IsoNet: Spatially-aware audio-visual target speech extraction in complex acoustic environments
Pith reviewed 2026-05-19 16:27 UTC · model grok-4.3
The pith
IsoNet extracts target speech from compact four-microphone arrays by fusing visual face embeddings with spatial audio cues where beamformers fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
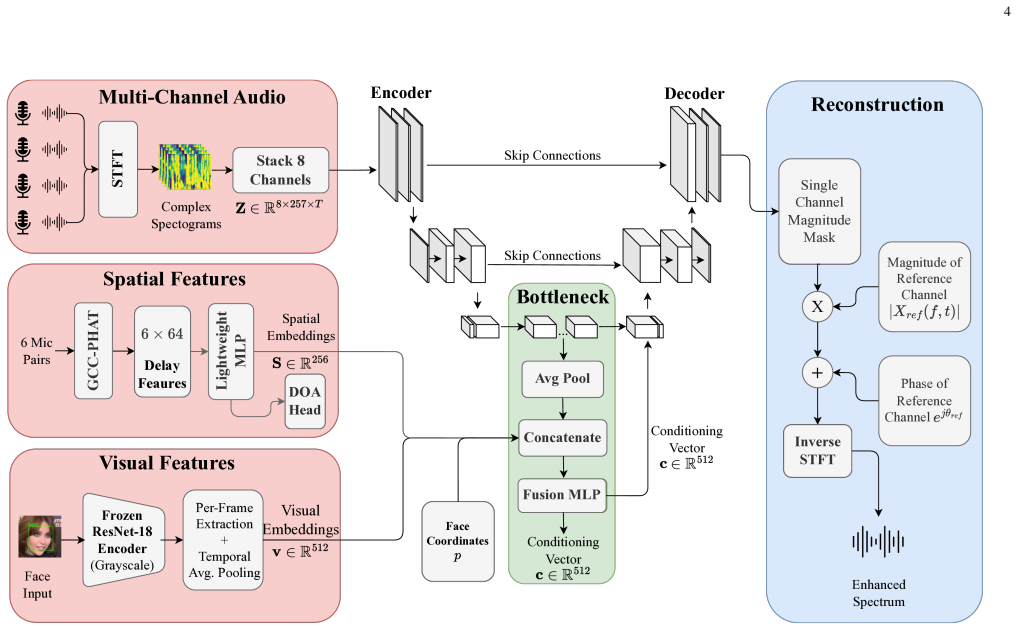
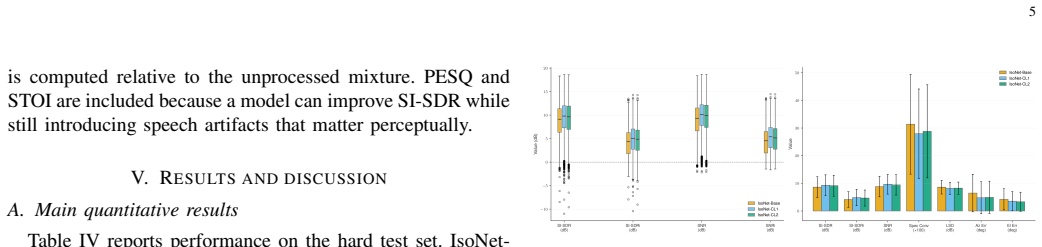
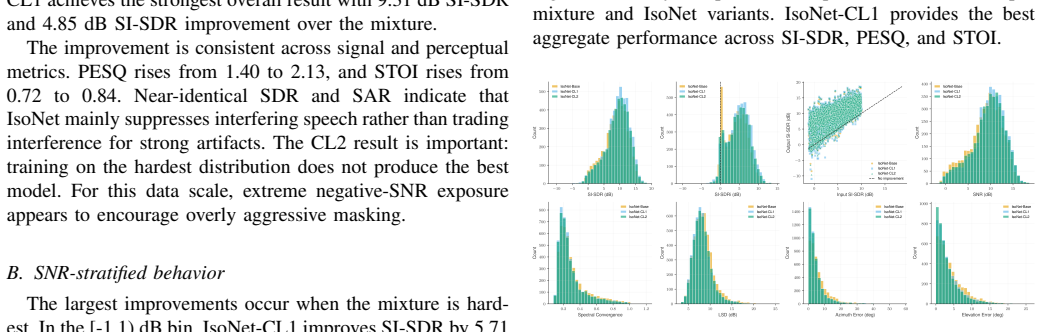
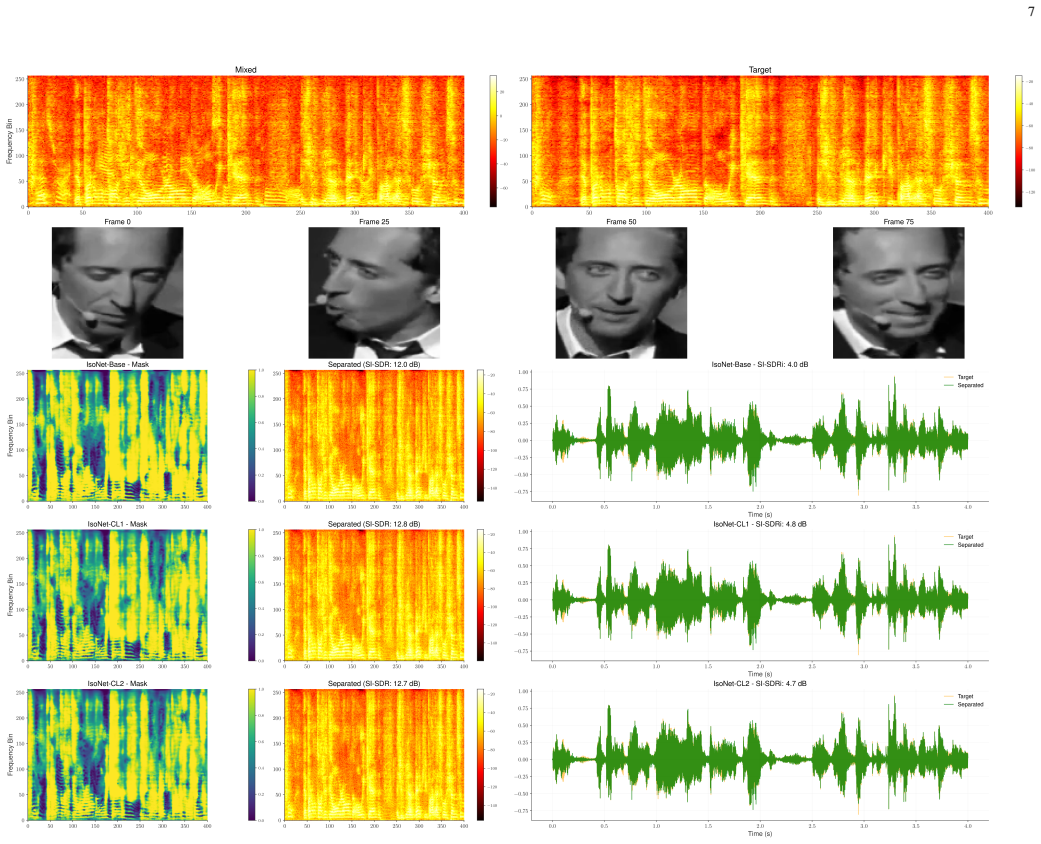
IsoNet is a U-Net mask estimation network that ingests complex multi-channel STFT features, GCC-PHAT spatial cues, face-conditioned visual embeddings, and auxiliary direction-of-arrival supervision. Trained on 25,000 simulated VoxCeleb mixtures under curriculum SNR schedules, the best variant reaches 9.31 dB SI-SDR on a hard test set spanning -1 to 10 dB SNR, delivering a 4.85 dB improvement over the mixture while oracle delay-and-sum and MVDR beamformers degrade the same mixtures.
What carries the argument
The IsoNet U-Net mask estimation network that fuses complex multi-channel STFT features, GCC-PHAT spatial cues, and face-conditioned visual embeddings with auxiliary direction-of-arrival supervision.
If this is right
- Visual face conditioning yields consistent gains in extraction quality on compact arrays.
- GCC-PHAT features and extended delay-bin encoding supply useful spatial information that classical methods cannot exploit at small apertures.
- The approach supplies a reproducible baseline for user-selectable target speech extraction under controlled simulation.
- Phase reconstruction and multi-interferer handling remain open barriers after the reported gains.
Where Pith is reading between the lines
- Real-device performance will likely require explicit handling of phase reconstruction and simulation-to-real transfer.
- Adding support for several concurrent interferers would extend the method to more realistic crowded scenes.
- Joint training with lip-reading or other visual speech tasks could further tighten audio-visual alignment.
