Probabilistic Verification of Recurrent Neural Networks for Single and Multi-Agent Reinforcement Learning
Pith reviewed 2026-06-30 20:50 UTC · model grok-4.3
The pith
RNN-ProVe estimates the likelihood of undesired behaviors in RNN policies by sampling feasible hidden states and applying statistical error bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RNN-ProVe estimates the likelihood of undesired behaviors in RNN-based policies. It uses policy-driven sampling to approximate the set of hidden states that are feasible under a trained policy, and derives statistical error bounds to produce bounded-error, high-confidence estimates of behavioral violations. Experiments on partially observable single-agent and cooperative multi-agent tasks show that RNN-ProVe yields more quantitative, feasibility-aware probabilistic guarantees than existing tools, while scaling to recurrent and multi-agent settings.
What carries the argument
Policy-driven sampling to approximate feasible hidden states under the trained policy, paired with statistical error bounds on violation likelihood estimates.
If this is right
- Produces bounded-error high-confidence estimates of behavioral violations instead of binary or overly conservative outcomes.
- Applies directly to recurrent policies in partially observable environments without requiring restrictive modeling assumptions.
- Extends verification coverage to cooperative multi-agent reinforcement learning tasks.
- Yields feasibility-aware probabilistic guarantees that reflect what states are actually reachable under the policy.
Where Pith is reading between the lines
- The sampling-plus-bounds approach could be combined with online monitoring to flag high-risk states during policy execution.
- If the statistical bounds prove tight in practice, they might serve as a lightweight alternative to exhaustive reachability analysis for continuous hidden-state spaces.
- The method opens a path to verifying policies whose hidden-state dynamics are too complex for symbolic or abstraction-based tools.
