MediaClaw: Multimodal Intelligent-Agent Platform Technical Report
Pith reviewed 2026-06-30 20:44 UTC · model grok-4.3
The pith
MediaClaw unifies AIGC capabilities with a three-layer architecture of abstraction, plugins, and workflow orchestration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
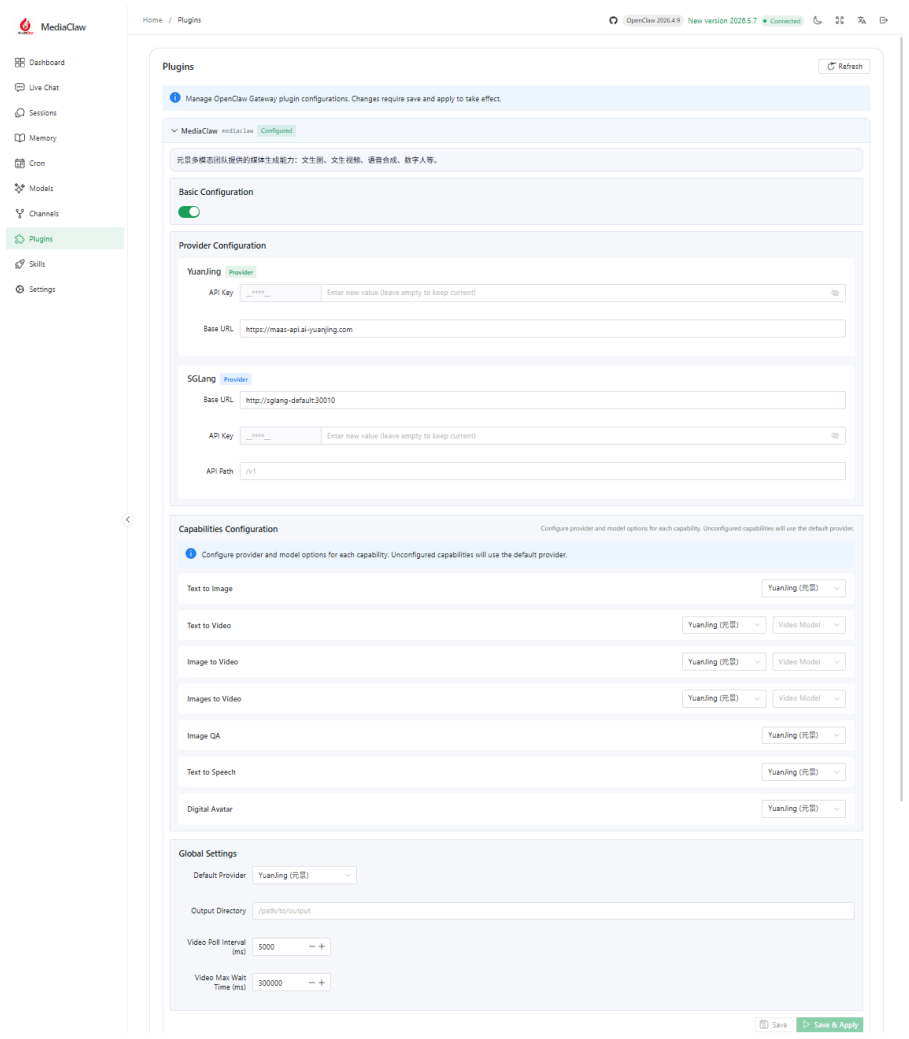
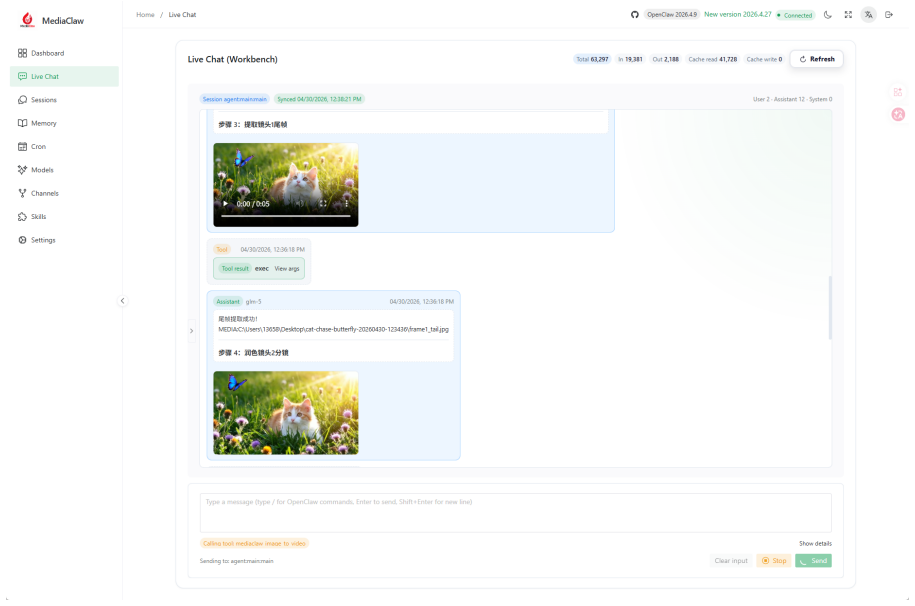
MediaClaw abstracts full-category AIGC capabilities into a unified invocation model, uses plugins to support hot-pluggable capability expansion, and uses task-oriented Skills to turn complex production processes into reusable workflow assets. The report focuses on the architectural design philosophy, the design logic of its core capability model, and the key engineering trade-offs in implementation to provide reusable practical reference for building multimodal capability platforms.
What carries the argument
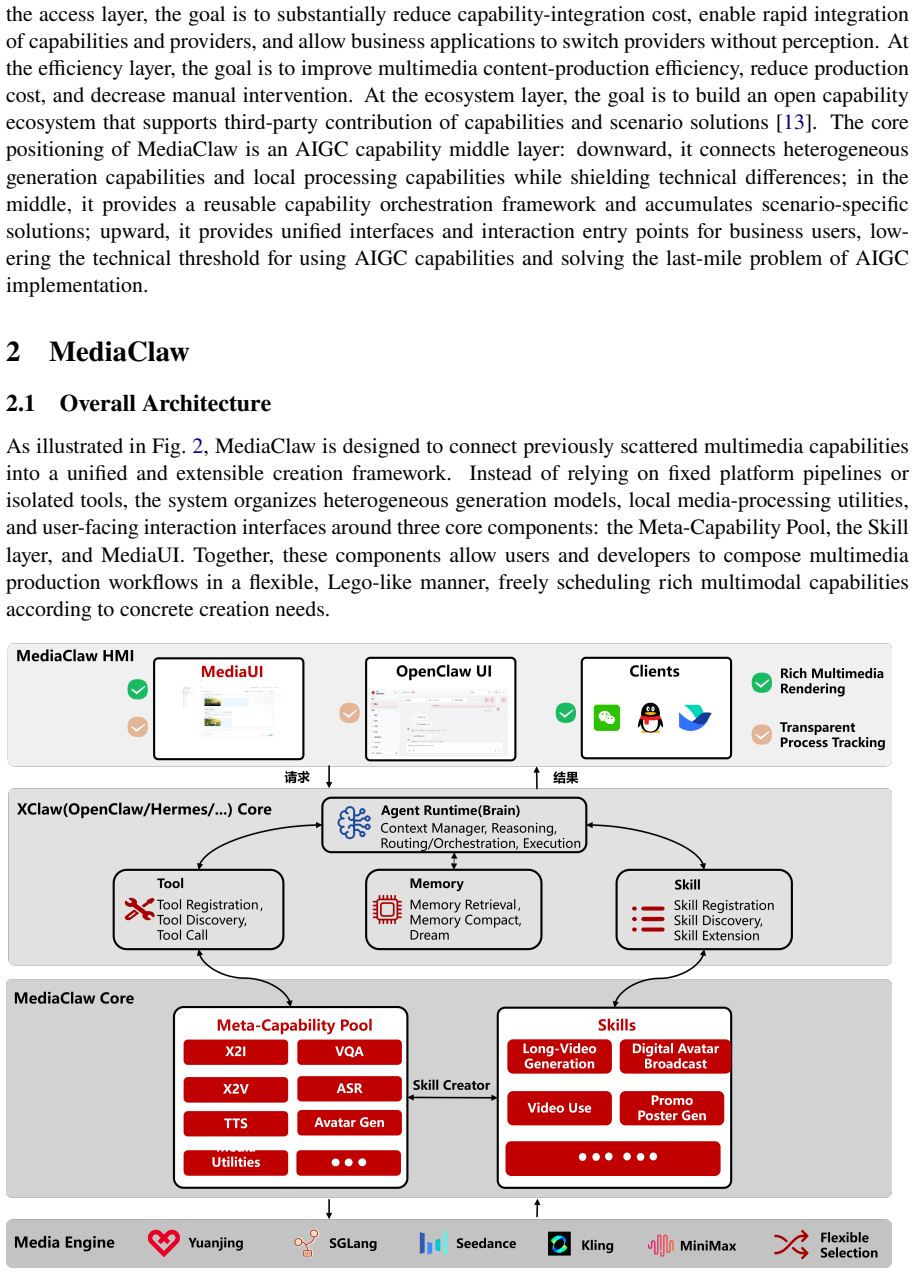
The three-layer architecture of unified abstraction for capabilities, pluginized extension for adding features, and workflow orchestration with Skills.
If this is right
- Capabilities from different sources become callable through one consistent interface.
- New AIGC functions integrate without system restarts via plugins.
- Complex production processes become saved and reusable workflow assets.
- The design supplies a reference pattern for other multimodal platforms.