Load-bearing premise
Simulated single-interferer mixtures with controlled SNR regimes accurately reflect the acoustic conditions and audio-visual alignment found in real compact-device deployments.
What would settle it
Direct comparison of IsoNet output quality against beamformers on real recordings made with a physical four-microphone array in rooms containing multiple simultaneous talkers.
Figures

read the original abstract
Target speech extraction remains difficult for compact devices because monaural neural models lack spatial evidence and classical beamformers lose resolving power when the microphone aperture is only a few centimetres. We present IsoNet, a user-selectable audio-visual target speech extraction system for a compact 4-microphone array. IsoNet combines complex multi-channel STFT features, GCC-PHAT spatial cues, face-conditioned visual embeddings, and auxiliary direction-of-arrival supervision inside a U-Net mask estimation network. Three curriculum variants were trained on 25,000 simulated VoxCeleb mixtures with progressively difficult SNR regimes. On a hard test set spanning -1 to 10 dB SNR, IsoNet-CL1 achieves 9.31 dB SI-SDR, a 4.85 dB improvement over the mixture, with PESQ 2.13 and STOI 0.84. Oracle delay-and-sum and MVDR beamformers degrade the same mixtures by 4.82 dB and 6.08 dB SI-SDRi, respectively, showing that the proposed learned multimodal conditioning solves a regime where conventional spatial filtering is ineffective. Ablation studies show consistent gains from visual conditioning, GCC-PHAT features, and extended delay-bin encoding. The results establish a compact-array, face-selectable speech extraction baseline under controlled simulation and identify the remaining barriers to real deployment, especially phase reconstruction, multi-interferer mixtures, and simulation-to-real transfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IsoNet, a user-selectable audio-visual target speech extraction network for compact 4-microphone arrays. It fuses complex multi-channel STFT features, GCC-PHAT spatial cues, face-conditioned visual embeddings, and auxiliary DOA supervision inside a U-Net mask estimator. Three curriculum-learning variants are trained on 25,000 simulated VoxCeleb mixtures. On a held-out hard test set spanning -1 to 10 dB SNR, IsoNet-CL1 reports 9.31 dB SI-SDR (4.85 dB improvement over the mixture), PESQ 2.13 and STOI 0.84. Oracle delay-and-sum and MVDR beamformers degrade the same mixtures, and ablations attribute gains to the visual, GCC-PHAT and extended delay-bin components.
Significance. If the simulation assumptions hold, the work supplies a clear empirical baseline showing that learned multimodal conditioning can succeed where classical spatial filters lose effectiveness on small-aperture arrays. The oracle comparisons, curriculum variants, and component ablations are presented transparently and constitute a useful reference point for compact-device AV speech extraction research.
major comments (2)
- [Abstract and Results] Abstract and Results section: The central claim that IsoNet 'solves' the compact-array regime where oracle delay-and-sum and MVDR degrade performance (by 4.82 dB and 6.08 dB SI-SDRi) rests entirely on 25,000 simulated single-interferer mixtures with perfect visual-audio alignment and ideal microphone responses. No real-array recordings or sim-to-real transfer experiments are reported, even though the abstract itself flags simulation-to-real transfer as a remaining barrier. This makes the generalizability of the 4.85 dB SI-SDRi gain to physical compact-device conditions difficult to assess.
- [Methods and Experiments] Methods and Experiments: The oracle beamformer comparisons are presented without explicit detail on whether the oracles receive the same DOA supervision or visual face embeddings that IsoNet uses, or how the compact 4-mic geometry and reverberation are modeled in the simulation. Clarifying these implementation choices would strengthen the interpretation that the learned multimodal model genuinely outperforms classical spatial filtering rather than benefiting from additional side information.
minor comments (2)
- [Abstract] The abstract states '25,000 simulated VoxCeleb mixtures' but does not specify the train/validation/test split ratios or whether speakers and acoustic conditions are disjoint; adding this information would improve reproducibility.
- [Figures] Figure captions and axis labels for the ablation and curriculum curves should explicitly state the number of runs or whether error bars are shown; currently the quantitative gains are reported without visible variability measures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the value of the empirical baseline provided by our simulation study. We respond to each major comment below with clarifications and note the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results section: The central claim that IsoNet 'solves' the compact-array regime where oracle delay-and-sum and MVDR degrade performance (by 4.82 dB and 6.08 dB SI-SDRi) rests entirely on 25,000 simulated single-interferer mixtures with perfect visual-audio alignment and ideal microphone responses. No real-array recordings or sim-to-real transfer experiments are reported, even though the abstract itself flags simulation-to-real transfer as a remaining barrier. This makes the generalizability of the 4.85 dB SI-SDRi gain to physical compact-device conditions difficult to assess.