Load-bearing premise
That sampling trajectories from the trained policy produces a representative approximation of all hidden states the policy can actually reach.
What would settle it
An experiment that computes the exact violation probability on a small RNN policy instance and shows that the sampled estimate with its reported bounds fails to contain the true value.
Figures




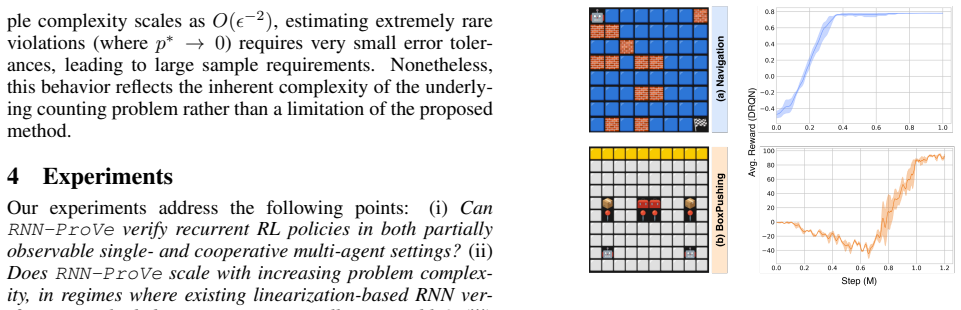
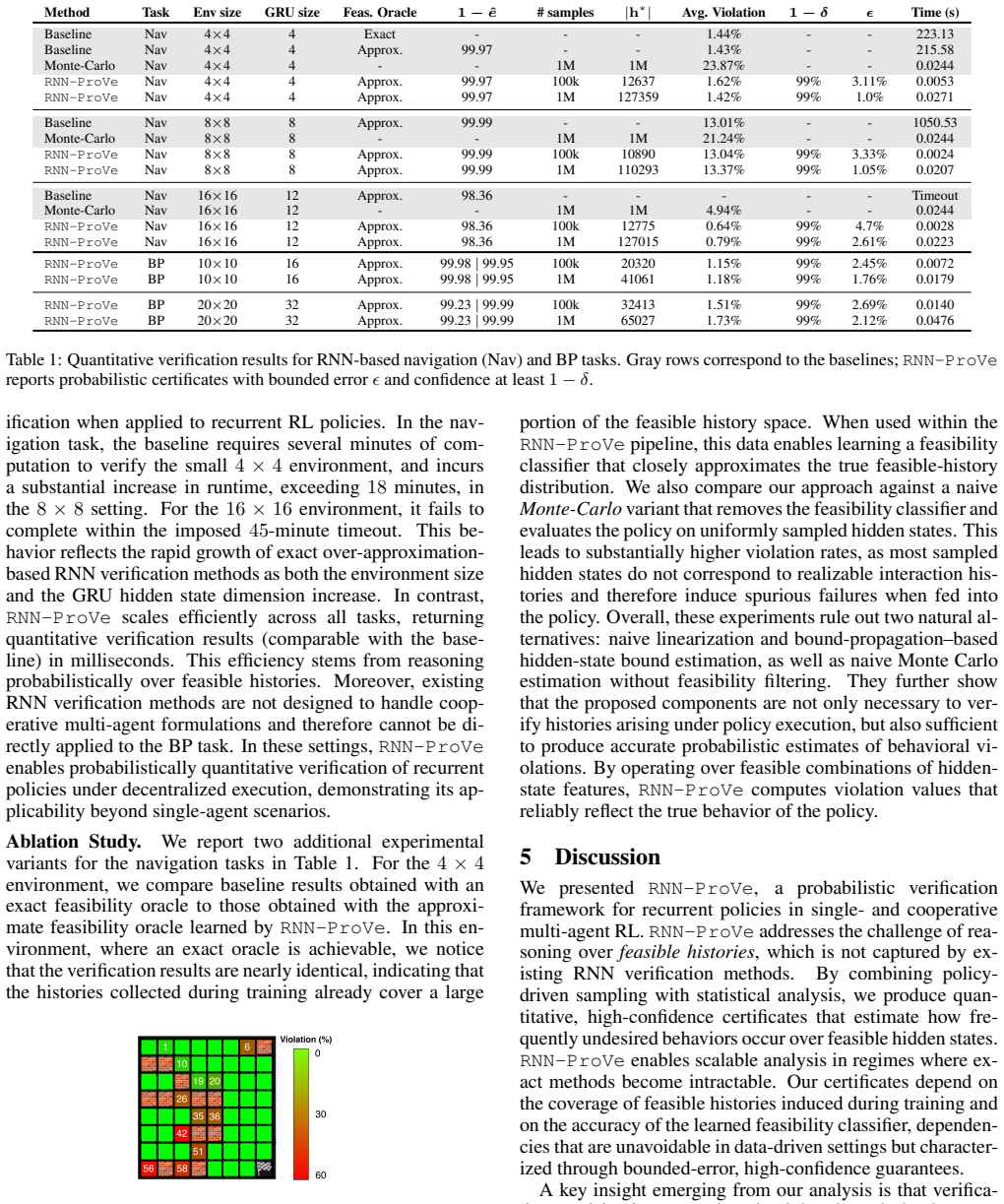
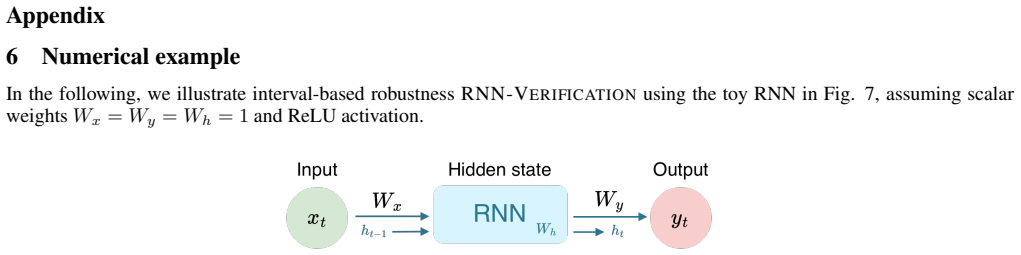
read the original abstract
History-dependent policies induced by recurrent neural networks (RNNs) rely on latent hidden state dynamics, making verification in partially observable reinforcement learning (RL) challenging. Existing RNN verification tools typically rely on restrictive modeling assumptions or coarse over-approximations of the hidden state space, which can lead to overly conservative or inconclusive results. We propose $\textbf{RNN}$ $\textbf{Pro}$babilistic $\textbf{Ve}$rification ($\texttt{RNN-ProVe}$), a probabilistic framework that $\textit{estimates the likelihood}$ of undesired behaviors in RNN-based policies. $\texttt{RNN-ProVe}$ uses policy-driven sampling to approximate the set of hidden states that are feasible under a trained policy, and derives statistical error bounds to produce bounded-error, high-confidence estimates of behavioral violations. Experiments on partially observable single-agent and cooperative multi-agent tasks show that $\texttt{RNN-ProVe}$ yields more quantitative, feasibility-aware probabilistic guarantees than existing tools, while scaling to recurrent and multi-agent settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RNN-ProVe, a probabilistic verification framework for RNN-based policies in partially observable single-agent and multi-agent RL. It approximates the feasible hidden-state set under a trained policy via policy-driven sampling, then derives statistical error bounds to produce bounded-error, high-confidence estimates of the probability of undesired behaviors. Experiments on partially observable tasks are claimed to show that RNN-ProVe provides more quantitative and feasibility-aware guarantees than existing tools while scaling to recurrent and multi-agent settings.