Where Pith is reading between the lines
- The layering pattern may apply to agent systems outside AIGC that suffer similar tool fragmentation.
- Reusable Skills could become shareable assets across teams or organizations.
- Real-world performance would still require separate measurement of integration effort and error rates.
Load-bearing premise
That the three-layer architecture resolves fragmented capabilities, heterogeneous interfaces, disconnected processes, and limited workflow reuse.
What would settle it
A deployment comparison in which users still face separate interfaces or non-reusable workflows after switching to the unified model and Skills.
Figures








read the original abstract
MediaClaw is a multimodal agent platform built on the OpenClaw ecosystem. Its core design follows a three-layer architecture of unified abstraction, pluginized extension, and workflow orchestration. The system is intended to address practical deployment pain points in AIGC adoption, including fragmented capabilities, heterogeneous interfaces, disconnected production processes, and limited reuse of high-quality production workflows. \system{} abstracts full-category AIGC capabilities into a unified invocation model, uses plugins to support hot-pluggable capability expansion, and uses task-oriented Skills to turn complex production processes into reusable workflow assets. This report focuses on the architectural design philosophy of MediaClaw, the design logic of its core capability model, and the key engineering trade-offs in implementation. It aims to provide reusable practical reference for building multimodal capability platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes MediaClaw, a multimodal intelligent-agent platform built on the OpenClaw ecosystem. It outlines a three-layer architecture consisting of unified abstraction of AIGC capabilities into a single invocation model, pluginized extension for hot-pluggable capabilities, and workflow orchestration via task-oriented Skills to create reusable assets. The report details the architectural design philosophy, core capability model, and engineering trade-offs, with the goal of addressing issues like fragmented capabilities and limited workflow reuse in AIGC adoption, and providing a practical reference for similar platforms.
Significance. If the three-layer architecture is implemented as described, the work supplies a concrete design reference for unifying multimodal AIGC capabilities through abstraction, plugins, and Skills-based workflows. Its primary value is the explicit discussion of engineering trade-offs and the mapping of pain points (fragmented capabilities, heterogeneous interfaces) to architectural choices, offering reusable guidance for platform builders even in the absence of quantitative validation.