Authors: We agree that the reported results, including the 4.85 dB SI-SDRi improvement, are obtained exclusively under controlled simulation conditions with single interferers, perfect alignment, and ideal microphone responses, as stated throughout the manuscript. The central claim is scoped to demonstrating that learned multimodal conditioning can outperform oracle classical beamformers in this specific simulated compact-array regime, where limited aperture causes traditional spatial filters to degrade performance. This serves as a transparent reference point rather than a claim of real-world solution. We will revise the abstract and discussion to replace the word 'solves' with more precise phrasing such as 'outperforms in the simulated regime' and expand the limitations paragraph to further emphasize the simulation assumptions and the identified barriers to real deployment. revision: partial
-
Referee: [Methods and Experiments] Methods and Experiments: The oracle beamformer comparisons are presented without explicit detail on whether the oracles receive the same DOA supervision or visual face embeddings that IsoNet uses, or how the compact 4-mic geometry and reverberation are modeled in the simulation. Clarifying these implementation choices would strengthen the interpretation that the learned multimodal model genuinely outperforms classical spatial filtering rather than benefiting from additional side information.
Authors: The oracle delay-and-sum and MVDR beamformers are implemented as classical algorithms that receive only ground-truth DOA computed directly from the known source and microphone positions in the simulation; they receive neither visual face embeddings nor any learned features. The auxiliary DOA supervision is used solely during IsoNet training to promote spatial awareness and is not provided to the oracles at test time. The simulation models a compact 4-microphone array with inter-microphone spacing of a few centimeters and generates reverberant mixtures by convolving clean speech with room impulse responses simulated for typical indoor acoustic environments using the image-source method. We will add a new subsection in the Methods section explicitly describing the oracle implementations, the exact geometry parameters, and the reverberation modeling to ensure the comparison is interpreted as the learned model succeeding with multimodal cues where purely spatial classical methods fail even with oracle spatial information. revision: yes
Circularity Check
No circularity: empirical results on held-out simulated mixtures
full rationale
The paper describes a U-Net-based neural architecture for audio-visual target speech extraction, trained on 25,000 simulated VoxCeleb mixtures and evaluated via standard metrics (SI-SDR, PESQ, STOI) on a held-out hard test set. No mathematical derivation, first-principles prediction, or uniqueness theorem is claimed; performance numbers are direct empirical outcomes of supervised training and inference. Ablations compare feature variants but do not reduce any reported quantity to a fitted parameter by construction. No self-citations appear as load-bearing justifications for the central claims. The work is self-contained as an experimental baseline under controlled simulation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulated room acoustics and single-interferer mixtures are representative of target real-world conditions
Reference graph
Works this paper leans on
-
[1]
Some experiments on the recognition of speech, with one and with two ears,
E. C. Cherry, “Some experiments on the recognition of speech, with one and with two ears,”J. Acoust. Soc. Am., vol. 25, no. 5, pp. 975–979, 1953
work page 1953
-
[2]
Beamforming: A versatile approach to spatial filtering,
B. D. Van Veen and K. M. Buckley, “Beamforming: A versatile approach to spatial filtering,”IEEE ASSP Mag., vol. 5, no. 2, pp. 4–24, Apr. 1988
work page 1988
-
[3]
A con- solidated perspective on multimicrophone speech enhancement and source separation,
S. Gannot, E. Vincent, S. Markovich-Golan, and A. Ozerov, “A con- solidated perspective on multimicrophone speech enhancement and source separation,”IEEE/ACM Trans. Audio, Speech, Language Pro- cess., vol. 25, no. 4, pp. 692–730, Apr. 2017
work page 2017
-
[4]
High-resolution frequency-wavenumber spectrum analysis,