Significance. If the sampling procedure can be shown to produce a sufficiently representative approximation of the reachable hidden-state distribution and the statistical bounds are rigorously derived, the method could provide a practical alternative to conservative over-approximations for verifying history-dependent policies where exact verification is intractable. This would be particularly valuable in multi-agent cooperative settings.
major comments (1)
- [Abstract] Abstract: The claim that RNN-ProVe 'derives statistical error bounds' to produce 'bounded-error, high-confidence estimates' is load-bearing on the unstated assumption that policy-driven sampling yields a representative (unbiased or sufficiently covering) approximation of the reachable hidden-state set under the policy. No derivation, sampling algorithm, or argument establishing this representativeness is supplied in the provided text; without it, the concentration inequalities cannot be guaranteed to apply, directly undermining the central probabilistic guarantee.
Simulated Author's Rebuttal
We thank the referee for their careful review and for highlighting an important point about the foundations of our probabilistic claims. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that RNN-ProVe 'derives statistical error bounds' to produce 'bounded-error, high-confidence estimates' is load-bearing on the unstated assumption that policy-driven sampling yields a representative (unbiased or sufficiently covering) approximation of the reachable hidden-state set under the policy. No derivation, sampling algorithm, or argument establishing this representativeness is supplied in the provided text; without it, the concentration inequalities cannot be guaranteed to apply, directly undermining the central probabilistic guarantee.