Simulated Author's Rebuttal
We thank the referee for the positive review, the assessment of significance, and the recommendation to accept the manuscript. No major comments were raised.
Circularity Check
No significant circularity
full rationale
The paper is a purely descriptive technical report on a three-layer architecture (unified abstraction, pluginized extension, workflow orchestration) for MediaClaw. It states design intent and rationale without equations, quantitative predictions, fitted parameters, or any derivation chain. No load-bearing claims reduce to self-definition, fitted inputs, or self-citation chains; the account is self-contained as an engineering description with no asserted effectiveness metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
video-use: Edit videos with coding agents.https://github.com/browser-use/ video-use, 2026
browser-use. video-use: Edit videos with coding agents.https://github.com/browser-use/ video-use, 2026. GitHub repository. Accessed: 2026-05-08
2026
-
[3]
Generative AI Technology Implementation White Paper, 2025
China Academy of Information and Communications Technology. Generative AI Technology Implementation White Paper, 2025
2025
-
[4]
FFmpeg documentation.https://ffmpeg.org/documentation.html,
FFmpeg Developers. FFmpeg documentation.https://ffmpeg.org/documentation.html,
-
[5]
Accessed: 2026-04-29
2026
-
[6]
Lemica: Lexicographicminimaxpathcachingforefficientdiffusion-basedvideogeneration
HuanlinGao,PingChen,FuyuanShi,ChaoTan,ZhaoxiangLiu,FangZhao,KaiWang,andShiguo Lian. Lemica: Lexicographicminimaxpathcachingforefficientdiffusion-basedvideogeneration. arXiv preprint arXiv:2511.00090, 2025
-
[7]
Huanlin Gao, Ping Chen, Fuyuan Shi, Ruijia Wu, Li YanTao, Qiang Hui, Yuren You, Ting Lu, ChaoTan,ShaoanZhao,etal. Meancache: Frominstantaneoustoaveragevelocityforaccelerating flow matching inference.arXiv preprint arXiv:2601.19961, 2026
-
[8]
HeyGen Skills: Ai agent skills for avatar creation and video production.https: //github.com/heygen-com/skills, 2026
HeyGen. HeyGen Skills: Ai agent skills for avatar creation and video production.https: //github.com/heygen-com/skills, 2026. Accessed: 2026-04-30
2026
-
[9]
2025–2026 China AIGC Market Tracker Report, 2025
IDC. 2025–2026 China AIGC Market Tracker Report, 2025
2025
-
[10]
OpenClaw-Admin: Webui framework for openclaw.https://github.com/itq5/ OpenClaw-Admin.git, 2026
itq5. OpenClaw-Admin: Webui framework for openclaw.https://github.com/itq5/ OpenClaw-Admin.git, 2026. GitHub repository. Accessed: 2026-05-13
2026
-
[11]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024. 16
2024
-
[13]
Phantom: Subject-consistent video generation via cross-modal alignment
Lijie Liu, Tianxiang Ma, Bingchuan Li, Zhuowei Chen, Jiawei Liu, Gen Li, Siyu Zhou, Qian He, and Xinglong Wu. Phantom: Subject-consistent video generation via cross-modal alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision,pages14951–14961, 2025
2025
-
[14]
OpenClaw official documentation.https://openclaw.dev/docs, 2026
OpenClaw Project. OpenClaw official documentation.https://openclaw.dev/docs, 2026. Accessed: 2026-04-29
2026
-
[15]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, HaimingZhao,JianxiaoYang,etal. Wan: Openandadvancedlarge-scalevideogenerativemodels. arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Qwen-image technical report, 2025
ChenfeiWu,JiahaoLi,JingrenZhou,JunyangLin,KaiyuanGao,KunYan,ShengmingYin,Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun Wen, Wensen Fe...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.