J. Capon, “High-resolution frequency-wavenumber spectrum analysis,” Proc. IEEE, vol. 57, no. 8, pp. 1408–1418, Aug. 1969
work page 1969
-
[5]
An alternative approach to linearly constrained adaptive beamforming,
L. J. Griffiths and C. W. Jim, “An alternative approach to linearly constrained adaptive beamforming,”IEEE Trans. Antennas Propag., vol. 30, no. 1, pp. 27–34, Jan. 1982
work page 1982
-
[6]
Towards scaling up classification-based speech separation,
Y . Wang and D. Wang, “Towards scaling up classification-based speech separation,”IEEE Trans. Audio, Speech, Language Process., vol. 21, no. 7, pp. 1381–1390, Jul. 2013
work page 2013
-
[7]
Conv-tasnet: Surpassing ideal time-frequency magnitude masking for speech separation,
Y . Luo and N. Mesgarani, “Conv-tasnet: Surpassing ideal time-frequency magnitude masking for speech separation,”IEEE/ACM Trans. Audio, Speech, Language Process., vol. 27, no. 8, pp. 1256–1266, Aug. 2019
work page 2019
-
[8]
Dual-path rnn: Efficient long sequence modeling for time-domain single-channel speech separation,
Y . Luo, Z. Chen, and T. Yoshioka, “Dual-path rnn: Efficient long sequence modeling for time-domain single-channel speech separation,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), May 2020, pp. 46–50
work page 2020
-
[9]
Attention is all you need in speech separation,
C. Subakan, M. Ravanelli, S. Cornell, M. Bronzi, and J. Zhong, “Attention is all you need in speech separation,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), Jun. 2021, pp. 21–25
work page 2021
-
[10]
M. Kolbæk, D. Yu, Z.-H. Tan, and J. Jensen, “Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks,”IEEE/ACM Trans. Audio, Speech, Language Process., vol. 25, no. 10, pp. 1901–1913, Oct. 2017
work page 1901
-
[11]
A. Ephrat, I. Mosseri, O. Lang, T. Dekel, K. Wilson, A. Hassidim, W. T. Freeman, and M. Rubinstein, “Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation,”ACM Trans. Graph. (SIGGRAPH), vol. 37, no. 4, pp. 1–11, Aug. 2018
work page 2018
-
[12]
Visualvoice: Audio-visual speech separation with cross-modal consistency,
R. Gao and K. Grauman, “Visualvoice: Audio-visual speech separation with cross-modal consistency,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2021, pp. 15 490–15 500
work page 2021
-
[13]
An overview of deep-learning-based audio-visual speech en- hancement and separation,
D. Michelsanti, Z.-H. Tan, S.-X. Zhang, Y . Xu, M. Yu, D. Yu, and J. Jensen, “An overview of deep-learning-based audio-visual speech en- hancement and separation,”IEEE/ACM Trans. Audio, Speech, Language Process., vol. 29, pp. 1368–1396, 2021
work page 2021
-
[14]
The generalized correlation method for estimation of time delay,
C. Knapp and G. Carter, “The generalized correlation method for estimation of time delay,”IEEE Trans. Acoust., Speech, Signal Process., vol. 24, no. 4, pp. 320–327, Aug. 1976
work page 1976
-
[15]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inProc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent. (MICCAI), 2015, pp. 234–241
work page 2015
-
[16]
Multi-modal multi-channel target speech separation,
R. Gu, S.-X. Zhang, Y . Xu, L. Chen, Y . Zou, and D. Yu, “Multi-modal multi-channel target speech separation,”IEEE J. Sel. Topics Signal Process., vol. 14, no. 3, pp. 530–541, Mar. 2020
work page 2020
-
[17]
R. Tao, Z. Pan, R. K. Das, X. Qian, M. Z. Shou, and H. Li, “Is someone speaking? exploring long-term temporal features for audio-visual active speaker detection,” inProc. ACM Int. Conf. Multimedia, 2021, pp. 3927– 3935
work page 2021
-
[18]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” inProc. AAAI Conf. Artif. Intell., 2018, pp. 3942–3951
work page 2018
-
[19]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 770–778
work page 2016
-
[20]
V oxceleb: Large- scale speaker verification in the wild,
A. Nagrani, J. S. Chung, W. Xie, and A. Zisserman, “V oxceleb: Large- scale speaker verification in the wild,”Computer Speech & Language, vol. 60, pp. 1–27, 2020
work page 2020
-
[21]
Pyroomacoustics: A python package for audio room simulation and array processing,
R. Scheibler, E. Bezzam, and I. Dokmani ´c, “Pyroomacoustics: A python package for audio room simulation and array processing,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), Calgary, AB, Canada, Apr. 2018, pp. 351–355
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.