorted by V on TopK ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.