Authors: Policy-driven sampling generates trajectories by executing the trained RNN policy within the POMDP, so the observed hidden states are drawn exactly from the distribution induced by the policy and the environment dynamics. This construction ensures the samples are representative of the reachable hidden-state distribution under the policy, allowing standard concentration inequalities to apply directly to the empirical estimates of violation probabilities. The sampling algorithm, its unbiasedness properties, and the derivation of the resulting error bounds are presented in Section 3 of the manuscript. We agree that the abstract would benefit from an explicit reference to this property and will revise it accordingly. revision: partial
Circularity Check
No significant circularity; derivation relies on independent statistical estimation
full rationale
The provided abstract and description present RNN-ProVe as using policy-driven sampling to approximate reachable hidden states followed by standard statistical error bounds for violation probabilities. This is a conventional Monte Carlo-style estimation procedure whose validity depends on sampling assumptions but does not reduce any claimed prediction or bound to the inputs by definition or self-citation. No equations, self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the text. The method is self-contained against external benchmarks for its statistical component.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Christopher Amato. An introduction to centralized training for decentralized execution in cooperative multi-agent re- inforcement learning.arXiv preprint arXiv:2409.03052,
-
[2]
On the Properties of Neural Machine Translation: Encoder-Decoder Approaches
Kyunghyun Cho, Bart Van Merri¨enboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neural machine translation: Encoder-decoder approaches.arXiv preprint arXiv:1409.1259,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Deep Recurrent Q-Learning for Partially Observable MDPs
Matthew Hausknecht and Peter Stone. Deep recurrent q- learning for partially observable mdps.arXiv preprint arXiv:1507.06527,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Safe deep reinforcement learning by verifying task-level properties
Enrico Marchesini, Luca Marzari, Alessandro Farinelli, and Christopher Amato. Safe deep reinforcement learning by verifying task-level properties. InProceedings of the 2023 International Conference on Autonomous Agents and Mul- tiagent Systems, AAMAS 2023, pages 1466–1475. ACM,
2023
-
[5]
Enrico Marchesini, Benjamin Donnot, Constance Crozier, Ian Dytham, Christian Merz, Lars Schewe, Nico Westerbeck, Cathy Wu, Antoine Marot, and Priya L Donti. Rl2grid: Benchmarking reinforcement learning in power grid oper- ations.arXiv preprint arXiv:2503.23101,
-
[6]
Donti, Changliu Liu, and En- rico Marchesini
Luca Marzari, Priya L. Donti, Changliu Liu, and En- rico Marchesini. Improving policy optimization viaϵ- retrain. InProceedings of the 24th International Con- ference on Autonomous Agents and Multiagent Systems, AAMAS 2025, pages 1464–1472. International Foundation for Autonomous Agents and Multiagent Systems / ACM,
2025
-
[7]
Advancing neural network verification through hierarchi- cal safety abstract interpretation
Luca Marzari, Isabella Mastroeni, and Alessandro Farinelli. Advancing neural network verification through hierarchi- cal safety abstract interpretation. InECAI 2025 - 28th Eu- ropean Conference on Artificial Intelligence, pages 1736– 1743,
2025
-
[8]
Yun, Peizhi Niu, Xusheng Luo, and Changliu Liu
Tianhao Wei, Hanjiang Hu, Luca Marzari, Kai S. Yun, Peizhi Niu, Xusheng Luo, and Changliu Liu. Modelverification.jl: A comprehensive toolbox for formally verifying deep neu- ral networks. InComputer Aided Verification - 37th In- ternational Conference, CAV 2025, volume 15932 ofLec- ture Notes in Computer Science, pages 395–408. Springer,
2025
-
[9]
Finally,Y T =y T = 1·h 2 = [1,5]
= ReLU([1,5]) = [1,5]. Finally,Y T =y T = 1·h 2 = [1,5]. Sincemin(Y T ) = 1>0, the RNN is verified as robust. 7 On the Hardness of the #RNN-VERIFICATIONProblem. We now analyze the computational complexity of the #RNN-VERIFICATIONproblem. Theorem 1.The#RNN-VERIFICATIONproblem is #P-hard. Proof Sketch.The hardness result relies on the established relationsh...
2017
-
[10]
The problem requires characterizing the set of histories (hidden states)Γ(T) :={h∈ H |f(h, x)≤0}. If we fix the observationxand considerhas the input variable, determining the volumeV ol(Γ(T))is equivalent to determining the preimage volume of a DNNfthat maps to the unsafe region(−∞,0]. Hence, from the #P-hardness of the #DNN-VERIFICATIONit follows that #...
2020
-
[11]
Best performing parameters used for training are highlighted in bold
Table 2: Hyper-parameters candidate for initial grid search tuning. Best performing parameters used for training are highlighted in bold. Learning rate 3e-3,3e-4, 3e-5 γ0.9, 0.95, 0.99 Buffer size (episodes)1000, 2500, 5000 Batch size32, 64, 128 Sampling trajectory size 10, 25, 50,T Polyak averagingω0.995, 0.9998 N° hidden layers2, 3 Hidden layers size32,...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.